性能测试四十一:sql案例之慢sql配置、执行计划和索引
MYSQL 慢查询使用方法
MYSQL慢查询介绍
分析MySQL语句查询性能的问题时候,可以在MySQL记录中查询超过指定时间的语句,我们将超过指定时间的SQL语句查询称为“慢查询”。MYSQL自带的慢查询分析工具mysqldumpslow可对慢查询日志进行分析:主要功能是, 统计sql的执行信息,其中包括 :
出现次数(Count),
执行最长时间(Time),
累计总耗费时间(Time),
等待锁的时间(Lock),
发送给客户端的行总数(Rows),
扫描的行总数(Rows),
用户以及sql语句本身(抽象了一下格式, 比如 limit 1, 20 用 limit N,N 表示).
案例:慢sql
先确定项目指向的数据库是对的

问题接口:http://localhost:8080/PerfTeach/SlowQuery?cardNO=10001
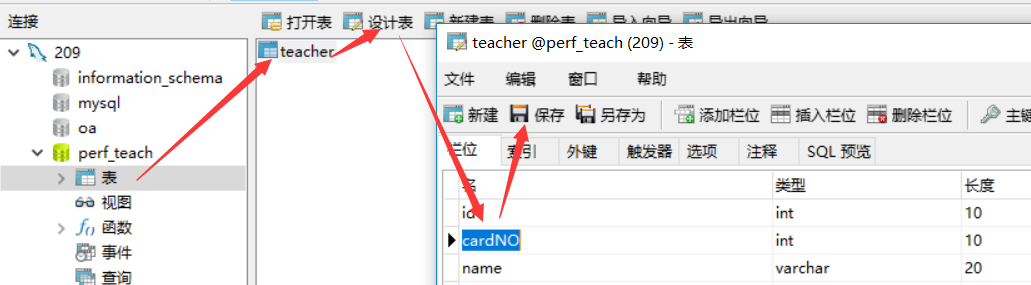
由于数据库里面是card_no,而代码里面是cardNO,所以要改一下数据库里面的字段名

修改
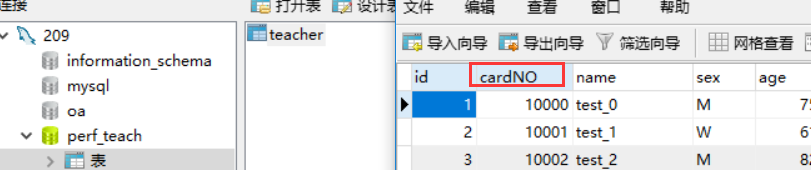
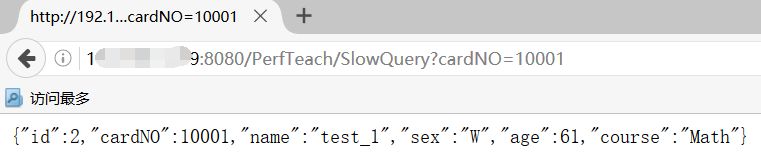
访问一下:http://localhost:8080/PerfTeach/SlowQuery?cardNO=10001,和数据库里的一样
在jmeter里面造一个10000--20000的随机数函数

监控开起来
运行jmeter,用10个并发,跑600秒
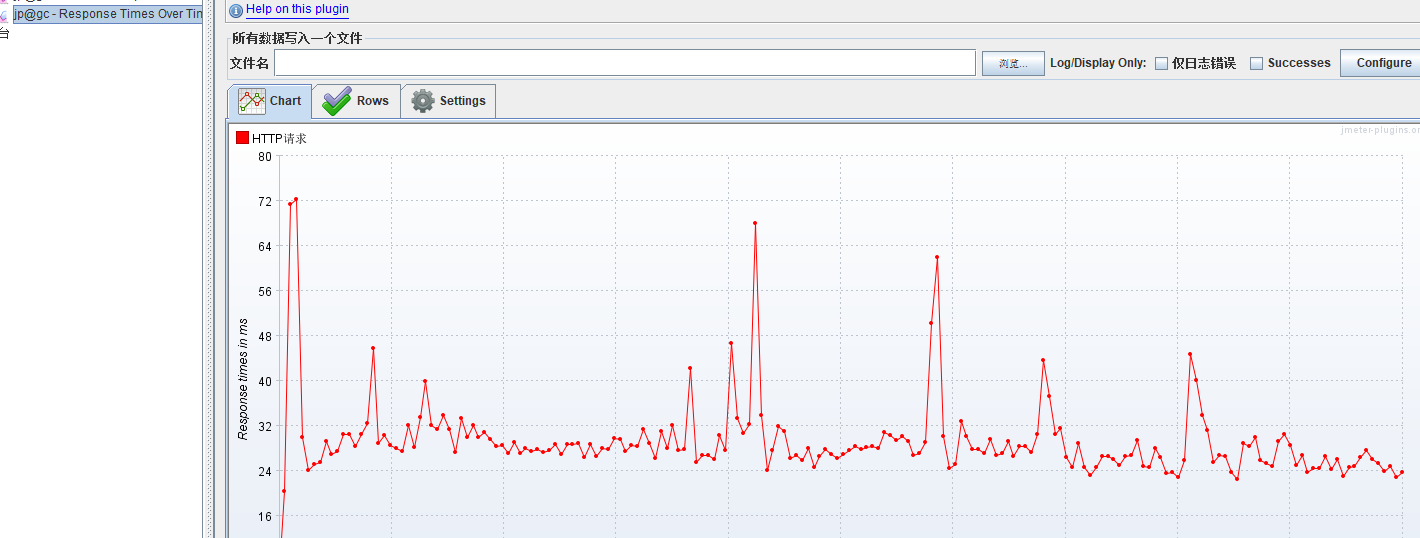
TPS很低
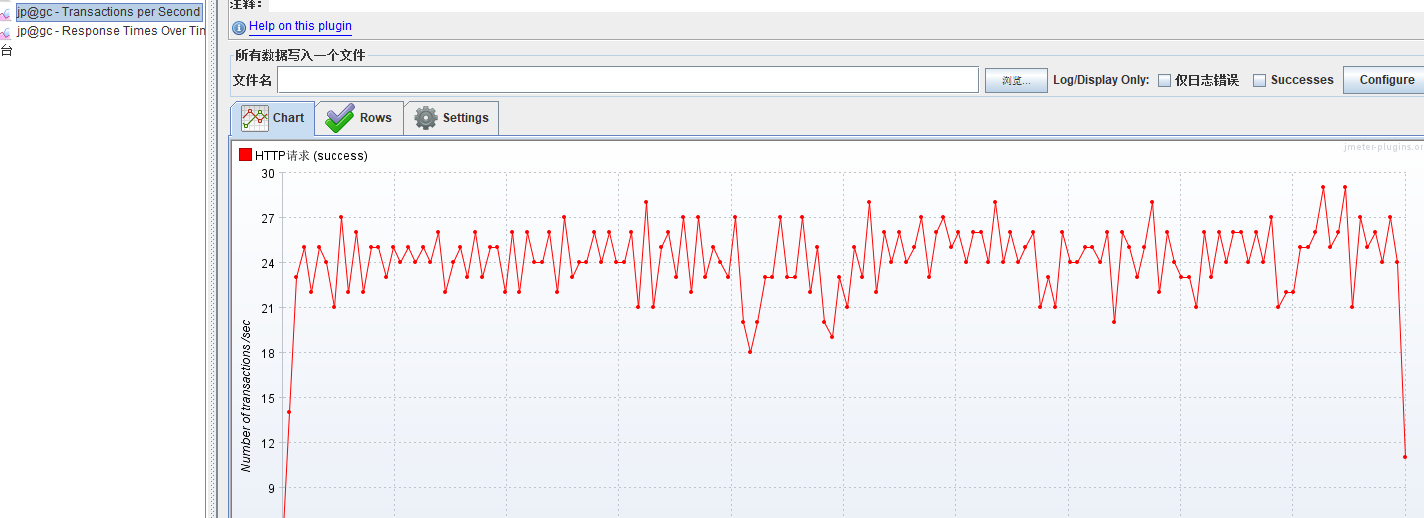
响应时间很长

CPU高

mysql进程占了89.9%的cpu使用率
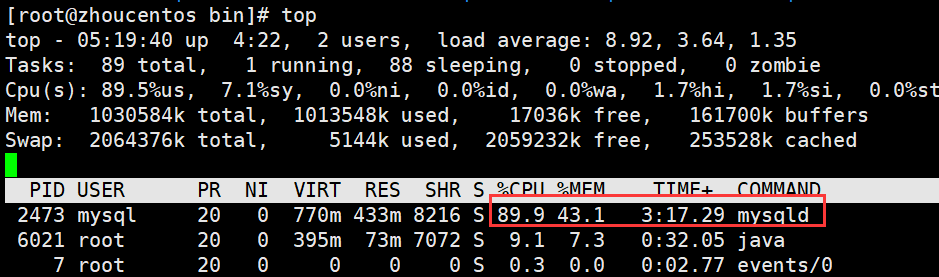
所以,可以确定是mysql这块有问题,而这种问题一般都是sql写的不好造成的
1、 开启慢SQL的配置
1.1 LIUNX 系统 在mysql配置文件my.cnf中(文件最后)增加
slow_query_log:这是一个布尔型变量,默认为真。没有这变量,数据库不会打印慢查询的日志。
slow_query_log_file=/usr/local/mysql/data/zhoucentos-slow.log:(指定日志文件存放位置(安装mysql的目录),可以为空,系统会给一个缺省的文件hostName-slow.log)
long_query_time=0.1:(记录超过的时间,默认为10s),与DBA沟通,性能测试分析问题时可以将该值设为0.1即100毫秒,这样分析的粒度更详细。
备选 :log-queries-not-using-indexes (log下来没有使用索引的query,可以根据情况决定是否开启)。log-long-format (如果设置了,所有没有使用索引的查询也将被记录)


重启mysql

1.2 Windows下配置:
在my.ini的[mysqld]添加如下语句:
log-slow-queries = E:\web\mysql\log\mysqlslowquery.log
long_query_time = 0.1(其他参数如上)
注: 配置完成后,重新mysql服务配置才能生效。
2、 慢查询开启与关闭
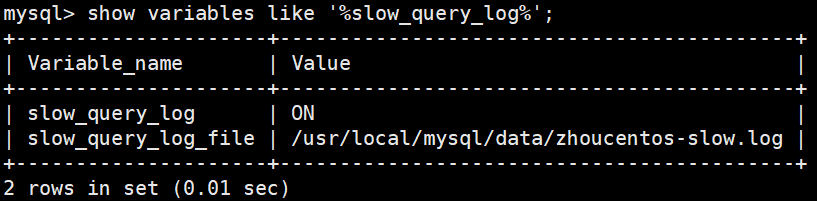
2.1 配置完成,连接数据库检查慢查询日志是否开启:
命令如下:mysql> show variables like '%slow_query_log%';


压一下,看看有没有数据写进去,从172,变成了124800,使用-h查看:122K


2.2 如果没有打开,请开启,slow_query_log,以下方法是一次性的,只要重启mysql就会恢复到原样
开启命令:mysql> set @@global.slow_query_log = on;
关闭命令:mysql> set @@global.slow_query_log = off;
2.3 再次检查是否开启成功
mysql> show variables like '%slow_query_log%';
2.4 检查目录中是否生成文件
/mysql目录下是否存在mysql_slow.log
[root@localhost mysql]# ls -l mysql_slow.log
3、 慢查询日志分析
3.1 Linux系统:
使用mysql自带命令mysqldumpslow查看(需在mysql/bin目录下执行,因为mysqldumpslow在bin目录下)
常用命令,通过 ./mysqldumpslow -help查看
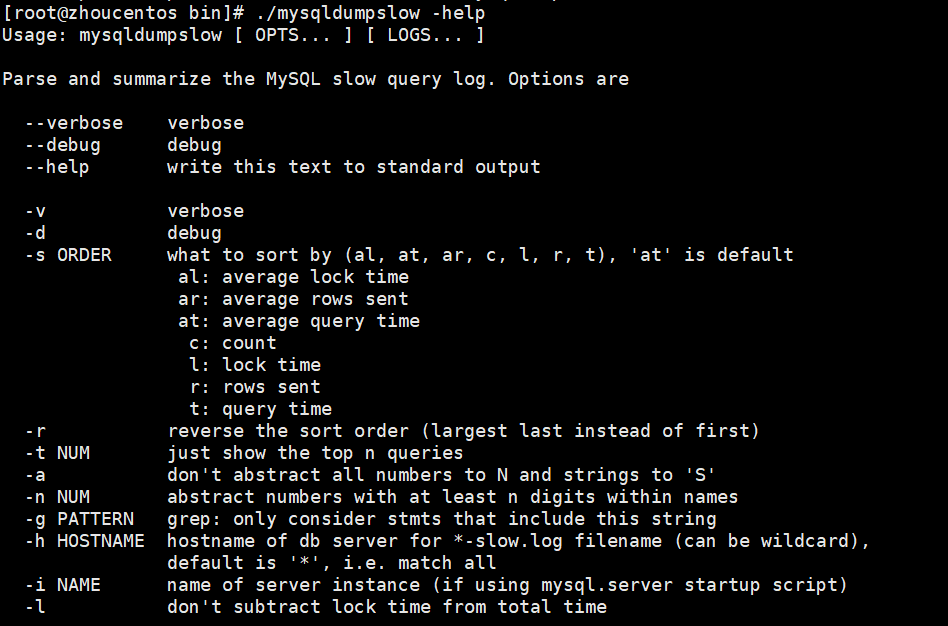
-s,是order的排序,主要有 c,t,l,r和ac,at,al,ar,分别是按照query次数,时间,lock的时间和返回的记录数来排序
-a,倒序排列
-t,是top n的意思,即为返回前面多少条的数据
-g,后边可以写一个正则匹配模式,大小写不敏感的
例如:
./mysqldumpslow -s c -t 20 host-slow.log:访问次数最多的20个sql语句

./mysqldumpslow -s r -t 20 host-slow.log:返回记录集最多的20个sql

./mysqldumpslow -t 10 -s t -g “left join” host-slow.log这个是按照时间返回前10条里面含有左连接的sql语句。
./mysqldumpslow -s at -t 50 host-slow.log 显示出耗时最长的50个SQL语句的执行信息(此方法最常用)
总共执行了602次,平均执行390毫秒,和jmeter统计出来的平均响应时间差不多了,所以,时间都耗在执行sql上面了

由于这里数据量不够,所以找了个项目中的图
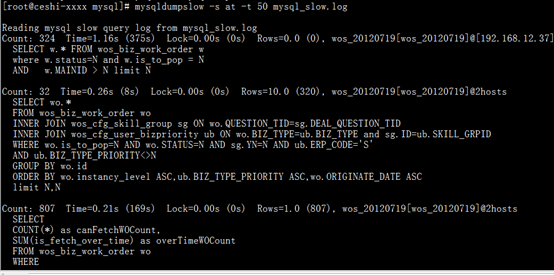
以Count: 32 Time=0.26s (8s) Lock=0.00s (0s) Rows=10.0 (320), wos_20120719[wos_20120719]@2host 为例:
Count: 32 该SQL总共执行32次
Time = 0.26s (8s) 平均每次执行该SQL耗时0.26秒,总共耗时32(次)*0.26(秒)=8秒。
Lock=0.00s(0s) lock时间0秒
Rows =10.0(320) 每次执行SQL影响数据库表中的10行记录,总共影响 10(行)*32(次)=320行记录
执行计划
在sql语句前加上explain,可以分析这条sql语句的执行情况:explain select * from teacher where cardNO=10000

select_type:
SIMPLE:简单查询
Type列可能的值(以下按效率降序排列):
Const:表中只有一个匹配行,用到primary key或unique key (性能最好)


Eq_ref:唯一性索引扫描,key的所有部分被连接联接查询使用,且key是unique或primary key
ref:非唯一性索引扫描,或只使用了联合索引的最左前缀
Range:索引范围扫描,在索引列上进行给定范围内的检索,如between,in(1,100)
Index:遍历索引...(类似于在字典上找字)
All:全表扫描(没有用索引,直接从表里面第一条找到最后一条(即使在前面或中间已经找到数据),所以项目中一般禁止使用select*和全表扫描)
所以上面就运行那条简单的sql,确很费cpu,就是因为在进行全表扫描
在工作中,一般有以下3种情况会造成sql效率低:
1.库里面没有加索引
2.加了索引,但是索引加的不合理
3.索引加的合理,但是sql写的不合理
一般,一个表里面,最多加3/4个索引,不能再多,否则就是表设计的不合理
上面那个情况就是应为没有加索引,所以,加个索引看看,
一般加索引,就看where条件的字段,用这些字段来当索引,这条sql就一个字段:cardNO

压一下看看
TPS从刚才的20多变成了300多,提升了15倍左右
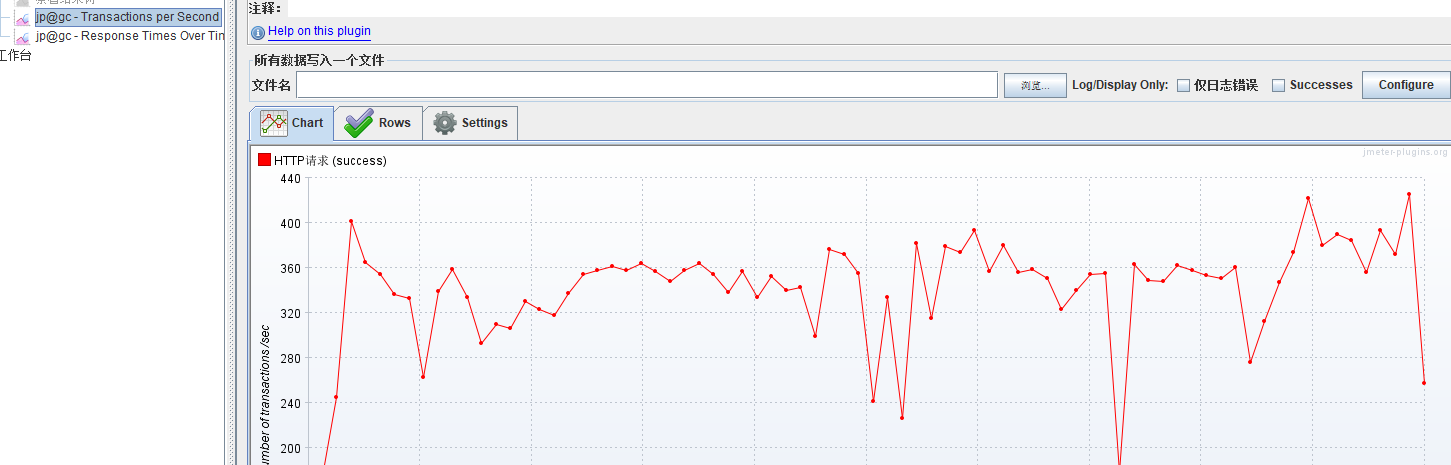
响应时间:从刚才的400左右,降到30左右
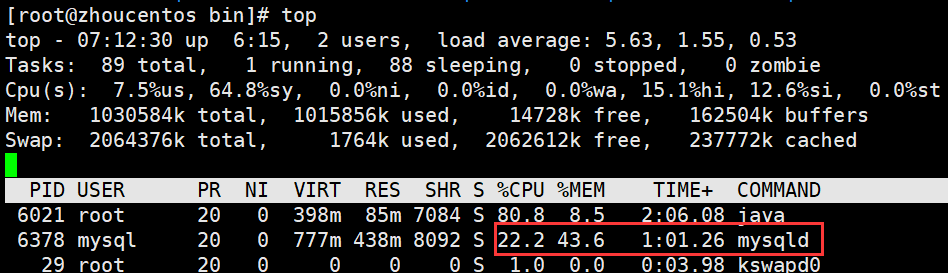
TOP命令查看,mysql只占了22.2%,一般项目中就应该是tomcat占比最高,应为它要处理业务逻辑
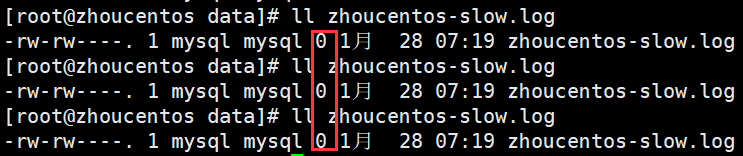
由于压测还在进行中,所以可以把慢查询的日志清空后再看看还有没有慢查询

文件大小都是0了,没有往文件里面写入内容了
3.2 Windows系统:
当你是第一次开启mysql的慢查询,会在你指定的目录下创建这个记录文件,本文就是mysqlslowquery.log,这个文件的内容大致如下(第一次开启MYSQL慢查询的情况下)
E:\web\mysql\bin\mysqld, Version: 5.4.3-beta-community-log (MySQL Community Server (GPL)). started with:
TCP Port: 3306, Named Pipe: (null)
Time Id Command Argument
可以通过如下的命令来查看慢查询的记录数:
mysql> show global status like ‘%slow%’;
+———————+——-+
| Variable_name | Value |
+———————+——-+
| Slow_launch_threads | 0 |
| Slow_queries | 0 |
+———————+——-+
性能测试四十一:sql案例之慢sql配置、执行计划和索引的更多相关文章
- SQL点滴27—性能分析之执行计划
原文:SQL点滴27-性能分析之执行计划 一直想找一些关于SQL语句性能调试的权威参考,但是有参考未必就能够做好调试的工作.我深信实践中得到的经验是最珍贵的,书本知识只是一个引导.本篇来源于<I ...
- 浅析SqlServer简单参数化模式下对sql语句自动参数化处理以及执行计划重用
我们知道,SqlServer执行sql语句的时候,有一步是对sql进行编译以生成执行计划, 在生成执行计划之前会去缓存中查找执行计划 如果执行计划缓存中有对应的执行计划缓存,那么SqlServer就会 ...
- SQL Sever 2008性能分析之执行计划
一直想找一些关于SQL语句性能调试的权威参考,但是有参考未必就能够做好调试 2的工作.我深信实践中得到的经验是最珍贵的,书本知识只是一个引导.本篇来源于<Inside Microsoft SQL ...
- SQL Server INSET/UPDATE/DELETE的执行计划
DML操作符包括增删改查等操作方式. insert into Person.Address (AddressLine1, AddressLine2, City, StateProvinceID, Po ...
- SQL Server 性能调优 之执行计划(Execution Plan)调优
SQL Server 存在三种 Join 策略:Hash Join,Merge Join,Nested Loop Join. Hash Join:用来处理没有排过序/没有索引的数据,它在内存中把 Jo ...
- SQL Server如何查看存储过程的执行计划
有时候,我们需要查看存储过程的执行计划,那么我们有什么方式获取存储过程的历史执行计划或当前的执行计划呢? 下面总结一下获取存储过程的执行计划的方法. 1:我们可以通过下面脚本查看存储过程的执行计划,但 ...
- 【测试】使用hr用户下的employees表写一条SQL语句,执行计划走索引全扫描
SQL> select count(*) from employees; COUNT(*) ---------- Execution Plan ------------------------- ...
- SQL Server如何固定执行计划
SQL Server 其实从SQL Server 2005开始,也提供了类似ORACLE中固定执行计划的功能,只是好像很少人使用这个功能.当然在SQL Server中不叫"固定执行计划&qu ...
- 基于Oracle的SQL优化(崔华著)-整理笔记-第2章“Oracle里的执行计划”
详细介绍了Oracle数据里与执行计划有关的各个方面的内容,包括执行计划的含义,加何查看执行计划,如何得到目标SQL真实的执行计划,如何查看执行计划的执行顺序,Oracle数据库里各种常见的执行计划的 ...
随机推荐
- zabbix系列 ~ 如何更好的利用mysql监控
一 简介:今天来聊聊一些关于mysql 监控需要关注的问题二 实现的原理 1 global status 2 variables 三 我们需要关注的zabbix性能图 1 事务类型 ...
- Nginx系列3:用Nginx搭建一个具备缓存功能的反向代理服务
反向代理的理解:https://www.cnblogs.com/zkfopen/p/10126105.html 我是在一台linux服务器上搭建了两个nginx服务器A和B,把静态资源文件甲放在A服务 ...
- nginx 模块配置
第一个 当前活跃的连接数 nginx握手的数 连接数 总的请求数
- nginx 目录讲解
- 20165221 JAVA第四周学习心得
教材内容总结 子类与继承 子类与父类 定义的标准格式为 class 子类名 extends 父类名 { ... } 如果一个类的声明中,没有使用extends关键字,则默认为Object类. 子类的继 ...
- 20165231 预备作业二:学习基础和C语言基础调查
微信文章感想 读了娄老师微信公众号中的文章,老师给我们的启示首先就是要坚持,万事开头难,但是只要肯坚持就一定会有所成就,不管是学习还是生活方面.其中最有触动的就是减肥了,是我三四年来一直难以完成的目标 ...
- python之async-timeout模块
async-timeout 兼容async的超时的上下文管理器 async-timeout的timeout和asyncio的wiat_for比较 首先从使用上来说asyncio.wait_for(aw ...
- STL中vector、list、deque和map的区别
1 vector 向量 相当于一个数组 在内存中分配一块连续的内存空间进行存储.支持不指定vector大小的存储.STL内部实现时,首先分配一个非常大的内存空间预备进行存储,即capac ...
- Codeforces 1091E New Year and the Acquaintance Estimation Erdős–Gallai定理
题目链接:E - New Year and the Acquaintance Estimation 题解参考: Havel–Hakimi algorithm 和 Erdős–Gallai theore ...
- 牛客国庆训练,CCPC Camp DAY1 J 倍增,括号匹配
https://www.nowcoder.com/acm/contest/201#question 题意:中文不翻译了 解法的个人理解: 对于一个合法的区间$[L,R]$ 1.显然其左括号的匹配位置都 ...