Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
本文主要是记录一写我在学习MapReduce时的一些琐碎的学习笔记, 方便自己以后查看。在调用API的时候,可能会需要maven依赖,添加依赖的包如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>HADOOP</artifactId>
<groupId>yinzhengjie.org.cn</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion> <artifactId>MapReduce</artifactId> <dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency> <dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency> </dependencies> </project>
一.MapReduce定义
Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架。
Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上。
二.MapReduce优点
1>.MapReduce 易于编程。
它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的PC机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得MapReduce编程变得非常流行。
2>.良好的扩展性。
当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。
3>.高容错性。
MapReduce设计的初衷就是使程序能够部署在廉价的PC机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由 Hadoop内部完成的。
4>.适合PB级以上海量数据的离线处理。
它适合离线处理而不适合在线处理。比如像毫秒级别的返回一个结果,MapReduce很难做到。
三.MapReduce缺点
MapReduce不擅长做实时计算、流式计算、DAG(有向图)计算。
1>.实时计算。
MapReduce无法像Mysql一样,在毫秒或者秒级内返回结果。
2>.流式计算。
流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的。
3>.DAG(有向图)计算。
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce并不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入到磁盘,会造成大量的磁盘IO,导致性能非常的低下。
四.MapReduce进程
一个完整的mapreduce程序在分布式运行时有三类实例进程:
1>.MrAppMaster:
负责整个程序的过程调度及状态协调。
2>.MapTask:
负责map阶段的整个数据处理流程。
3>.ReduceTask:
负责reduce阶段的整个数据处理流程。
五.MapReduce编程规范
用户编写的程序分成三个部分:Mapper,Reducer,Driver(提交运行mr程序的客户端)
1>.Mapper阶段
(1)用户自定义的Mapper要继承自己的父类
(2)Mapper的输入数据是KV对的形式(KV的类型可自定义)
(3)Mapper中的业务逻辑写在map()方法中
(4)Mapper的输出数据是KV对的形式(KV的类型可自定义)
(5)map()方法(maptask进程)对每一个<K,V>调用一次
2>.Reducer阶段
(1)用户自定义的Reducer要继承自己的父类
(2)Reducer的输入数据类型对应Mapper的输出数据类型,也是KV
(3)Reducer的业务逻辑写在reduce()方法中
(4)Reducetask进程对每一组相同k的<k,v>组调用一次reduce()方法
3>.Driver阶段
整个程序需要一个Drvier来进行提交,提交的是一个描述了各种必要信息的job对象
六.Hadoop序列化
1>.为什么要序列化?
一般来说,“活的”对象只生存在内存里,关机断电就没有了。而且“活的”对象只能由本地的进程使用,不能被发送到网络上的另外一台计算机。 然而序列化可以存储“活的”对象,可以将“活的”对象发送到远程计算机。
2>.什么是序列化?
序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储(持久化)和网络传输。
反序列化就是将收到字节序列(或其他数据传输协议)或者是硬盘的持久化数据,转换成内存中的对象。
3>.为什么不用Java的序列化?
ava的序列化是一个重量级序列化框架(Serializable),一个对象被序列化后,会附带很多额外的信息(各种校验信息,header,继承体系等),不便于在网络中高效传输。所以,hadoop自己开发了一套序列化机制(Writable),精简、高效。
4>.为什么序列化对Hadoop很重要?
因为Hadoop在集群之间进行通讯或者RPC调用的时候,需要序列化,而且要求序列化要快,且体积要小,占用带宽要小。所以必须理解Hadoop的序列化机制。
序列化和反序列化在分布式数据处理领域经常出现:进程通信和永久存储。然而Hadoop中各个节点的通信是通过远程调用(RPC)实现的,那么RPC序列化要求具有以下特点:
(1)紧凑:紧凑的格式能让我们充分利用网络带宽,而带宽是数据中心最稀缺的资
(2)快速:进程通信形成了分布式系统的骨架,所以需要尽量减少序列化和反序列化的性能开销,这是基本的;
(3)可扩展:协议为了满足新的需求变化,所以控制客户端和服务器过程中,需要直接引进相应的协议,这些是新协议,原序列化方式能支持新的协议报文;
(4)互操作:能支持不同语言写的客户端和服务端进行交互;
(5).常用数据序列化类型
5>.常用的数据类型对应的hadoop数据序列化类型

七.MapReduce案例实操
1>.编写mapper类
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/
EMAIL:y1053419035@qq.com
*/
package mapreduce.yinzhengjie.org.cn; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ Text k = new Text();
IntWritable v = new IntWritable(1); @Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException { // 1 获取一行
String line = value.toString(); // 2 切割
String[] words = line.split(" "); // 3 输出
for (String word : words) { k.set(word);
context.write(k, v);
}
}
}
2>.编写Reduce类
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/
EMAIL:y1053419035@qq.com
*/
package mapreduce.yinzhengjie.org.cn; import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override
protected void reduce(Text key, Iterable<IntWritable> value,
Context context) throws IOException, InterruptedException { // 1 累加求和
int sum = 0;
for (IntWritable count : value) {
sum += count.get();
} // 2 输出
context.write(key, new IntWritable(sum));
}
}
3>.编写驱动类
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/
EMAIL:y1053419035@qq.com
*/
package mapreduce.yinzhengjie.org.cn; import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordcountDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
/**
* 配合Hadoop的环境变量,如果没有配置可能会抛异常:“ERROR util.Shell: Failed to locate the winutils binary in the hadoop binary path”,
* 还有一件事就是你的HADOOP_HOME的bin目录下必须得有winutils.exe
*
*/
System.setProperty("hadoop.home.dir", "D:\\yinzhengjie\\softwares\\hadoop-2.7.3"); //获取配置信息
Configuration conf = new Configuration();
Job job = Job.getInstance(conf); //设置jar加载路径
job.setJarByClass(WordcountDriver.class); //设置map和Reduce类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class); //设置map输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); //设置Reduce输出
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); //设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); //等待job提交完毕
boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1);
}
}
八.本地测试
1>.在代码中配置HADOOP_HOME的环境变量
System.setProperty("hadoop.home.dir", "D:\\yinzhengjie\\softwares\\hadoop-2.7.3");
2>.在resources目录下生成"log4j.properties"配置文件
log4j.rootLogger=${hadoop.root.logger}
hadoop.root.logger=INFO,console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{}: %m%n
3>.点击驱动类的配置文件,如下图的"Edit Configurations...."
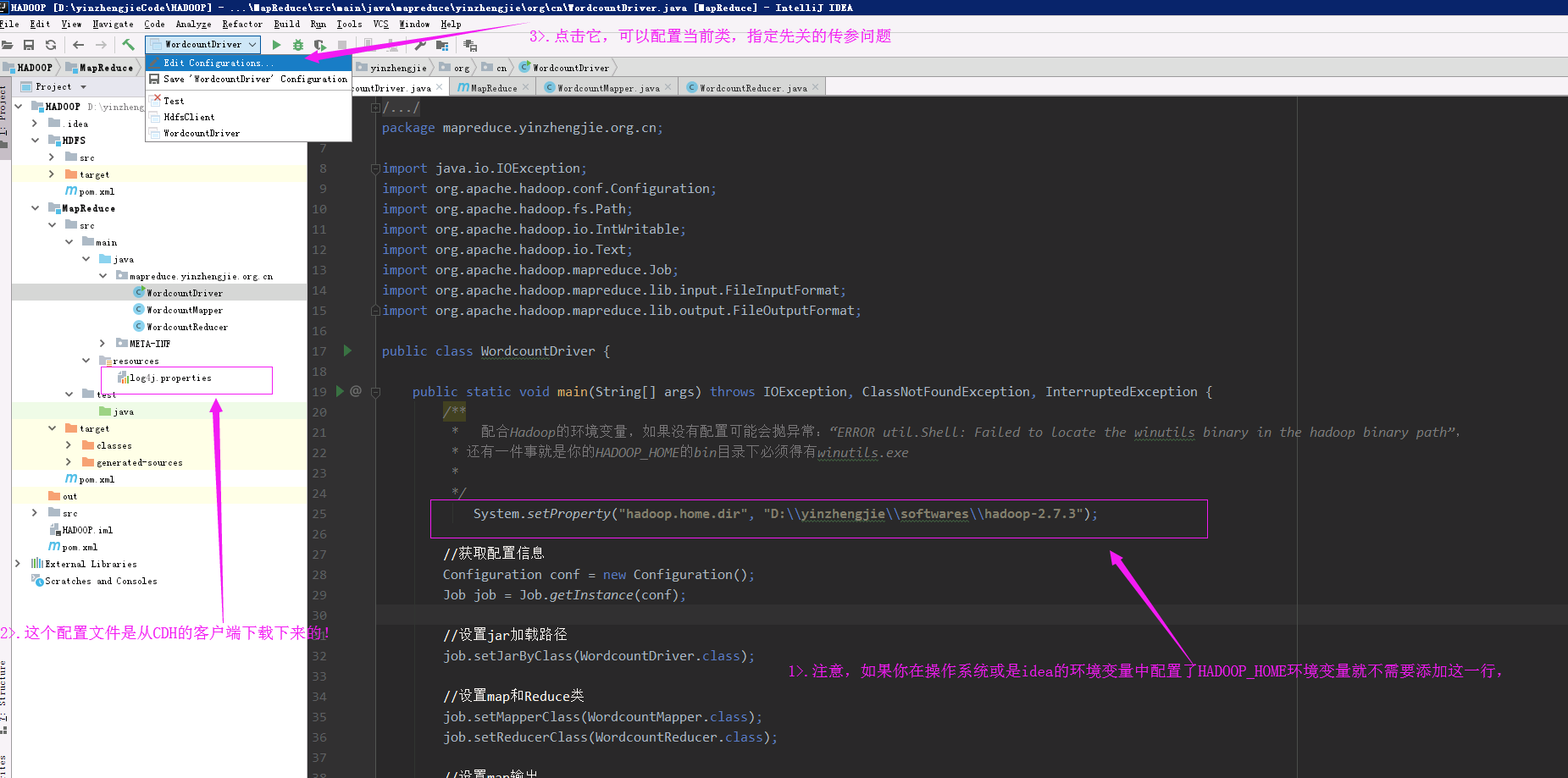
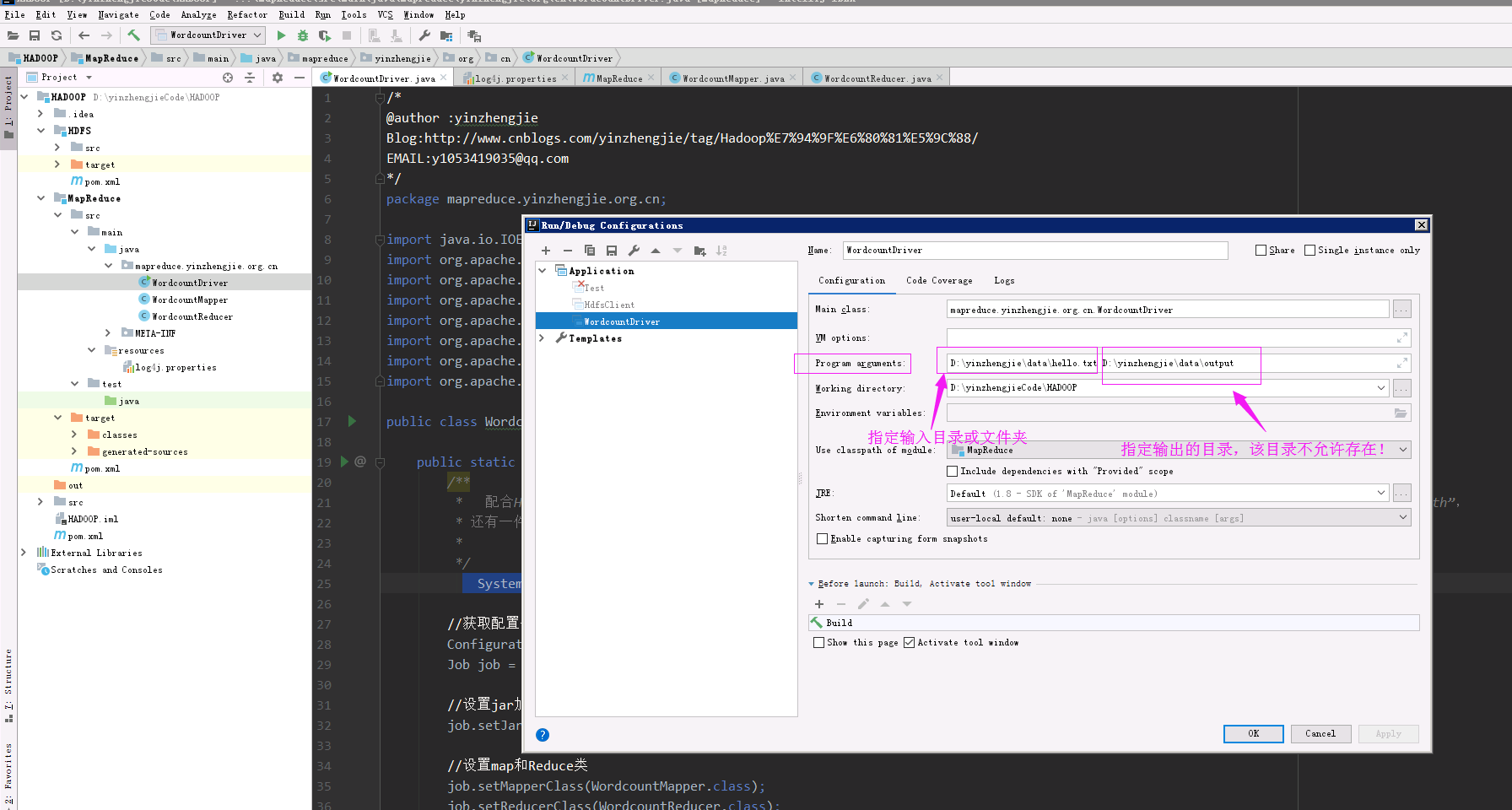
4>.编辑“Program arguments”的输入和输出路径(注意,输入路径必须存在,输出路径的目录必须不存在!)
Apache Hive is an open source project run by volunteers at the Apache Software Foundation.
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
Use Apache HBase when you need random, realtime read/write access to your Big Data. This project's goal is the hosting of very
large tables -- billions of rows X millions of columns -- atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google's Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application.
Apache Spark is a unified analytics engine for large-scale data processing.
D:\yinzhengjie\data\hello.txt 文件内容戳我!!!!
5>.运行“WordcountDriver.java”程序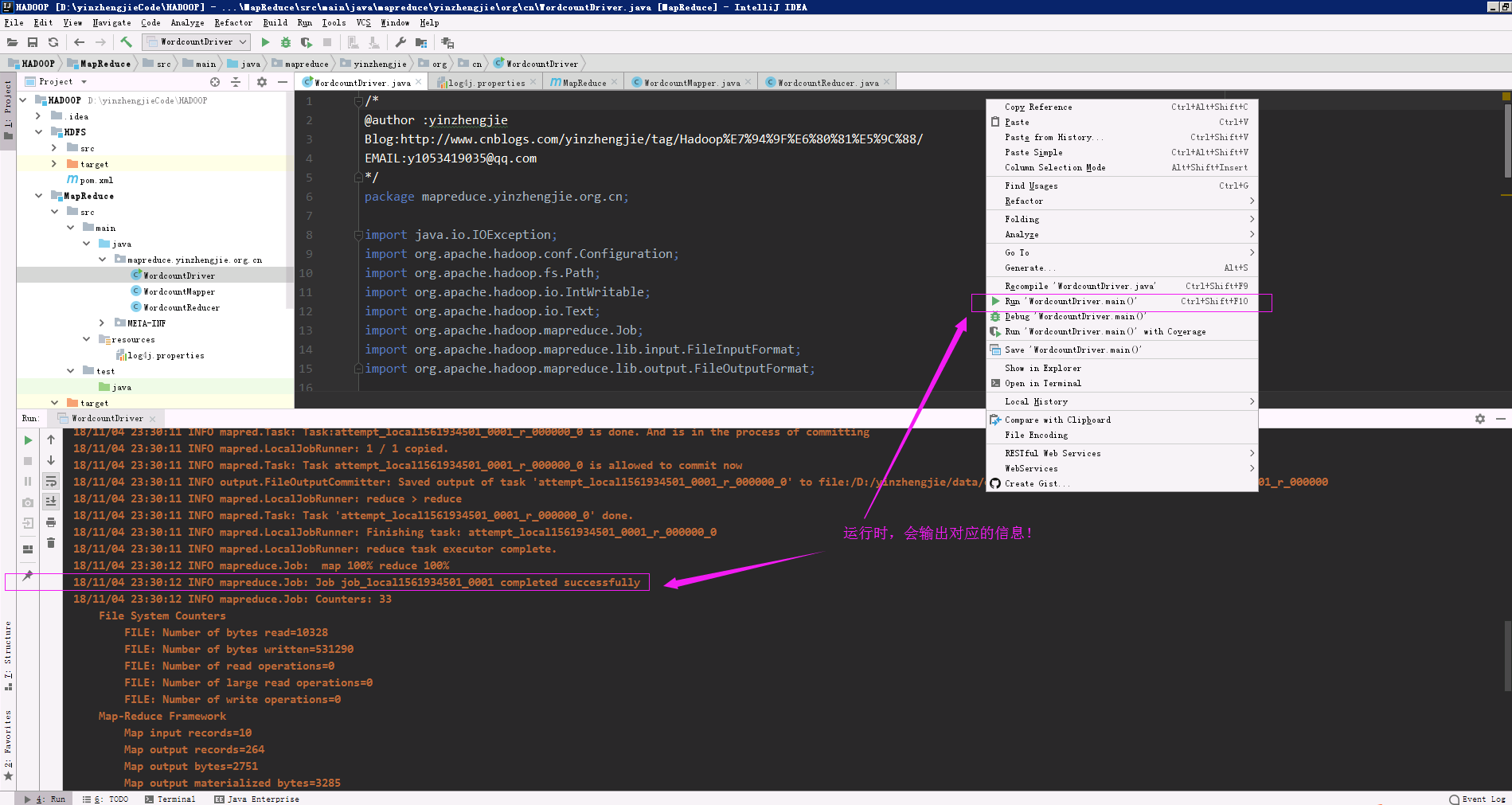
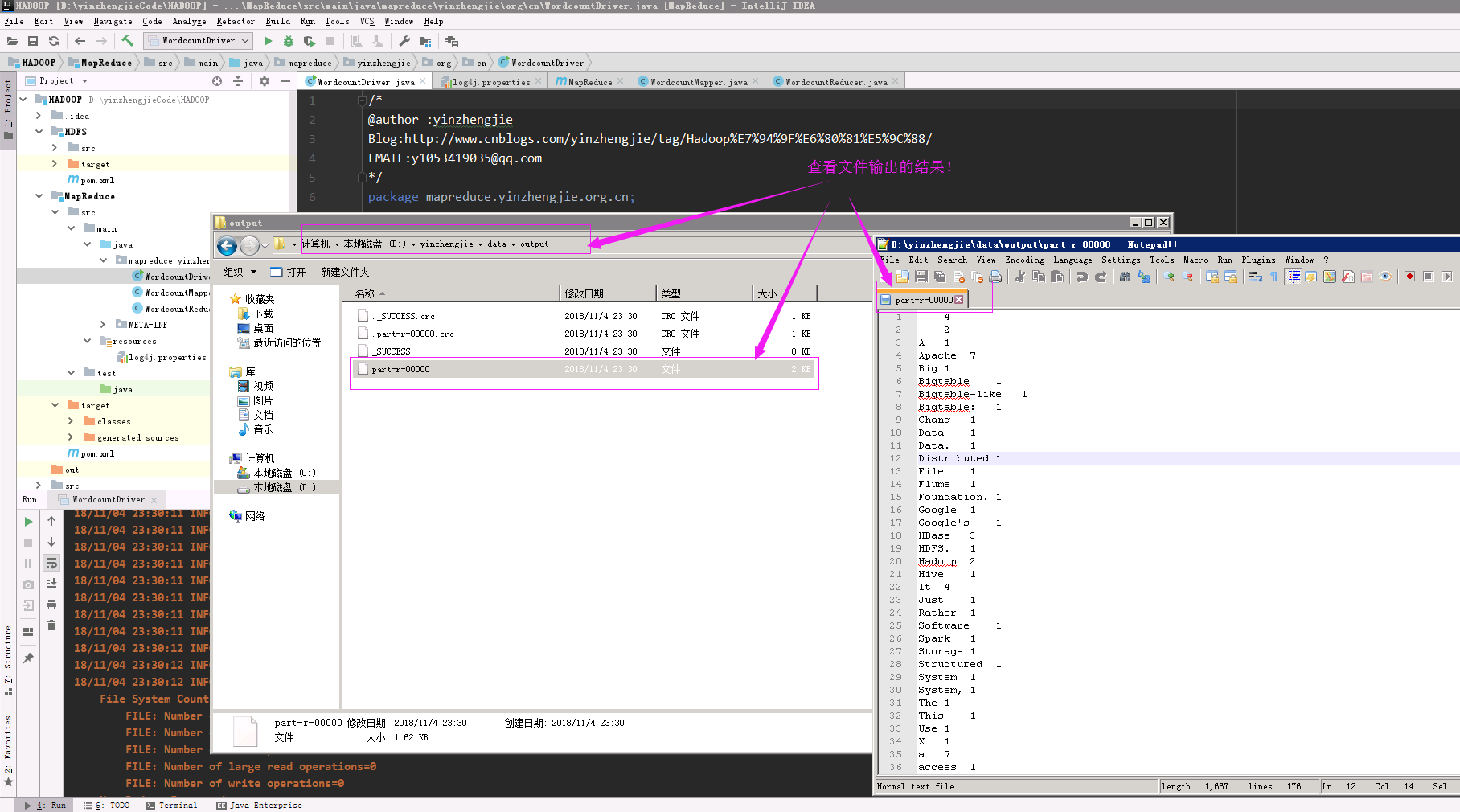
6>.查看输出的结果
九.集群测试
1>.删除代码中指定的Windows中HADOOP_HOME的代码,并点击当前模块的设置,即下图中的“Open Module Setting”。
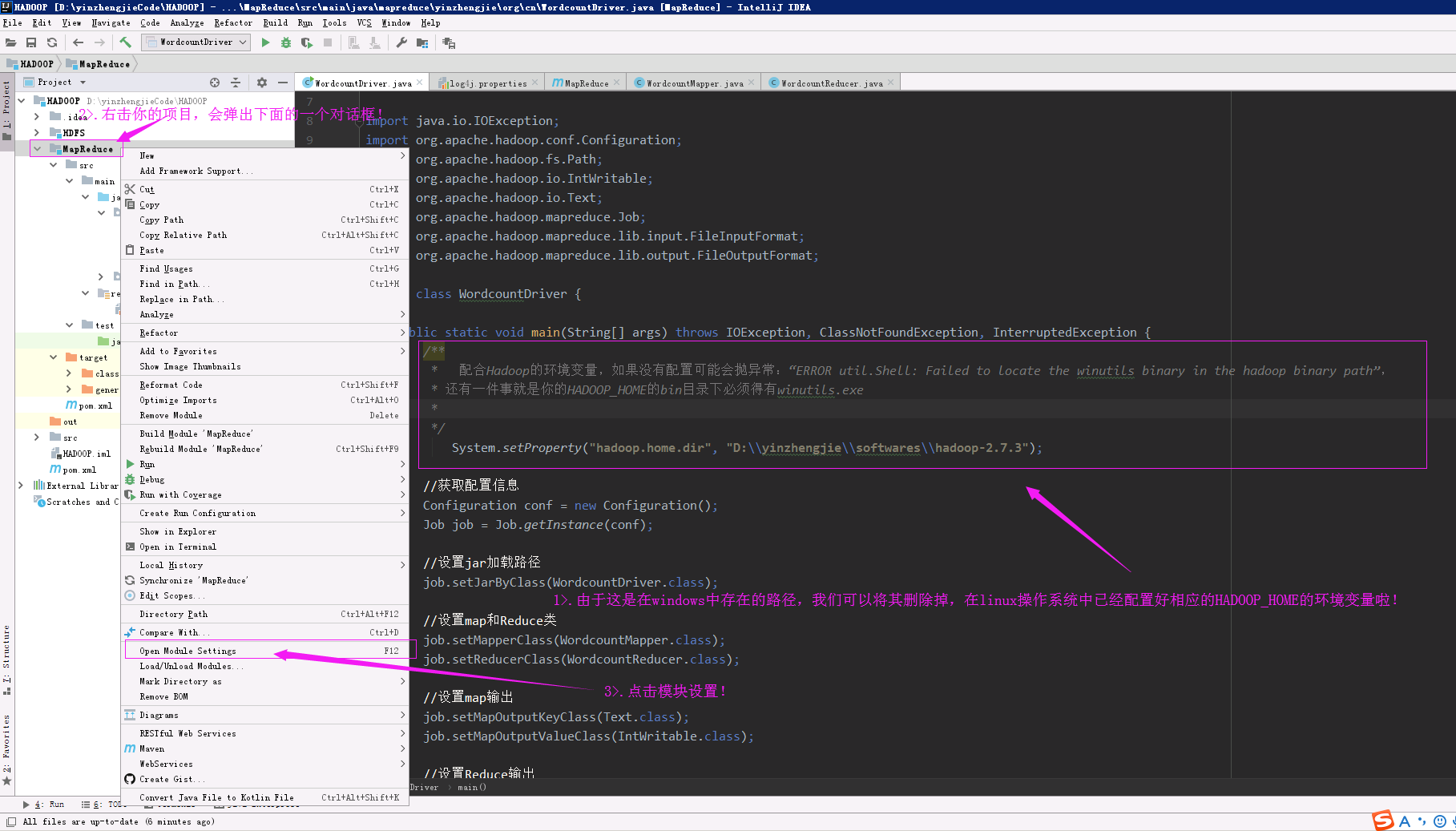
2>.添加"Artifacts"
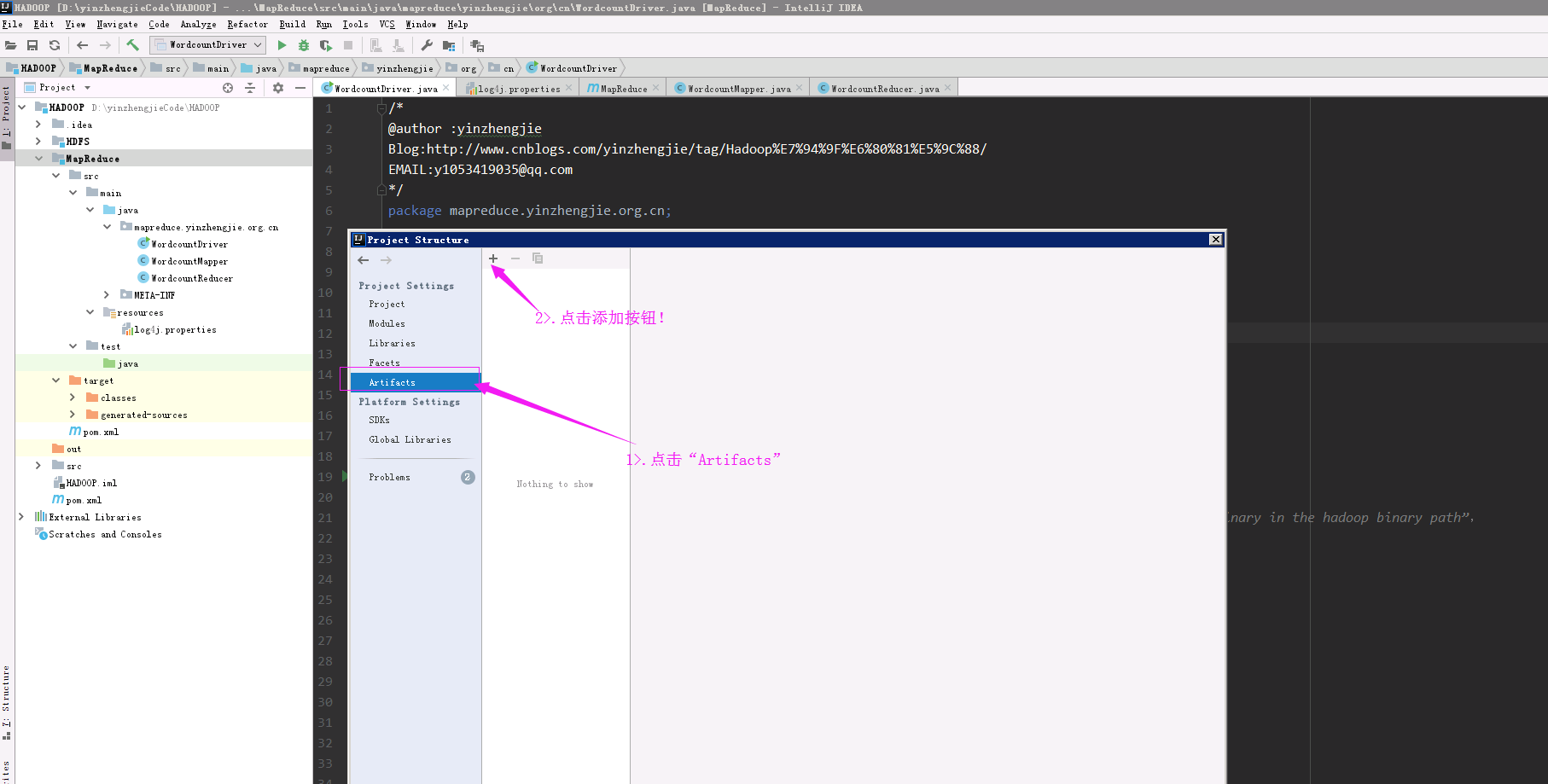
3>.选择jar,点击“From modules with dependencies....”
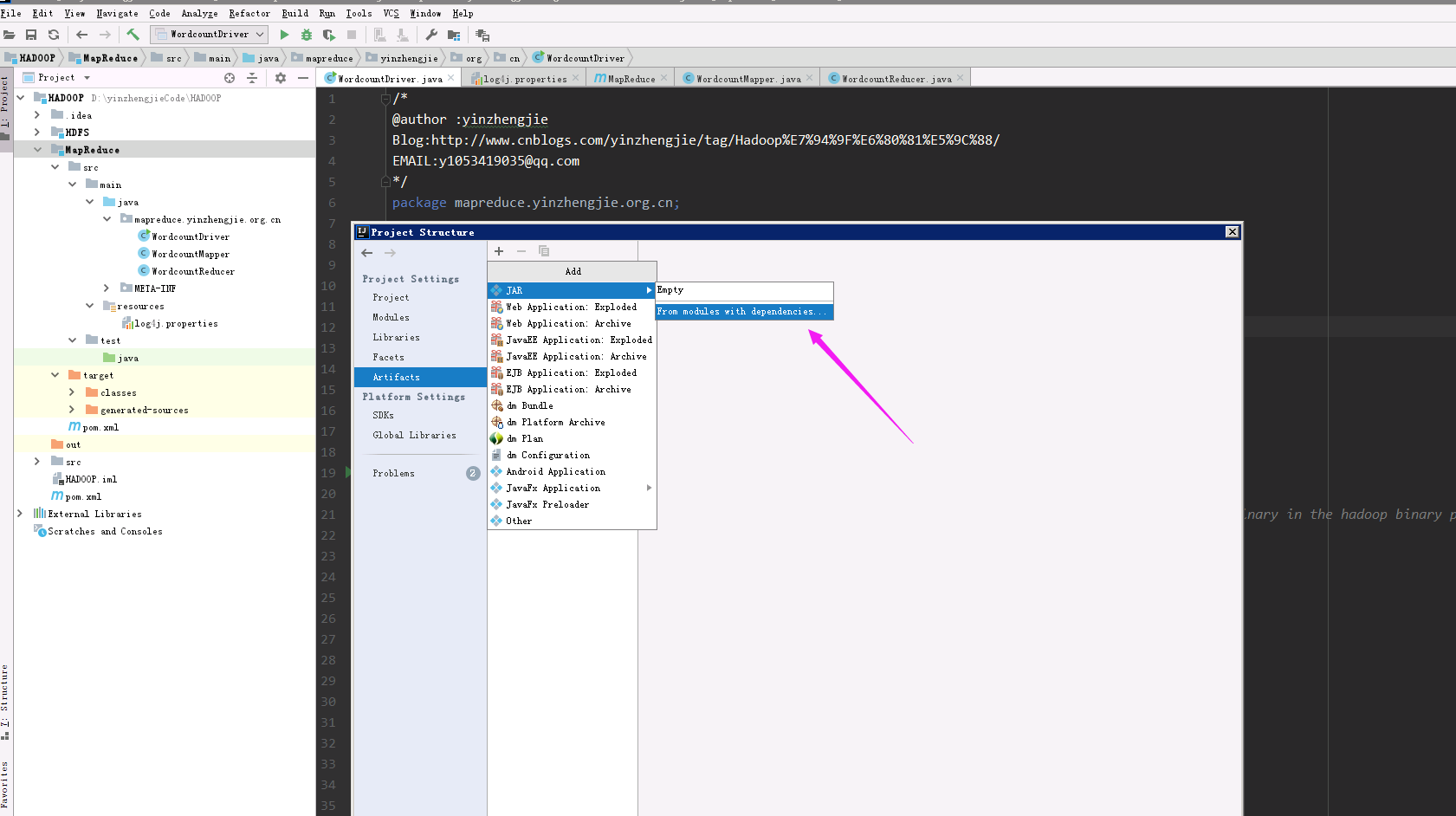
4>.选择需要打包的Module和Main Class
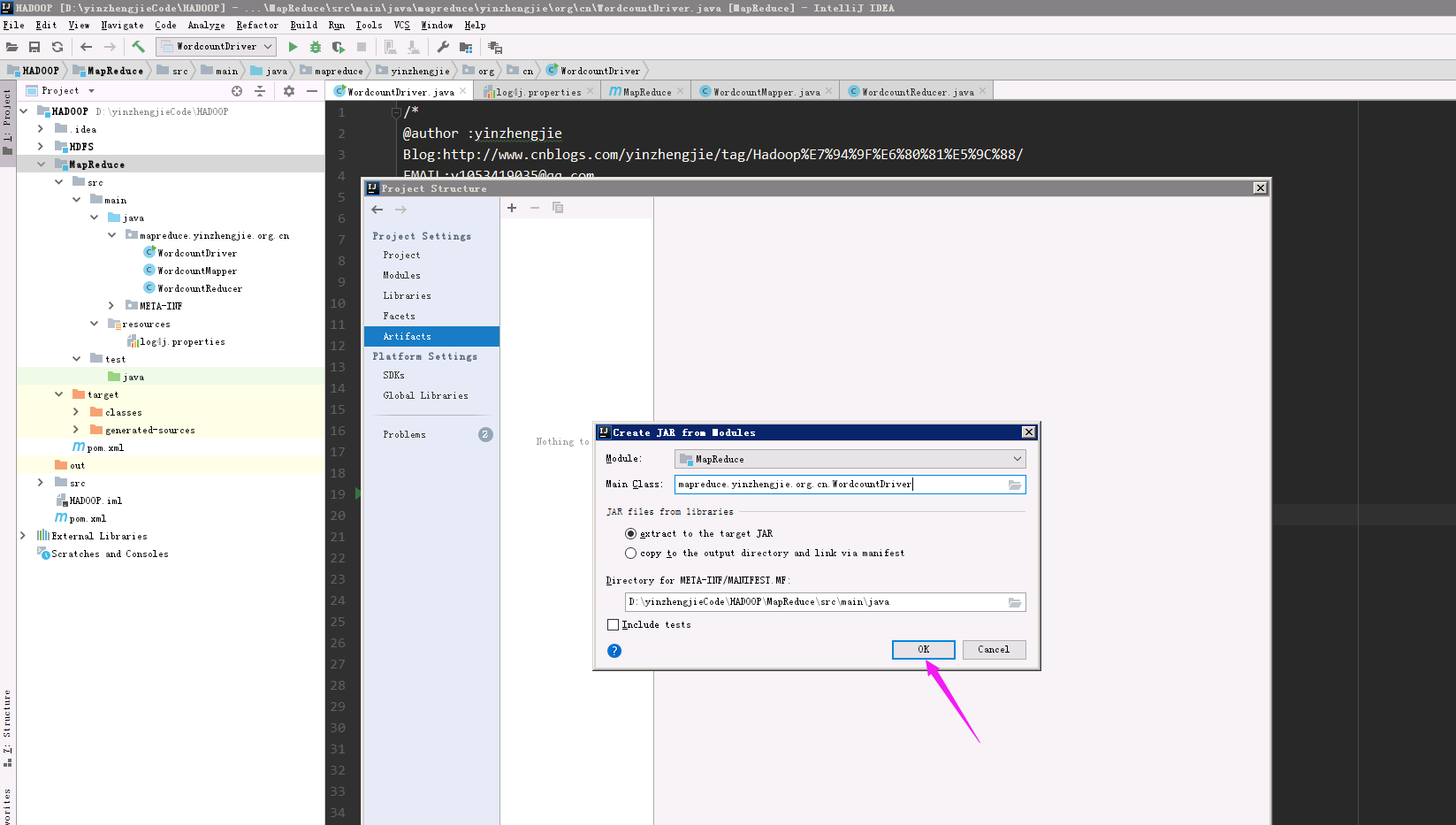
5>.完成配置
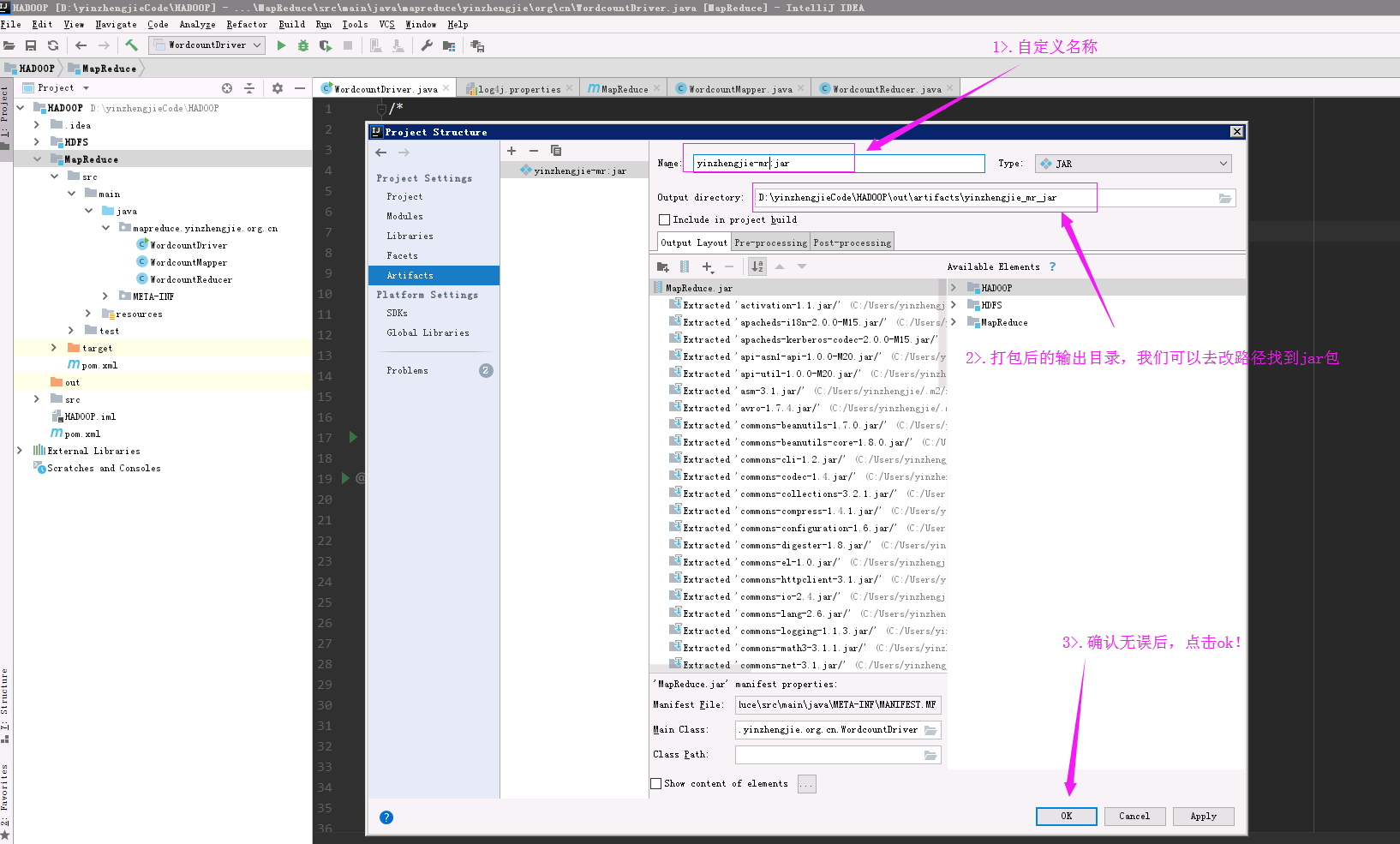
6>.点击菜单栏的“Build”标签,选择“Build Artifacts...”
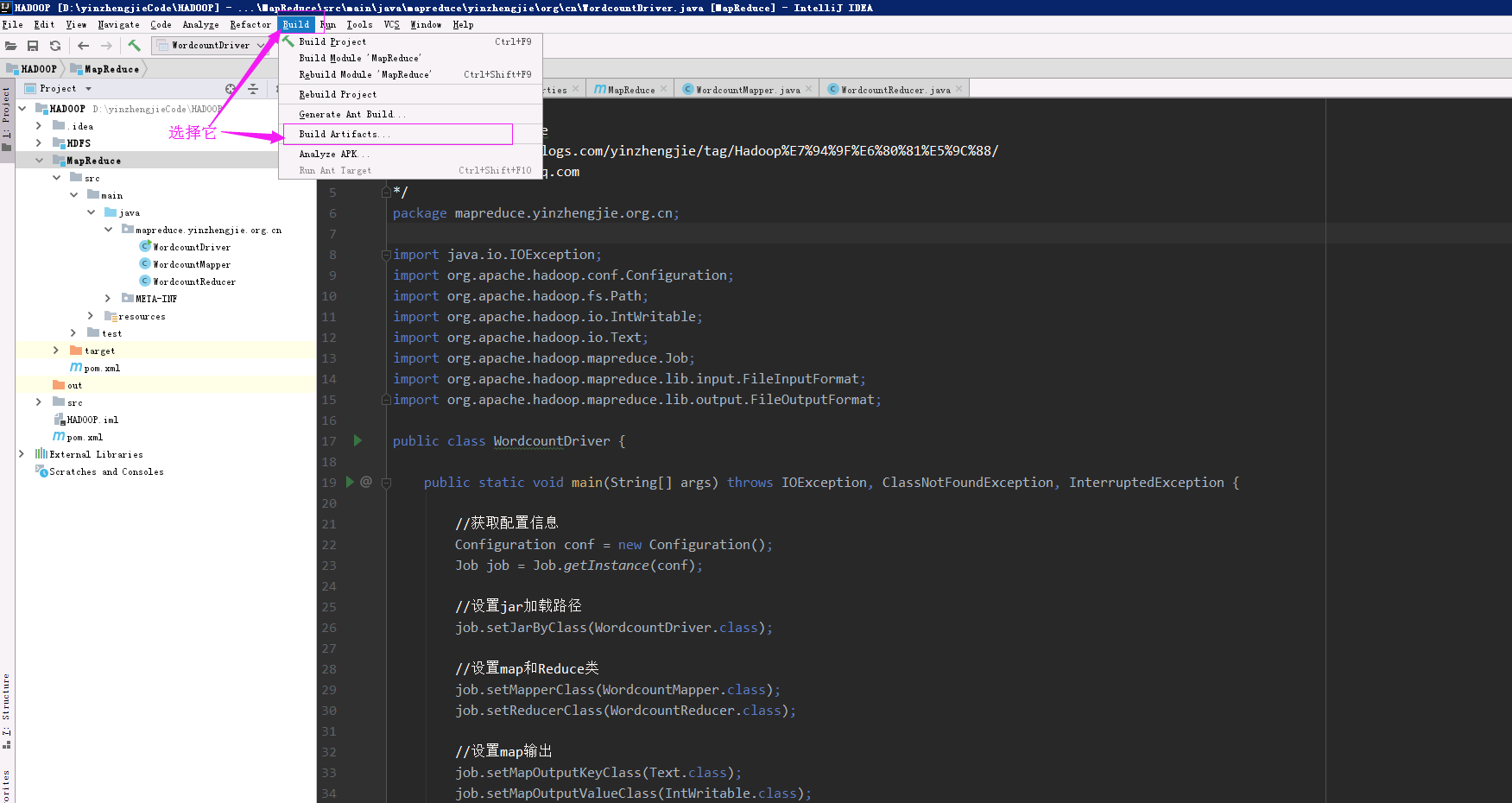
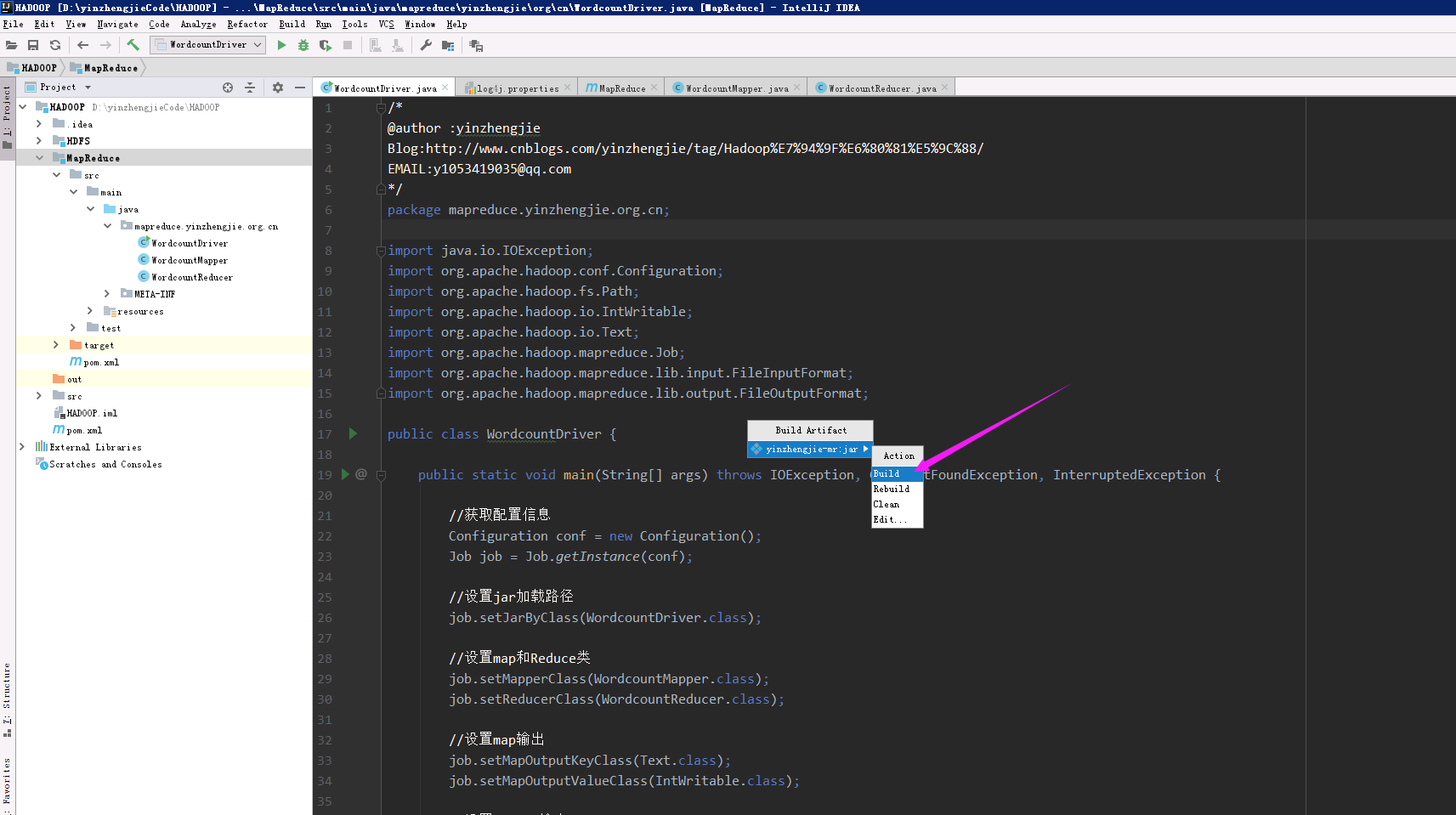
7>.点击Build
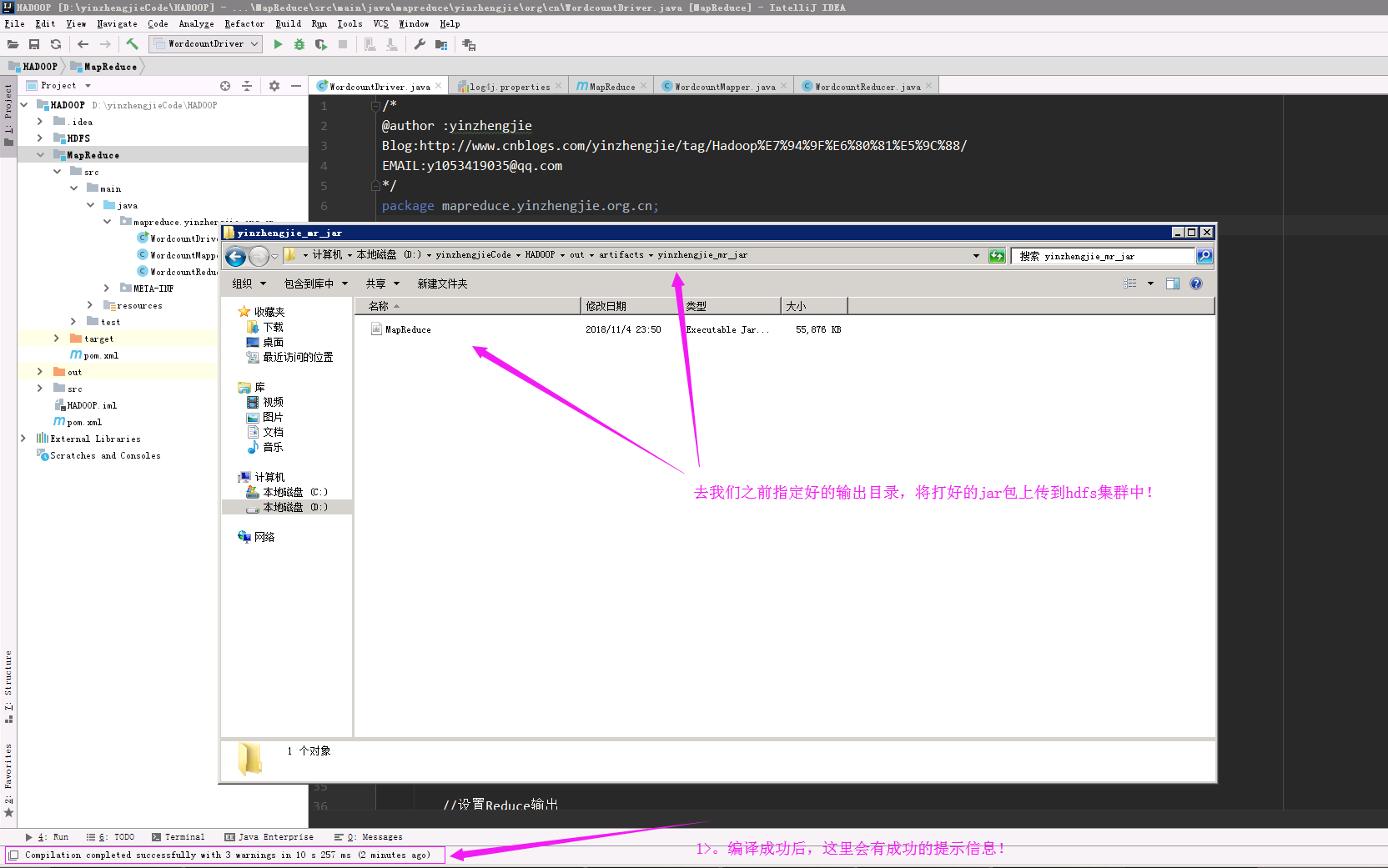
8>.找到咱们刚刚编译好的jar包,将其上传到hdfs集群中。
9>.将测试文件上传至hdfs集群中
[root@node105 ~]# hdfs dfs -put hello.txt /yinzhengjie/data/
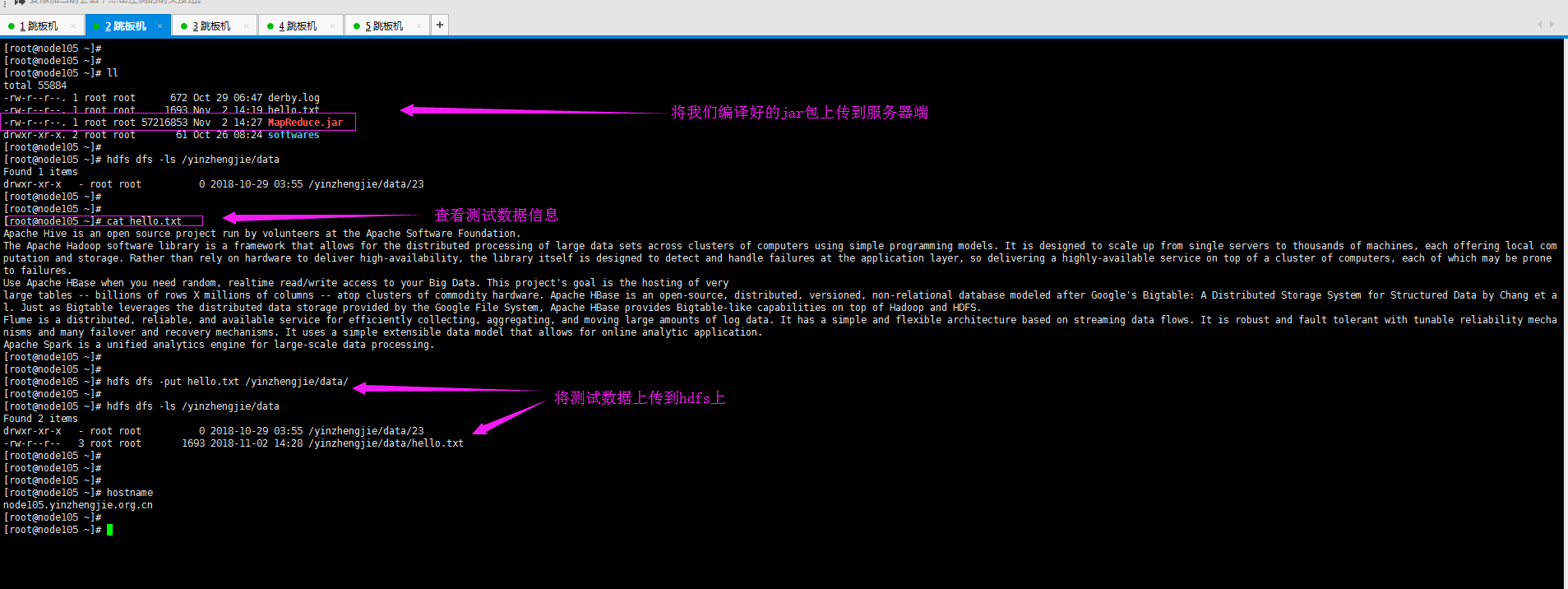
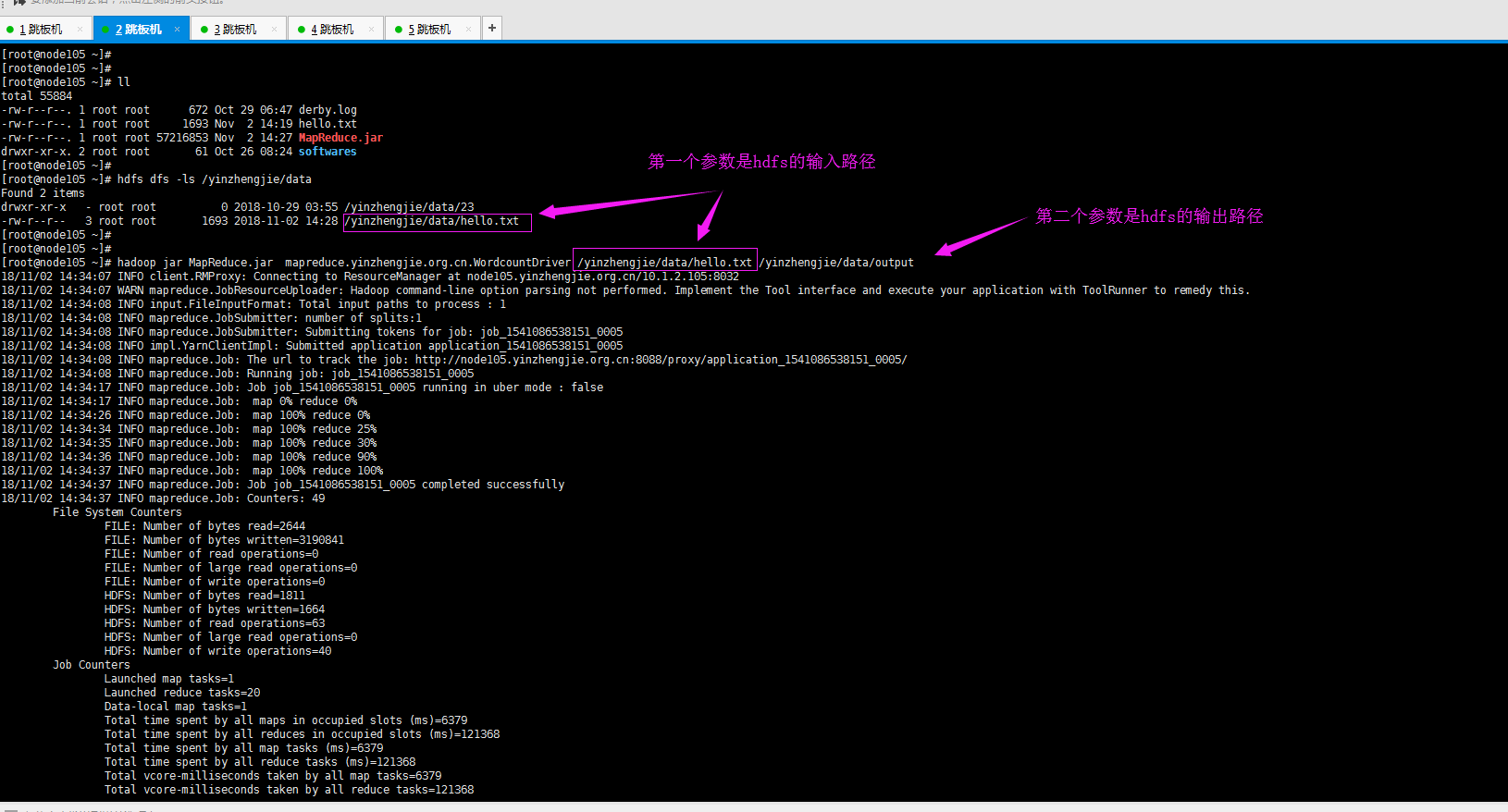
10>.运行我们自己编译好的jar包
[root@node105 ~]# hadoop jar MapReduce.jar mapreduce.yinzhengjie.org.cn.WordcountDriver /yinzhengjie/data/hello.txt /yinzhengjie/data/output
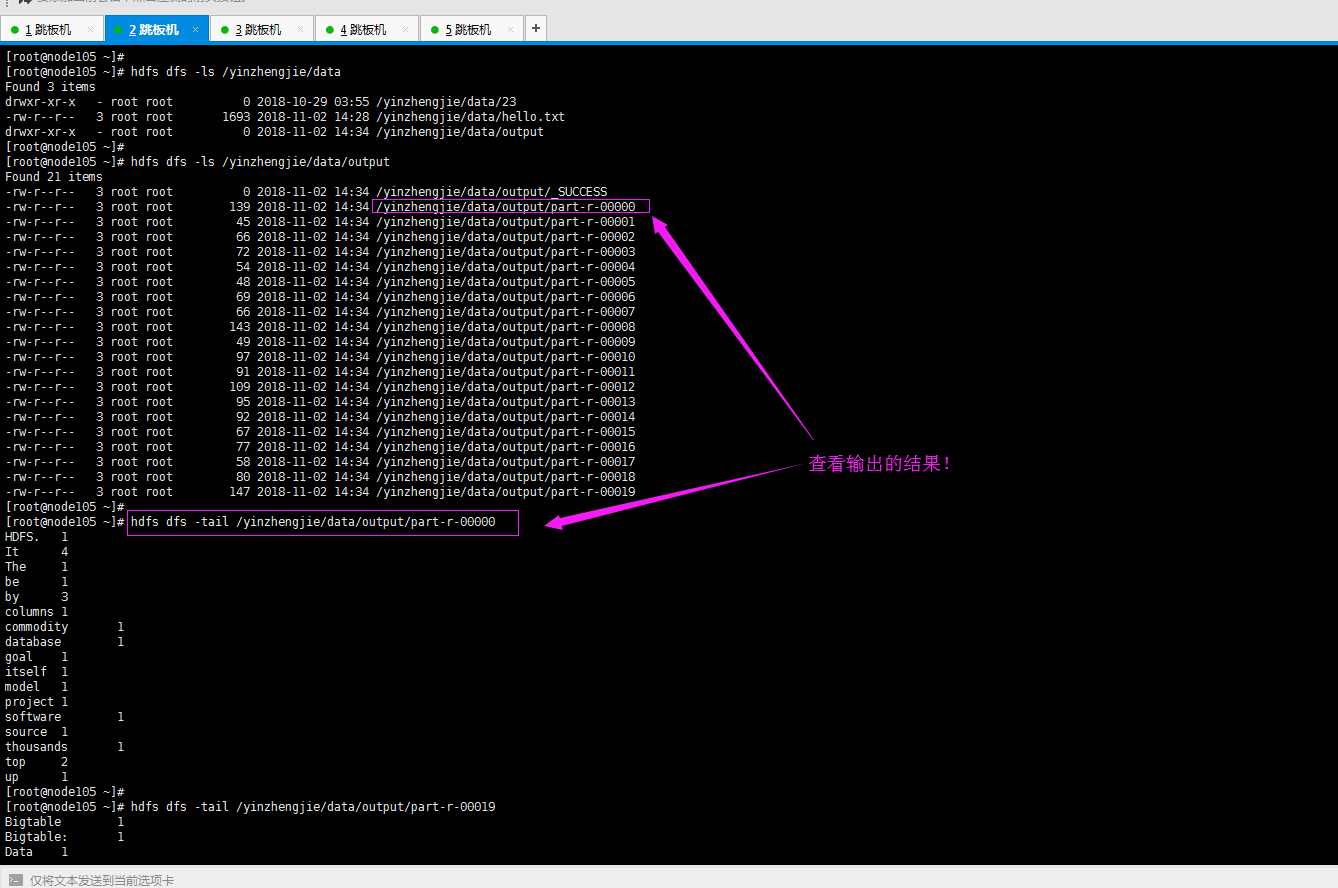
11>.查看输出的结果
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码的更多相关文章
- Hadoop基础-MapReduce的工作原理第一弹
Hadoop基础-MapReduce的工作原理第一弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在本篇博客中,我们将深入学习Hadoop中的MapReduce工作机制,这些知识 ...
- Hadoop基础-MapReduce的Combiner用法案例
Hadoop基础-MapReduce的Combiner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.编写年度最高气温统计 如上图说所示:有一个temp的文件,里面存放 ...
- Hadoop基础-MapReduce的常用文件格式介绍
Hadoop基础-MapReduce的常用文件格式介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MR文件格式-SequenceFile 1>.生成SequenceF ...
- Hadoop基础-MapReduce的排序
Hadoop基础-MapReduce的排序 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MapReduce的排序分类 1>.部分排序 部分排序是对单个分区进行排序,举个 ...
- Hadoop基础-MapReduce的工作原理第二弹
Hadoop基础-MapReduce的工作原理第二弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Split(切片) 1>.MapReduce处理的单位(切片) 想必 ...
- Hadoop基础-MapReduce的Join操作
Hadoop基础-MapReduce的Join操作 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.连接操作Map端Join(适合处理小表+大表的情况) no001 no002 ...
- Hadoop基础-MapReduce的数据倾斜解决方案
Hadoop基础-MapReduce的数据倾斜解决方案 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.数据倾斜简介 1>.什么是数据倾斜 答:大量数据涌入到某一节点,导致 ...
- Hadoop基础-MapReduce的Partitioner用法案例
Hadoop基础-MapReduce的Partitioner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Partitioner关键代码剖析 1>.返回的分区号 ...
- 自定义编写jmeter的Java测试代码
我们在做性能测试时,有时需要自己编写测试脚本,很多测试工具都支持自定义编写测试脚本,比如LoadRunner就有很多自定义脚本的协议,比如"C Vuser","JavaV ...
随机推荐
- 进程间通信IPC与Binder机制原理
1, Intent隐式意图携带数据 2, AIDL(Binder) 3, 广播BroadCast 4, 内容提供者ContentProvider 5,Messager(内部通过binder实现) 6, ...
- RESTful 架构详解
RESTful 架构详解 分类 编程技术 1. 什么是REST REST全称是Representational State Transfer,中文意思是表述(编者注:通常译为表征)性状态转移. 它首次 ...
- Volatile的应用
.java 的执行过程 Java代码在编译后会变成Java字节码 字节码被类加载器加载到JVM里 JVM执行字节码,转化为汇编指令在CPU上执行 Java中所使用的并发机制依赖于JVM的实现和CPU的 ...
- python 机械学习之sklearn的数据正规化
from sklearn import preprocessing #导入sklearn的处理函数用于处理一些大值数据 x_train, x_test, y_train, y_test = tr ...
- POJ3261-Milk Patterns-后缀数组
可重叠重复k次的最长子串长度. 还是使用二分答案对heigh数组分组的做法. #include <cstdio> #include <algorithm> #include & ...
- POI如何自动调整Excel单元格中字体的大小
问题 目的是要将Excel中的文字全部显示出来,可以设置对齐格式为[缩小字体填充],但是这样的话只能展示出一行数据,字体会变得很小.还有一种办法,设置对齐格式为[自动换行],然后让单元格中的字体自动调 ...
- 【SPOJ】Power Modulo Inverted(拓展BSGS)
[SPOJ]Power Modulo Inverted(拓展BSGS) 题面 洛谷 求最小的\(y\) 满足 \[k\equiv x^y(mod\ z)\] 题解 拓展\(BSGS\)模板题 #inc ...
- 【Nowcoder71E】组一组(差分约束,最短路)
[Nowcoder71E]组一组(差分约束,最短路) 题面 Nowcoder 题解 看到二进制显然就直接拆位,那么区间的按位或和按位与转成前缀和之后,可以写成两个前缀和的值的差的大小关系,那么直接差分 ...
- 【AtCoder3611】Tree MST(点分治,最小生成树)
[AtCoder3611]Tree MST(点分治,最小生成树) 题面 AtCoder 洛谷 给定一棵\(n\)个节点的树,现有有一张完全图,两点\(x,y\)之间的边长为\(w[x]+w[y]+di ...
- jmeter生成测试报告