Hbase原理| 优化
GFS -->hdfs
mapreduce --->hadoop mr
bigtable-->hbase
HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统
海量存储;列式存储;极易扩展;高并发;稀疏(针对HBase列的灵活性,在列族中,你可以指定任意多的列;稀疏性体现了它的非结构化特点)
hbase是一个基于hdfs的列式存储系统,可以用廉价pc组建集群,对10亿行百万列的数据量级提供随机实时读写。
标示 列族
rowkey column family
列族中有若干列,列并不是它的结构;
1. HBase的安装
1 Zookeeper正常部署
首先保证Zookeeper集群的正常部署,并启动之
[kris@hadoop101 zookeeper-3.4.]$ bin/zkServer.sh start
[kris@hadoop102 zookeeper-3.4.]$ bin/zkServer.sh start
[kris@hadoop103 zookeeper-3.4.]$ bin/zkServer.sh start
2 Hadoop正常部署
Hadoop集群的正常部署并启动
[kris@hadoop101 hadoop-2.7.]$ sbin/start-dfs.sh
[kris@hadoop102 hadoop-2.7.]$ sbin/start-yarn.sh
3 HBase解压
解压HBase到指定目录
[kris@hadoop101 software]$ tar -zxvf hbase-1.3.1-bin.tar.gz -C /opt/module
4 HBase配置
修改HBase对应的配置文件
1)hbase-env.sh修改内容,声明jdk路径,并且hbase自带的zookeeper设置为false
export JAVA_HOME=/opt/module/jdk1..0_144
export HBASE_MANAGES_ZK=false
2)hbase-site.xml修改内容
<configuration>
<!-- Hbase在hadoop的存储路径 ,存储在/hbase的路径下 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop101:9000/hbase</value>
</property>
<!-- 开启完全分布式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property> <!-- Hbase的master端口号 .98后的新变动,之前版本没有.port,默认端口为60000(可省略) -->
<property>
<name>hbase.master.port</name>
<value></value>
</property> <property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop101,hadoop102,hadoop103</value>
</property> <!-- 具体hbase的存储路径, 参照zk的zoo.cfg文件中的dataDir值 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/module/zookeeper-3.4./zkData</value>
</property>
<!-- Hbase关闭流的配置,(只适用于本地模式),完全分布式和伪分布式都得关闭 -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property> </configuration>
说明:hbase.rootdir:这个目录是region server的共享目录,用来持久化Hbase 。
hbase.cluster.distributed :Hbase的运行模式。false是单机模式,true是分布式模式。若为false,Hbase和Zookeeper会运行在同一个JVM里面。
3)hbase/conf/regionservers
hadoop101
hadoop102
hadoop103
在conf创建一个文件名为backup-masters,并且在这文件里添加hadoop102的域名
[root@hadoop101 hbase]# vim conf/backup-masters
hadoop102
4)软连接hadoop配置文件到HBase,core-site.xml、hdfs-site.xml
[kris@hadoop101 module]$ ln -s /opt/module/hadoop-2.7./etc/hadoop/core-site.xml /opt/module/hbase/conf/core-site.xml
[kris@hadoop101 module]$ ln -s /opt/module/hadoop-2.7./etc/hadoop/hdfs-site.xml /opt/module/hbase/conf/hdfs-site.xml
5 HBase发送到其他集群
[kris@hadoop101 module]$ xsync hbase/
并配置hbase环境变量
[root@hadoop101 module]# vim /etc/profile
#HBASE_HOME
export HBASE_HOME=/opt/module/hbase-2.2.
export PATH=$PATH:$HBASE_HOME/bin
[root@hadoop101 module]# source /etc/profile
[root@hadoop102 module]# vim /etc/profile
#HBASE_HOME
export HBASE_HOME=/opt/module/hbase-2.2.
export PATH=$PATH:$HBASE_HOME/bin
[root@hadoop102 module]# source /etc/profile
[root@hadoop103 module]# vim /etc/profile
#HBASE_HOME
export HBASE_HOME=/opt/module/hbase-2.2.
export PATH=$PATH:$HBASE_HOME/bin
[root@hadoop103 module]# source /etc/profile
6 HBase服务启动
1)启动方式1
启动前确保时间是同步的;因为要hbase有version,所以要保证时间的一致性
[kris@hadoop101 ~]$ date
2019年 03月 05日 星期二 :: CST
[kris@hadoop102 module]$ date
2019年 03月 05日 星期二 :: CST
[kris@hadoop103 ~]$ date
2019年 03月 05日 星期二 :: CST
[kris@hadoop101 hbase]$ bin/hbase-daemon.sh start master
[kris@hadoop101 hbase]$ bin/hbase-daemon.sh start regionserver
提示:如果集群之间的节点时间不同步,会导致regionserver无法启动,抛出ClockOutOfSyncException异常。
修复提示:
a、同步时间服务
b、属性:hbase.master.maxclockskew设置更大的值
<property>
<name>hbase.master.maxclockskew</name>
<value></value>
<description>Time difference of regionserver from master</description>
</property>
2)启动方式2
[kris@hadoop101 hbase]$ bin/start-hbase.sh
对应的停止服务:
[kris@hadoop101 hbase]$ bin/stop-hbase.sh
7 查看HBase页面
启动成功后,可以通过“host:port”的方式来访问HBase管理页面,例如:
http://hadoop101:16010
jar包冲突//启动时若出现hadoop和hbase下的jar包冲突,可删掉一个;不删也不影响运行
[kris@hadoop101 lib]$ rm -rf slf4j-log4j12-1.7..jar
2. HBase Shell操作
)进入HBase客户端命令行
[kris@hadoop101 hbase]$ bin/hbase shell
)查看帮助命令
hbase(main)::> help
hbase(main)::> help ‘create’
)查看当前数据库中有哪些表
查看所有的数据库:list_namespace
查看某个数据库下的所有表:list_namespace_tables ‘库名’
查看所有表: list namespace相关的操作
create_namespace 'my_ns'
drop_namespace 'my_ns'
alter_namespace 'my_ns', {METHOD => 'set', 'PROPERTY_NAME' => 'PROPERTY_VALUE'}
建表
create 表名 , 列族中有若干列
create 'student', 'cf1'
desc 'student' A. 对于不存在的表的添加方式: 创建预分区、SNAPPY压缩
表在刚刚被创建时,只有1个分区(region),当一个region过大(达到hbase.hregion.max.filesize属性中定义的阈值,默认10GB)时,
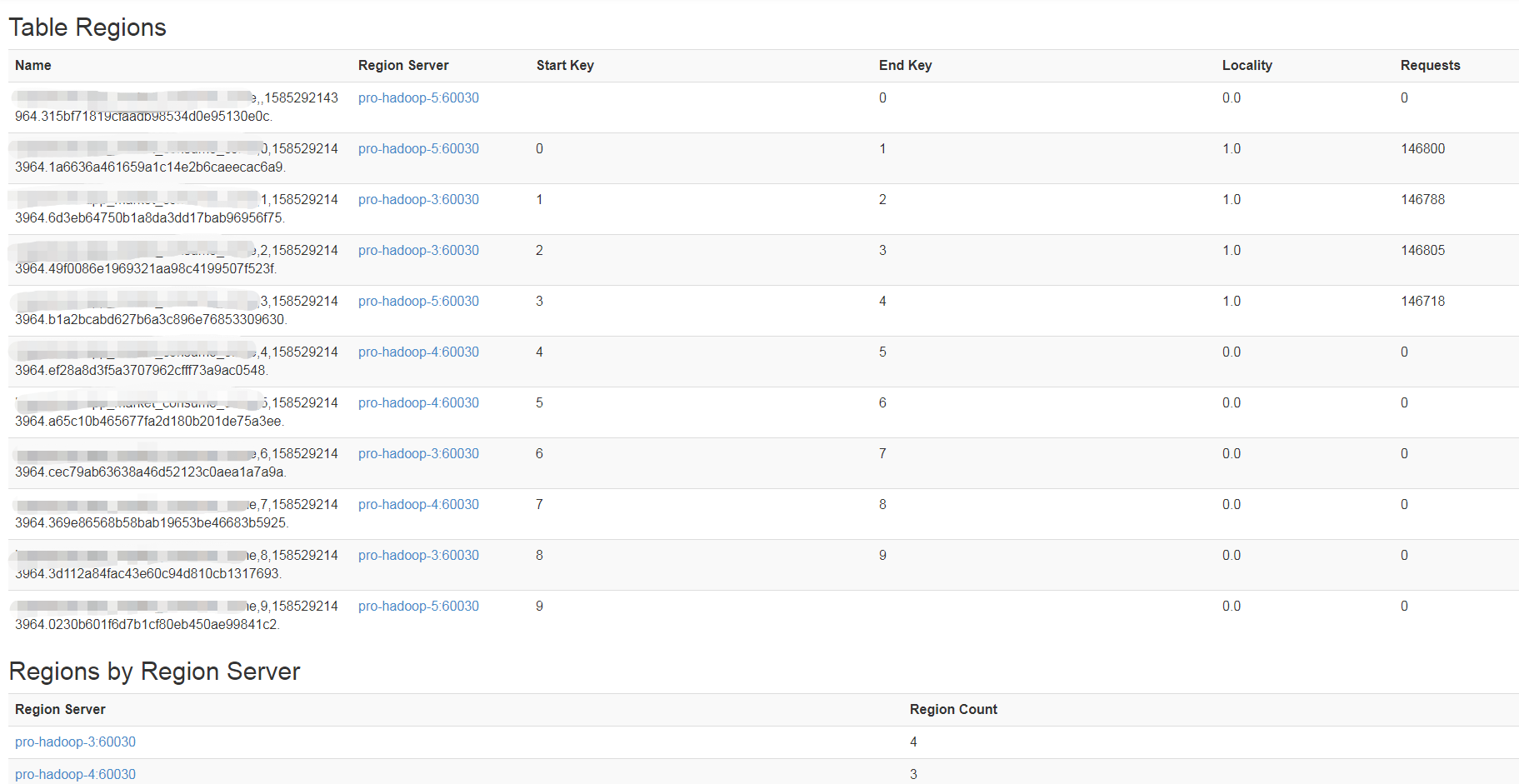
表将会进行split,分裂为2个分区。表在进行split的时候,会耗费大量的资源,频繁的分区对HBase的性能有巨大的影响。HBase提供了预分区功能,即用户可以在创建表的时候对表按照一定的规则分区。 预分区:可以减少由于region split带来的资源消耗。从而提高HBase的性能。 create 'hopsonone:app_consume', {NAME => 'info', VERSIONS => , COMPRESSION => 'snappy'}, SPLITS => ['','','','','','','','','',''] 查看HDFS可以看到这个表下有10个文件夹(如果没有预分区,则只有一个文件夹):
[easylife@pro-hadoop- log]$ hdfs dfs -ls /hbase/data/hopsonone/app_market_consume_come
Found items
drwxr-xr-x - hbase hbase -- : /hbase/data/hopsonone/app_consume/.tabledesc
drwxr-xr-x - hbase hbase -- : /hbase/data/hopsonone/app_consume/.tmp
drwxr-xr-x - hbase hbase -- : /hbase/data/hopsonone/app_consume/0230b601f6d7b1cf80eb450ae99841c2
drwxr-xr-x - hbase hbase -- : /hbase/data/hopsonone/app_consume/1a6636a461659a1c14e2b6caeecac6a9
drwxr-xr-x - hbase hbase -- : /hbase/data/hopsonone/app_consume/315bf71819cfaadb98534d0e95130e0c
drwxr-xr-x - hbase hbase -- : /hbase/data/hopsonone/app_consume/369e86568b58bab19653be46683b5925
drwxr-xr-x - hbase hbase -- : /hbase/data/hopsonone/app_consume/3d112a84fac43e60c94d810cb1317693
drwxr-xr-x - hbase hbase -- : /hbase/data/hopsonone/app__consume/49f0086e1969321aa98c4199507f523f
drwxr-xr-x - hbase hbase -- : /hbase/data/hopsonone/app_consume/6d3eb64750b1a8da3dd17bab96956f75
drwxr-xr-x - hbase hbase -- : /hbase/data/hopsonone/app_consume/a65c10b465677fa2d180b201de75a3ee
drwxr-xr-x - hbase hbase -- : /hbase/data/hopsonone/app_consume/b1a2bcabd627b6a3c896e76853309630
drwxr-xr-x - hbase hbase -- : /hbase/data/hopsonone/app_consume/cec79ab63638a46d52123c0aea1a7a9a
drwxr-xr-x - hbase hbase -- : /hbase/data/hopsonone/app_consume/ef28a8d3f5a3707962cfff73a9ac0548 手动分区:(一开始没有分区)
使用切分键 ‘’ 一分为二:
hbase(main)::> split 'hopsonone:app_consume', 'splitKey'
hbase(main)::> split 'hopsonone:app_consume_','' 继续将第二个Region进行切分,以’’作为切分键:
hbase(main)::> split 'hopsonone:app_consume,1,1588043248742','' 合并分区:
hbase(main)::> merge_region '847db2576ef2492b049c806fc46dcb47','7d084c88b65397304a18a7b982998c8d',true
B. 对于一个已经存在的表,修改其压缩方式,并对之前的旧数据生效的方式:
disable '表名'
alter '表名', {NAME => '列族名',VERSION => , COMPRESSION => 'snappy'} //注意修改压缩时必须一个列族一个列族的修改;
enable '表名' 这只是能让新数据使用SNAPPY压缩方式,如果旧数据也要采用压缩的话,需要执行
major_compact '表名' //不要在表繁忙期间执行此操作 执行完毕后可以去hdfs上验证压缩是否生效:
hadoop fs -du -s -h /hbase/data/default(namespace名称)/(表名) 如果你要删除压缩方式,步骤和上述步骤一致,唯一不一样的是:
alter '表名', NAME => '列族名', COMPRESSION => 'none' C. TTL 用的少
create 't1', {NAME =>'f1', TTL => }, SPLITS => ['', '', '', '']
TTL=>的更新超时时间是指:该列最后更新的时间,到超时时间的限制,而不是第一次创建,到超时时间;
TTL的概念只针对CELL
增 put 'table', 'rowkey', 'cfName:filed', 'value' -- 隐式列rowkey
put 'default:student', '', 'cf1:name', 'alex'
put 'default:student', '', 'cf1:salary', ''
put 'default:student', '', 'cf1:hoby', 'java'
scan 'default:student'
改
put 'default:student', '', 'cf1:hoby', 'math'
查 scan 'table',{STARTROW => '', STOPROW => ''} | get 'table','rowkey' | get 'table', 'rowkey', 'cf:filed'
scan 'default:student', {STARTROW=>'', STOPROW=>''}
scan 'default:student', {STARTROW=>''}
scan 'default:student', {LIMIT => 5} scan 'student', {STOPROW=>''}
get 'student', '', 'cf1:name' get 'student', '', 'cf1:name' 删
删除数据:
delete 'student', '', 'cf1:name' //删除指定列的数据
deleteall 'student', '' //删除rowkey的全部数据
清空数据:
truncate 'default:student' //清空数据,包括表的预分区等
truncate_preserve 'default:student' //只清空数据,不清空表预分区;
删除表:
disable 'student'
drop 'student'
hbase(main)::> count 'student'
row(s) in 0.0230 seconds
=> rowkey是根据自动字典排序的
快照
创建快照:
snapshot 'one:tmp_cookie','snapshot_cookie' hbase(main)::> list_snapshots 'snapshot_cookie'
SNAPSHOT TABLE + CREATION TIME
snapshot_cookie one:tmp_cookie (Tue Apr :: + )
row(s) in 0.0160 seconds
=> ["snapshot_cookie"]
hadoop fs -ls -R /hbase/.hbase-snapshot
drwxr-xr-x - hbase hbase -- : /hbase/.hbase-snapshot/.tmp
drwxr-xr-x - hbase hbase -- : /hbase/.hbase-snapshot/snapshot_cookie
-rw-r--r-- hbase hbase -- : /hbase/.hbase-snapshot/snapshot_cookie/.snapshotinfo
-rw-r--r-- hbase hbase -- : /hbase/.hbase-snapshot/snapshot_cookie/data.manifest
克隆快照:
hbase(main)::> clone_snapshot 'snapshot_cookie','one:clone_cookie'
row(s) in 0.7270 seconds
put 'hopsonone:tmp_cookie','','info:pv',''
恢复快照:
hbase(main)::> disable 'one:tmp_cookie'
row(s) in 2.3620 seconds hbase(main)::> restore_snapshot 'snapshot_cookie'
row(s) in 0.7670 seconds hbase(main)::> enable 'one:tmp_cookie'
row(s) in 2.2440 seconds
version版本,毫秒数时间戳即默认版本号,scan默认的是加载最新的版本号的数据;
RAW最原始数据;VERSION=>4是本次查询可以看到4个版本的值
它是没有真正的修改,只是在后边追加
flush由内存到hdfs,不是最新的就会丢弃
长整型longint,也可自定义 倒叙排列
hbase(main)::> create 'stu1', 'cf1', {NAME=>'cf2', VERSIONS=>}
row(s) in 1.2800 seconds
=> Hbase::Table - stu1
hbase(main)::> desc 'stu1'
Table stu1 is ENABLED
stu1
COLUMN FAMILIES DESCRIPTION
{NAME => 'cf1', BLOOMFILTER => 'ROW', VERSIONS => '', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENC
ODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '', BLOCKCACHE => 'true', BLOCKSIZE => '',
REPLICATION_SCOPE => ''}
{NAME => 'cf2', BLOOMFILTER => 'ROW', VERSIONS => '', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENC
ODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '', BLOCKCACHE => 'true', BLOCKSIZE => '',
REPLICATION_SCOPE => ''}
row(s) in 0.0260 seconds
往里put数据
hbase(main)::> put 'stu1', '', 'cf1:name', 'alex1'
row(s) in 0.1060 seconds hbase(main)::> put 'stu1', '', 'cf1:name', 'alex2'
row(s) in 0.0090 seconds hbase(main)::> put 'stu1', '', 'cf1:name', 'alex3'
row(s) in 0.0050 seconds hbase(main)::> put 'stu1', '', 'cf1:name', 'alex4'
row(s) in 0.0060 seconds hbase(main)::> put 'stu1', '', 'cf1:name', 'alex5'
row(s) in 0.0050 seconds hbase(main)::> put 'stu1', '', 'cf2:name', 'kris1'
row(s) in 0.0090 seconds hbase(main)::> put 'stu1', '', 'cf2:name', 'kris2'
row(s) in 0.0110 seconds hbase(main)::> put 'stu1', '', 'cf2:name', 'kris3'
row(s) in 0.0060 seconds hbase(main)::> put 'stu1', '', 'cf2:name', 'kris4'
row(s) in 0.0060 seconds hbase(main)::> put 'stu1', '', 'cf2:name', 'kris5'
row(s) in 0.0060 seconds
hbase(main)::> scan 'stu1'
ROW COLUMN+CELL
column=cf1:name, timestamp=, value=alex5
column=cf2:name, timestamp=, value=kris5
row(s) in 0.0140 seconds
hbase(main)::> scan 'stu1', {VERSIONS=>, RAW=>true}
ROW COLUMN+CELL
column=cf1:name, timestamp=, value=alex5
column=cf1:name, timestamp=, value=alex4
column=cf1:name, timestamp=, value=alex3
column=cf1:name, timestamp=, value=alex2
column=cf1:name, timestamp=, value=alex1
column=cf2:name, timestamp=, value=kris5
column=cf2:name, timestamp=, value=kris4
column=cf2:name, timestamp=, value=kris3
column=cf2:name, timestamp=, value=kris2
column=cf2:name, timestamp=, value=kris1
row(s) in 0.0240 seconds hbase(main)::> flush 'stu1'
row(s) in 0.4880 seconds hbase(main)::> scan 'stu1', {VERSIONS=>, RAW=>true}
ROW COLUMN+CELL
column=cf1:name, timestamp=, value=alex5
column=cf2:name, timestamp=, value=kris5
column=cf2:name, timestamp=, value=kris4
column=cf2:name, timestamp=, value=kris3
row(s) in 0.0390 seconds
墓碑数据
删除会把删掉的数据让他们成为墓碑
会新增一条最新的墓碑数据
会存到hdfs,但最终会被删除
hbase(main)::> put 'stu1', '', 'cf1:age', ''
row(s) in 0.0430 seconds
hbase(main)::> put 'stu1', '', 'cf1:name', 'alex6'
row(s) in 0.0060 seconds hbase(main)::> scan 'stu1', {VERSIONS=>, RAW=>true}
ROW COLUMN+CELL
column=cf1:age, timestamp=, value=
column=cf1:name, timestamp=, value=alex6
column=cf1:name, timestamp=, value=alex5
column=cf2:name, timestamp=, value=kris5
column=cf2:name, timestamp=, value=kris4
column=cf2:name, timestamp=, value=kris3
row(s) in 0.0110 seconds hbase(main)::> delete 'stu1', '', 'cf1:name'
row(s) in 0.0580 seconds hbase(main)::> scan 'stu1'
ROW COLUMN+CELL
column=cf1:age, timestamp=, value=
column=cf2:name, timestamp=, value=kris5
row(s) in 0.0160 seconds hbase(main)::> scan 'stu1', {VERSIONS=>, RAW=>true}
ROW COLUMN+CELL
column=cf1:age, timestamp=, value=
column=cf1:name, timestamp=, type=DeleteColumn
column=cf1:name, timestamp=, value=alex6
column=cf1:name, timestamp=, value=alex5
column=cf2:name, timestamp=, value=kris5
column=cf2:name, timestamp=, value=kris4
column=cf2:name, timestamp=, value=kris3
row(s) in 0.0170 seconds
Hbase原理| 优化的更多相关文章
- HBase原理、设计与优化实践
转自:http://www.open-open.com/lib/view/open1449891885004.html 1.HBase 简介 HBase —— Hadoop Database的简称,G ...
- hbase读写优化
一.hbase读优化 客户端优化 1.scan缓存是否设置合理? 优化原理:一次scan请求,实际并不会一次就将所有数据加载到本地,而是多次RPC请求进行加载.默认100条数据大小. 优化建议:大sc ...
- HBase笔记:对HBase原理的简单理解
早些时候学习hadoop的技术,我一直对里面两项技术倍感困惑,一个是zookeeper,一个就是Hbase了.现在有机会专职做大数据相关的项目,终于看到了HBase实战的项目,也因此有机会搞懂Hbas ...
- Hbase原理
Hbase原理 概述 HBase是一个构建在HDFS上的分布式列存储系统:HBase是基于Google BigTable模型开发的,典型的key/value系统:HBase是Apache Hadoop ...
- hbase性能优化总结
hbase性能优化总结 1. 表的设计 1.1 Pre-Creating Regions 默认情况下,在创建HBase表的时候会自动创建一个region分区,当导入数据的时候,所有的HBase客户端都 ...
- Hadoop生态圈-HBase性能优化
Hadoop生态圈-HBase性能优化 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- HBase性能优化方法总结(转)
原文链接:HBase性能优化方法总结(一):表的设计 本文主要是从HBase应用程序设计与开发的角度,总结几种常用的性能优化方法.有关HBase系统配置级别的优化,可参考:淘宝Ken Wu同学的博客. ...
- HBase参数优化
zookeeper.session.timeout默认值:3分钟(180000ms)说明:RegionServer与Zookeeper间的连接超时时间.当超时时间到后,ReigonServer会被Zo ...
- HBASE的优化、hadoop通用优化,Linux优化,zookeeper优化,基础优化
HBase 的优化3.1.高可用在 HBase 中 Hmaster 负责监控 RegionServer 的生命周期,均衡 RegionServer 的负载,如果Hmaster 挂掉了,那么整个 HBa ...
随机推荐
- Django 中间件 请求前
中间件: class TestMiddleware(object): """中间件类""" def __init__(self): &quo ...
- scrapy-redis(调度器Scheduler源码分析)
settings里面的配置:'''当下面配置了这个(scrapy-redis)时候,下面的调度器已经配置在scrapy-redis里面了'''##########连接配置######## REDIS_ ...
- Linux学习之CentOS(三)--初识linux的文件系统以及用户组等概念
Linux学习之CentOS(三)--初识linux的文件系统以及用户组等概念 进入到了Linux学习之CentOS第三篇了,这篇文章主要记录下对linux文件系统的初步认识,以及用户组.用户权限.文 ...
- 并发性能的隐形杀手之伪共享(false sharing)
在并发编程过程中,我们大部分的焦点都放在如何控制共享变量的访问控制上(代码层面),但是很少人会关注系统硬件及 JVM 底层相关的影响因素.前段时间学习了一个牛X的高性能异步处理框架 Disruptor ...
- spring、springMVC、mybatis配置文件
一.jdbc.properties 文件: driver=com.mysql.jdbc.Driverurl=jdbc:mysql://192.168.31.xxx:3306/abc?useUnicod ...
- js 对象的循环
var car = {type:"Fiat", model:500, color:"white"}; var arr = array(); for(i in c ...
- React基础知识备忘
section-1 //react组件 export class Halo extends React.Component{ constructor(...args){ super(...args); ...
- 关于vue项目去除margin和padding后设置元素width和height为100%后,出现滚动条问题(移动端)
bug点,这个页面设置100%(100vw和100vh).页面出现抖动. 经过一番检察,原因出现在,vue项目自动添加的一个div上.就是body里的最后一个.如果选中这个元素,右键删除它.页面就不会 ...
- 判断三次URL可用性脚本
#!/bin/bash check_url() { HTTP_CODE=$(curl -o /dev/ -s -) ];then continue fi } URL_LIST="www.ba ...
- Jmeter中使用外部的java文件
感觉在Jmeter中使用外部的Java文件比较方便,语法一样,而且可以直接引用,所以个人觉得这个功能还是蛮重要的,特别是在使用Jmeter的过程中,可能需要结合一定的业务场景进行判断等,那使用Jmet ...