[转] Torch中实现mini-batch RNN
工作中需要把一个SGD的LSTM改造成mini-batch的LSTM, 两篇比较有用的博文,转载mark
https://zhuanlan.zhihu.com/p/34418001
http://www.cnblogs.com/lindaxin/p/8052043.html
一、为什么RNN需要处理变长输入
假设我们有情感分析的例子,对每句话进行一个感情级别的分类,主体流程大概是下图所示:
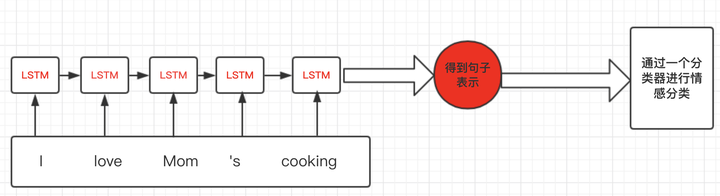
思路比较简单,但是当我们进行batch个训练数据一起计算的时候,我们会遇到多个训练样例长度不同的情况,这样我们就会很自然的进行padding,将短句子padding为跟最长的句子一样。
比如向下图这样:
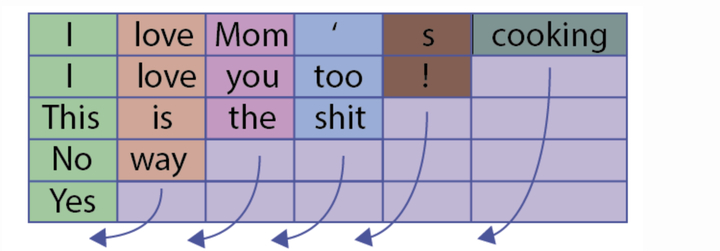
但是这会有一个问题,什么问题呢?比如上图,句子“Yes”只有一个单词,但是padding了5的pad符号,这样会导致LSTM对它的表示通过了非常多无用的字符,这样得到的句子表示就会有误差,更直观的如下图:
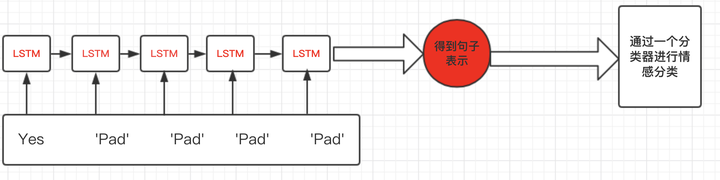
那么我们正确的做法应该是怎么样呢?
这就引出pytorch中RNN需要处理变长输入的需求了。在上面这个例子,我们想要得到的表示仅仅是LSTM过完单词"Yes"之后的表示,而不是通过了多个无用的“Pad”得到的表示:如下图:
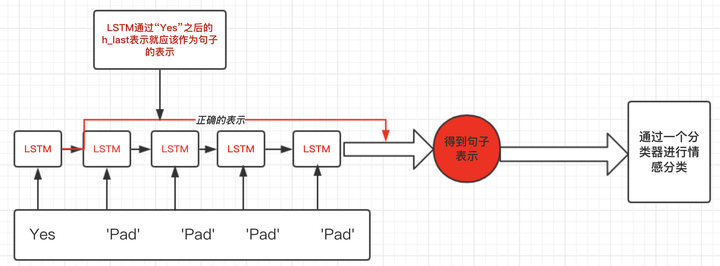
二、pytorch中RNN如何处理变长padding
主要是用函数torch.nn.utils.rnn.pack_padded_sequence()以及torch.nn.utils.rnn.pad_packed_sequence()来进行的,分别来看看这两个函数的用法。
这里的pack,理解成压紧比较好。 将一个 填充过的变长序列 压紧。(填充时候,会有冗余,所以压紧一下)
输入的形状可以是(T×B×* )。T是最长序列长度,B是batch size,*代表任意维度(可以是0)。如果batch_first=True的话,那么相应的 input size 就是 (B×T×*)。
Variable中保存的序列,应该按序列长度的长短排序,长的在前,短的在后(特别注意需要进行排序)。即input[:,0]代表的是最长的序列,input[:, B-1]保存的是最短的序列。
参数说明:
input (Variable) – 变长序列 被填充后的 batch
lengths (list[int]) – Variable 中 每个序列的长度。(知道了每个序列的长度,才能知道每个序列处理到多长停止)
batch_first (bool, optional) – 如果是True,input的形状应该是B*T*size。
返回值:
一个PackedSequence 对象。一个PackedSequence表示如下所示:
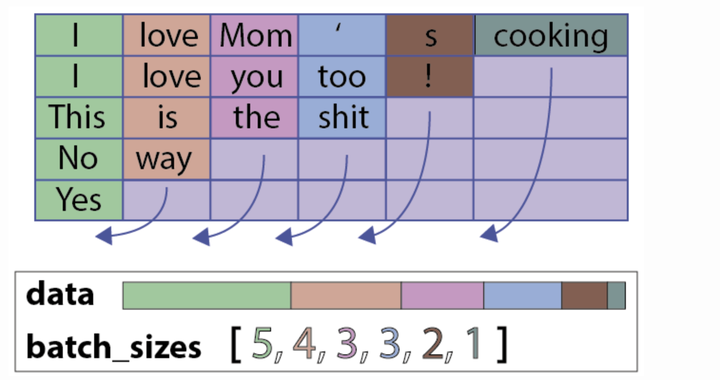
具体代码如下:
embed_input_x_packed = pack_padded_sequence(embed_input_x, sentence_lens, batch_first=True)
encoder_outputs_packed, (h_last, c_last) = self.lstm(embed_input_x_packed)
此时,返回的h_last和c_last就是剔除padding字符后的hidden state和cell state,都是Variable类型的。代表的意思如下(各个句子的表示,lstm只会作用到它实际长度的句子,而不是通过无用的padding字符,下图用红色的打钩来表示):
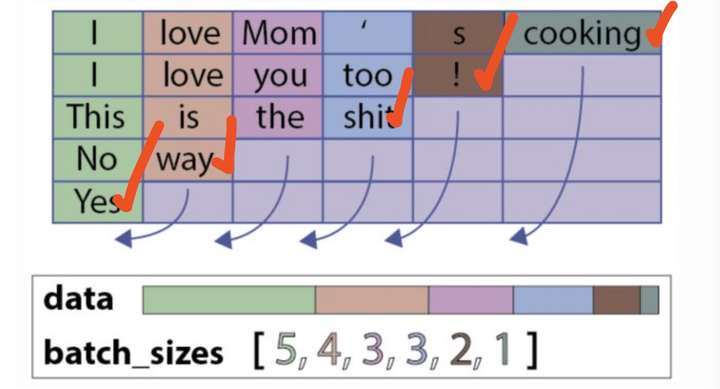
但是返回的output是PackedSequence类型的,可以使用:
encoder_outputs, _ = pad_packed_sequence(encoder_outputs_packed, batch_first=True)
将encoderoutputs在转换为Variable类型,得到的_代表各个句子的长度。
三、总结
这样综上所述,RNN在处理类似变长的句子序列的时候,我们就可以配套使用torch.nn.utils.rnn.pack_padded_sequence()以及torch.nn.utils.rnn.pad_packed_sequence()来避免padding对句子表示的影响
PackedSequence对象有一个很不错的特性,就是我们无需对序列解包(这一步操作非常慢)即可直接在PackedSequence数据变量上执行许多操作。特别是我们可以对令牌执行任何操作(即对令牌的顺序/上下文不敏感)。当然,我们也可以使用接受PackedSequence作为输入的任何一个pyTorch模块(pyTorch 0.2)。
2、torch.nn.utils.rnn.pack_padded_sequence()
这里的pack,理解成压紧比较好。 将一个 填充过的变长序列 压紧。(填充时候,会有冗余,所以压紧一下)
输入的形状可以是(T×B×* )。T是最长序列长度,B是batch size,*代表任意维度(可以是0)。如果batch_first=True的话,那么相应的 input size 就是 (B×T×*)。
Variable中保存的序列,应该按序列长度的长短排序,长的在前,短的在后。即input[:,0]代表的是最长的序列,input[:, B-1]保存的是最短的序列。
NOTE: 只要是维度大于等于2的input都可以作为这个函数的参数。你可以用它来打包labels,然后用RNN的输出和打包后的labels来计算loss。通过PackedSequence对象的.data属性可以获取 Variable。
参数说明:
input (Variable) – 变长序列 被填充后的 batch
lengths (list[int]) –
Variable中 每个序列的长度。batch_first (bool, optional) – 如果是
True,input的形状应该是B*T*size。
返回值:
一个PackedSequence 对象。
3、torch.nn.utils.rnn.pad_packed_sequence()
填充packed_sequence。
上面提到的函数的功能是将一个填充后的变长序列压紧。 这个操作和pack_padded_sequence()是相反的。把压紧的序列再填充回来。
返回的Varaible的值的size是 T×B×*, T 是最长序列的长度,B 是 batch_size,如果 batch_first=True,那么返回值是B×T×*。
Batch中的元素将会以它们长度的逆序排列。
参数说明:
sequence (PackedSequence) – 将要被填充的 batch
batch_first (bool, optional) – 如果为True,返回的数据的格式为
B×T×*。
返回值: 一个tuple,包含被填充后的序列,和batch中序列的长度列表。
例子:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
import torchimport torch.nn as nnfrom torch.autograd import Variablefrom torch.nn import utils as nn_utilsbatch_size = 2max_length = 3hidden_size = 2n_layers =1tensor_in = torch.FloatTensor([[1, 2, 3], [1, 0, 0]]).resize_(2,3,1)tensor_in = Variable( tensor_in ) #[batch, seq, feature], [2, 3, 1]seq_lengths = [3,1] # list of integers holding information about the batch size at each sequence step# pack itpack = nn_utils.rnn.pack_padded_sequence(tensor_in, seq_lengths, batch_first=True)# initializernn = nn.RNN(1, hidden_size, n_layers, batch_first=True)h0 = Variable(torch.randn(n_layers, batch_size, hidden_size))#forwardout, _ = rnn(pack, h0)# unpackunpacked = nn_utils.rnn.pad_packed_sequence(out)print('111',unpacked) |
输出:
|
1
2
3
4
5
6
7
8
9
10
|
111 (Variable containing:(0 ,.,.) = 0.5406 0.3584 -0.1403 0.0308(1 ,.,.) = -0.6855 -0.9307 0.0000 0.0000[torch.FloatTensor of size 2x2x2], [2, 1]) |
[转] Torch中实现mini-batch RNN的更多相关文章
- 转载: scikit-learn学习之K-means聚类算法与 Mini Batch K-Means算法
版权声明:<—— 本文为作者呕心沥血打造,若要转载,请注明出处@http://blog.csdn.net/gamer_gyt <—— 目录(?)[+] ================== ...
- (原)torch中微调某层参数
转载请注明出处: http://www.cnblogs.com/darkknightzh/p/6221664.html 参考网址: https://github.com/torch/nn/issues ...
- Deep Learning中的Large Batch Training相关理论与实践
背景 [作者:DeepLearningStack,阿里巴巴算法工程师,开源TensorFlow Contributor] 在分布式训练时,提高计算通信占比是提高计算加速比的有效手段,当网络通信优化到一 ...
- Batch Normalization原理及其TensorFlow实现——为了减少深度神经网络中的internal covariate shift,论文中提出了Batch Normalization算法,首先是对”每一层“的输入做一个Batch Normalization 变换
批标准化(Bactch Normalization,BN)是为了克服神经网络加深导致难以训练而诞生的,随着神经网络深度加深,训练起来就会越来越困难,收敛速度回很慢,常常会导致梯度弥散问题(Vanish ...
- (原)torch中threads的addjob函数使用方法
转载请注明出处: http://www.cnblogs.com/darkknightzh/p/6549452.html 参考网址: https://github.com/torch/threads#e ...
- torch中的多线程threads学习
torch中的多线程threads学习 torch threads threads 包介绍 threads package的优势点: 程序中线程可以随时创建 Jobs被以回调函数的形式提交给线程系统, ...
- 如何在ASP.NET Core Web API中使用Mini Profiler
原文如何在ASP.NET Core Web API中使用Mini Profiler 由Anuraj发表于2019年11月25日星期一阅读时间:1分钟 ASPNETCoreMiniProfiler 这篇 ...
- 聚类K-Means和大数据集的Mini Batch K-Means算法
import numpy as np from sklearn.datasets import make_blobs from sklearn.cluster import KMeans from s ...
- torch中的copy()和clone()
torch中的copy()和clone() 1.torch中的copy()和clone() y = torch.Tensor(2,2):copy(x) ---1 修改y并不改变原来的x y = x:c ...
- torch中squeeze与unsqueeze用法
import torch torch中的squeeze与unsqueeze作用是去除/添加维度为1的行 例如,a=torch.randn(2,3) 那么b=a.unsqueeze(0),b为(1,2, ...
随机推荐
- STM32F407 ------ 使用定时器实现精确延时
测试环境:主频168M #include "delay.h" void delay_init() { TIM_TimeBaseInitTypeDef TIM_TimeBaseStr ...
- 使用Redis模拟简单分布式锁,解决单点故障的问题
需求描述: 最近做一个项目,项目中有一个功能,每天定时(凌晨1点)从数据库中获取需要爬虫的URL,并发送到对应的队列中,然后客户端监听对应的队列,然后执行任务.如果同时部署多个定时任务节点的话,每个节 ...
- continue #结束本次循环进行下次循环
#!/user/bin/python# -*- coding:utf-8 -*-print(111)while True: print(222) print(333) continue #结束本次循环 ...
- 信用评分卡 (part 7 of 7)
python信用评分卡(附代码,博主录制) https://study.163.com/course/introduction.htm?courseId=1005214003&utm_camp ...
- MY服务器架设
研究了一天,终于弄出来了,进游戏耍了会,感觉不错,下面分享架设步骤给大家 分享端的大大也出了个虚拟机运行需要注意的视频,大家看看吧,我就这样弄架设成功了 链接:链接: http://pan.baidu ...
- Jmeter测试报告生成
Jmeter测试报告生成 本文使用的 Jmeter 版本为 apache-jmeter-3.2 1. 命令行模式将 jtl 文件转成测试图表 注意: 这种方式只适用于jmeter3.0以后的版本 1. ...
- HTTP.SYS远程执行代码漏洞分析 (MS15-034 )
写在前言: 在2015年4月安全补丁日,微软发布了11项安全更新,共修复了包括Microsoft Windows.Internet Explorer.Office..NET Framework.S ...
- Windows Server 2008 R2中无法使用360免费Wifi的解决方案
为了使主机和虚拟机在同一个无线网络中,而虚拟机的系统是Windows Server 2008 R2 64位的,使用360免费wifi,始终无法开启.在网上查找解决方案,终于找到了原因:Windows ...
- 大规模数据导入和导出(sqlserver)
请期待... https://docs.microsoft.com/en-us/sql/linux/sql-server-linux-setup-tools#RHEL msodbcsql-13.1.6 ...
- c++过程
<<C++ beginner >> 入门 <<C++ primer>> 基础 <<The C++ programming language ...