FSB总线、HT总线、QPI总线、DMI总线
【FSB总线、HT总线、QPI总线、DMI总线区别】
FSB:是Front Side BUS的英文缩写,中文叫前端总线,是将中央处理器(CPU)连接到北桥芯片的系统总线,它是CPU和外界交换数据的主要通道。前端总线的数据传输能力对计算机整体性能影响很大,如果没有足够带宽的前端总线,即使配备再强劲的CPU,用户也不会感觉到计算机整体速度的明显提升。这个名称是由AMD在推出K7 微架构系列CPU时提出的概念,但是一直以来都被大家误认为是外频的另一个名称。我们所说的外频指的是CPU与主板连接的速度,这个概念是建立在数字脉冲信号震荡速度基础之上的,而前端总线的速度指的是数据传输的速度,由于数据传输最大带宽取决于所有同时传输的数据的位宽和传输频率,即数据带宽=(总线频率×数据位宽)÷8。目前PC机上主流的前端总线频率有800MHz、1066MHz、 1333MHz几种,前端总线频率越大,代表着CPU与内存之间的数据传输量越大。虽然前端总线频率看起来已经很高,但与同时不断提升的内存频率、高性能显卡(特别多显卡系统)相比,CPU与芯片组存在的前端总线瓶颈仍未根本改变。例如,64位、1333MHz的FSB所提供的内存带宽是1333MHz×64bit/8=10667MB/s=10.67GB/s,与双通道的DDR2-667内存刚好匹配,但如果使用双通道的DDR2-800、DDR2-1066的内存,这时FSB的带宽就小于内存的带宽。更不用说和三通道和更高频率的DDR3内存搭配了。
HT总线:HT是Hyper-Transport的简称,是AMD为K8平台专门设计的高速串行总线。它的发展历史可回溯到1999年,原名为“LDT总线”(Lightning Data Transport,闪电数据传输)。2001年7月这项技术正式推出,AMD同时将它更名为Hyper-Transport。随后,Broadcom、Cisco、Sun、NVIDIA、ALI、ATI、Apple等许多企业均决定采用这项新型总线技术,而AMD也借此组建Hyper-Transport技术联盟(HTC),从而将Hyper-Transport推向产业界。Hyper-Transport本质是一种为主板上的集成电路互连而设计的端到端总线技术,目的是加快芯片间的数据传输速度。Hyper-Transport技术在AMD平台上使用后,是指AMD CPU到主板芯片之间的连接总线(如果主板芯片组是南北桥架构,则指CPU到北桥),即HT总线,类似于Intel平台中的前端总线(FSB),但Intel平台目前还没采用。在基础原理上,Hyper-Transport与目前的PCI Express非常相似,都是采用点对点的单双工传输线路,引入抗干扰能力强的LVDS信号技术,命令信号、地址信号和数据信号共享一个数据路径,支持DDR双沿触发技术等等,但两者在用途上截然不同—PCI Express作为计算机的系统总线,而Hyper-Transport则被设计为两枚芯片间的连接,连接对象可以是处理器与处理器、处理器与芯片组、芯片组的南北桥、路由器控制芯片等等,属于计算机系统的内部总线范畴。Hyper-Transport技术从规格上讲已经用HT1.0、HT2.0、HT3.0、HT3.1。
第一代Hyper-Transport的工作频率在200MHz—800MHz范围。因采用DDR技术,Hyper-Transport的实际数据激发频率为400MHz—1.6GHz,可支持2、4、8、16和32bit等五种通道模式,800MHz下,双向32bit模式的总线带宽为12.8GB/s,远远高于当时任何一种总线技术。
2004年2月,Hyper-Transport技术联盟(Hyper Transport Technology Consortium,HTC)又发布了Hyper-Transport 2.0规格,使频率成功提升到了1.0GHz、1.2GHz和1.4GHz,双向16bit模式的总线带宽提升到了8.0GB/s、9.6GB/s和11.2GB/s,而当时Intel 915G架构前端总线在6.4GB/s。
2007年11月19日,AMD正式发布了Hyper-Transport 3.0总线规范,提供了1.8GHz、2.0GHz、2.4GHz、2.6GHz几种频率,最高可以支持32通道。32位通道下,其总线的传输效率可以达到史无前例的41.6GB/s。超传输技术联盟(HTC)在2008年8月19日发布了新版Hyper-Transport 3.1规范和HTX3规范,将这种点对点、低延迟总线技术的速度提升到了3.2GHz,再结合双倍数据率(DDR),那么64-bit带宽可达51.2GB/s(即6.4GHz X 64bit/8)。
与AMD的HT总线技术相比,Intel的FSB总线瓶颈也很明显。面对这种带宽上的劣势,Intel要想改变这种处理器和北桥设备之间带宽捉襟见肘的情况,纵使在技术上将FSB频率进一步提高到2133MHz,也难以应付未来DDR3内存及多显卡系统所带来的带宽需求,Intel推出新的总线技术势在必行,所以,QPI总线就应运而生了。
QPI总线:是Quick Path Interconnect的缩写,译为快速通道互联,它的官方名字叫做CSI(Common System Interface公共系统界面),用来实现芯片之间的直接互联,而不是再通过FSB连接到北桥,矛头直指AMD的HT总线。
QPI是一种基于包传输的串行式高速点对点连接协议,在每次传输的20bit数据中,有16bit是真实有效的数据,其余4位用于循环校验,以提高系统的可靠性。由于QPI是双向的,在发送的同时也可以接收另一端传输来的数据,这样,每个QPI总线总带宽= QPI频率×每次传输的有效数据(即16bit/8=2Byte)×双向。所以QPI频率为4.8GT/s的总带宽=4.8GT/s×2Byte×2=19.2GB/s,QPI频率为6.4GT/s的总带宽=6.4GT/s×2Byte×2=25.6GB/s。此外,QPI另一个亮点就是支持多条系统总线连接,Intel称之为multi-FSB。系统总线将会被分成多条连接,并且频率不再是单一固定的,根据各个子系统对数据吞吐量的需求调整,这种特性无疑要比AMD目前的HT总线更具弹性。
在处理器中集成内存控制器的Intel微架构,抛弃了沿用多年的的FSB,CPU可直接通过内存控制器访问内存资源,而不是以前繁杂的“前端总线——北桥——内存控制器”模式。并且,与AMD在主流的多核处理器上采用的4HT3(4根传输线路,两根用于数据发送,两个用于数据接收)连接方式不同,英特尔采用了4+1 QPI互联方式(4针对处理器,1针对I/O设计),这样多处理器的每个处理器都能直接与物理内存相连,每个处理器之间也能彼此互联来充分利用不同的内存,可以让多处理器的等待时间变短。在Intel高端的安腾处理器系统中,QPI高速互联方式使得CPU与CPU之间的峰值带宽可达96GB/s,峰值内存带宽可达34GB/s。这主要在于QPI采用了与PCI-E类似的点对点设计,包括一对线路,分别负责数据发送和接收,每一条通路可传送20bit数据。QPI总线可实现多核处理器内部的直接互联,而无须像以前那样还要再经过FSB进行连接,从而大幅提升整体系统性能。
DMI总线:是Direct Media Interface的缩写,中文叫做直接媒体接口,是Intel公司开发用于连接主板南北桥的总线,取代了以前的Hub-Link总线。DMI采用点对点的连接方式,具有PCI-E总线的优势。DMI实现了上行与下行各1GB/s的数据传输率,总带宽达到2GB/s。
在Intel的Nehalem架构发布之初,由于集成了内存控制器,需要一个更为快速的数据传输接口来进行处理器数据和内存数据的传输,同时还要保证与主板上的其他芯片和接口如PCIE2.0和ICH南桥芯片之间的连接速度,所以当时采用了QPI总线技术,然而到了Lynnfield核心的Core i7/i5系列,其核心内部完全集成了内存控制器、PCI-E 2.0控制器等,也就是说将整个北桥都集成到了CPU内部,还稍有加强,在数据传输方面的要求自然要更高,所以Intel在CPU内部依然保留了QPI总线,用于CPU内部的数据传输。而在与外部接口设备进行连接的时候,需要有一条简洁快速的通道,就是DMI总线。这样,这两个总线的传输任务就分工明确了,QPI主管内,DMI主管外。
1技术特点
2区别
3带来什么
4影响
5示意图

1、QPI---QuickPath Interconnect 用于替代FSB
http://tech.sina.com.cn/h/2008-08-11/1422764825.shtml
X58的秘密武器 英特尔QPI总线技术解析
随P4X系列芯片组的推出,英特尔下一代旗舰级芯片组——X58上市日程也离我们是越来越近。其实Intel在今年5月份就曾揭露关于下一代旗舰X58主板信息,而在今年Computex展览的INTEL展区中已经可以看到各协力厂商所推出X58主板,只是这些产品仍处于最初的工程样品阶段。下一代桌上型X58主板预计取代现行X48主板,锁定高端玩家市场,INTEL率先在这款新产品导入LGA1366脚位设计的Nehalem处理器(代号为Bloomfield),不过此次X58最大的亮点并不是支持Nehalem处理器之上,而是它所引入推名为QuickPath Interconnect的总线技术。该技术将取代陪伴了我们多年的前端总线(FSB)技术,成为新一代CPU与CPU、CPU与芯片组(CPU与内存)之间的连接总线……
多核心时代,FSB架构成英特尔平台瓶颈
一直以来,在Intel处理器中,处理器与内存之间的通信都是通过前端总线(FSB)来完成的。在芯片世界,芯片互连一直是瓶颈问题。虽然处理器性能逐渐攀升,但是芯片互连性能却以一个很慢的速度在提升,从而导致芯片互连出现了瓶颈问题。特别是随着多处理核心的到来,处理核心与内存之间,核心与核心之间的数据共享和协调就变得异常复杂起来,英特尔平台所采用前端总线的瓶颈问题越来越明显,特加是在多处理器的服务器平台中更为明显。
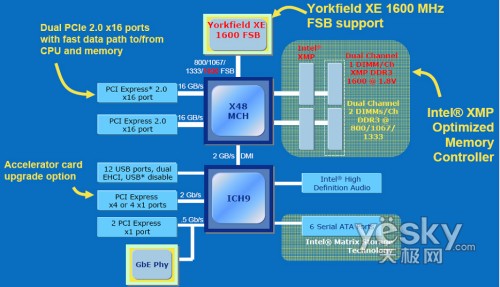
INTEL X48架构
目前Intel处理器主流的前端总线频率有800MHz、1066MHz、1333MHz几种,而就在2007年11月,Intel再度将处理器前端总线提升至1600MHz(默认外频400MHz),这比2003年最高端的800MHz FSB总线频率整整提升了一倍。这样高的前端总线频率,其带宽有多大呢?前端总线为1333MHz时,处理器与北桥之间的带宽是10.67GB/s,而提升到1600MHz能达到12.80GB/s,增加了20%。虽然Intel处理器的前端总线频率看起来已很高,但CPU与芯片组存在的前端总线瓶颈仍未根本改变。例如1333MHz的FSB所提供的内存带宽是1333MHz×64bit/8=10667MB/s=10.67GB/s,其与双通道的DDR2 667正好匹配,但如果使用双通道的DDR2 800、DDR2 1066的内存,这时候FSB的带宽就小于内存的带宽,更不用说和未来的三通道高频率DDR3内存搭配了。同时与AMD的HyperTransport(HT)总线技术相比,FSB的带宽瓶颈也很明显。以目前AMD最新的HT 3.0的为例,HT3.0将工作频率从HT 2.0最高的1.4GHz增到2.6GHz,提升幅度几乎又达一倍。这样,HT 3.0在2.6GHz高频率32bit高位宽的运行模式下,它即可提供高达41.6GB/s的总线带宽(即使在16bit位宽下它也能提供20.8GB/s带宽),相比FSB优势明显,应付近两年内内存、显卡和处理器的未来需要也没有问题。
同时,对于多处理器系统,多个处理器共享一个FSB连接到北桥,再通过北桥里边的内存控制器来访问内存。FSB是抢占性的,通过仲裁器决定哪一个处理器可以占用总线。在多处理器系统中,每个处理器通过单独的FSB连接到北桥,这样不同的处理器之间就不会出现一个处理器占用总线而另一个在等待的情况了,但是不同的处理器还是共用相同的内存控制器,这样不同的处理器之间还是要争夺内存的带宽。此外,在多处理器系统中,不同处理器之间需要进行缓存同步,在FSB这样的架构下,缓存同步要通过读写内存来实现,造成处理器缓存之间访问的延迟很大。随着处理器核心性能的提高,以及核心数量的急剧增长,FSB正在日益成为瓶颈,必须加以解决。
因此,Intel 要想在多核心时代处于不败之地,目前首要问题就是顺利解决系统资源的分配难题、充分发挥多核心的优势,这就是英特尔推出QPI总线技术的最终目的。 Intel自身也清醒地认识到,要想再通过单纯提高处理器的外频和FSB,已难以象以前那样带来更好的性能提升。Intel推出新的总线技术势在必行。
QPI技术特点——带宽更大
Intel的QuickPath Interconnect技术缩写为QPI,译为快速通道互联。事实上它的官方名字叫做CSI,Common System Interface公共系统界面,用来实现芯片之间的直接互联,而不是在通过FSB连接到北桥,矛头直指AMD的HT总线。无论是速度、带宽、每个针脚的带宽、功耗等一切规格都要超越HT总线。
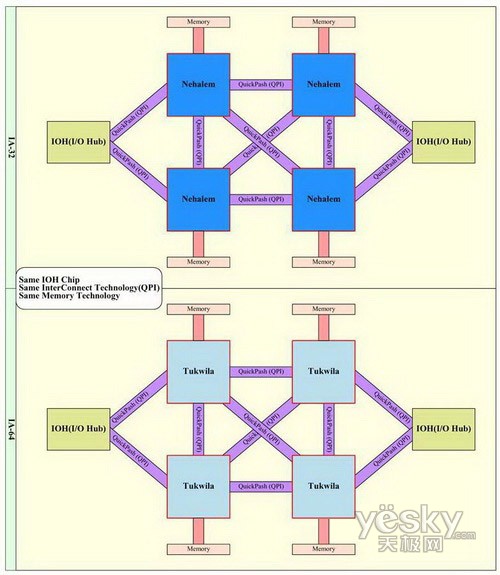
QPI最大的改进是采用单条点对点模式下,QPI的输出传输能力非常惊人,在4.8至6.4GT/s之间。一个连接的每个方向的位宽可以是5、10、20bit。因此每一个方向的QPI全宽度链接可以提供12至16BG/s的带宽,那么每一个QPI链接的带宽为24至32GB/s。(不过,这仍是逊色于AMD的Hypertransport3---单条连接最大传输带宽可以达到45GB/s,但我们相信未来英特尔仍会对QPI进行进一步提速改进。)在早期的Nehalem处理器中,Intel预计使用20bit的链接位宽,大约能提供25.6GB/s的数据传输能力。这个数字是Intel在上一季IDF中公布的。举例来说,在X48芯片组中,FSB的速度为1600MHz,这是目前为止规格最高的FSB总线了。不过最初的QPI总线具备25.6GB/s的吞吐量,这个值相当于1600MHz FSB带宽的2倍。
QPI技术特点——效率更高
此外,QPI另一个亮点就是支持多条系统总线连接,Intel称之为multi-FSB。系统总线将会被分成多条连接,并且频率不再是单一固定的,也无须如以前那样还要再经过FSB进行连接。根据系统各个子系统对数据吞吐量的需求,每条系统总线连接的速度也可不同,这种特性无疑要比AMD目前的Hypertransport总线更具弹性。
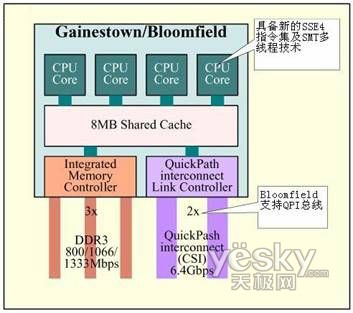
例如,针对服务器的Nehalem处理器将拥有至少4组QPI传输,可至少组成包括4枚处理器的4路高端服务器系统(也就是16枚运算内核至少32线程并行运作)。而且在多处理器作业下,每颗处理器可以互相传送资料,并不需经过芯片组,从而大幅提升整体系统性能。随着未来Nehalem架构的处理器集成内存控制器、PCI-E 2.0图形接口乃至图形核心,QPI架构的优势将进一步发挥出来。
为了降低QPI总线的延迟,Intel打算在4路处理器以上的系统中使用一种叫做粘贴缓存的技术。它主要是倚靠更大容量的二级高速缓存来存储南桥和北桥的数据,使处理器不必反复通过QPI总线来读取南北桥信息。同时,为了更高提升数据处理效率,英特尔还将在处理器内部集成内存控制器(IMC)。QPI和IMC结合,可以让Intel更轻松地扩展多路系统和高性能计算(HPC)应用,而Intel现有的处理器架构更关注于指令执行引擎和缓存架构,以便在单线程应用中提高性能,导致双路服务器平台性能受限,也无法在对内存带宽需求甚高的HPC中发挥作用。对于第一代采用QPI总线的Nehalem Xeon来说,集成了3通道的DDR3内存控制器,这样在搭配DDR3 1066的情况下,每个处理器自己就能得到25.6GB/s的内存带宽,大概是现在Tigerton系统的5倍,并且这个带宽数量随着处理器插座的增长而增长,对于四插座系统,总的带宽将增长到恐怖的102.4GB/s。强大的内存性能将保证即使每个插座上边采用8核心的处理器,内存带宽也不会成为性能发挥的瓶颈。需要说明的是在QPI中,对于四路系统来说,任何两个处理器之间都可以直接通信,这样,一个处理器可以很方便的访问到其他处理器控制的内存,这可以大大提升效率。另外,由于在QPI系统下不同处理器可以直接通信,同步缓存称为很方便的事情,再也不用通过北桥的内存读写来进行了。
结语:
随着QPI的正式推出,英特尔主导的QPI及AMD的HT 两大未来总线系统将会正面冲突。为了让多核心的系统更高效的工作,我们相信今后的芯片组会更加复杂,多条系统总线连接才是今后系统总线发展的王道。需要说明的是,英特尔在季秋IDF是已经在展示了可以工作的、首个采用QPI互联架构的Nehalem平台。我们有理由相信,QPI将冲破内存性能带来的樊篱,实现性能的新飞跃。
http://en.wikipedia.org/wiki/Intel_QuickPath_Interconnect
Intel QuickPath Interconnect
The Intel QuickPath Interconnect (QPI)[1][2] is a point-to-point processor interconnect developed by Intel which replaced the front-side bus (FSB) in Xeon,Itanium, and certain desktop platforms starting in 2008. Prior to the name's announcement, Intel referred to it as Common System Interface (CSI).[3] Earlier incarnations were known as Yet Another Protocol (YAP) and YAP+.
Contents
[hide]
Background[edit]
Although sometimes called a "bus", QPI is a point-to-point interconnect. It was designed to compete with HyperTransport that had been used by Advanced Micro Devices (AMD) since around 2003.[4][5] Intel developed QPI at its Massachusetts Microprocessor Design Center (MMDC) by members of what had been the AlphaDevelopment Group, which Intel had acquired from Compaq and HP and in turn originally came from Digital Equipment Corporation (DEC).[6] Its development had been reported as early as 2004.[7]
Intel first delivered it for desktop processors in November 2008 on the Intel Core i7-9xx and X58 chipset. It was released in Xeon processors code-named Nehalemin March 2009 and Itanium processors in February 2010 (code named Tukwila).[8]
Implementation[edit]
The QPI is an element of a system architecture that Intel calls the QuickPath architecture that implements what Intel calls QuickPath technology.[9] In its simplest form on a single-processor motherboard, a single QPI is used to connect the processor to the IO Hub (e.g., to connect an Intel Core i7 to an X58). In more complex instances of the architecture, separate QPI link pairs connect one or more processors and one or more IO hubs or routing hubs in a network on the motherboard, allowing all of the components to access other components via the network. As with HyperTransport, the QuickPath Architecture assumes that the processors will have integrated memory controllers, and enables a non-uniform memory access (NUMA) architecture.
Each QPI comprises two 20-lane point-to-point data links, one in each direction (full duplex), with a separate clock pair in each direction, for a total of 42 signals. Each signal is a differential pair, so the total number of pins is 84. The 20 data lanes are divided onto four "quadrants" of 5 lanes each. The basic unit of transfer is the 80-bit "flit", which is transferred in two clock cycles (four 20 bit transfers, two per clock.) The 80-bit "flit" has 8 bits for error detection, 8 bits for "link-layer header," and 64 bits for "data". QPI bandwidths are advertised by computing the transfer of 64 bits (8 bytes) of data every two clock cycles in each direction.[6]
Although the initial implementations use single four-quadrant links, the QPI specification permits other implementations. Each quadrant can be used independently. On high-reliability servers, a QPI link can operate in a degraded mode. If one or more of the 20+1 signals fails, the interface will operate using 10+1 or even 5+1 remaining signals, even reassigning the clock to a data signal if the clock fails.[6]
The initial Nehalem implementation used a full four-quadrant interface to achieve 25.6 GB/s, which provides exactly double the theoretical bandwidth of Intel's 1600 MHz FSB used in the X48 chipset.
Although some Core i7 processors use QPI, other Nehalem desktop and mobile processors (e.g. Core i3, Core i5, and other Core i7 processors) do not—at least in any externally accessible fashion. These processors cannot participate in a multiprocessor system. Instead, they directly implement the DMI and PCI-einterfaces, obviating the need for a "northbridge" device or a processor bus of any type.[citation needed]
Frequency specifications[edit]
QPI operates at a clock rate of 2.4 GHz, 2.93 GHz, 3.2 GHz, or 4.0 GHz (4.0 GHz frequency is introduced with the Sandy Bridge-E/EP platform). The clock rate for a particular link depends on the capabilities of the components at each end of the link and the signal characteristics of the signal path on the printed circuit board. The non-extreme Core i7 9xx processors are restricted to a 2.4 GHz frequency at stock reference clocks. Bit transfers occur on both the rising and the falling edges of the clock, so the transfer rate is double the clock rate.
Intel describes the data throughput (in GB/s) by counting only the 64-bit data payload in each 80-bit "flit". However, Intel then doubles the result because the unidirectional send and receive link pair can be simultaneously active. Thus, Intel describes a 20-lane QPI link pair (send and receive) with a 3.2 GHz clock as having a data rate of 25.6 GB/s. A clock rate of 2.4 GHz yields a data rate of 19.2 GB/s. More generally, by this definition a two-link 20-lane QPI transfers eight bytes per clock cycle, four in each direction.
The rate is computed as follows:
- 3.2 GHz
- × 2 bits/Hz (double data rate)
- × 20 (QPI link width)
- × (64/80) (data bits/flit bits)
- × 2 (unidirectional send and receive operating simultaneously)
- ÷ 8 (bits/byte)
- = 25.6 GB/s
Protocol layers[edit]
QPI is specified as a five-layer architecture, with separate physical, link, routing, transport, and protocol layers.[1] In devices intended only for point-to-point QPI use with no forwarding, such as the Core i7-9xx and Xeon DP processors, the transport layer is not present and the routing layer is minimal.
- Physical layer
- The physical layer comprises the actual wiring and the differential transmitters and receivers, plus the lowest-level logic that transmits and receives the physical-layer unit. The physical-layer unit is the 20-bit "phit." The physical layer transmits a 20-bit "phit" using a single clock edge on 20 lanes when all 20 lanes are available, or on 10 or 5 lanes when the QPI is reconfigured due to a failure. Note that in addition to the data signals, a clock signal is forwarded from the transmitter to receiver (which simplifies clock recovery at the expense of additional pins).
- Link layer
- The link layer is responsible for sending and receiving 80-bit flits. Each flit is sent to the physical layer as four 20-bit phits. Each flit contains an 8-bit CRC generated by the link layer transmitter and a 72-bit payload. If the link layer receiver detects a CRC error, the receiver notifies the transmitter via a flit on the return link of the pair and the transmitter resends the flit. The link layer implements flow control using a credit/debit scheme to prevent the receiver's buffer from overflowing. The link layer supports six different classes of message to permit the higher layers to distinguish data flits from non-data messages primarily for maintenance of cache coherence. In complex implementations of the QuickPath architecture, the link layer can be configured to maintain separate flows and flow control for the different classes. It is not clear if this is needed or implemented for single-processor and dual-processor implementations.
- Routing layer
- The routing layer sends a 72-bit unit consisting of an 8-bit header and a 64-bit payload. The header contains the destination and the message type. When the routing layer receives a unit, it examines its routing tables to determine if the unit has reached its destination. If so it is delivered to the next-higher layer. If not, it is sent on the correct outbound QPI. On a device with only one QPI, the routing layer is minimal. For more complex implementations, the routing layer's routing tables are more complex, and are modified dynamically to avoid failed QPI links.
- Transport layer
- The transport layer is not needed and is not present in devices that are intended for only point-to-point connections. This includes the Core i7. The transport layer sends and receives data across the QPI network from its peers on other devices that may not be directly connected (i.e., the data may have been routed through an intervening device.) the transport layer verifies that the data is complete, and if not, it requests retransmission from its peer.
- Protocol layer
- The protocol layer sends and receives packets on behalf of the device. A typical packet is a memory cache row. The protocol layer also participates in cache coherency maintenance by sending and receiving cache coherency messages.
-
Computer bus — technical and de facto standards (wired) General Standards - S-100 bus
- Unibus
- VAXBI
- MBus
- STD Bus
- SMBus
- Q-Bus
- ISA
- STEbus
- Zorro II
- Zorro III
- CAMAC
- FASTBUS
- LPC
- HP Precision Bus
- EISA
- VME
- VXI
- VXS
- NuBus
- TURBOchannel
- MCA
- SBus
- VLB
- PCI
- PXI
- HP GSC bus
- CoreConnect
- InfiniBand
- UPA
- PCI Extended (PCI-X)
- AGP
- PCI Express (PCIe)
- RapidIO
- Intel QuickPath Interconnect
- HyperTransport
Portable Embedded Storage Peripheral Note: interfaces are listed in speed ascending order (roughly), the interface at the end of each section should be the fastest
FSB总线、HT总线、QPI总线、DMI总线的更多相关文章
- FSB\QPI\DMI总线的区别
FSB\QPI\DMI总线的区别 zjdyx91 一些客户问:intel CPU有的是前端总线(FSB),有的是QPI总线,有的又是DMI总线,这就把人弄晕了, ...
- FSB—QPI—DMI总线的发展
intel CPU有的是前端总线(FSB),有的是QPI总线,有的又是DMI总线 FSB总线(由于cpu的发展,fsb总线制约了cpu的发展,所以该总线已经渐渐淡出历史舞台) FSB即Front Si ...
- CAN总线学习系列之二——CAN总线与RS485的比较
CAN总线学习系列之二——CAN总线与RS485的比较 上 一节介绍了一下CAN总线的基本知识,那么有人会问,现在的总线格式很多,CAN相对于其他的总线有什么特点啊?这个问题问的好,所以我想与其它总线 ...
- CAN总线系列讲座第五讲——CAN总线硬件电路设计
CAN总线系列讲座第五讲--CAN总线硬件电路设计一 实战学习背景 CAN总线节点的硬件构成方案有两种,其中的方案:(1).MCU控制器+独立CAN控制器+CAN收发器.独立CAN控制器如SJA10 ...
- C#总结(六)EventBus事件总线的使用-自己实现事件总线
在C#中,我们可以在一个类中定义自己的事件,而其他的类可以订阅该事件,当某些事情发生时,可以通知到该类.这对于桌面应用或者独立的windows服务来说是非常有用的.但对于一个web应用来说是有点问题的 ...
- I2S音频总线学习(二)I2S总线协议
http://blog.csdn.net/ce123_zhouwei/article/details/6919954
- 计算机原理学习(2)-- 存储器和I/O设备和总线
前言 前一篇文章介绍了冯诺依曼体系结构的计算机的基本工作原理,其中主要介绍了CPU的结构和工作原理.这一篇主要来介绍存储区,总线,以及IO设备等其他几大组件,来了解整个计算机是如何工作的. 这些东西都 ...
- 2.1 存储器域与PCI总线域
HOST主桥的实现因处理器系统而异.PowerPC处理器和x86处理器的HOST主桥除了集成方式不同之外,其实现机制也有较大差异.但是这些HOST主桥所完成的最基本功能依然是分离存储器域与PCI总线域 ...
- 006 PCI总线的桥与配置(一)
在PCI体系结构中,含有两类桥片,一个是HOST主桥,另一个是PCI桥.在每一个PCI设备中(包括PCI桥)都含有一个配置空间.这个配置空间由HOST主桥管理,而PCI桥可以转发来自HOST主桥的配置 ...
随机推荐
- 在myeclipse中使用查找功能
1.全局搜索(快捷键:ctrl+H) 在弹出对话框中选File Search选项,然后在第一个文本框中粘贴(我一般用粘贴)或自已手动录入(容易写错)要查找的字符串(可以是英文字符也可以是汉字),在第二 ...
- 【原】缓存之 HttpRuntime.Cache
1.HttpRuntime.Cache HttpRuntime.Cache 相当于就是一个缓存具体实现类,这个类虽然被放在了 System.Web 命名空间下了.但是非 Web 应用也是可以拿来用的. ...
- 使用ANT将Android打包成Jar包
本文主要实现使用ANT,将Android项目打包成jar,为方便其他项目使用. ANT可以去官网下载(http://ant.apache.org/) 先介绍打包的步骤,打包脚本下方贴出 步骤: 1,将 ...
- Python logging 学习
基本用法: import logging #初始化logger 对象 logger = logging.getLogger("main") #设置logger对象基础级别,后面的h ...
- 被忽视的控件UIToolbar
前言 UIToolbar以前也接触过,不过没有怎么用,久而久之就忘了他的存在,今天看别人源码的时候看见了,它怎么很方便,在排列一排视图的时候不需要我们算里面的坐标就可以轻松良好的把布局做出来 代码 U ...
- nginx进程属主问题讨论
文章作者:luxianghao 文章来源:http://www.cnblogs.com/luxianghao/p/6107096.html 转载请注明,谢谢合作. 免责声明:文章内容仅代表个人观点,如 ...
- 【Luogu】P1417烹调方案(排序01背包)
题目链接 对食材进行排序,重载运算符代码如下: struct food{ long long a,b,c; bool operator <(const food &a)const{ re ...
- leetcode 350
找两个数组的交叉部分,可以用map进行标记 首先对第一个数组进行记录,第二个数组在第一个数组记录基础上进行判断,如果在第一个数组出现过,就记录 class Solution { public: vec ...
- NVMe与SCM结合将赋予存储介质的能力
转自:SCM是什么鬼,NVMe与其结合将赋予存储介质哪些能力? 全SSD闪存阵列在企业级存储得到广泛应用,相比传统机械硬盘,它的延迟.性能和可靠性都有了显著提高.许多早期开发商抓住其闪存技术优势的机遇 ...
- 16.1113 模拟考试T2
测试题 #4 括号括号[问题描述]有一个长度为?的括号序列,以及?种不同的括号.序列的每个位置上是哪种括号是随机的,并且已知每个位置上出现每种左右括号的概率.求整个序列是一个合法的括号序列的概率.我们 ...