《Microsoft COCO Captions Data Collection and Evaluation Server》论文笔记
出处:CVPR2015
Motivation
本文描述了MSCoco标题数据集及评估服务器(Microsoft COCO Caption dataset and evaluation server),最终生成了超过330,000带标题的 images。训练集和验证集找了5个人力来标注,并且为了验证标注预测的一致性,引入了评估服务器机制。评估服务器使用了BLEU, METEOR, ROUGE and CIDEr等多种评估标准。
Introduction
在介绍了之前的一些生成caption的工作后,作者非常关心是否有一种评估机制能保证生成caption的一致性(When evaluating image caption generation algorithms,it is essential that a consistent evaluation protocol is used.)。
数据集:The MS COCO caption dataset contains human generated captions for images contained in the Microsoft Common Objects in COntext(COCO) dataset
Paper Structure
First we describe the data collection process. Next, we describe the caption evaluation server and the various metrics used. Human performance using these metrics are provided. Finally the annotation format and instructions for using the evaluation server are described for those who wish to submit results.
数据(如何被)收集
MSCoco -> MSCoco Caption
MS COCO c40 每张图片40句人工参考描述
MS COCO c5 每张图片5句人工参考描述
Evaluation server
作者用该评估服务器来从候选caption中选取score最高的 Our goal is to automatically evaluate for an image 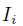 the quality of a candidate caption
the quality of a candidate caption 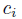 given a set of reference captions
given a set of reference captions 
评估机制
BLEU[1]
BLEU是事实上的机器翻译评测标准,n 常取1到4,基于准确率(precision)的评测。参考句子1是“the cat is on the mat”,参考句子2是“there is a cat on the mat”,而模型生成的句子是“the the the the the the the”,那么按照上述定义,考察 n=1 的情况,也就是unigram,模型生成的句子包含7个 unigram ,这7个 unigram 全部出现在了参考句子集合中,所以将得到 7/7 这样的满分,但是这样的译文显然没有意义。为了获得较高的指标,模型完全可以在任何位置都去生成一个“百搭”的词,使得分子随着分母的增长而增长。BLEU引进了precision的计算方式来修正这个“百搭”的问题。考虑模型生成的句子 c 的全部 n-gram ,考察其中的任一 n-gram :首先计算其在 c 中出现的次数 Count(n-gram) ;然后统计其在各参考句子中分别出现的次数的最大值,将该值与 Count(n-gram) 的较小者记作该 n-gram 的匹配次数 Countclip(n-gram) 。之后,再把每个 n-gram 的计算结果累加起来,得到句子的结果。

{Candidates} 代表需要评测的多句译文的集合。当n取1时,∑n-gram∈cCount(n-gram) 就是句子 c 的长度。回过头来看上面那个例子,译文句子的 unigram 只有“the”,它在译文中出现了7次,故 Count(the)=7;在参考句子1中出现2次,参考句子2中出现1次,最大值为2,所以“the”的匹配次数为 Countclip(the)=min{7,2}=2 ,因此precision为 2/7 。但是这样的计算方式仍然存在问题:比如模型生成的句子是“the cat is on”,那么从 n 不论取1、2、3还是4,得分都是1,满分。换言之,由于评价的是precision,所以会倾向于短句子,如果模型只翻译最有把握的片段,那么就可以得到高分,因此要对短句子进行惩罚。惩罚的方式就是在原先的评价指标值上乘一个惩罚因子(brevity penalty factor):当模型给出的译文句子 c 的长度 lc 要比参考句子的长度 ls 长时,就不进行惩罚,即惩罚因子为1,比如说有三个参考句子的长度分别为12、15、17,模型给出的译文句子长度为12,那么就不进行惩罚,比较的是各参考句子长度里最接近的那个;否则就惩罚:

式中的 lC 代表模型给出的测试集全部句子译文的长度总和,lS 代表与模型给出译文句子长度最接近的参考译文的长度(语料级别)。综合起来,BLEU的评分公式采用的是对数加权平均值(这是因为当n增大时评分会指数级减小),再乘上惩罚因子:
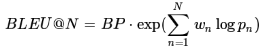 式中的 N 通常取4,权重 wn 通常取1N(几何平均)。最终评分在0到1之间,1表示完全与人工翻译一致。
式中的 N 通常取4,权重 wn 通常取1N(几何平均)。最终评分在0到1之间,1表示完全与人工翻译一致。
BLEU的优点:它考虑的粒度是 n-gram 而不是词,考虑了更长的匹配信息;
BLEU的缺点:是不管什么样的 n-gram 被匹配上了,都会被同等对待。比如说动词匹配上的重要性从直觉上讲应该是大于冠词的
ROUGE[2]
ROUGE是出于召回率来计算,所以是自动摘要任务的评价标准
METEOR[3]
Meteor也是来评测机器翻译的,对模型给出的译文与参考译文进行词对齐,计算词汇完全匹配、词干匹配和同义词匹配等各种情况的准确率、召回率和F值。首先计算 unigram 情况下的准确率 P 和召回率 R(计算方式与BLEU、ROUGE类似),得到调和均值(F值)
 如果 α>1 就说明 R 的权重高。Meteor的特别之处在于,它不希望生成很“碎”的译文:比如参考译文是“A B C D”,模型给出的译文是“B A D C”,虽然每个 unigram 都对应上了,但是会受到很严重的惩罚,惩罚因子的计算方式为
如果 α>1 就说明 R 的权重高。Meteor的特别之处在于,它不希望生成很“碎”的译文:比如参考译文是“A B C D”,模型给出的译文是“B A D C”,虽然每个 unigram 都对应上了,但是会受到很严重的惩罚,惩罚因子的计算方式为
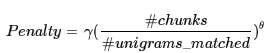
式中的 #chunks 表示匹配上的语块个数,如果模型生成的译文很碎的话,语块个数会非常多;#unigrams_matched 表示匹配上的 unigram 个数。所以最终的评分为
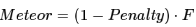
CIDEr(Consensus-based image description evaluation)[4]
这个指标将每个句子都看作“文档”,将其表示成 tf-idf 向量的形式,然后计算参考caption与模型生成的caption的余弦相似度,作为打分。换句话讲,就是向量空间模型。

式中的 Ω 是全部 n-gram 构成的词表。可以看出 idf 的分母部分代表的是 ωk 出现于参考caption的图片个数。
那么,CIDEr的值可以用余弦相似度的平均值来计算:

类似于BLEU的做法:
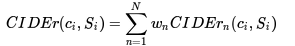
这个指标的motivation之一是刚才提到的BLEU的一个缺点,就是对所有匹配上的词都同等对待,而实际上有些词应该更加重要。(参考tf-idf提取关键词的算法)
[1]K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” in ACL, 2002.
[2]C.-Y. Lin, “Rouge: A package for automatic evaluation of summaries,” in ACL Workshop, 2004.
[3]M. Denkowski and A. Lavie, “Meteor universal: Language specific translation evaluation for any target language,” in EACL Workshop on Statistical Machine Translation, 2014.
[4]R. Vedantam, C. L. Zitnick, and D. Parikh, “Cider:Consensus-based image description evaluation,” arXiv preprint arXiv:1411.5726, 2014.
《Microsoft COCO Captions Data Collection and Evaluation Server》论文笔记的更多相关文章
- 《Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition》论文笔记
论文题目:<Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition> 论文作者:Qibin ...
- [place recognition]NetVLAD: CNN architecture for weakly supervised place recognition 论文翻译及解析(转)
https://blog.csdn.net/qq_32417287/article/details/80102466 abstract introduction method overview Dee ...
- 论文笔记系列-Auto-DeepLab:Hierarchical Neural Architecture Search for Semantic Image Segmentation
Pytorch实现代码:https://github.com/MenghaoGuo/AutoDeeplab 创新点 cell-level and network-level search 以往的NAS ...
- 论文笔记——Rethinking the Inception Architecture for Computer Vision
1. 论文思想 factorized convolutions and aggressive regularization. 本文给出了一些网络设计的技巧. 2. 结果 用5G的计算量和25M的参数. ...
- 论文笔记:Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells
Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells 2019-04- ...
- 论文笔记:ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware
ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware 2019-03-19 16:13:18 Pape ...
- 论文笔记:DARTS: Differentiable Architecture Search
DARTS: Differentiable Architecture Search 2019-03-19 10:04:26accepted by ICLR 2019 Paper:https://arx ...
- 论文笔记:Progressive Neural Architecture Search
Progressive Neural Architecture Search 2019-03-18 20:28:13 Paper:http://openaccess.thecvf.com/conten ...
- 论文笔记:Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation2019-03-18 14:4 ...
- 论文笔记系列-DARTS: Differentiable Architecture Search
Summary 我的理解就是原本节点和节点之间操作是离散的,因为就是从若干个操作中选择某一个,而作者试图使用softmax和relaxation(松弛化)将操作连续化,所以模型结构搜索的任务就转变成了 ...
随机推荐
- jsonp跨域请求实现示例
网上看了很多关于jsonp的资料,发现在本机运行后实现不了,有的是有错漏,有的是说的比较含糊,接合自己的情况,整了一个可运行的示例: 前言: ajax请求地址:http://192.168.1.102 ...
- [转]Fedora22添加国内软件源和本地软件源
Fedora22添加国内软件源和本地软件源 Linux系统和Windows系统一个很大的区别就是软件安装方式,windows系统下安软件,我们去相应的网站下载软件安装包离线安装就可以了.虽然Linux ...
- Hotel(poj 3667)
题意:询问区间最长连续空串 /* 用线段树维护区间最长连续左空串和右空串 */ #include<cstdio> #include<iostream> #define N 50 ...
- 【POJ3311】Hie with the Pie(状压DP,最短路)
题意: 思路:状压DP入门题 #include<cstdio> #include<cstdlib> #include<algorithm> #include< ...
- controller跳到另一个controller
1.无参数: return "redirect:park/findByTag"; 2/有参数: public String addChild(Model model2) model ...
- zookeeper原理浅析(一)
参考:https://www.cnblogs.com/leocook/p/zk_0.html 代码:https://github.com/littlecarzz/zookeeper 1. 什么是Zoo ...
- DELPHI最新的产品路线图
1)根据众多像您一样的客户要求,我们改为一年一个重大版本及更多更新.这个计划回到一年发布周期并提供额外的2或3个包含附加功能及支持期间发布的新版操作系统的更新. 2)在 RAD Studio 10. ...
- 从CLR GC到CoreCLR GC看.NET Core对云原生的支持
内存分配概要 前段时间在园子里看到有人提到了GC学习的重要性,很赞同他的观点.充分了解GC可以帮助我们更好的认识.NET的设计以及为何在云原生开发中.NET Core会占有更大的优势,这也是一个程序员 ...
- Meteor表单
在本教程中,我们将告诉你如何使用 Meteor 的表单. 文本输入 首先,我们将创建一个 form 元素中文本输入字段和提交按钮. meteorApp/import/ui/meteorApp.html ...
- Teamviewer ubuntu 提示 TeamViewer Daemon is not running
http://blog.csdn.net/laohuang1122/article/details/12657343 Ubunut 12.04下面安装了Teamviewer,刚安装完启动是没有问题的, ...