Forward团队-爬虫豆瓣top250项目-项目总结
托管平台地址:https://github.com/xyhcq/top250
小组名称:Forward团队
组长:马壮
成员:李志宇、刘子轩、年光宇、邢云淇、张良
我们这次团队项目内容是爬取豆瓣电影TOP250的电影信息,为什么我们选这个项目作为团队项目呢?因为在这个大数据时代,我们总有一些信息需要收集保存,而手动收集信息会很麻烦,所以选了爬取豆瓣TOP250,其实,项目爬取什么网站、内容并不重要,因为我们在这次团队项目中学会了爬虫的工作原理,以后我们想爬取别的网站那都不是事了。
这次团队项目中,我们都有了很大的收获,无论是组员中基础好的还是基础弱的,都是有收获的,可喜可贺!在团队项目中,我们遇到了很多大问题,对于我们来说,很多是可能导致我们项目失败的致命问题,好在经过组员们的不懈努力,刻苦学习,查资料解决了。
程序的开发过程,我们就不提了,在之前的作业里,我们组都有详细的分析,都很详细,下面总结一些我们遇到的问题以及解决办法,这是我们团队项目中收获的最有价值的内容。
在开发之初,我们选择了BeautifulSoup模块,需要在python里安装上这个模块,然而,单单给python安装模块就困扰了我们很久,网上有说用pip install命令安装的,可是当我们尝试时候发现,pip不好使,问了老师,老师说python自带pip的,于是我们在网上各种找资料,终于找到了解决方法:我们安装的python2.7.5里不自带pip,安装了新版本的python(我们试了2.7.11),终于成功解决了pip命令不好使,成功安装上了模块(这个问题浪费了我们好几天)
安完模块,由于我们都是做爬虫零基础的菜鸟,所以我们又在网上找教程学习了一番。
我们学习时候用到的参考资料:
Python中使用Beautiful Soup库的超详细教程
于是我们第一版程序出炉
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
import re
import time
import sys def getHTMLText(url,k):
# 获取网页源代码
try:
if(k==0):
kw={}
else:
kw={'start':k,'filter':''}
# 保存获取的网页
read = requests.get(url,params=kw,headers={'User-Agent': 'Mozilla/4.0'})
read.raise_for_status()
read.encoding = read.apparent_encoding
return read.text
except:
print("获取失败!") def getData(html):
# 分析代码信息,提取数据
soup = BeautifulSoup(html, "html.parser") # 找到第一个class属性值为grid_view的ol标签
movieList=soup.find('ol',attrs={'class':'grid_view'}) # 找到所有的li标签
for movieLi in movieList.find_all('li'):
# 找到第一个class属性值为hd的div标签
movieHd=movieLi.find('div',attrs={'class':'hd'})
# 找到第一个class属性值为title的span标签 # 获取电影名字
movieName=movieHd.find('span',attrs={'class':'title'}).getText()
print movieName # 获取电影链接
movieUrl=movieHd.find('a class="" href="')
print movieUrl # 获取电影导演/演员
movieBd = movieLi.find('div', attrs={'class': 'bd'})
movieSF=movieBd.find('p',attrs={'class':''}).getText()
print movieSF # 获取电影的评分
movieScore=movieLi.find('span',attrs={'class':'rating_num'}).getText()
print movieScore #获取电影的评论数
movieEval=movieLi.find('div',attrs={'class':'star'})
movieEvalNum=re.findall(r'\d+',str(movieEval))[-1]
print movieEvalNum # 获取电影短评
movieQuote = movieLi.find('span', attrs={'class': 'inq'})
# 有的电影没有短评,为防止报错,加次
if(movieQuote):
print movieQuote.getText()
else:
print ('没有短评!') #print '=================================================================' # 本次抓取的网址
basicUrl='https://movie.douban.com/top250'
k=0
i=1 print '===============================魔法开始===============================' while k<=225:
html=getHTMLText(basicUrl,k)
#time.sleep(2)
k+=25
getData(html)
print '-------第'+str(i)+'轮完成!-------'
i+=1 print '完成!'
已经能实现基本功能了
随后,我们开始添加一些新功能,不过随着功能的增多,bug也随之而来:
一开始,我们添加了将爬取结果写入到文件的功能,不过我们发现写入不全,后来发现漏了一句代码:
# 关闭文件,否则容易写入不全
f.close()
加上这句话后,程序就正常了,这次问题提示我们:python写入完文件,一定要关闭文件!
在后来我们测试的时候,发现程序在cmd中运行会乱吗:
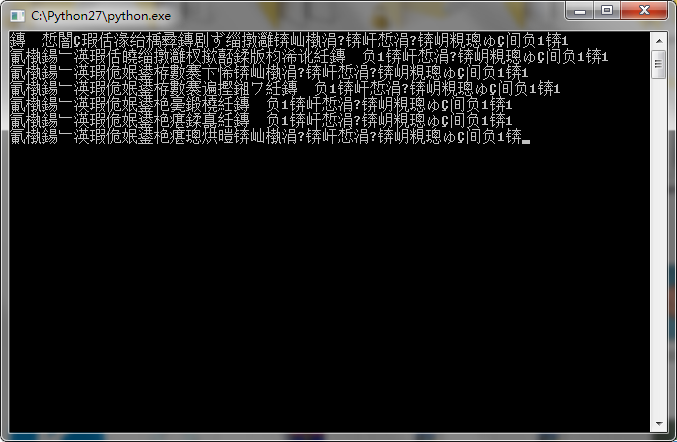
参考了网上的资料,我们解决了问题
将程序中都采用raw_input()的语句都改为:
raw_input(unicode('xxxxxxxxxx','utf-8').encode('gbk'))
程序就正常现实文本了
在程序的各种功能实现后,我们想把程序连带运行库打包,因为程序是用python写的,一般人电脑里不会有这个运行环境,我们考虑了py2exe模块和pyinstaller模块,因为在网上找资料时,pyinstaller某些功能优于py2exe(最主要的是pyinstaller可以把程序的黑窗口隐藏)
参考了网上的教程:
Python | 用Pyinstaller打包发布exe应用
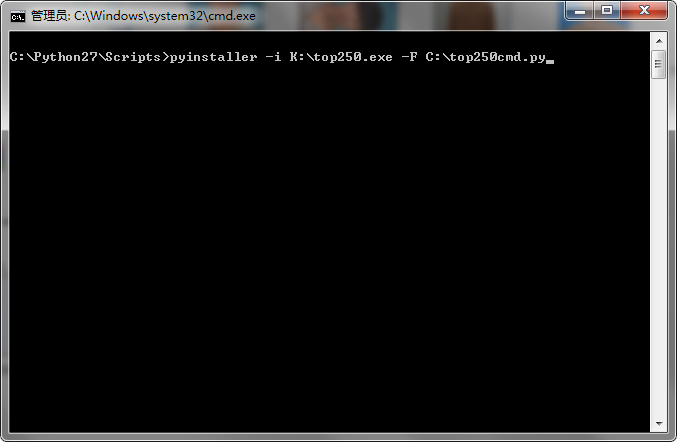
成功打包后,变成了带有运行库的单文件

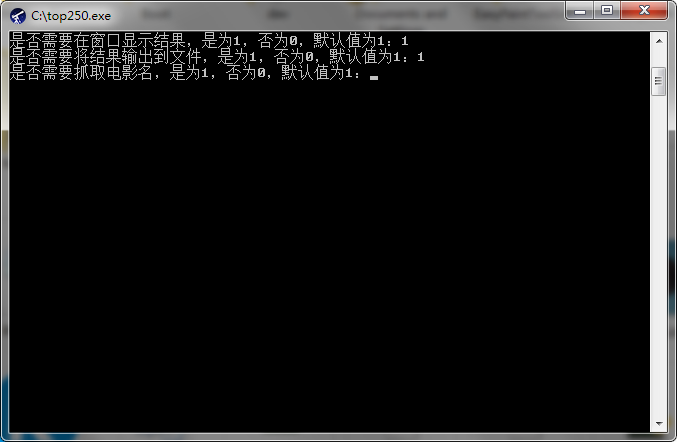
完成!我们又学会了pyinstaller模块的使用。
本次团队项目,我们都是一边学习一边碰壁,磕磕绊绊终于写出了程序,我们都有了很大的收获。
Forward团队-爬虫豆瓣top250项目-项目总结的更多相关文章
- Forward团队-爬虫豆瓣top250项目-项目进度
项目地址:https://github.com/xyhcq/top250 我们的项目是爬取豆瓣top250的电影的信息,在做这个项目前,我们都没有经验,完全是从零开始,过程中也遇到了很多困难,不过我们 ...
- Forward团队-爬虫豆瓣top250项目-最终程序
托管平台地址:https://github.com/xyhcq/top250 小组名称:Forward团队 小组成员合照: 程序运行方法: 在python中打开程序并运行:或者直接执行程序即可运行 程 ...
- 《Forward团队-爬虫豆瓣top250项目-开发文档》
码云地址:https://github.com/xyhcq/top250 模块功能:获取豆瓣top250网页的源代码,并分析. def getHTMLText(url,k): # 获取网页源代码 tr ...
- Forward团队-爬虫豆瓣top250项目-开发文档
项目地址:https://github.com/xyhcq/top250 我在本次项目中负责写爬虫中对数据分析的一部分,根据马壮分析过的html,我来进一步写代码获取数据,具体的功能及实现方法我已经写 ...
- Forward团队-爬虫豆瓣top250项目-模块测试
项目托管平台地址:https://github.com/xyhcq/top250 模块测试:爬虫对信息的处理部分 测试方法: 实际运行一下代码: 可以看见,信息都已经爬取出来了 其他补充说明: 原本系 ...
- Forward团队-爬虫豆瓣top250项目-模块开发过程
项目托管平台地址:https://github.com/xyhcq/top250 开发模块功能: 爬虫对信息的处理部分 开发时间:5天的下午空余时间(每天大约1小时,边学模块的使用边开发) 实现了:爬 ...
- Forward团队-爬虫豆瓣top250项目-团队编程项目开发环境搭建过程
本次结对编程和团队项目我都需要用python环境,所以环境的搭建是一样的.(本文部分内容引用自己博客:http://www.cnblogs.com/xingyunqi/p/7527411.html) ...
- Forward团队-爬虫豆瓣top250项目-需求分析
一. 需求:1.爬取豆瓣电影top250. 2.获取电影名称,排名,分数,简介,导演,演员. 3.将爬取到的数据保存,以便随时查看. 3.可以将获取到的数据展示给用户. 二. 参考: 豆瓣api参考资 ...
- Forward团队-爬虫豆瓣top250项目-设计文档
组长地址:http://www.cnblogs.com/mazhuangmz/p/7603594.html 成员:马壮,李志宇,刘子轩,年光宇,邢云淇,张良 设计方案: 1.能分析HTML语言: 2. ...
随机推荐
- form表单的三个属性 action 、mothod 、 enctype。
form_action: 表单数据提交到此页面 下面的表单拥有两个输入字段以及一个提交按钮,当提交表单时,表单数据会提交到名为 "form_action.asp" 的页面: < ...
- Git安装配置和提交本地代码至Github,修改GitHub上显示的项目语言
1. 下载安装git Windows版Git下载地址: https://gitforwindows.org/ 安装没有特别要求可以一路Next即可,安装完成后可以看到: 2. 创建本地代码仓库 打开G ...
- mybatis出现无效的列类型
package com.webapp.hanqi.test; import java.util.Date; import org.junit.jupiter.api.AfterEach; import ...
- pyautogui 文档(五):截图及定位功能
截图函数 PyAutoGUI可以截取屏幕截图,将其保存到文件中,并在屏幕中查找图像.如果您有一个小图像,例如需要单击并希望在屏幕上找到它的按钮,这将非常有用.这些功能由PyScreeze模块提供,该模 ...
- Python CGI编程
CGI(Common Gateway Interface)通用网关接口,它是一段程序,运行在服务器上.如:HTTP服务器,提供同客户端HTML页面的接口. CGI程序可以是python脚本,PERL脚 ...
- MySQL索引原理以及查询优化
转载自:https://www.cnblogs.com/bypp/p/7755307.html MySQL索引原理以及查询优化 一.介绍 1.什么是索引? 一般的应用系统,读写比例在10:1左右,而且 ...
- 4.7做作业时发现,内联元素设置宽高背景以后正常不显示,但是设置了position:absolute;以后就可以显示了。起到了和display:block;一样的效果。然后查了一下知道了。
如果内联元素定位属性设置为:absolate,元素脱离文档,即使a元素中没有内容,设置的背景依然会显示!
- distpicker使用记录
今天使用distpicker遇到了一些问题,记录一下. 插件地址 使用说明 需要引入的 js 文件 <script type="text/javascript" src=&q ...
- 深入理解HashMap和CurrentHashMap
原文链接:https://segmentfault.com/a/1190000015726870 前言 Map 这样的 Key Value 在软件开发中是非常经典的结构,常用于在内存中存放数据. 本篇 ...
- zabbix的api接口
zabbix官方文档解释,api是开发者能获得修改zabbix配置,获取历史数据.主要用于: 1.创建新应用 2.集成zabbix与第三方软件 3.自动运行任务 运用JSON-RPC2.0协议,因此接 ...