Recommender System
推荐系统我们都很熟悉,淘宝推荐用户可能感兴趣的产品,搜索引擎帮助用户发现可能感兴趣的东西,这些都是推荐系统的内容。接下来讲述一个电影推荐的项目。
Netflix 电影推荐系统
这个项目是使用的Netflix的数据,数据记录了用户观看过的电影和用户对电影的评分,使用基于物品的协同过滤算法,需要根据所有用户的观看评分历史来找出不同电影之间的相似性,然后根据单个用户的历史电影评分来估算用户喜欢某部新电影的概率,以此来进行电影的推荐。
主要的工作可以分为:
1.构建评分矩阵
2.构建同现矩阵
3.归一化同现矩阵获得电影之间的关系
4.矩阵的相乘获取预估评分 具体的,数据文件每一行记录的数据为:用户,电影,评分
Map-Reducer1 按用户进行拆分
Mapper : 输入 用户,电影,评分 输出 key -> 用户 value -> 电影:评分
Reducer : key -> 用户 value -> 列表(电影:评分) Map-Reducer2 构建同现矩阵
Mapper: 输入 用户 电影:评分的这个列表,列表两两组合 输出 MovieA : MovieB 1
Reducer: MovieA: MovieB 次数 Map-Reducer3 归一化 按照行归一化
Mapper: 输入 MovieA:MovieB 次数 输出 MovieA MovieB = 次数
Reducer:使用一个map,记录MovieB 及 次数 遍历一遍求和sum总次数。然后输出 MovieB MovieA = B次数 / sum Map-Reducer4 矩阵相乘
Mapper1: 输入 MovieB MovieA = relation 就是简单的读取数据
Mapper2: 输入用户,电影,评分 输出 电影 用户:评分
Reducer: 得到movie_relation map和user_rate map,然后遍历entry 输出 用户:电影 relation * rate Map-Reducer5 求和
简单就是对用户:电影为键求和即可。 一个比较重要的trick,为什么矩阵相乘的时候是采用按行归一化,然后按照列写入。
不这样的话,如果按照行写入,那么比如键为M1的数据 记录的就是M1与电影 1 2 3 4 5的relation 那么就需要inmemory的存储用户对于每个电影的评分矩阵。
而我们的方法就不用嘛,相当于每一个小项考虑的是我这个电影对其他电影的贡献是多少。
一、电影推荐系统中的算法
- User Collaborative Filtering (User CF)
- Item Collaborative Filtering (Item CF)
- ...
1.1 User CF
User CF (协同过滤算法)是把与你有相同爱好的用户所喜欢的物品(并且你没有评过分)推荐给你。而怎么识别有相同爱好的用户呢?一个思路比如说可以根据用户对同一商品的评分来分析。
比如下图可以根据用户之前对电影1,2,3的评分推断A和C具有相同爱好,然后A看了电影4,给了高分,就把电影4推荐给用户C.

User-based算法存在两个重大问题:
数据稀疏性。一个大型的电子商务推荐系统一般有非常多的物品,用户可能买的其中不到1%的物品,不同用户之间买的物品重叠性较低,导致算法无法找到一个用户的邻居,即偏好相似的用户。
算法扩展性。最近邻居算法的计算量随着用户和物品数量的增加而增加,不适合数据量大的情况使用。
1.2Item CF
Item CF 是把与你之前喜欢的物品近似的物品推荐给你。
比如下图根据用户AB对电影1,2的评分推断电影1和电影3相似,然后用户C看了电影1,那么就再把电影3推荐给他。

1.3采用Item CF
本项目采用Item CF来实现,主要基于以下几点考虑:
用户数量比电影数量大的多得多
Item的改变不会特别频繁,降低计算复杂度
使用用户的历史数据来为用户推荐,结果更具有说服力
二、Item CF实现电影推荐
主要分为以下三个步骤:
- Build co-occurrence matrix
- Build rating matrix
- Matrix computation to get recommending result
2.1 Build co-occurrence matrix
使用Item CF,当然首先需要描述不同Item之间的关系,那么怎么定义这些Item之间的关系呢?
Based on user’s profile
- watching history
- rating history
- favorite list
Based on movie’s info
- movie category
- movie producer
我们使用基于用户的rating history来定义两个电影时间的关系。
我们认为,同一用户看过相同的两部电影,那么这两部电影就是有关系的。(无论评分高低,因为在看之前,既然两部电影都吸引了这个用户,那么就证明两部电影还是有一些关系的)
我们构建一个co-occurrence matrix来描述不同电影之间的关系。

2.2 Build rating matrix
那么怎么定义电影之间的不同呢?我们使用rating matrix.

这里如果用户没有对一部电影评分的话,默认为0,我们可以想象为用户都不想去看这部电影。然后一个改进措施可以取值为用户历史评分的均值,这样似乎更准确一些。
2.3 Matrix computation to get recommending result
2.3.1 对co-occurrence matrix进行归一化处理

2.3.2 矩阵相乘

如上图所示,归一化时候第一行就表示电影M1和电影M1,M2,M3,M4,M5的相似性依次为2/6,2/6,1/6,1/6,0,而用户B看过M1,M2,M3三部电影,评分分别为3,7,8,没看过M4,M5。第一行和UserB的这列数据相乘时候就得到电影M1在UserB这里的得分,依次类推,可以得到电影M2,M3,M4,M5在用户这里的得分。然后从用户B没看过的电影M4,M5中选出TopK来推荐给用户B。
三、Map-Reduce工作流程
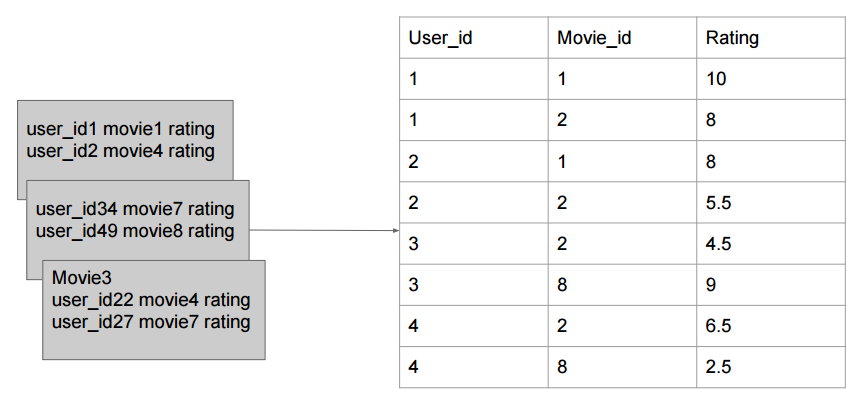
输入数据: 同PaperRank一样,我们不应该存储一颗矩阵,存储样式如下:

如上图所示,第一行就表示用户1看过10001这部电影,评分5.0.
3.1 MR1 Data divided by User
首先我们需要一个Mapper-Reducer来实现按照User-id分割数据,再按照User-id merge数据,得到每个用户看过的所有电影和评分。
Mapper:
Reducer:

3.2 MR2 构建co-occurrence matrix
使用一个mapper-reducer建立电影之间的两两相似性矩阵元。代表同一部电影或电影A,B同时被多少人看过。(A:B 代表A行B列)
Mapper:

Reducer:

3.3 MR3 对同现矩阵进行归一化操作
Mapper:
对MR2得到的结果按照行号进行拆分(按照行归一化)

Reducer:
按照行号求sum之后,分别得到当前行每一个列的位置归一化之后对应的值。然后按照列号为key写入HDFS。(之后矩阵相乘的时候分析为什么按照列号写入)
3.4 矩阵相乘
回想我们现在已经完成的工作,我们首先得到了User Rating Matrix,然后通过对同一个user id下的电影Id进行了一个两层循环得到了co-occurrence matrix。之后再对co-occurrence matrix进行行归一化,并进行了一个转置,让key为列。然后我们要做的就是矩阵的相乘了。
现在来分析我们之前说的为什么要把列存为key。(下边先不考虑多个用户,就只讨论一个用户)
我们要做的工作是什么?
假设现在有ABCD四部电影,用户user1,需要计算user1对A电影的评分。
一种方法是,使用同现矩阵的一行去乘以评分矩阵的一列,得到评分。同现矩阵: key : 行,value : A与ABCD的relation 那么就需要in-memory的存储用户对A,B,C,D的评分。不然你做不了啊,一边是key为行过来,另一边你过来的是什么东西?只能行的过来之后,对应的 列 = value 去 in-memory的查找那个列所对应的评分。
另一种方法是,同现矩阵的每一列和rating的一个数相乘,最后相加。同现矩阵: key : 列, value : 该列与A,B,C,D的relation。相当于我们计算A,B,C,D对A做了多少贡献,最后A把所有贡献加起来作为A的值,B,C,D类似。这样一来,我们以列为key,代表作贡献的电影,然后其评分同样以它为key,我们就不用再in-memoty的存储那么多东西了。
好了,现在来看这个Map-Reduce吧!


Mapper:

Mapper1仅仅是一个读取操作:

Mapper2需要变换Movie id为key

Reducer:
reducer需要对相同的key进行处理,区分来自于同现矩阵和来自于rating 矩阵,然后相乘写到HDFS,键为User: movie,值为这个用户看这个电影的来自于某一部其他电影的贡献。。。(好绕口)

3.5 Sum
最后再来一个Map-Reduce进行求和即可。

流程图如下

四、主要代码
1.Driver
public class Driver {
public static void main(String[] args) throws Exception {
DataDividerByUser dataDividerByUser = new DataDividerByUser();
CoOccurrenceMatrixGenerator coOccurrenceMatrixGenerator = new CoOccurrenceMatrixGenerator();
Normalize normalize = new Normalize();
Multiplication multiplication = new Multiplication();
Sum sum = new Sum();
String rawInput = args[0];
String userMovieListOutputDir = args[1];
String coOccurrenceMatrixDir = args[2];
String normalizeDir = args[3];
String multiplicationDir = args[4];
String sumDir = args[5];
String[] path1 = {rawInput, userMovieListOutputDir};
String[] path2 = {userMovieListOutputDir, coOccurrenceMatrixDir};
String[] path3 = {coOccurrenceMatrixDir, normalizeDir};
String[] path4 = {normalizeDir, rawInput, multiplicationDir};
String[] path5 = {multiplicationDir, sumDir};
dataDividerByUser.main(path1);
coOccurrenceMatrixGenerator.main(path2);
normalize.main(path3);
multiplication.main(path4);
sum.main(path5);
}
}
2.DataDividerByUser
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import java.io.IOException;
import java.util.Iterator; public class DataDividerByUser {
public static class DataDividerMapper extends Mapper<LongWritable, Text, IntWritable, Text> { // map method
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//input user,movie,rating
String line = value.toString().trim();
String[] user_movie_value = line.split(",");
//divide data by user
context.write(new IntWritable(Integer.valueOf(user_movie_value[0])), new Text(user_movie_value[1] + ":" + user_movie_value[2]));
}
} public static class DataDividerReducer extends Reducer<IntWritable, Text, IntWritable, Text> {
// reduce method
@Override
public void reduce(IntWritable key, Iterable<Text> values, Context context)
throws IOException, InterruptedException { //merge data for one user
StringBuilder sb = new StringBuilder();
Iterator<Text> iterator = values.iterator();
while (iterator.hasNext()) {
sb.append(",").append(iterator.next());
}
context.write(key, new Text(sb.toString().replaceFirst(",","")));
}
} public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf);
job.setMapperClass(DataDividerMapper.class);
job.setReducerClass(DataDividerReducer.class); job.setJarByClass(DataDividerByUser.class); job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class); TextInputFormat.setInputPaths(job, new Path(args[0]));
TextOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true);
} }
3.CoOccurrenceMatrixGenerator
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import java.io.IOException;
import java.util.Iterator; public class CoOccurrenceMatrixGenerator {
public static class MatrixGeneratorMapper extends Mapper<LongWritable, Text, Text, IntWritable> { // map method
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//value = userid \t movie1: rating, movie2: rating...
//key = movie1: movie2 value = 1
//calculate each user rating list: <movieA, movieB>
String line = value.toString().trim();
String[] user_movie_rate = line.split("\t");
String[] movie_rate = user_movie_rate[1].split(",");
for (int i = 0; i < movie_rate.length; i++) {
String movieA = movie_rate[i].split(":")[0];
for (int j = 0; j < movie_rate.length; j++) {
String movieB = movie_rate[j].split(":")[0];
context.write(new Text(movieA + ":" + movieB), new IntWritable(1));
}
} }
} public static class MatrixGeneratorReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
// reduce method
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
//key movie1:movie2 value = iterable<1, 1, 1>
//calculate each two movies have been watched by how many people
int sum = 0;
Iterator<IntWritable> iterator = values.iterator();
while (iterator.hasNext()) {
sum += iterator.next().get();
}
context.write(key, new IntWritable(sum));
}
} public static void main(String[] args) throws Exception{ Configuration conf = new Configuration(); Job job = Job.getInstance(conf);
job.setMapperClass(MatrixGeneratorMapper.class);
job.setReducerClass(MatrixGeneratorReducer.class); job.setJarByClass(CoOccurrenceMatrixGenerator.class); job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); TextInputFormat.setInputPaths(job, new Path(args[0]));
TextOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); }
}
4.Normalize
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map; public class Normalize { public static class NormalizeMapper extends Mapper<LongWritable, Text, Text, Text> { // map method
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //movieA:movieB \t relation
//collect the relationship list for movieA
String line = value.toString().trim();
String[] movie_relation = line.split("\t");
String[] movies = movie_relation[0].split(":");
context.write(new Text(movies[0]), new Text(movies[1] + "=" + movie_relation[1]));
}
} public static class NormalizeReducer extends Reducer<Text, Text, Text, Text> {
// reduce method
@Override
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException { //key = movieA, value=<movieB:relation, movieC:relation...>
//normalize each unit of co-occurrence matrix
int sum = 0;
HashMap<String, Integer> map = new HashMap<String, Integer>();
Iterator<Text> iterator = values.iterator();
while (iterator.hasNext()) {
String value = iterator.next().toString().trim();
String[] movie_relation = value.split("=");
map.put(movie_relation[0], Integer.parseInt(movie_relation[1]));
sum += Integer.parseInt(movie_relation[1]);
}
for (Map.Entry<String, Integer> entry : map.entrySet()) {
context.write(new Text(entry.getKey()), new Text(key.toString() + "=" + (double)entry.getValue()/sum));
}
}
} public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf);
job.setMapperClass(NormalizeMapper.class);
job.setReducerClass(NormalizeReducer.class); job.setJarByClass(Normalize.class); job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); TextInputFormat.setInputPaths(job, new Path(args[0]));
TextOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true);
}
}
5.Multiplication
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.chain.ChainMapper;
import org.apache.hadoop.mapreduce.lib.input.MultipleInputs;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map; public class Multiplication {
public static class CooccurrenceMapper extends Mapper<LongWritable, Text, Text, Text> { // map method
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//input: movieB \t movieA=relation
String line = value.toString().trim();
String[] movie_movie_ralation = line.split("\t");
//pass data to reducer
context.write(new Text(movie_movie_ralation[0]), new Text(movie_movie_ralation[1]));
}
} public static class RatingMapper extends Mapper<LongWritable, Text, Text, Text> { // map method
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //input: user,movie,rating
String line = value.toString().trim();
String[] user_movie_rate = line.split(",");
//pass data to reducer
context.write(new Text(user_movie_rate[1]), new Text(user_movie_rate[0] + ":" + user_movie_rate[2]));
}
} public static class MultiplicationReducer extends Reducer<Text, Text, Text, DoubleWritable> {
// reduce method
@Override
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException { //key = movieB value = <movieA=relation, movieC=relation... userA:rating, userB:rating...>
//collect the data for each movie, then do the multiplication
HashMap<String, Double> movie_relation_map = new HashMap<String, Double>();
HashMap<String, Double> movie_rate_map = new HashMap<String, Double>();
Iterator<Text> iterator = values.iterator();
while (iterator.hasNext()) {
String value =iterator.next().toString().trim();
if (value.contains("=")) {
movie_relation_map.put(value.split("=")[0], Double.parseDouble(value.split("=")[1]));
} else {
movie_rate_map.put(value.split(":")[0], Double.parseDouble(value.split(":")[1]));
}
}
for (Map.Entry<String,Double> entry1 : movie_relation_map.entrySet()) {
String movie = entry1.getKey();
double relation = entry1.getValue();
for (Map.Entry<String, Double> entry2 : movie_rate_map.entrySet()) {
String user = entry2.getKey();
double rate = entry2.getValue();
context.write(new Text(user + ":" + movie), new DoubleWritable(relation * rate));
}
}
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); Job job = Job.getInstance(conf);
job.setJarByClass(Multiplication.class); ChainMapper.addMapper(job, CooccurrenceMapper.class, LongWritable.class, Text.class, Text.class, Text.class, conf);
ChainMapper.addMapper(job, RatingMapper.class, Text.class, Text.class, Text.class, Text.class, conf); job.setMapperClass(CooccurrenceMapper.class);
job.setMapperClass(RatingMapper.class); job.setReducerClass(MultiplicationReducer.class); job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class); MultipleInputs.addInputPath(job, new Path(args[0]), TextInputFormat.class, CooccurrenceMapper.class);
MultipleInputs.addInputPath(job, new Path(args[1]), TextInputFormat.class, RatingMapper.class); TextOutputFormat.setOutputPath(job, new Path(args[2])); job.waitForCompletion(true);
}
}
6.Sum
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import java.io.IOException;
import java.util.Iterator; /**
* Created by Michelle on 11/12/16.
*/
public class Sum { public static class SumMapper extends Mapper<LongWritable, Text, Text, DoubleWritable> { // map method
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//pass data to reducer
String line = value.toString().trim();
String[] user_movie_rate = line.split("\t");
context.write(new Text(user_movie_rate[0]), new DoubleWritable(Double.parseDouble(user_movie_rate[1])));
}
} public static class SumReducer extends Reducer<Text, DoubleWritable, Text, DoubleWritable> {
// reduce method
@Override
public void reduce(Text key, Iterable<DoubleWritable> values, Context context)
throws IOException, InterruptedException { //user:movie relation
//calculate the sum
double sum = 0; for (DoubleWritable value : values) {
sum += value.get();
}
context.write(key, new DoubleWritable(sum));
}
} public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf);
job.setMapperClass(SumMapper.class);
job.setReducerClass(SumReducer.class); job.setJarByClass(Sum.class); job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class); TextInputFormat.setInputPaths(job, new Path(args[0]));
TextOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true);
}
}
Recommender System的更多相关文章
- A cost-effective recommender system for taxi drivers
一个针对出租车司机有效花费的推荐系统 摘要 GPS技术和新形式的城市地理学改变了手机服务的形式.比如说,丰富的出租车GPS轨迹使得出做租车领域有新方法.事实上,最近很多工作是在使用出租车GPS轨迹数据 ...
- Coursera, Machine Learning, Anomoly Detection & Recommender system
Algorithm: When to select Anonaly detection or Supervised learning? 总的来说guideline是如果positive e ...
- 推荐系统(Recommender System)
推荐系统(Recommender System) 案例 为用户推荐电影 数据展示 Bob Tom Alice Jack 动作成分 浪漫成分 Movie1 5 ? 0 3 ? ? Movie2 ? 0 ...
- 【RS】Deep Learning based Recommender System: A Survey and New Perspectives - 基于深度学习的推荐系统:调查与新视角
[论文标题]Deep Learning based Recommender System: A Survey and New Perspectives ( ACM Computing Surveys ...
- 论文笔记: Deep Learning based Recommender System: A Survey and New Perspectives
(聊两句,突然记起来以前一个学长说的看论文要能够把论文的亮点挖掘出来,合理的进行概括23333) 传统的推荐系统方法获取的user-item关系并不能获取其中非线性以及非平凡的信息,获取非线性以及非平 ...
- User-Based Collaborative Recommender System
Collaborative Recommender System基于User给Item的打分表,认为相似度很高的用户,会对同一个item给出相似的分数,找出K个相似度最高的用户,集合他们的打分,来推算 ...
- Item-Based Collaborative Recommender System
与User-Based Collaborative Recommender System认为‘类似的用户会对同一个item给出类似的打分’不同,Item-Based Collaborative Rec ...
- Content-Based Recommender System
Content-Based Recommender System是基于产品(商品.网页)的内容.属性.关键字,以及目标用户的喜好.行为,这两部分数据来联合计算出,该为目标用户推荐其可能最感兴趣的产品. ...
- 与Recommender System相关的会议及期刊
会议 We refer specifically to ACM Recommender Systems (RecSys), established in 2007 and now the prem ...
- A smooth collaborative recommender system 推荐系统-浅显了解
characteristic: 1.Tracking user 2.personliza 3.面对的问题类似于分形学+混沌学(以有观无+窥一管而知全貌) 4.Data:high-volume.spar ...
随机推荐
- python3基础10(操作日志)
#!/usr/bin/env python# -*- coding:UTF-8 -*- import logging, time, os # 这个是日志保存本地的路径log_path = " ...
- 初学基础python记录
1.对于python来说,最重要的就是缩进.相当于其他语言的{}中括号. 2.转义快捷等 alt+p和alt+n来复制上下一行.变量使用时得先赋值,且大小写敏感,遵循变量命名规则.Python还允许用 ...
- springMvc-reset风格和对静态资源的管理
1.所谓rest风格及比较优雅的,没有一大堆后缀的风格 2.对静态资源的管理,及样式.图片等不需要springMvc过滤 代码: 1.在springMvc的配置文件中添加mvc标签 <?xml ...
- shrio中去掉 login;JSESSIONID
shrio中去掉 login;JSESSIONID 在session管理器配置页面中新增一条记录
- 【洛谷3157】[CQOI2011] 动态逆序对(CDQ分治)
点此看题面 大致题意: 给你一个从\(1\)到\(n\)的排列,问你每次删去一个元素后剩余的逆序对个数. 关于\(80\)分的树套树 为了练树套树,我找到了这道题目. 但悲剧的是,我的 线段树套\(T ...
- PHP数组排序方法总结
随着PHP的快速发展,用它的人越来越多,在PHP数组学习摘录部分了解到最基本的PHP数组的建立和数组元素的显示.需要深入学习下PHP数组的相关操作.首先接触的就是PHP数组排序.降序的排序问题. so ...
- 使ListView控件中的选择项高亮显示
实现效果: 知识运用: ListView控件的SelectedItems属性 //获取在ListView控件中被选中数据项的集合 public ListView.SelectedListViewIte ...
- vue项目跨域问题
跨域 了解同源政策:所谓"同源"指的是"三个相同". 协议相同 域名相同 端口相同 解决跨域 jsonp 缺点:只能get请求 ,需要修改B网站的代码 cors ...
- node 中的redis使用
1.创建sql.config.js 配置文件 : var redis_db = { ", "URL":"127.0.0.1", "OPTIO ...
- Linux入门-第八周
1.用shell脚本实现自动登录机器 #!/usr/bin/expectset ip 192.168.2.192set user rootset password rootspawn ssh $use ...