mysql order by是怎么工作的?
假设我们要查询一个市民表中城市=杭州的所有人的名字,并且按照名字排序
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`city` varchar(16) NOT NULL,
`name` varchar(16) NOT NULL,
`age` int(11) NOT NULL,
`addr` varchar(128) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `city` (`city`)
) ENGINE=InnoDB;
那么sql语句可以这样写
select city,name,age from t where city='杭州' order by name limit 1000 ;
接下来我们看下explain的结果

图中的Extra这一列下面的Using filesort表示需要排序,MySQL会为每个连接分配一块内存用于排序,就是sort_buffer,sort_buffer_size可以调整该排序内存大小
因为我们where条件用到了city,所以我们在city上面建立了索引
我们先看下该索引结构
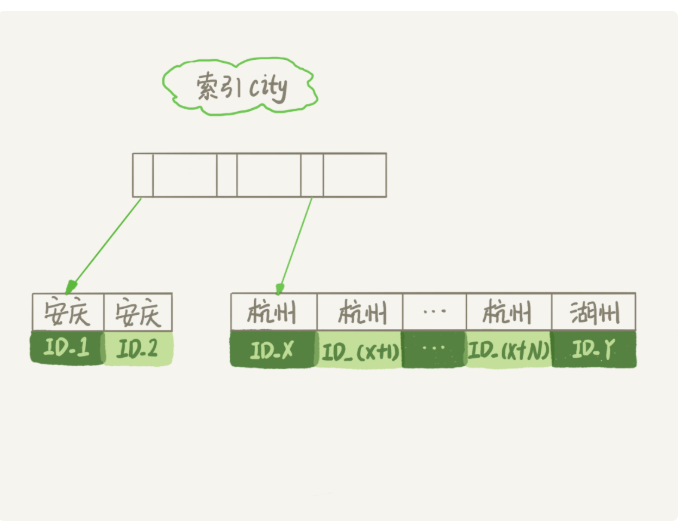
从图中可以看出满足city=杭州的条件是ID_X到ID_Y之间的数据
通常情况下这个语句的执行流程如下:
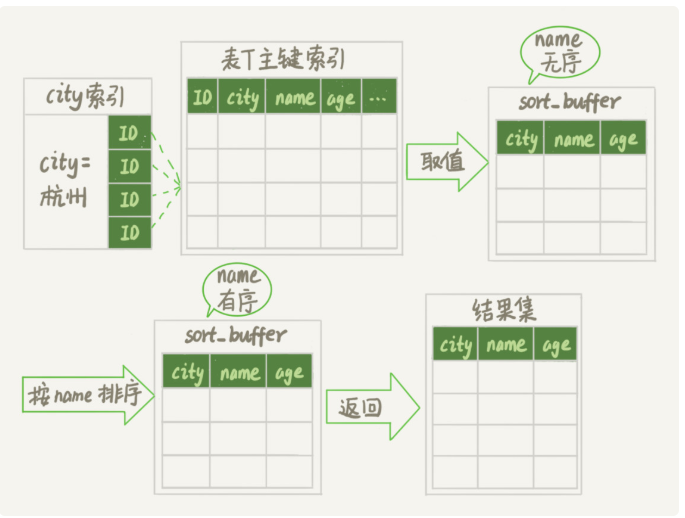
1.初始化sort_buffer,确定放入name,age,city三个字段
2.从索引city中找到第一个符合条件的数据,也就是ID_X这个
3.取出索引中id的值,回表查询name,age,city的数据放入sort_buffer中
4.从索引city取下一个符合条件的id
5.重复步骤3,4直到city的值不满足city=杭州的条件,也就是图中ID_Y
6.对sort_buffer中的数据按照name排序
7.按照排序结果取前1000行数据返回给客户端
我们把这个排序过程叫全字段排序
如下图所示
上图按name排序这个动作可能在内存中完成也可能需要外部排序,这取决于排序需要的内存大小和sort_buffer_size这个参数
如果排序需要的内存大于sort_buffer_size设置的数值,那么就需要使用磁盘临时文件辅助排序
rowid排序
在上面的那个全字段排序中,只对原表查询了一次,但是如果查询的字段很多的话,那么sort_buffer中就会很多数据,就会使用到
磁盘临时辅助文件排序,这样性能会变差。
那么如果mysql认为单行数据过大会怎么办呢?
接下来设置一下这个参数为16

max_length_for_sort_data这个参数是mysql专门用来控制用于排序的行数据的单行的长度的一个参数,如果单行数据的字段的长度超过这个参数设置的值
那么就会使用rowid排序,比如说我们这个例子中name,age,city这三个字段的单行数据长度之和要是大于16,那么就会使用rowid排序
排序流程:
1.初始化sort_buffer,确定放入id,name
2.取出city索引中第一个满足条件的索引的id值
3.到主键id索引里面取出整行,取出name,id字段放入sort_buffer
4.去下一个符合条件的索引记录,放入sort_buffer中
5.重复步骤3.4直到不满足city=杭州
6.对sort_buffer中的数据按照name进行排序
7.遍历排序结果取出前1000行的数据的id,去表中查询出name,age,city返回给客户端
可以看出来rowid排序比全字段排序多了一次表查询就是步骤7
我们来对比下这两个排序
如果mysql觉得内存不够用就会用到rowid排序,如果内存够用则用全字段排序
也就是说Mysql有个设计思想,就是如果内存够,就尽量用内存,尽量减少磁盘的访问
看到这里你是不是觉得Mysql排序是一个非常复杂的流程,性能会不好,那么是不是所有的order_by语句都要排序呢?
不是的,如果需要排序的字段天然就是有序的,那么就不需要排序,啥意思呢,比如说我们建立一个city和name的联合索引
alter table t add index city_user(city, name);
作为与city索引的对比,我们看看这个索引
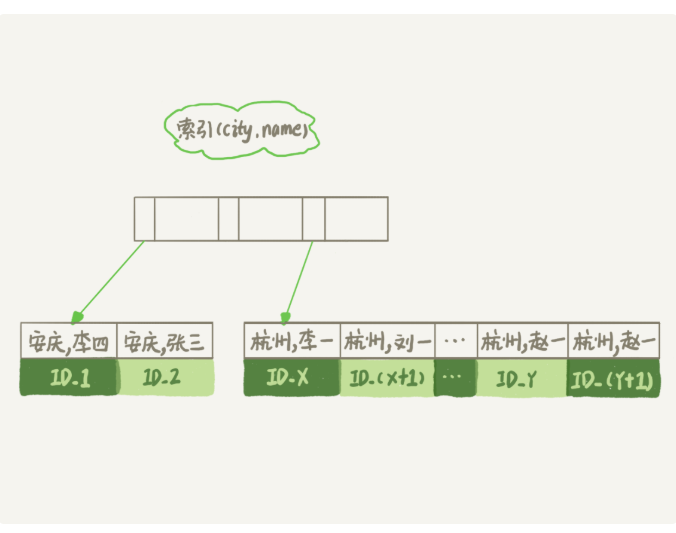
如果建立了这个索引那么执行流程就变成了这样
1.查询出第一条联合索引中city,name里面city=杭州的数据的id值
2.到主键索引里面取出整行,取出name,age,city字段
3.从索引city,name去下一个记录主键id
4.重复步骤2,3直到查到1000条记录或者不符合city=杭州循环结束
可以看到这个过程不需要排序,也不需要用到临时表
用explain验证一下

那么这个语句还有没有优化空间呢?
有的
我们建立一个三个字段的联合索引
alter table t add index city_user_age(city, name, age);
那么流程就变成了这样
1.查询出索引中第一条符合条件的数据,取出city,name,age作为结果集的一部分直接返回
2.从索引继续取下一个符合条件的数据作为结果集的一部分直接返回
3.重复步骤2直到查到1000条记录或者不符合city=杭州循环结束
这里其实就是用到了覆盖索引,直接不用回表查询了
当然这里绝对不是说遇到问题就加索引,这里只是举个例子,因为毕竟维护索引也是有代价的
了解更多:https://www.toutiao.com/c/user/83293539887/#mid=1633933053814798
mysql order by是怎么工作的?的更多相关文章
- MySQL 笔记整理(16) --“order by”是怎么工作的?
笔记记录自林晓斌(丁奇)老师的<MySQL实战45讲> (本篇内图片均来自丁奇老师的讲解,如有侵权,请联系我删除) 16) --“order by”是怎么工作的? 在林老师的课程中,第15 ...
- MySQL/MariaDB数据库的索引工作原理和优化
MySQL/MariaDB数据库的索引工作原理和优化 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 实际工作中索引这个技术是影响服务器性能一个非常重要的指标,因此我们得花时间去了 ...
- 16 | “order by”是怎么工作的? 学习记录
<MySQL实战45讲>16 | “order by”是怎么工作的? 学习记录http://naotu.baidu.com/file/0be0e0acdf751def1c0ce66215e ...
- MYSQL随机抽取查询 MySQL Order By Rand()效率问题
MYSQL随机抽取查询:MySQL Order By Rand()效率问题一直是开发人员的常见问题,俺们不是DBA,没有那么牛B,所只能慢慢研究咯,最近由于项目问题,需要大概研究了一下MYSQL的随机 ...
- MySQL Order By Rand()效率
最近由于需要大概研究了一下MYSQL的随机抽取实现方法.举个例子,要从tablename表中随机提取一条记录,大家一般的写法就是:SELECT * FROM tablename ORDER BY RA ...
- Mysql Order By 字符串排序,mysql 字符串order by
Mysql Order By 字符串排序,mysql 字符串order by ============================== ©Copyright 蕃薯耀 2017年9月30日 http ...
- mysql order by多个字段
Mysql order by 多字段排序 mysql单个字段降序排序: select * from table order by id desc; mysql单个字段升序排序: select * fr ...
- Mysql order by与limit混用陷阱
在Mysql中我们常常用order by来进行排序,使用limit来进行分页,当需要先排序后分页时我们往往使用类似的写法select * from 表名 order by 排序字段 limt M,N. ...
- MySQL ORDER BY主键id加LIMIT限制走错索引
背景及现象 report_product_sales_data表数据量2800万: 经测试,在当前数据量情况下,order by主键id,limit最大到49的时候可以用到索引report_produ ...
随机推荐
- JavaScript事件在WebKit中的处理流程研究
本文主要探讨了JavaScript事件在WebKit中的注冊和触发机制. JS事件有两种注冊方式: 通过DOM节点的属性加入或者通过node.addEventListener()函数注冊: 通过DOM ...
- Java 多线程1(转载)
来源:http://hllvm.group.iteye.com/group/wiki/2877-synchronized-volatile 最近想将java基础的一些东西都整理整理,写下来,这是对知识 ...
- 优化梯度计算的改进的HS光流算法
前言 在经典HS光流算法中,图像中两点间的灰度变化被假定为线性的,但实际上灰度变化是非线性的.本文详细分析了灰度估计不准确造成的偏差并提出了一种改进HS光流算法,这种算法可以得到较好的计算结果,并能明 ...
- 【BZOJ1414/3705】[ZJOI2009]对称的正方形 二分+hash
[BZOJ1414/3705][ZJOI2009]对称的正方形 Description Orez很喜欢搜集一些神秘的数据,并经常把它们排成一个矩阵进行研究.最近,Orez又得到了一些数据,并已经把它们 ...
- 2018-11-13-常用模块1 (time random os sys)
1.时间模块 time 2.随机数模块 random 3.与操作系统交互模块 os 4.系统模块 sys 在我们真正开始学习之前我们先解决下面几个问题,打好学习模块的小基础,以便更好的学习模块. (1 ...
- Android笔记之为TextView设置边框
效果图 text_view_background.xml <?xml version="1.0" encoding="utf-8"?> <sh ...
- BZOJ2759: 一个动态树好题
BZOJ2759: 一个动态树好题 Description 有N个未知数x[1..n]和N个等式组成的同余方程组:x[i]=k[i]*x[p[i]]+b[i] mod 10007其中,k[i],b[i ...
- swift-ios开发pod的使用(1)
MAC安裝CocoaPods http://www.cnblogs.com/surge/p/4436360.html 请注意我的环境,这个很重要 xcode版本7.3.2 mac 版本OS X ...
- Java 获取当前日期和时间
原文地址:http://www.blogjava.net/parable-myth/archive/2013/01/17/394364.html 有三种方法: 方法一:用java.util.Date类 ...
- Python序列——序列操作
Python中的序列包括,字符串.列表.元组.本文介绍序列的通用操作. 1. 切片中的None >>> s = 'abcdefg' >>> for i in ran ...