Temporal Action Detection with Structured Segment Networks (ssn)【转】

Action Recognition: 行为识别,视频分类,数据集为剪辑过的动作视频
Temporal Action Detection: 从未剪辑的视频,定位动作发生的区间,起始帧和终止帧并预测类别
难点
1: 边界不明确(助跑跳远,上篮,高尔夫挥杆)
2: 如何利用时序信息
3: 时序跨度大(Activitynet:1s — 200s)

上图为模型框架,用temporal actionness grouping算法提取proposal后进行上下文信息的金字塔池化,后接两个级联分类器分别是完整性判断和类别分类
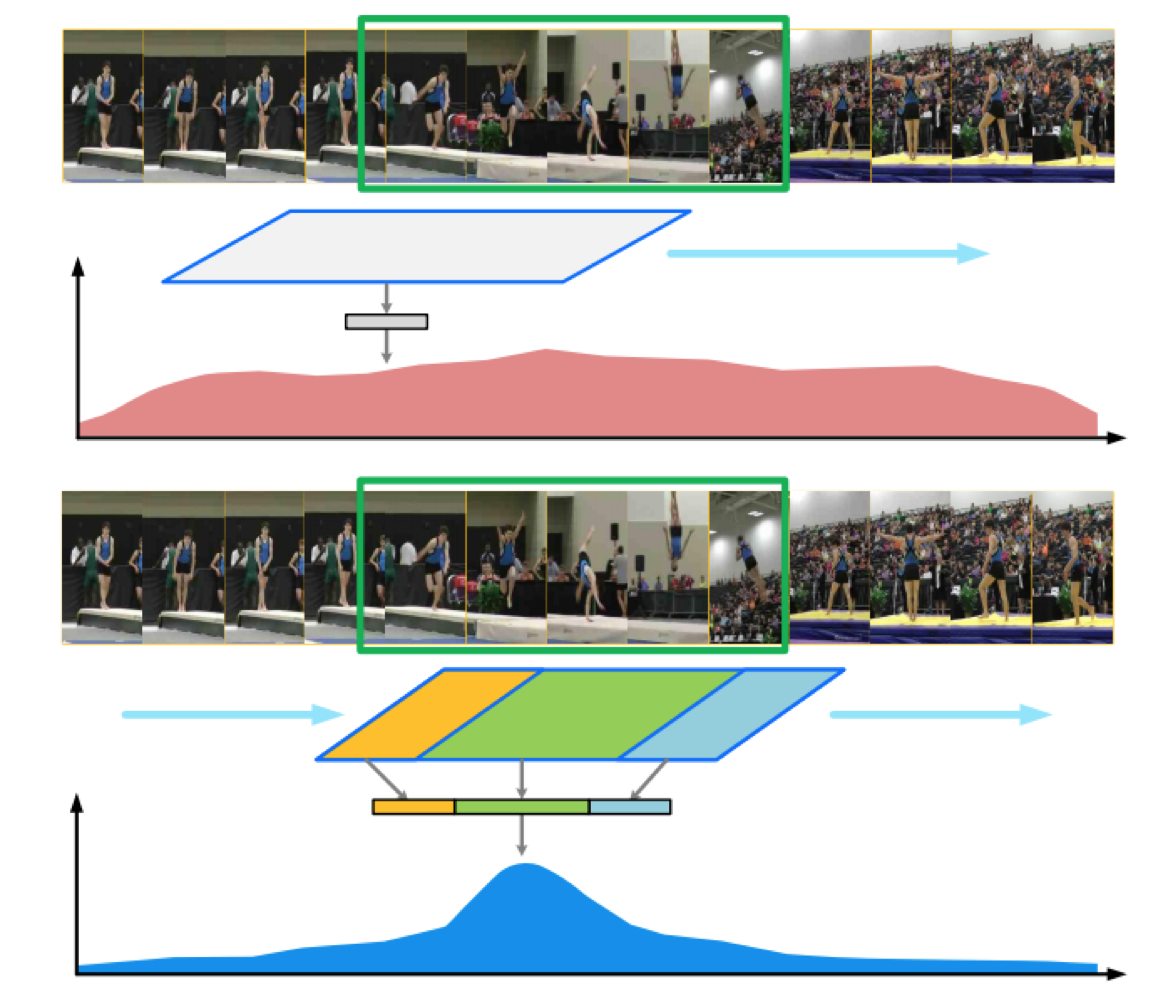
图中上半部分所示的是现有的基于视频短片段(discriminative snippets)的行为识别方法的检测结果,可以看到只要图中蓝色的框遇到具有明显判别信息的snippets时(绿色框),分类器就会具有很强的响应,这样就导致很难精确的去定位动作何时发生何时停止。为解决这个问题,文中指出需要对视频的时序结构进行分析,也就是说我们需要识别视频中动作的开始、持续以及结束三个阶段来确定视频中的动作是否完整。 为了简单的描述整个过程,这里将深度特征提取部分看作一个独立的小模块。这样整个的模型可以描述为以下几个过程:
分水岭聚合方法
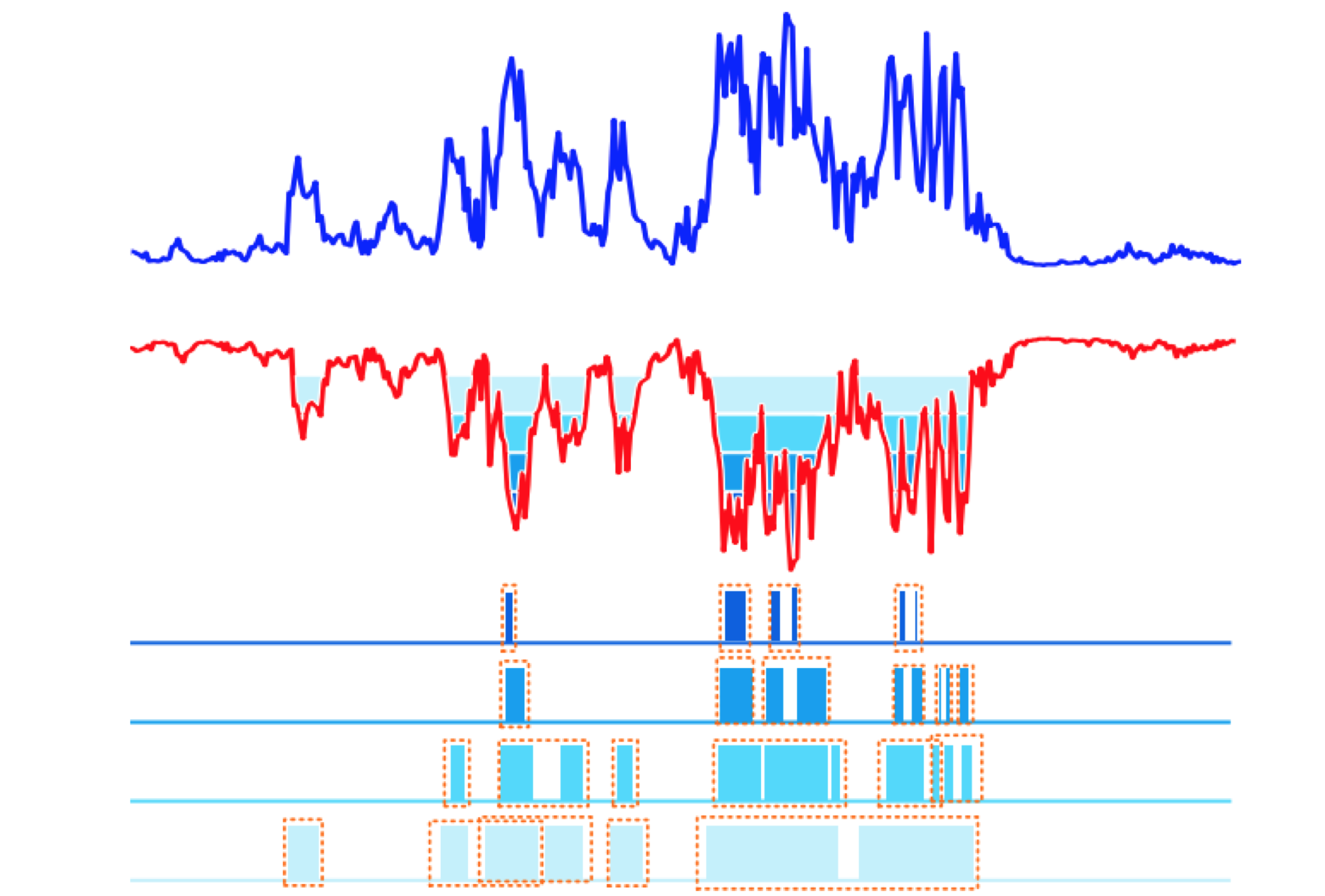
使用temporal actionness grouping (TAG) 方法获取多个高质量的 proposals (图中绿色方框)。文中通过使用一个分类器 actionness classifier 来计算每个独立的 snippets 的 binary actionness probability ,简单的说就是来预测某个 snippets 存在运动的可能性,这样就在时序上得到以下图中所示结果:从上图中可以看出,如果我们将它反过来我们就可以使用类似于分水岭算法的方法来生成proposals。

在得到原始的 proposal后,我们将其分别向两端扩展原始 proposals 长度一半的长度,得到新的2倍于原始长度的新 proposal 。两端被扩展的部分分别被定义为 starting 和 ending 两个 stage ,而原始的 proposals 则被定义为中间 course 部分。这样就得到上图中黄色方框所对应的情况。 在训练过程中为了有效的减小计算量,文中采用了类似于上文中的 segment 策略,将扩展后的 proposal 分为 9 个 segments (starting, course, ending 各对应3个), 然后在每个 segment 中随机选择一个小片段 snippet 参与运算。这样不仅可以有效的提取整个proposal 的信息,同时也使得特征的长度不随 proposal 的长度而改变,方便后续 end to end 的网络训练 。
在得到每个 stage 上的多个小片段 snippets 后,文中利用 two-stream 网络提取每个 snippts 的特征,然后采用的 structured temporal pyramid pooling 操作来对特征进行整合,实现从 snippt-level 的特征到 stage-level 的特征。 在实现过程中,对于starting 以及 ending 两个 stage 分别采用 one-level pyramids pooling, 既对两个stage的特征进行一次平均池化(图中黄色和蓝色部分)。对于course stage 文中采用 two-level pyramid pooling , 在第一层原始的 course stage 首先被分为两个 part , 分别计算两个 part 的平均池化;在第二层对上一层得到的结果再进行一次平均池化(图中绿色部分),这样分别得到了 starting, course, ending 所对应的 stage-level 特征。
在得到stage-level 特征后,文章中分别采用两种分类器 activity classifer 以及 completeness classifiers 分别实现对动作和动作的完整度进行分类。activity classifer 包含一个分类器,它仅输入 course 的特征,将 proposals 分为 K+1 个类别(包含背景类)。 completeness classifiers 则包含 K 个二分类器,每个分类器的输入是其对应的第 k 类 starting, course, ending stage 金字塔池化特征,输出该动作是否完整的概率。文中从概率的角度将两种分类器通过联合概率的形式进行整合,从而构造统一的损失函数,实现端对端的学习。
在得到 stage-level 的特征后我们不仅可以实现分类,还可以实现对原始的 proposal 进行重新定位,这个过程类似于 RCNN 对bounding box 的回归操作。文章中对训练样本中正类 proposal , 以其最接近的 groundtruth 为目标对该 proposal 的中心和长度进行回归。文中采用多任务学习策略将分类和回归两个部分整合为一个统一的损失函数。
定义统一分类损失(unified classification loss):
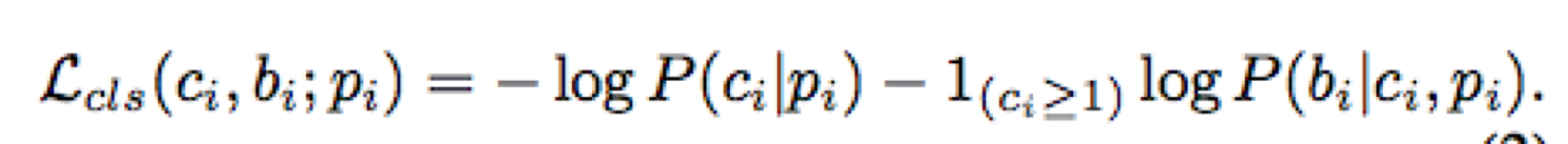
两种分类器部署在高级特征之上。对于一个proposal:pi
A分类器给出一个经过softmax后的向量,条件分布表示为 P(ci|pi),其中 ci 表示类别。
对于每个类别 k,对应的 Ck 完整性分类器给出一个概率值,分布为:P(bi|ci,pi),bi 指示动作是否完成。
训练时,关注三种proposal样本:
(1)positive proposals(ci>0,bi=1):与最接近的groundtruth的IOU至少为0.7
(2)background proposals(ci=0):不与任何groundtruth重叠
(3)incomplete proposals(ci>0,bi=0):其80%包含在groundtruth中,但IOU小于0.3,仅仅包含gt的一小部分。
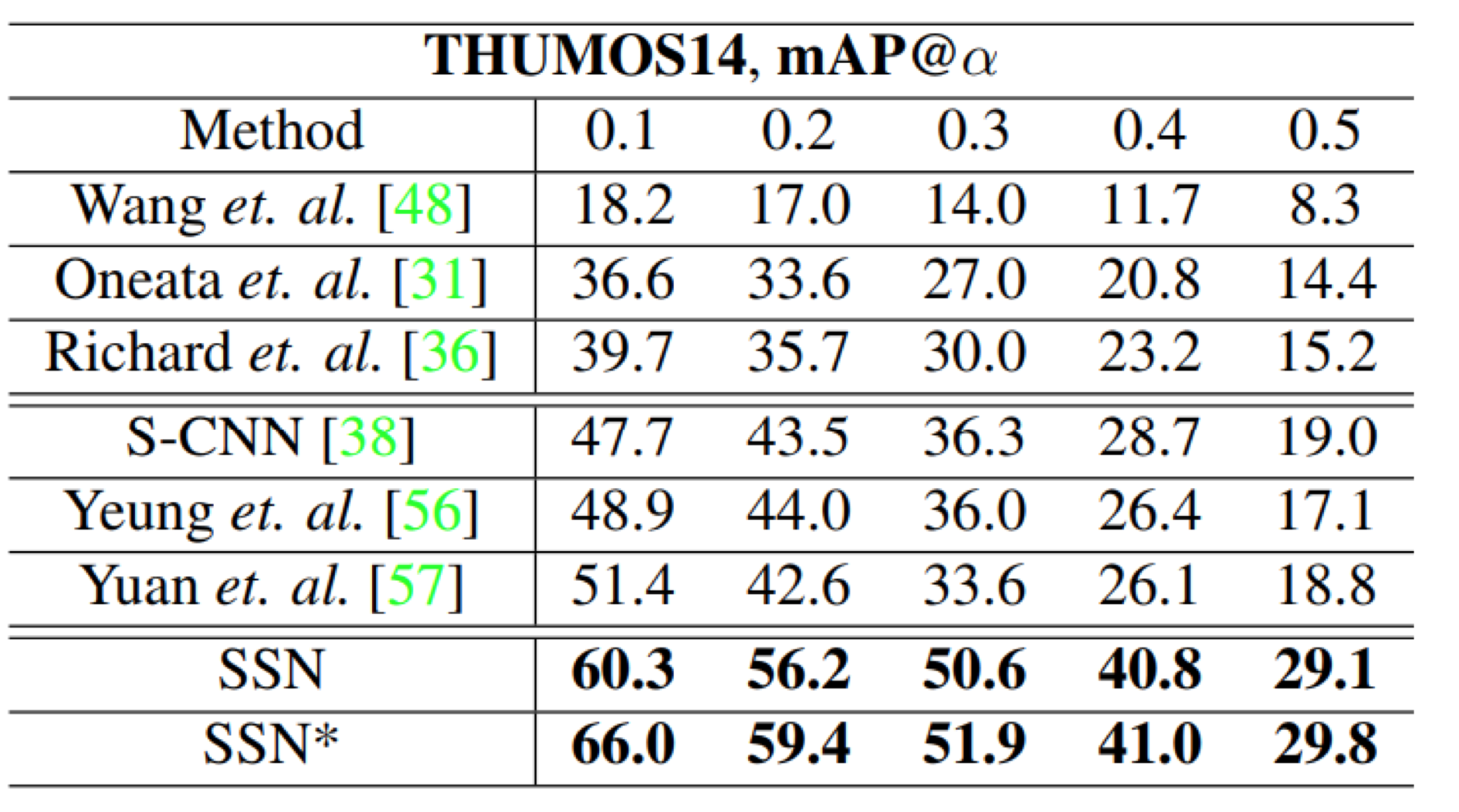
Thumos14和Activitynet1.3的结果:

code:github
Temporal Action Detection with Structured Segment Networks (ssn)【转】的更多相关文章
- 论文阅读: End-to-end Learning of Action Detection from Frame Glimpses in Videos
End-to-End Learning of Action Detection from Frame Glimpses in Videos CVPR 2016 Motivation: 本 ...
- 中文版 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 摘要 最先进的目标检测网络依靠区域提出算法 ...
- 论文阅读(Xiang Bai——【CVPR2016】Multi-Oriented Text Detection with Fully Convolutional Networks)
Xiang Bai--[CVPR2016]Multi-Oriented Text Detection with Fully Convolutional Networks 目录 作者和相关链接 方法概括 ...
- TURN TAP: Temporal Unit Regression Network for Temporal Action Proposals(ICCV2017)
Motivation 实现快速和准确地抽取出视频中的语义片段 Proposed Method -提出了TURN模型预测proposal并用temporal coordinate regression来 ...
- 目标检测--Scalable Object Detection using Deep Neural Networks(CVPR 2014)
Scalable Object Detection using Deep Neural Networks 作者: Dumitru Erhan, Christian Szegedy, Alexander ...
- 论文笔记之 SST: Single-Stream Temporal Action Proposals
SST: Single-Stream Temporal Action Proposals 2017-06-11 14:28:00 本文提出一种 时间维度上的 proposal 方法,进行行为的识别.本 ...
- Top Leaders社区发现算法(top leaders community detection approach in information networks)
一.概念 复杂网络:现实生活中各种系统都可以看做成复杂网络,复杂网络构成包括节点和边,节点是网络中的基本组成单元,节点之间的联系或者关系是网络中的边.例如 电力网络:基站代表节点,基站之间是否互通表示 ...
- SST:Single-Stream Temporal Action Proposals论文笔记
SST:Single-Stream Temporal Action Proposals 这是本仙女认认真真读完且把算法全部读懂(其实也不是非常懂)的第一篇论文 CVPR2017 一作 论文写作的动机m ...
- [论文理解] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 简介 Faster R-CNN是很经典的t ...
随机推荐
- Delphi 实现自动更新
Delphi 通用程序自动更新升级:http://www.delphitop.com/html/wangluo/2968.html https://www.cnblogs.com/hnxxcxg/p/ ...
- MySQL索引调优【转】
一.关于查询计划 其实,关于所有的关系型数据库中,在运行T-SQL语句的时候,在查询器进行编译运行的同时,都会有着自己的内部的一个优化过程,而这优化之后的产物就是:执行计划. 在SQL SERVER中 ...
- lnmp 搭建 初试
#初始化环境检查 # uname -r -.el6.x86_64 # uname -m x86_64 #添加mysql用户 useradd -s /sbin/nologin mysql -M #下载安 ...
- MFCWinInet学习
http://blog.csdn.net/segen_jaa/article/details/6278167 背景: 功能:服务端下载文件 服务端:用Java写Sevlet进行有效性验证 客户端:用C ...
- SharePoint 2010 安装错误:请重新启动计算机,然后运行安装程序以继续
一.环境:Windows Server 2008 R2 with sp1,SharePoint 2010 二.问题描述: 正常的安装SharePoint 2010 ,安装完必备组件,并提示所有必备组件 ...
- MATLAB GUI对话框设计
原文地址:http://blog.csdn.net/shuziluoji1988/article/details/8532982 1.公共对话框: 公共对话框是利用windows资源的对话框,包括文件 ...
- TechnoSoftware OPCDA client(1.2.1) Error Codes
OPCDA.NET Client Interface WrapperSummary of OPC Error Codes We have attempted to minimize the numbe ...
- mysql 5.6 windows 启动脚本
2018-4-25 17:02:08 星期三 下载mysql 5.6 zip(免安装版)到本机 一台电脑上可能装有多个版本的mysql, 启动时为了不影响: 1. 解压后文件夹根目录改名为 mysql ...
- ACL认证 vs 密码认证
呼入时需要进行认证:acl IP认证 和 密码认证. acl 认证优先进行. ACL认证成功: Access Granted. 直接进入 sip_profile>context 进行路由 A ...
- Apache服务器和tomcat服务器有什么区别(转)
Apache与Tomcat都是Apache开源组织开发的用于处理HTTP服务的项目,两者都是免费的,都可以做为独立的Web服务器运行.Apache是Web服务器而Tomcat是Java应用服务器. A ...