rabbitmq3.6.5镜像集群搭建以及haproxy负载均衡
一、集群架构
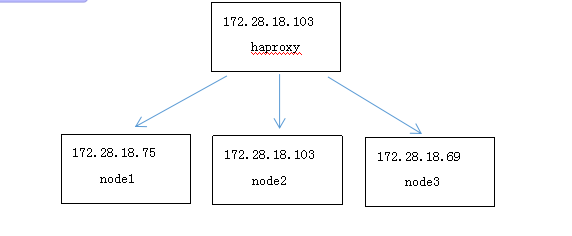
后端75、103、69分别是3台rabbitmq节点做镜像集群,前端103用haproxy作为负载均衡器
二、安装rabbitmq节点
参照
https://www.cnblogs.com/sky-cheng/p/10709104.html
三、配置hosts文件
vim /etc/hosts
172.28.18.75 zabbix_server
172.28.18.103 node2
172.28.18.69 node3
这里的zabbix_server主机就是node1,因为是我一台监控服务器,所以我就没有修改主机名。一下zabbix_server主机对应的就是node1节点。
四、设置erlang cookie
RabbitMQ节点之间和命令行工具 (e.g. rabbitmqctl)是使用Cookie互通的,Cookie是一组随机的数字+字母的字符串。当RabbitMQ服务器启动的时候,Erlang VM会自动创建一个随机内容的Cookie文件。如果是通过源安装RabbitMQ的话,Erlang Cookie 文件在/var/lib/rabbitmq/.erlang.cookie。如果是通过源码安装的RabbitMQ,Erlang Cookie文件$HOME/.erlang.cookie。
首先需要将3个节点的cookie进行统一,将75的.erlang.cookie覆盖到103和69的cookie
.erlang.cookie文件权限默认是400
[root@zabbix_server src]# ll -a /var/lib/rabbitmq/
总用量
drwxr-xr-x rabbitmq rabbitmq 3月 : .
drwxr-xr-x. root root 4月 : ..
-r-------- rabbitmq rabbitmq 4月 : .erlang.cookie
drwxr-x--- rabbitmq rabbitmq 4月 : mnesia
修改权限为777
chmod /var/lib/rabbitmq/.erlang.cookie
[root@zabbix_server src]# ll -a /var/lib/rabbitmq/.erlang.cookie
-rwxrwxrwx rabbitmq rabbitmq 4月 : /var/lib/rabbitmq/.erlang.cookie
复制文件
[root@zabbix_server src]# scp -P25601 /var/lib/rabbitmq/.erlang.cookie root@172.28.18.103:/var/lib/rabbitmq/
root@172.28.18.103's password:
.erlang.cookie % .0KB/s :
[root@zabbix_server src]# scp -P25601 /var/lib/rabbitmq/.erlang.cookie root@172.28.18.69:/var/lib/rabbitmq/
root@172.28.18.69's password:
.erlang.cookie % .0KB/s :
验证三个节点文件内容是否相同
[root@zabbix_server src]# cat /var/lib/rabbitmq/.erlang.cookie
ATHUHJDWKYXPPLSHYCED
[root@localhost src]# cat /var/lib/rabbitmq/.erlang.cookie
ATHUHJDWKYXPPLSHYCED
[root@localhost ~]# cat /var/lib/rabbitmq/.erlang.cookie
ATHUHJDWKYXPPLSHYCED
再将node1、node2、node3将权限恢复为400
[root@zabbix_server src]# chmod /var/lib/rabbitmq/.erlang.cookie
[root@localhost src]# chmod /var/lib/rabbitmq/.erlang.cookie
[root@localhost ~]# chmod /var/lib/rabbitmq/.erlang.cookie
五、使用detached参数,启动rabbitmq 节点
先停止3个rabbitmq节点
[root@zabbix_server /]# rabbitmqctl stop
Stopping and halting node rabbit@zabbix_server ...
[root@zabbix_server /]#
注意修改3个服务器的主机名
[root@localhost src]# hostname
localhost.localdomain
[root@localhost src]# hostname node2.jinglong
[root@localhost src]# hostname
node2.jinglong
重启ssh登录
[root@node2 ~]# hostname
node2.jinglong
显示@ node2了
启动3个节点 ,带detached参数
[root@zabbix_server /]# rabbitmq-server -detached
Warning: PID file not written; -detached was passed.
六、查看3个节点状态
[root@zabbix_server src]# rabbitmqctl cluster_status
Cluster status of node rabbit@zabbix_server ...
[{nodes,[{disc,[rabbit@zabbix_server]}]},
{running_nodes,[rabbit@zabbix_server]},
{cluster_name,<<"rabbit@zabbix_server">>},
{partitions,[]},
{alarms,[{rabbit@zabbix_server,[]}]}]
[root@node2 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@node2 ...
[{nodes,[{disc,[rabbit@node2]}]},
{running_nodes,[rabbit@node2]},
{cluster_name,<<"rabbit@node2">>},
{partitions,[]},
{alarms,[{rabbit@node2,[]}]}]
[root@node3 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@node3 ...
[{nodes,[{disc,[rabbit@node3]}]},
{running_nodes,[rabbit@node3]},
{cluster_name,<<"rabbit@node3">>},
{partitions,[]},
{alarms,[{rabbit@node3,[]}]}]
七、将node2、node3节点加入集群
3个节点启动后,节点和应用同时启动,应用默认是standalone模式,即单机模式,所以需要先停掉需要加入集群的node2、node3节点的应用,然后将节点进行加入集群设置:
在node2服务器上操作
[root@node2 ~]# rabbitmqctl stop_app
Stopping node rabbit@node2 ...
注意,这里不能使用 rabbitmqctl stop,这样会将节点也停掉,就不能进行后续节点加入集群操作了,只能使用stop_app参数停掉应用。
将node2加入集群
[root@node2 ~]# rabbitmqctl join_cluster rabbit@zabbix_server
Clustering node rabbit@node2 with rabbit@zabbix_server ...
Error: unable to connect to nodes [rabbit@zabbix_server]: nodedown DIAGNOSTICS
=========== attempted to contact: [rabbit@zabbix_server] rabbit@zabbix_server:
* unable to connect to epmd (port ) on zabbix_server: nxdomain (non-existing domain) current node details:
- node name: 'rabbitmq-cli-76@node2'
- home dir: /var/lib/rabbitmq
- cookie hash: W3bZoV8WKKWsCgfh3FFkzw==
报错,(non-existing domain),此时排查3台服务器的/etc/hosts文件内容,保证和hostname名称一致
vim /etc/hosts
172.28.18.75 zabbix_server
172.28.18.103 node2
172.28.18.69 node3
再次加入集群
[root@node2 ~]# rabbitmqctl join_cluster rabbit@zabbix_server
Clustering node rabbit@node2 with rabbit@zabbix_server ...
[root@node2 ~]#
查看集群状态
[root@node2 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@node2 ...
[{nodes,[{disc,[rabbit@node2,rabbit@zabbix_server]}]},
{alarms,[{rabbit@zabbix_server,[]}]}]
此时可以看到nodes里已经有2个节点了node2和zabbix_server,说明集群加入成功
在75上查看集群状态
[root@zabbix_server src]# rabbitmqctl cluster_status
Cluster status of node rabbit@zabbix_server ...
[{nodes,[{disc,[rabbit@node2,rabbit@zabbix_server]}]},
{running_nodes,[rabbit@zabbix_server]},
{cluster_name,<<"rabbit@zabbix_server">>},
{partitions,[]},
{alarms,[{rabbit@zabbix_server,[]}]}]
也能看到有2个节点了,我们再把node3节点也加入集群
[root@node3 ~]# rabbitmqctl join_cluster rabbit@zabbix_server
Clustering node rabbit@node3 with rabbit@zabbix_server ...
[root@node3 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@node3 ...
[{nodes,[{disc,[rabbit@node2,rabbit@node3,rabbit@zabbix_server]}]},
{alarms,[{rabbit@zabbix_server,[]}]}]
此时,可以看到nodes里出现了node3节点,加入集群成功。我们再把node2和node3节点的应用启动
我们打开75的管控台

此时节点信息里,已经出现了node2和node3,但是目前的状态的未运行,所以我们需要把node2和node3的应用启动
[root@node2 ~]# rabbitmqctl start_app
Starting node rabbit@node2 ...
[root@node3 ~]# rabbitmqctl start_app
Starting node rabbit@node3 ...
此时刷新75的管控台
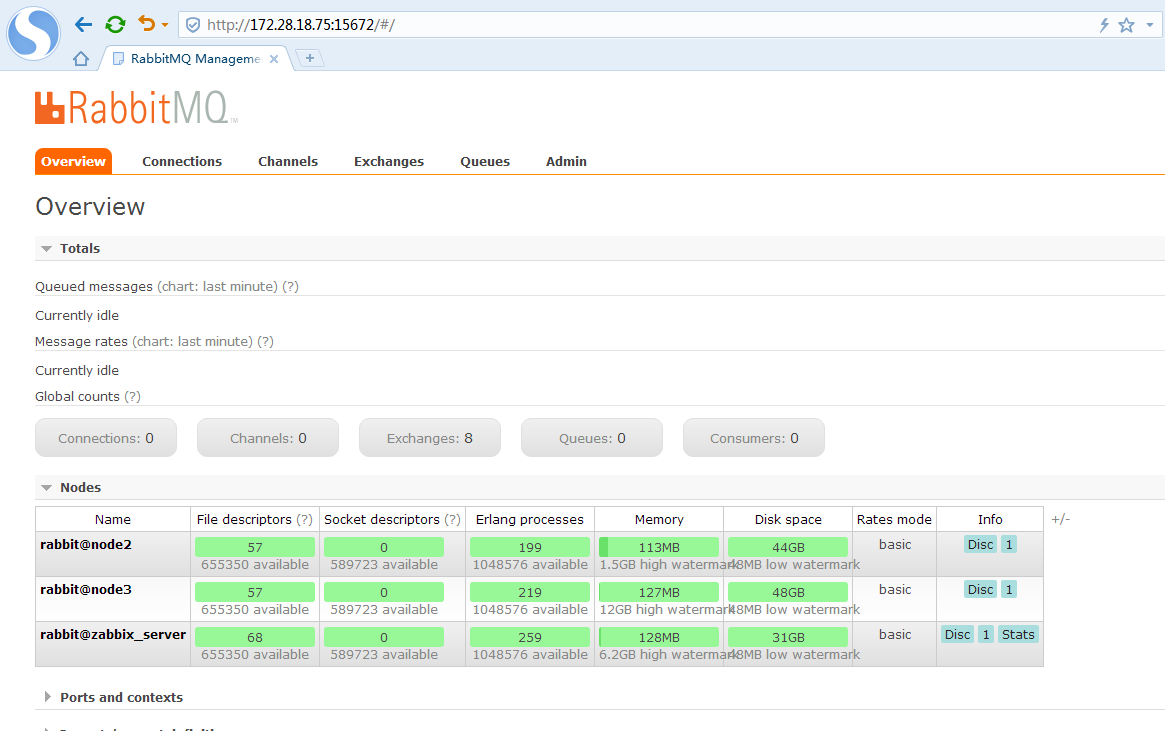
集群中的3个节点都已经正常了
修改下集群名称便于记忆
rabbitmqctl set_cluster_name rabbitmq_cluster
八、配置镜像队列
在任意一个节点执行设置镜像队列策略
[root@zabbix_server src]# rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
Setting policy "ha-all" for pattern "^" to "{\"ha-mode\":\"all\"}" with priority "" ...
[root@zabbix_server src]#
九、验证镜像队列
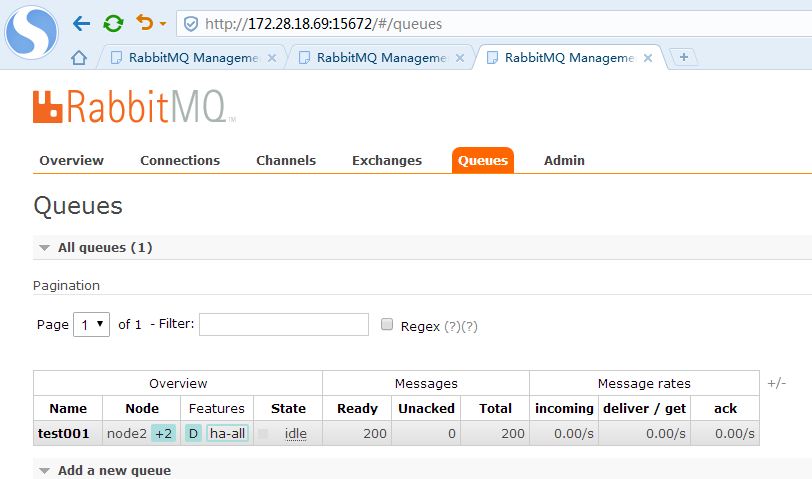
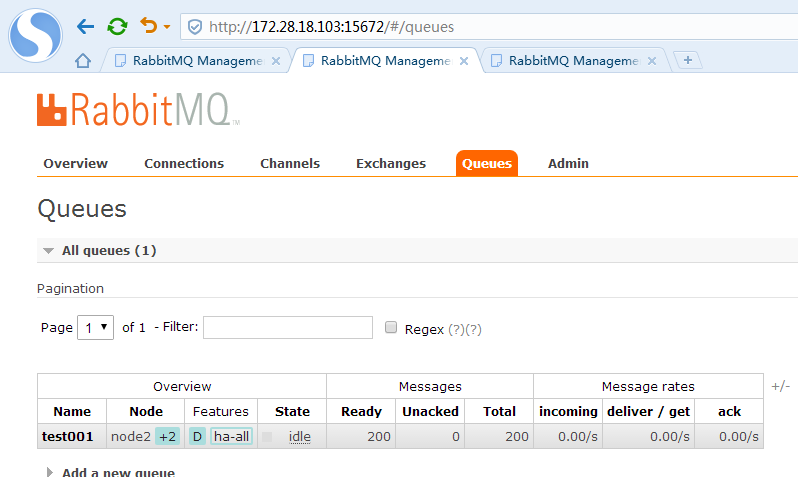
在任意一个节点管控台新建一个队列,新建完毕后,立刻在其余2个节点都可以看到这个队列
利用java 编写一个生产者测试客户端向其中一个节点队列发送消息,其余2个节点都可以在管控台看到消息的同步
package com.hl95.rabbitmq.demo; import java.io.IOException;
import java.util.concurrent.TimeoutException; import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory; public class Producer {
public static void main(String[]args) throws IOException,TimeoutException{
ConnectionFactory factory=new ConnectionFactory();
//配置连接属性
factory.setHost("172.28.18.69");
factory.setPort(5672);
factory.setVirtualHost("/");
factory.setUsername("admin");
factory.setPassword("xxxxxx"); //得到连接
Connection connection=factory.newConnection();
//创建通道
Channel channel=connection.createChannel();
//声明(创建)队列
String queueName="test001";
channel.queueDeclare(queueName, true, false, false, null);
//发送消息
String message="你好, RabbitMQ";
for(int i=0;i<200;i++){
channel.basicPublish("",queueName, null, message.getBytes("UTF-8"));
try {
Thread.sleep(500);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
channel.close();
connection.close();
}
}
十、在172.28.18.104上安装haproxy
1、下载
cd /usr/local/src
wget https://github.com/haproxy/haproxy/archive/v1.5-dev20.tar.gz
2、安装
tar -zxvf v1.-dev20.tar.gz
cd haproxy-1.5-dev20/
make TARGET=linux26 prefix=/usr/local/haproxy
make install prefix=/usr/local/haproxy
3、新建配置文件
mkdir /etc/haproxy
touch /etc/haproxy/haproxy.conf
vim /etc/haproxy/haproxy.conf
global
log 127.0.0.1 local2
chroot /usr/local/haproxy
pidfile /var/run/haproxy.pid ###haproxy的pid存放路径,启动进程的用户必须有权限访问此文件
maxconn ###最大连接数,默认4000
daemon defaults
mode tcp
option tcplog
log global
timeout connect 20s
timeout server 60s
timeout client 60s
retries listen stats
bind 0.0.0.0: #监听端口
mode http
option httplog
stats refresh 5s #统计页面自动刷新时间
stats uri /rabbitmq-stats #统计页面url
stats realm Haproxy Manager #统计页面密码框上提示文本
stats auth admin:xxxxxx #统计页面用户名和密码设置
stats hide-version #隐藏统计页面上HAProxy的版本信息 listen rabbitmq_cluster
bind 172.28.18.104: #监听端口
mode tcp
balance roundrobin
server zabbix_server 172.28.18.75: check inter rise fall
server node1 172.28.18.103: check inter rise fall
server node2 172.28.18.69: check inter rise fall
退出保存,并重启haproxy
[root@localhost haproxy-1.5-dev20]# ps -ef|grep haproxy
root : ? :: haproxy -f /etc/haproxy/haproxy.conf
root : pts/ :: grep haproxy
[root@localhost haproxy-1.5-dev20]# kill -
[root@localhost haproxy-1.5-dev20]# haproxy -f /etc/haproxy/haproxy.conf
4、打开管控台
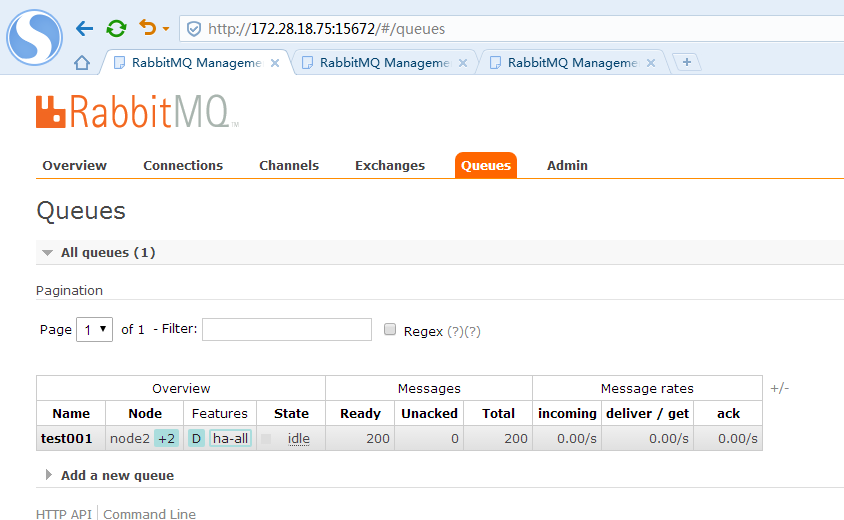
此时显示3个rabbitmq节点信息
十一、测试集群的负载均衡功能
利用下面java代码测试负载均衡代理
package com.hl95.rabbitmq.demo; import java.io.IOException;
import java.util.concurrent.TimeoutException; import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory; public class Producer {
public static void main(String[]args) throws IOException,TimeoutException{
ConnectionFactory factory=new ConnectionFactory();
//配置连接属性
factory.setHost("172.28.18.104");
factory.setPort(5672);
factory.setVirtualHost("/");
factory.setUsername("admin");
factory.setPassword("xxxxxxxx"); //得到连接
Connection connection=factory.newConnection();
//创建通道
Channel channel=connection.createChannel();
//声明(创建)队列
String queueName="test001";
channel.queueDeclare(queueName, true, false, false, null);
//发送消息
String message="你好, RabbitMQ";
for(int i=0;i<200;i++){
channel.basicPublish("",queueName, null, message.getBytes("UTF-8"));
try {
Thread.sleep(500);
System.out.println("Consumer: "+message+"---"+i);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
channel.close();
connection.close();
}
}
此时我们将客户端连接改为172.28.18.104的前端haproxy负载均衡服务器的IP和端口,测试发送消息,后端集群节点都能同步到消息
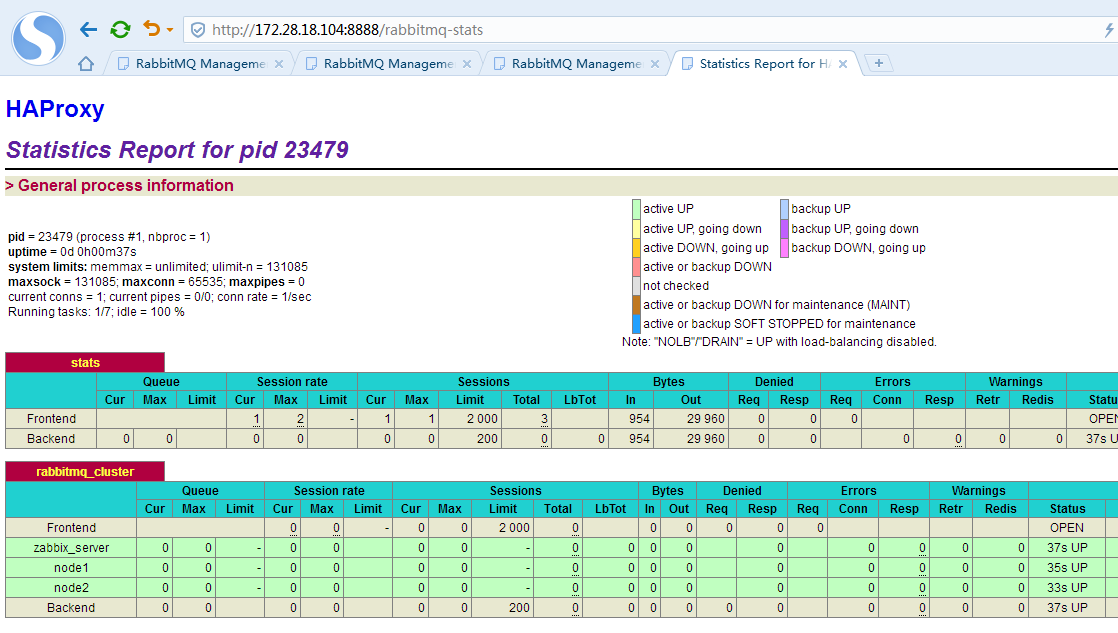
首先执行第一次消息投递,同时观察104上haproxy管控台后端连接到哪个rabbitmq节点
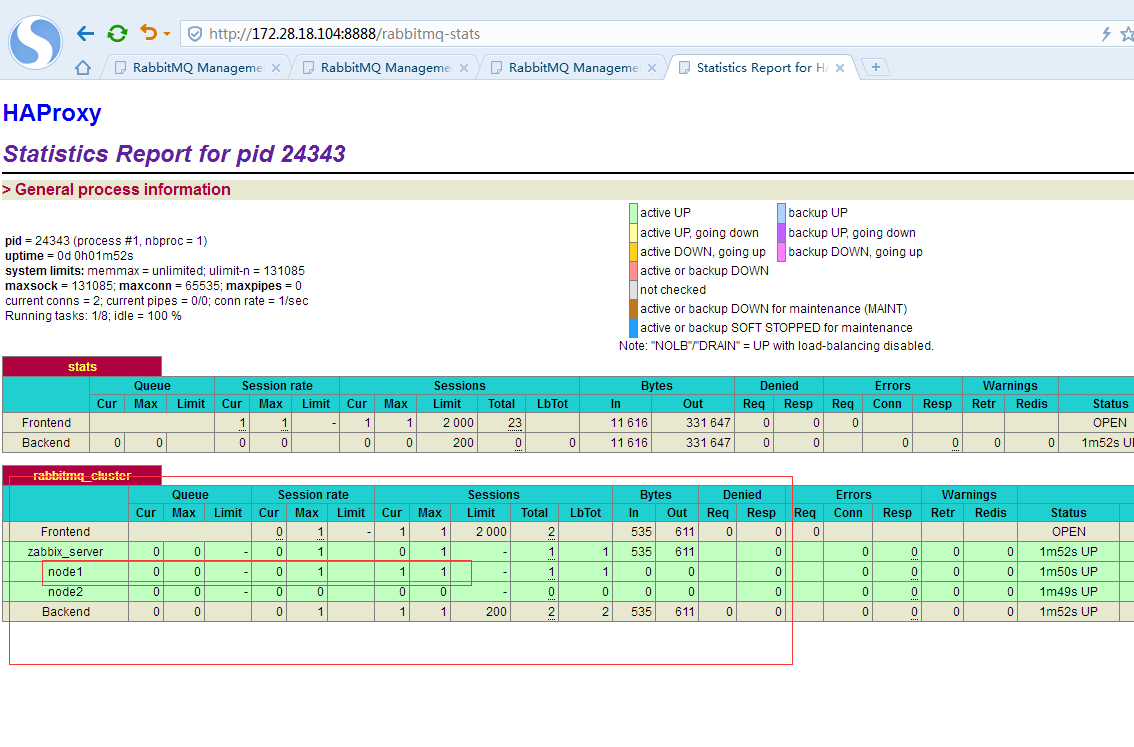
上图可以看到第一次消息投递是被haproxy分配到了node1节点来接收。
继续第二次消息投递

上图可以看到第二次消息投递是被haproxy分配到了node1节点来接收。
继续第三次
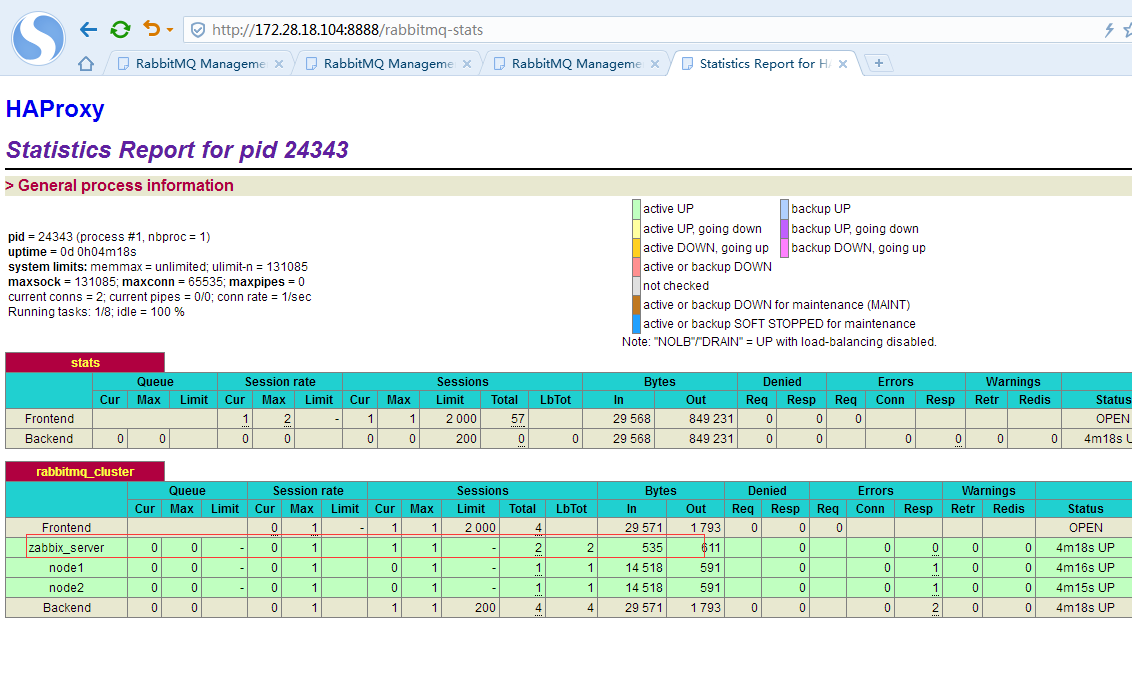
第三次消息投递是被haproxy分配到了zabbix_server节点来接收。
继续第四次
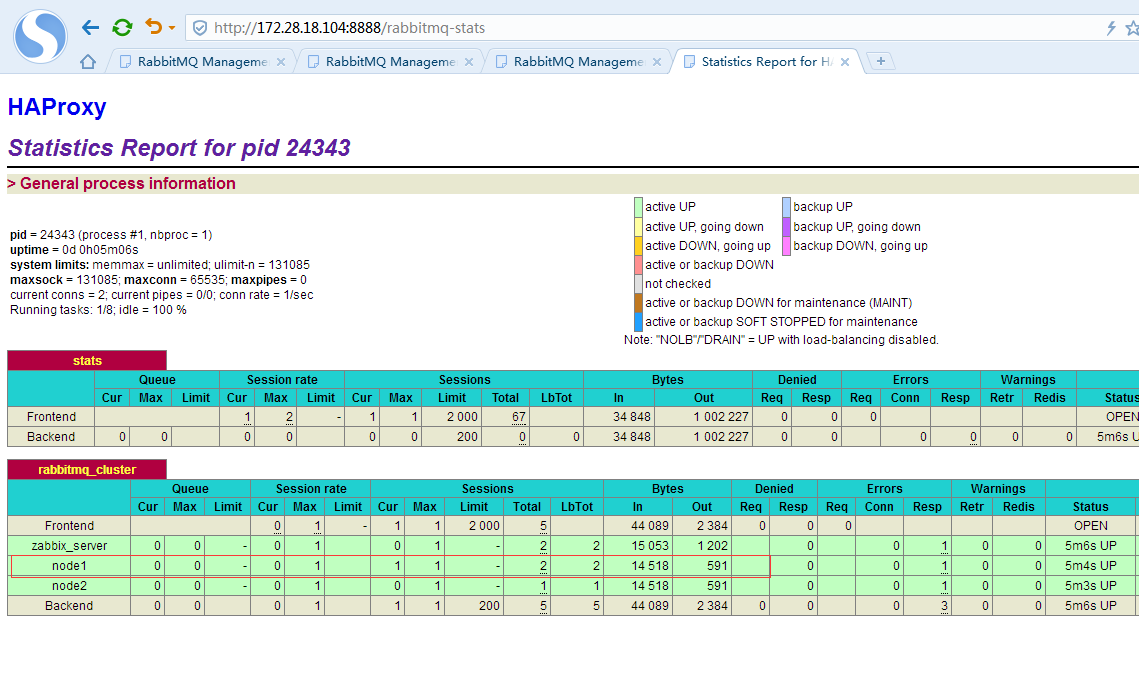
第四次消息投递是被haproxy重启分配回了node1节点来接收。验证了负载均衡是轮询的策略。
总共进行了4次投递,每次200个消息,目前队列里有800条消息待消费,3个节点的管控台队列消息是一致的,完全复制的
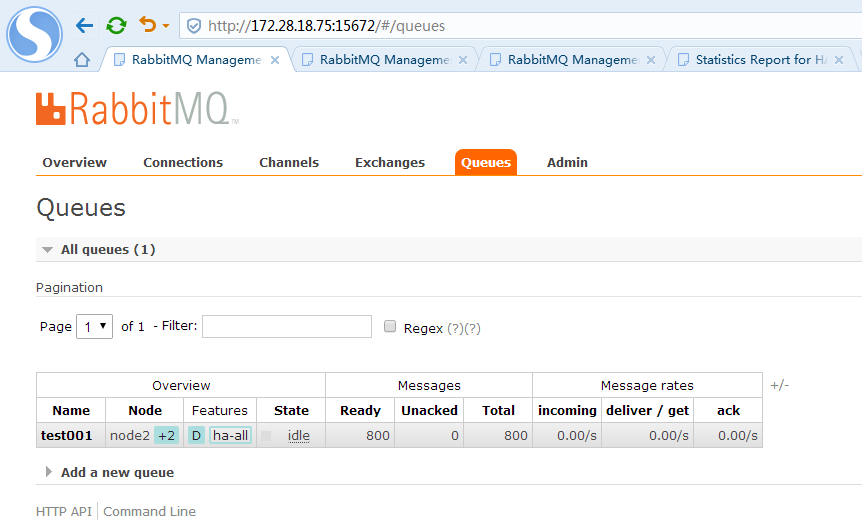


至此集群搭建和负载均衡策略配置成功。
十二、模拟节点故障处理
1、假设75节点的挂掉,那么首先利用forget_cluster_node参数,将此节点移除集群
停掉75上的rabbitmq应用
[root@zabbix_server src]# rabbitmqctl stop_app
Stopping node rabbit@zabbix_server ...
此时,rabbitmq管控台显示node信息中已经没有rabbit@zabbix_server了
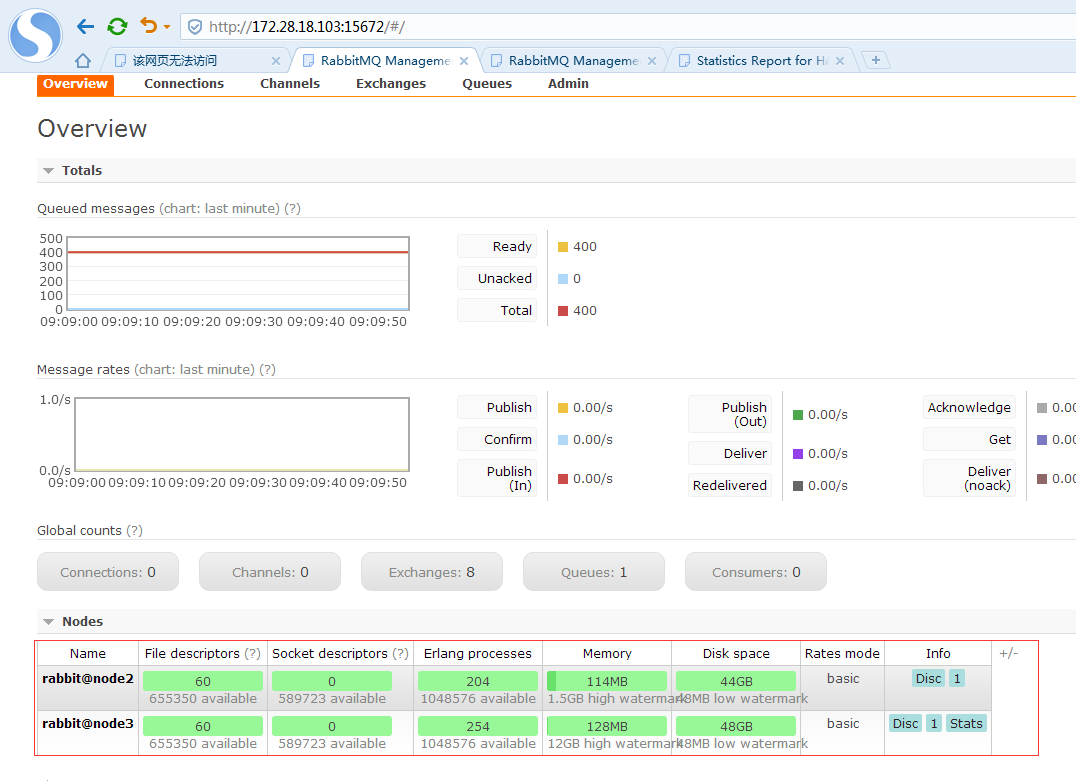
在其他任意节点查看集群状态
[root@node3 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@node3 ...
[{nodes,[{disc,[rabbit@node2,rabbit@node3,rabbit@zabbix_server]}]},
{running_nodes,[rabbit@node2,rabbit@node3]},
{cluster_name,<<"rabbitmq_cluster">>},
{partitions,[]},
{alarms,[{rabbit@node2,[]},{rabbit@node3,[]}]}]
显示集群中还是3个节点,但是running_nodes中只有2个节点,执行
[root@node3 ~]# rabbitmqctl forget_cluster_node rabbit@zabbix_server
Removing node rabbit@zabbix_server from cluster ...
[root@node3 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@node3 ...
[{nodes,[{disc,[rabbit@node2,rabbit@node3]}]},
{running_nodes,[rabbit@node2,rabbit@node3]},
{cluster_name,<<"rabbitmq_cluster">>},
{partitions,[]},
{alarms,[{rabbit@node2,[]},{rabbit@node3,[]}]}]
移除节点后,再查看集群状态,此时已经没有故障节点的信息了,说明我们将故障节点移除集群。
接下来我们重启75上的rabbitmq,模拟新节点,怎么重新加入集群
启动时出现以下错误:
[root@zabbix_server src]# rabbitmq-server start BOOT FAILED
=========== Error description:
{error,{inconsistent_cluster,"Node rabbit@zabbix_server thinks it's clustered with node rabbit@node3, but rabbit@node3 disagrees"}} Log files (may contain more information):
/var/log/rabbitmq/rabbit@zabbix_server.log
/var/log/rabbitmq/rabbit@zabbix_server-sasl.log Stack trace:
[{rabbit_mnesia,check_cluster_consistency,,
[{file,"src/rabbit_mnesia.erl"},{line,}]},
{rabbit,'-boot/0-fun-0-',,[{file,"src/rabbit.erl"},{line,}]},
{rabbit,start_it,,[{file,"src/rabbit.erl"},{line,}]},
{init,start_it,,[]},
{init,start_em,,[]}] {"init terminating in do_boot",{error,{inconsistent_cluster,"Node rabbit@zabbix_server thinks it's clustered with node rabbit@node3, but rabbit@node3 disagrees"}}}
/usr/lib/rabbitmq/bin/rabbitmq-server: line : 用户定义信号 start_rabbitmq_server "$@"
说明75上还保留集群信息,但实际上75已经被移除集群了,所以出现上述错误,解决方法删除/var/lib/rabbitmq/mnesia/目录,里面保存有节点的相关信息
[root@zabbix_server rabbitmq]# rm -rf /var/lib/rabbitmq/mnesia/
[root@zabbix_server rabbitmq]# rabbitmq-server -detached
Warning: PID file not written; -detached was passed.
[root@zabbix_server rabbitmq]# rabbitmqctl cluster_status
Cluster status of node rabbit@zabbix_server ...
[{nodes,[{disc,[rabbit@zabbix_server]}]},
{running_nodes,[rabbit@zabbix_server]},
{cluster_name,<<"rabbit@zabbix_server">>},
{partitions,[]},
{alarms,[{rabbit@zabbix_server,[]}]}]
删除后,再重新启动,查看集群状态,75已经是初始化状态,此时是单机模式。接下来加入集群操作:
[root@zabbix_server rabbitmq]# rabbitmqctl join_cluster rabbit@node2 --ram
Clustering node rabbit@zabbix_server with rabbit@node2 ...
[root@zabbix_server rabbitmq]# rabbitmqctl cluster_status
Cluster status of node rabbit@zabbix_server ...
[{nodes,[{disc,[rabbit@node2,rabbit@node3]},{ram,[rabbit@zabbix_server]}]},
{alarms,[{rabbit@node2,[]},{rabbit@node3,[]}]}]
加入成功,查看集群状态,已经成功了,此时在另外两个节点任意一个管控台上观察节点信息
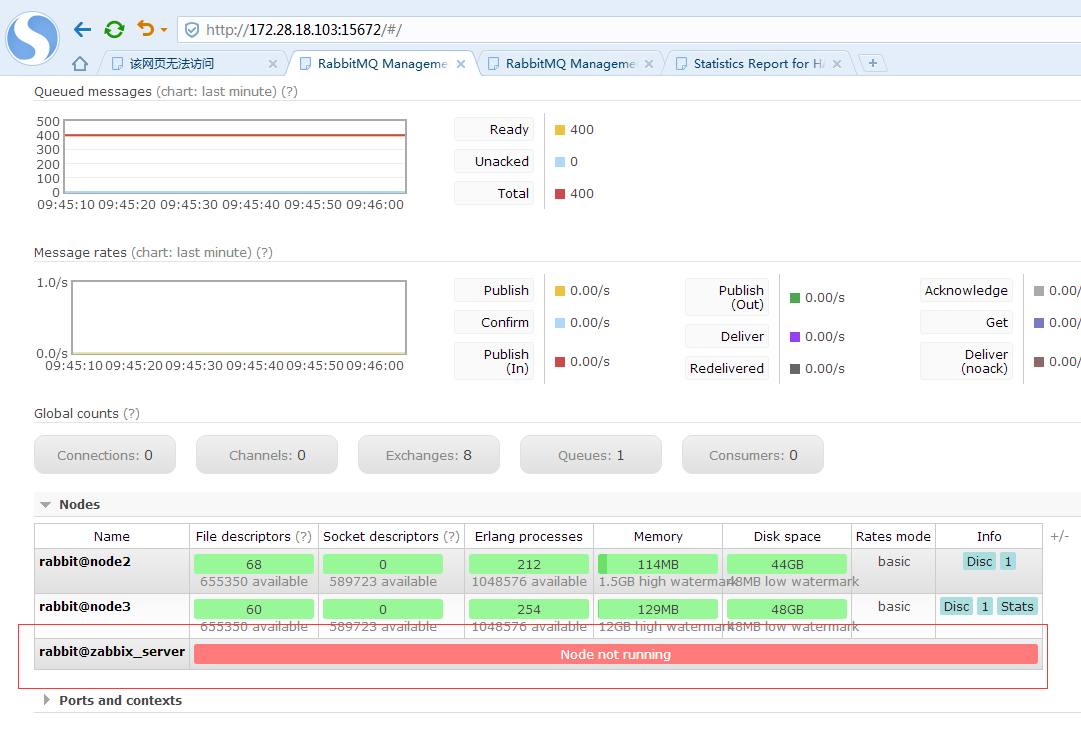
状态是未运行,在75上启动应用
[root@zabbix_server rabbitmq]# rabbitmqctl start_app
Starting node rabbit@zabbix_server ...
打开75上的管控台登录

此时,75节点正常运行,并且是内存模式。
rabbitmq3.6.5镜像集群搭建以及haproxy负载均衡的更多相关文章
- tomcat集群搭建集成nginx负载均衡
软件基础+版本: 1.3台centos7系统,其中都已经配置完成了jdk环境,jdk的版本为 [root@node03 bin]# java -version java version "1 ...
- RabbitMQ (十五) 镜像集群 + HAProxy1.7.8 负载均衡
RabbitMQ 默认的集群模式,也就是普通模式,最大的问题就在于存储队列完整数据的节点一旦宕机, 如果是非持久化队列,则消息丢失;如果是持久化队列+持久化消息,则必须等该节点恢复. 所以后来 Rab ...
- Linux 集群概念 , wsgi , Nginx负载均衡实验 , 部署CRM(Django+uwsgi+nginx), 部署学城项目(vue+uwsgi+nginx)
Linux 集群概念 , wsgi , Nginx负载均衡实验 , 部署CRM(Django+uwsgi+nginx), 部署学城项目(vue+uwsgi+nginx) 一丶集群和Nginx反向代理 ...
- Tomcat集群,Nginx集群,Tomcat+Nginx 负载均衡配置,Tomcat+Nginx集群
Tomcat集群,Nginx集群,Tomcat+Nginx 负载均衡配置,Tomcat+Nginx集群 >>>>>>>>>>>> ...
- LVS集群中的IP负载均衡技术
LVS集群中的IP负载均衡技术 章文嵩 (wensong@linux-vs.org) 转自LVS官方参考资料 2002 年 4 月 本文在分析服务器集群实现虚拟网络服务的相关技术上,详细描述了LVS集 ...
- 转载-lvs官方文档-LVS集群中的IP负载均衡技术
章文嵩(wensong@linux-vs.org) 2002 年 4 月 本文在分析服务器集群实现虚拟网络服务的相关技术上,详细描述了LVS集群中实现的三种IP负载均衡技术(VS/NAT.VS/TUN ...
- RabbitMQ镜像集群搭建
RabbitMQ 官网 https://www.rabbitmq.com/ 小编使用的系统环境是CentOS7.4 系统 IP hostname CentOS7.4 1.1.1.1 hostname0 ...
- 集群之LVS(负载均衡)详解
提高服务器响应能力的方法 scale on 在原有服务器的基础上进行升级或者直接换一台新的性能更高的服务器. scale out 横向扩展,将多台服务器并发向外响应客户端的请求.优点:成本低,扩展 ...
- MySQL读写分离高可用集群及读操作负载均衡(Centos7)
目录 概述 keepalived和heartbeat对比 一.环境 二.部署 部署lvs代理和keepalived MySQL+heartbeat+drbd的部署 MySQL主从复制 web服务器及a ...
随机推荐
- 语音识别传统方法(GMM+HMM+NGRAM)概述
春节后到现在近两个月了,没有更新博客,主要是因为工作的关注点正从传统语音(语音通信)转向智能语音(语音识别).部门起了个新项目,要用到语音识别(准备基于Kaldi来做).我们之前做的传统音频已基本成熟 ...
- nginx 用来做什么?
代理服务端,反向代理,负载均衡. 其特点是占有内存少,并发能力强.
- python-setuptool安装
安装setuptools时报error: ”RuntimeError: Compression requires the (missing) zlib module“ 解决办法: yum安装zlib和 ...
- javaAgent介绍
JavaAgent(转载) http://www.cnblogs.com/diyunpeng/archive/2011/05/26/2057932.html 一文带你了解Java Agent http ...
- python笔记(三)---文件读写、修改文件内容、处理json、函数
文件读写(一) #r 只读,打开文件不存在的话,会报错 #w 只写,会清空原来文件的内容 #a 追加写,不会请求,打开的文件不存在的话,也会帮你新建的一个文件 print(f.read()) #获取到 ...
- Ajax异步请求阻塞情况的解决办法(asp.net MVC Session锁的问题)
讨论今天这个问题之前,我们先来看下浏览器公布的资源并发数限制个数,如下图 不难看出,目前主流浏览器支持都是最多6个并发 需要注意的是,浏览器的并发请求数目限制是针对同一域名的 意即,同一时间针对同一域 ...
- idea中使用github
转载:https://www.cnblogs.com/javabg/p/7987755.html 1.先安装git插件,本机安装git在C:\InstallSoftWare\Git 2. 在Idea ...
- 关于mysql文件导入提示“Variable @OLD_CHARACTER_SET_CLIENT can't be set to the value of @@CHARACTER_SET_CLIENT”问题分析
今天用myssqldump导出数据,然后再导入另外mysql数据库时,提示Variable @OLD_CHARACTER_SET_CLIENT can't be set to the value of ...
- AS错误:Manifest merger failed with multiple errors, see logs
gradlew processDebugManifest --stacktrace 在as命令行输入 回车看到 往上滑, 就能看到错误的详细信息,图中这个错误应该不是我原来的错误,是因为我按照网上的方 ...
- 从javascript 调用angular的函数
从vanilla javascript 调用angular的函数: * 调用 service中的函数var yourService = angular.element(document.body).i ...