Game Engine Architecture 4
【Game Engine Architecture 4】
1、a model of multiple semi-independent flows of control simply matches the problem better than a single flow-of-control design.
2、There are two basic ways in which concurrent threads can communicate:
• Message passing. The messages might be sent across a network, passed between processes using a pipe, or transmitted via a message queue in memory that is accessible to both sender and receiver. This approach
• Shared memory. two or more threads are granted access to the same block of physical memory, and can therefore operate directly on any data objects residing in that memory area. Threads within different processes can also share memory by mapping certain physical memory pages into all of the processes’ virtual address spaces.
3、Race Conditions
A race condition is defined as any situation in which the behavior of a program is dependent on timing.
竞态条件(race condition)是指设备或系统出现不恰当的执行时序,而得到不正确的结果。竞态条件(race condition),从多进程间通信的角度来讲,是指两个或多个进程对共享的数据进行读或写的操作时,最终的结果取决于这些进程的执行顺序。
4、Critical Races
critical race is a race condition that has the potential to cause incorrect program behavior.
• intermittent or seemingly random bugs or crashes,
• incorrect results,
• data structures that get into corrupted states,
• bugs that magically disappear when you switch to a debug build,
• bugs that are around for a while, and then go away for a few days, onlyto return again (usually the night before E3!),
• bugs that go away when logging (a.k.a., “printf() debugging”) is added to the program in an attempt to discover the source of the problem.
5、Data Races
A data race is a critical race condition in which two or more flows of control intefere with one another while reading and/or writing a block of shared data, resulting in data corruption.


Upper is an example of a read-modify-write (RMW) operation.
Data race bugs only occur when an operation on a shared object is interrupted by another operation on that same object.
Let’s use the term critical operation to refer to any operation that can possibly read or mutate one particular shared object. To guarantee that the shared object is free from data race bugs, we must ensure that none of its critical operations can interrupt one another.
When a critical operation is made uninterruptable in this manner, it is called an atomic operation. Alternatively, we can say that such an operation has the property of atomicity.
6、Invocation and Response

7、Atomicity Defined
a data race bug can occur when a critical operation is interrupted by another critical operation on the same shared object. This can happen:
• when one thread preempts another on a single core, or
• when two or more critical operations overlap across multiple cores.
8、define the atomicity of a critical operation as follows:

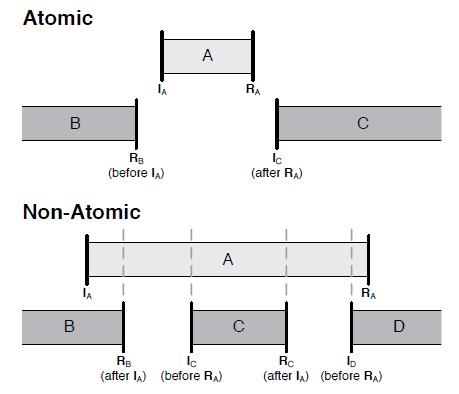

9、Makeing an Operation Atomic
how can we transform a critical operation into an atomic operation? The easiest and most reliable way to accomplish this is to use a special object called a mutex.
the OS guarantees that a mutex can only be acquired by one thread at a time.
10、Thread Synchronization Primitives
while these thread synchronization primitives are robust and relatively easy to use, they are generally quite expensive. This is because these tools are provided by the kernel. Interacting with any of them therefore requires a kernel call, which involves a context switch into protected mode. Such context switches can cost upwards of 1000 clock cycles.
11、Mutex
mutex can be in one of two states: unlocked or locked. (sometimes called released and acquired, or signaled and nonsignaled, respectively.)
“mutex” comes from “mutual exclusion.”
If one or more other threads is asleep (blocked) waiting on the mutex, the act of signaling it causes the kernel to select one of these waiting threads and wake it up.
12、Starting with C++11, the C++ standard library exposes kernel mutexes via the
class std::mutex.

13、Some operating systems provide less-expensive alternatives to a mutex. For example, Microsoft Windows provides a locking mechanism known as a critical section.
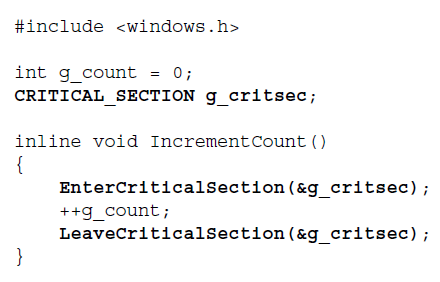
When a thread first attempts to enter (lock) a critical section that is already locked by another thread, an inexpensive spin lock is used to wait until the other thread has left (unlocked) that critical section. A spin lock does not require a context switch into the kernel, making it a few thousand clock cycles cheaper than a mutex.
Linux supports a thing called a “futex” that acts somewhat like a critical section under Windows.
14、condition variable (CV).
we’d like a way to block the consumer thread (put it to sleep) while the producer does its work, and then wake it up when the data is ready to be consumed. This can be accomplished by making use of a new kind of kernel object called a condition variable (CV).
In concurrent programming, we often need to send signals between threads in order to synchronize their activities.
3) wait(). A blocking function that puts the calling thread to sleep.
4) notify(). A non-blocking function that wakes up any threads that are currently asleep waiting on the condition variable.
The sleep and wake operations are performed in an atomic way with the help of a mutex provided by the program, plus a little help from the kernel.


15、Semaphores
a semaphore acts like an atomic counter whose value is never allowed to drop below zero.
3) take() or wait(). If the counter value encapsulated by a given semaphore is greater than zero, this function decrements the counter and returns immediately. If its counter value is currently zero, this function blocks (puts the thread to sleep) until the semaphore’s counter rises above zero again.
4) give(), post() or signal(). Increments the encapsulated counter value by one, thereby opening up a “slot” for another thread to take() the semaphore. If a thread is currently asleep waiting on the semaphore when give() is called, that thread will wake up from its call to take() or wait().7
We say that a semaphore is signaled whenever its count is greater than zero, and it is nonsignaled when its counter is equal to zero.
producer-consumer example, This notification mechanism can be implemented using two binary semaphores. One indicate how many item in buffer, one indicate how many room left.
Queue g_queue;
sem_t g_semUsed; // initialized to 0
sem_t g_semFree; // initialized to 1 void* ProducerThreadSem(void*)
{
// keep on producing forever...
while (true)
{
// produce an item (can be done non-
// atomically because it's local data)
Item item = ProduceItem(); // decrement the free count
// (wait until there's room)
sem_wait(&g_semFree); AddItemToQueue(&g_queue, item); // increment the used count
// (notify consumer that there's data)
sem_post(&g_semUsed);
}
return nullptr;
} void* ConsumerThreadSem(void*)
{
// keep on consuming forever...
while (true)
{
// decrement the used count
// (wait for the data to be ready)
sem_wait(&g_semUsed);
Item item = RemoveItemFromQueue(&g_queue); // increment the free count
// (notify producer that there's room)
sem_post(&g_semFree); // consume the item (can be done non-
// atomically because it's local data)
ConsumeItem(item);
}
return nullptr;
}
16、Implementing a Semaphore
class Semaphore
{
private:
int m_count;
pthread_mutex_t m_mutex;
pthread_cond_t m_cv; public:
explicit Semaphore(int initialCount)
{
m_count = initialCount;
pthread_mutex_init(&m_mutex, nullptr);
pthread_cond_init(&m_cv, nullptr);
}
void Take()
{
pthread_mutex_lock(&m_mutex); // put the thread to sleep as long as
// the count is zero
while (m_count == )
pthread_cond_wait(&m_cv, &m_mutex); --m_count; pthread_mutex_unlock(&m_mutex);
} void Give()
{
pthread_mutex_lock(&m_mutex);
++m_count; // if the count was zero before the
// increment, wake up a waiting thread
if (m_count == )
pthread_cond_signal(&m_cv); pthread_mutex_unlock(&m_mutex);
} // aliases for other commonly-used function names
void Wait() { Take(); }
void Post() { Give(); }
void Signal() { Give(); }
void Down() { Take(); }
void Up() { Give(); }
void P() { Take(); } // Dutch "proberen" = "test"
void V() { Give(); } // Dutch "verhogen" =
// "increment"
};
17、DeadLock
如果依赖图中有环,则必定有 DeadLock.
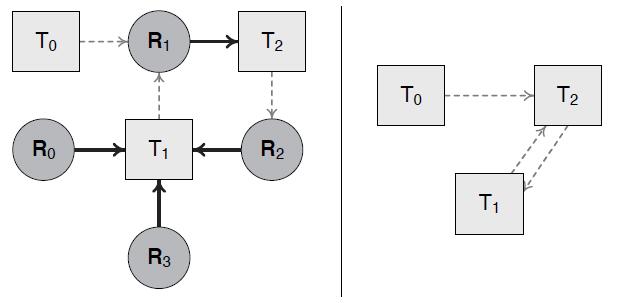
there are four necessary and sufficient conditions for deadlock, known as the Coffman conditions:
1)Mutual exclusive
2)Hold and wait
3)No lock preemption: No one (not even the kernel) is allowed to forcibly break a lock held by a sleeping thread.
4)Circular wait.
The circular wait condition can be avoided if Resource A and Resource B were both protected by a single lock L, then deadlock could not occur.
The circular wait condition can be avoided by imposing a global order to all lock-taking in the system.
18、Live Lock
two threads 1 and 2 contending over two resources A and B. Whenever a thread is unable to obtain a lock, it releases any locks it already holds and waits for a fixed timeout before trying again. If both threads use the same timeout, we can get into a situation in which the same degenerate situation simply repeats over and over. Our threads become “stuck” forever trying to resolve the conflict, and neither one ever gets a chance to do its real job. Livelock is akin to a stalemate in chess.
19、Starvation
Starvation is defined as any situation in which one or more threads fail to receive any execution time on the CPU.
20、Priority Inversion
Consider two threads, L and H, with a low and high priority, respectively. Thread L takes a mutex lock and then is preempted by H. If H attempts to take this same lock, then H will be put to sleep because L already holds the lock. This permits L to run even though it is lower priority than H—in violation of the principle that lower-priority threads should not run while a higher-priority thread is runnable.
21、Transaction-Based Algorithms
A transaction can be more precisely defined as an indivisible bundle of resources and/or operations. Threads in a concurrent system submit transaction requests to a central arbiter of some kind. A transaction either succeeds in its entirety, or it fails in its entirety (because some other thread’s transaction is actively being processed when the request arrives). If the transaction fails, its thread keeps resubmitting the transaction request until it succeeds (possibly waiting for a short time between retries).
22、Minimizing Contention
consider a group of threads that are producing data and storing it into a central repository. Every time one of these threads attempts to store its data in the repository, it contends with all of the other threads for this shared resource.
A simple solution that can sometimes work is to give each thread its own private repository. The threads can now produce data independently of one another, with no contention.
23、Lock-Free Concurrency
“lock-free” refers to the practice of preventing threads from going to sleep while waiting on a resource to become available. In other words, in lock-free programming we never allow a thread to block. So perhaps the term “blocking-free” would have been more descriptive.
Lock-free programming is actually just one of a collection of non-blocking concurrent programming techniques.
1)Blocking
2)Obstruction freedom:guarantee that a single thread will always complete its work in a bounded number of steps, when all of the other threads in the system are suddenly suspended. No algorithm that uses a mutex lock or spin lock can be obstruction-free.
不论其他线程什么时候停住,都不会影响本线程执行完毕。
使用了 mutex lock、spin lock 的线程都无法满足 Obstruction freedom。
3)Lock freedom: if one thread is arbitrarily suspended, all others can still make progress. it can allow some threads to starve. In other words, certain threads might get stuck in a loop of failing and retrying their transactions indefinitely, while other
threads’ transactions always succeed.
不论本线程什么时候停住,都不会影响其他线程。
使用了 mutex lock、spin lock 的线程都无法满足 Lock freedom。
4)Wait freedom:A wait-free algorithm provides all the guarantees of lock freedom, but also guarantees starvation freedom.
The term “lock-free programming” is sometimes used loosely to refer to any algorithm that avoids blocking, but technically speaking the correct term for obstruction-free, lock-free and wait-free algorithms as a whole is “non-blocking algorithm.”
23.1、Causes of Data Race Bugs
• via the interruption of one critical operation by another,
• by the instruction reordering optimizations performed by the compiler and CPU, and
• as a result of hardware-specific memory ordering semantics.
24、Atomicity by Disabling Interrupts
To prevent other threads from interrupting our operation, we could try disabling interrupts just prior to performing the operation, making sure to reenable them after the operation has been completed.
Interrupts are disabled by executing a machine language instruction (such as cli, “clear interrupt enable bit,” on an Intel x86 architecture). But this kind of instruction only affects the core that executed it.
25、Atomic Instructions
There are most certainly some machine language instructions that can never be assumed to execute atomically. Other instructions are atomic, but only when operating on certain kinds of data.
Some CPUs permit virtually any instruction to be forced to execute atomically by specifying a prefix on the instruction in assembly language. (The Intel x86 ISA’s lock prefix is one example.)
In fact, it is the existence of these atomic instructions that permits us to implement atomicity tools such as mutexes and spin locks
26、Atomic Reads and Writes
Misaligned reads and writes usually don’t have this atomicity property. This is because in order to read or write a misaligned object, the CPU usually composes two aligned memory accesses.
27、Atomic Read-Modify-Write
All modern CPUs support concurrency by providing at least one atomic read-modify-write (RMW) instruction.
The simplest RMW instruction is known as test-and-set (TAS). Rather, it atomically sets a Boolean variable to 1 (true) and returns its previous value.

设为 true,再返回值。下面是 TAS的应用,多个线程竞争,只有一个线程能够拿到 pLock 为 false的状态,其余线程拿到的均为 true,从而保证每个时刻只有一个线程运行。

28、Exchange
Some ISAs like Intel x86 offer an atomic exchange instruction. This instruction swaps the contents of two registers, or a register and a location in memory.

上例 Exchange 用意和 TAS 一样。pLock 每次均会被置为 true,且只有一个线程能获得值为 false 的 pLock。
29、Compare and Swap
The behavior of the CAS instruction is illustrated by the following pseudocode:

CAS 的语义,把后续的 write,与前置的read 绑定在一起。
CAS实现 Spin Lock

CAS实现原子增。

On the Intel x86 ISA, the CAS instruction is called cmpxchg, and it can be emitted with Visual Studio’s _InterlockedCompareExchange() compiler intrinsic.
30、ABA Problem
31、Load Linked/Store Conditional
LL/SC 可以解决 ABA Problem。
The load linked instruction reads the value of a memory location atomically, and also stores the address in a special CPU register known as the link register.
The store conditional instruction writes a value into the given address, but only if the address matches the contents of the link register. It returns true if the write succeeded, or false if it failed. Any write operation on the bus (including a store conditional) clears the link register to zero.
This means that an LL/SC instruction pair is capable of detecting data races, because if any write occurs between the LL and SC instructions, the SC will fail.
Here’s how we’d implement an atomic increment using LL/SC:

CAS 需要与 oldValue 比较,确认后才写入 newValue。而 _sc 需要与 linked register 比较,确认后才写入 newValue。
32、Advantages of LL/SC over CAS
First, because the SC instruction fails whenever any write is performed on the bus, an LL/SC pair is not prone to the ABA problem.
33、Strong and Weak Compare-Exchange
Because of the possibility of spurious failures of the store-conditional instruction, C++11 provides two varieties of compare-exchange: strong and weak. Strong compare-exchange “hides” spurious SC failures from the programmer, while weak compare-exchange does not.
34、How Instruction Reordering Causes Concurrency Bugs
The thread synchronization primitives provided by the operating system (mutexes et al.) are carefully crafted to avoid the concurrency bugs that can be caused by instruction reordering optimizations. But now that we’re investigating how mutexes are implemented, let’s take a look at how to avoid these problems manually.
mutex 等 primitives 可以避免 instructino reordering optimizations 问题。下面的文章会说明如何不使用 mutex 等,手动地避免 reordering 问题。
int32_t g_data = ;
int32_t g_ready = ; void ProducerThread()
{
// produce some data
g_data = ; // inform the consumer
g_ready = ;
} void ConsumerThread()
{
// wait for the data to be ready
while (!g_ready)
PAUSE(); // consume the data
ASSERT(g_data == );
}
there’s nothing to prevent the compiler or the CPU’s out-of-order execution logic from reordering the producer’s write of 1 into g_ready so that it occurs before the write of 42 into g_data. Likewise, in theory the compiler could reorder the consumer’s check that g_data is equal to 42 so that it happens before the while loop. So even though all of our reads and writes are atomic, this code may not behave reliably..
reordering 实际上发生在Machine Language级别。
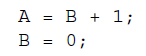


If a second thread were waiting for B to become zero before reading the value of A, it would cease to function correctly if this compiler optimization were to be applied.
35、Volatile in C/C++ (and Why It Doesn’t Help Us)
In C and C++, the volatile type qualifier guarantees that consecutive reads or writes of a variable cannot be “optimized away” by the compiler.
The only guarantee it provides is that the contents of a variable marked volatile won’t be cached in a register—the variable’s value will be re-read directly from memory every time it’s accessed.
Moreover, the volatile keyword in C/C++ does nothing to prevent the CPU’s out-of-order execution logic from reordering the instructions at runtime.
36、Compiler Barriers
With GCC, a compiler barrier can be inserted via some inline assembly syntax ; under Microsoft Visual C++, the compiler intrinsic _ReadWriteBarrier() has the same effect.

most function calls serve as an implicit compiler barrier. This makes sense, because the compiler doesn’t know anything about the side effects of a function call.
However compiler barriers don’t prevent the CPU’s out-of-order execution logic from reordering instructions at runtime.
we’ll learn about a collection of machine language instructions known as memory fences which serve as instruction reordering barriers for both the compiler and the CPU,
37、
38、
Game Engine Architecture 4的更多相关文章
- Game Engine Architecture 11
[Game Engine Architecture 11] 1.three most-common techniques used in modern game engines. 1)Cel Anim ...
- Game Engine Architecture 10
[Game Engine Architecture 10] 1.Full-Screen Antialiasing (FSAA) also known as super-sampled antialia ...
- Game Engine Architecture 9
[Game Engine Architecture 9] 1.Formatted Output with OutputDebugString() int VDebugPrintF(const char ...
- Game Engine Architecture 8
[Game Engine Architecture 8] 1.Differences across Operating Systems • UNIX uses a forward slash (/) ...
- Game Engine Architecture 7
[Game Engine Architecture 7] 1.SRT Transformations When a quaternion is combined with a translation ...
- Game Engine Architecture 6
[Game Engine Architecture 6] 1.Data-Parallel Computations A GPU is a specialized coprocessor designe ...
- Game Engine Architecture 5
[Game Engine Architecture 5] 1.Memory Ordering Semantics These mysterious and vexing problems can on ...
- Game Engine Architecture 3
[Game Engine Architecture 3] 1.Computing performance—typically measured in millions of instructions ...
- Game Engine Architecture 2
[Game Engine Architecture 2] 1.endian swap 函数 floating-point endian-swapping:将浮点指针reinterpert_cast 成 ...
随机推荐
- 【PLM】【PDM】60页PPT终于说清了PDM和PLM的区别;智造时代,PLM系统10大应用趋势!
https://blog.csdn.net/np4rhi455vg29y2/article/details/79266738
- 判断文件是否存在,不要用if exist和if not exist,因为他们会受到文件是否隐藏的影响,改用dir /a 命令代替
@echo off & setlocal enabledelayedexpansionrem 判断文件是否存在,不要用if exist和if not exist,因为他们会受到文件是否隐藏的影 ...
- Unix即IDE
前言 在图形界面下大家都想要这种能够集成在一起的工具,那是因为这类窗口应用除了用复制粘贴,没有别的方法使他们更好地协同工作,它们缺失一种 共用接口(common interface) . 有关这个问题 ...
- HttpURLConnection 传输数据和下载图片
一.传输字符串数据 在Android中HttpURLConnection传输数据是必不可少的,我们继续在“AsyncTask(异步任务)”案例的基础上添加. 案例: 首先我们做一个jsp的服务端,文件 ...
- Metabase研究 开源的数据报表
https://blog.csdn.net/bin330720911/article/details/79273317 https://blog.csdn.net/qq_35902833/articl ...
- note 8 字符串
字符串String 一个字符的序列 使用成对的单引号或双引号括起来 或者三引号""" 和 ''' 表示块注释 字符串运算 长度 len()函数 first_name = ...
- ABAP其实也是挺好的语言
目前工作当中使用的编程语言是SAP平台的ABPA语言,出于好奇心,我想把之前用JAVA(用C++也写过,事实上,我每学一个新的语言,就会尝试去实现这个小程序)写过的计算一个正整数的因子的程序用ABAP ...
- css选择器区别
空格选择器 ul li 选择ul 下面的所有li 元素 大于号选择器 ul>li 选择ul 下面的直接子元素 只能是儿子辈的 不能是孙子辈的
- 如何确保Memcache数据读写操作的原子性(转)
什么是CAS协议 Memcached于1.2.4版本新增CAS(Check and Set)协议类同于Java并发的CAS(Compare and Swap)原子操作,处理同一item被多个线程更改过 ...
- js小技巧总结
js小技巧总结 1.Array.includes条件判断 function test(fruit) { const redFruits = ["apple", "stra ...