NET Core中使用Irony
在.NET Core中使用Irony实现自己的查询语言语法解析器
在之前《在ASP.NET Core中使用Apworks快速开发数据服务》一文的评论部分,.NET大神张善友为我提了个建议,可以使用Compile As a Service的Roslyn为语法解析提供支持。在此非常感激友哥给我的建议,也让我了解了一些Roslyn的知识。使用Roslyn的一个很大的好处是,框架无需依赖第三方的组件,并且Roslyn也是.NET Foundation的一个开源项目,为.NET语言提供编译服务,社区支持做的也非常出色。然而,经过一段时间的思考,我还是选择了一个折中的方案:在Apworks中使用Irony作为查询语言的语法解析器,与此同时,为查询语言语法解析提供可扩展的框架级支持。
那么问题来了:为什么我需要在Apworks中设计查询语言?Irony是什么?如何使用Irony实现自己的查询语言语法解析器?下面我就一一为大家介绍。
Apworks中的查询语言
很多体验过Apworks数据服务(Apworks Data Services)案例:TaskList的读者肯定有这样的感受:为什么每次我新建的任务项目(Task Item)都是出现在列表中不确定的位置?难道新建的任务就不应该放在最前面吗?是的,你的疑问没有错,在之前的TaskList中,的确存在这样的问题,因为那时候Apworks数据服务在返回任务列表时,还不支持查询和排序,也就是说,它只能默认以Id作为升序进行分页,返回所有的数据。当然,在最近一版的Apworks数据服务中,通过基于Irony的语法解析器,已经能够成功地支持查询和排序了。
如果你之前有仔细阅读《在ASP.NET Core中使用Apworks快速开发数据服务》一文,并按照文中的演练步骤实现过一个简单的RESTful服务的话,那么,请你重新在Visual Studio 2017中打开你的解决方案,将Apworks相关库更新到最新版本,然后不要修改任何代码,直接运行你的应用。等应用程序运行后,执行一次GET请求,URL中你就可以使用query作为查询条件输入了。比如,使用curl执行下面的命令:
|
1
|
curl -G "http://localhost:58928/api/customers" --data-urlencode "query=name sw \"fr\"" |
你将得到下面的结果:
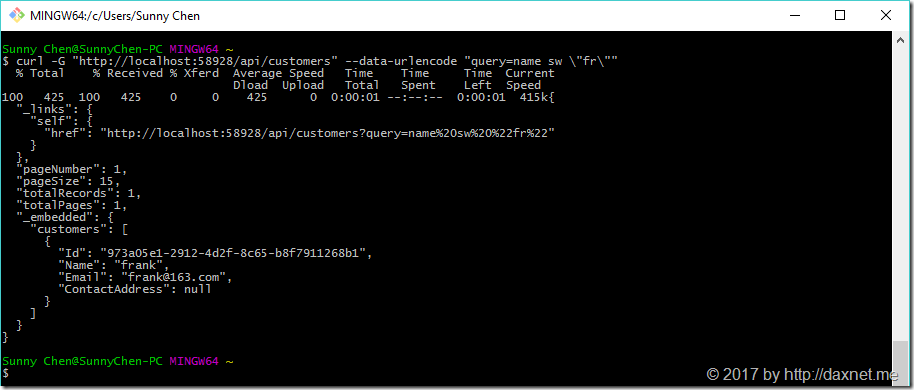
可以看到,数据服务返回了所有Name字段以“fr”开头的客户信息。当然,还支持排序操作。比如执行下面的命令:
|
1
|
curl -G "http://localhost:58928/api/customers" --data-urlencode "sort=name d" |
将得到下面的结果:
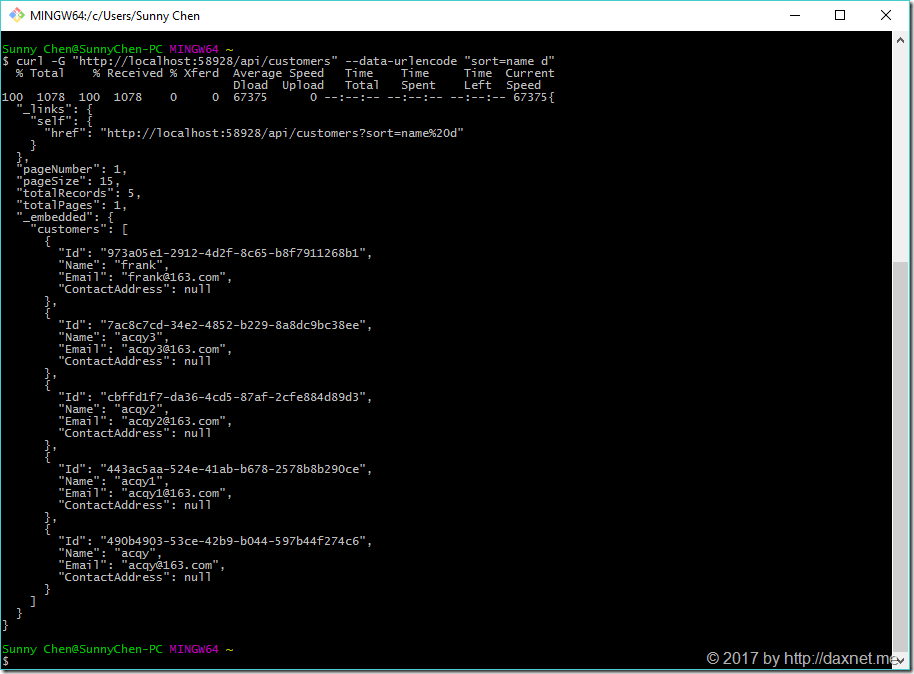
此时返回结果已经按Name字段倒序排列。
在Apworks中,查询语言支持以下操作和运算:
- 逻辑运算:AND OR NOT
- 关系运算:EQ(相等),NE(不等),LT(小于),LE(小于等于),GT(大于),GE(大于等于)
- 字符串运算:SW(以某字符串开头)、EW(以某字符串结尾)、CT(包含某字符串)
- 括号优先级
- 日期类型的比对
排序语言支持升序(用字母a表示)以及降序(用字母d表示),多个排序条件使用AND关键字连接。例如:name a AND email d,表示使用name字段做升序排序,并以email做降序排序。
以上就给大家大概介绍了一下Apworks数据服务对查询和排序的支持功能。设计这部分功能的需求是显而易见的:开发人员无需为一般的查询和排序功能自定义额外的接口。或许你会问,为何不使用已有的框架,比如OData。不错,OData的确可以提供统一的查询界面,做系统集成也会相对容易,但一方面我还是觉得OData太重,Apworks数据服务我希望能够提供更加简单便捷的功能;另一方面,看上去目前OData还不支持.NET Core(应该是不支持,我不太确定,有知道的朋友也欢迎留言指正)。
实现这套查询和排序语法,我使用的是一个.NET下开源的语法解析器生成工具集,它的名字叫做Irony。
Irony简介
Irony项目最开始是发布在微软的Codeplex代码托管服务上的,地址是:http://irony.codeplex.com/。在Codeplex上的好评数有51颗星,也已经很不错了。可惜的是,最近一次更新是在2013年12月,看起来已经停止维护了,不过之前使用了一下,感觉这个项目确实不错,不仅提供了开发库,而且还有一个图形化的语法解析器的测试工具,在写完自己的自定义语言的语法之后,还可以通过这个工具进行测试。于是,我把它迁移到了Github,成为我的一个公共repo,地址是:https://github.com/daxnet/irony。当然,我沿用了原有的MIT许可协议,并在首页的README.md中提供了原始地址(很可惜Codeplex将在年底关闭),并保留了开发者的名字。不仅如此,在一番踩坑之后,我把它迁移到了.NET Core平台。
在我的Irony Github Repo里,提供了一个非常简单的案例,就是实现四则混合运算的字符串解析,并计算最终结果。当然,这个案例也被包含在了这个项目的源代码里。大家可以自己下载查看。
Irony的一个特色就是运用了C#的运算符重载,使得语法定义借用了C#的编译功能(语法、类型检查等),简单直观,又不容易出错。比如,在如下案例中的语法定义类型中:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
[Language("Expression Grammar", "1.0", "abc")]public class ExpressionGrammar : Grammar{ /// <summary> /// Initializes a new instance of the <see cref="ExpressionGrammar"/> class. /// </summary> public ExpressionGrammar() : base(false) { var number = new NumberLiteral("Number"); number.DefaultIntTypes = new TypeCode[] { TypeCode.Int16, TypeCode.Int32, TypeCode.Int64 }; number.DefaultFloatType = TypeCode.Single; var identifier = new IdentifierTerminal("Identifier"); var comma = ToTerm(","); var BinOp = new NonTerminal("BinaryOperator", "operator"); var ParExpr = new NonTerminal("ParenthesisExpression"); var BinExpr = new NonTerminal("BinaryExpression", typeof(BinaryOperationNode)); var Expr = new NonTerminal("Expression"); var Term = new NonTerminal("Term"); var Program = new NonTerminal("Program", typeof(StatementListNode)); Expr.Rule = Term | ParExpr | BinExpr; Term.Rule = number | identifier; ParExpr.Rule = "(" + Expr + ")"; BinExpr.Rule = Expr + BinOp + Expr; BinOp.Rule = ToTerm("+") | "-" | "*" | "/"; RegisterOperators(10, "+", "-"); RegisterOperators(20, "*", "/"); MarkPunctuation("(", ")"); RegisterBracePair("(", ")"); MarkTransient(Expr, Term, BinOp, ParExpr); this.Root = Expr; }} |
从中可以很容易理解:运算符(BinOp)包含+、-、*和/,而一个二元运算的表达式(BinExpr)由两个表达式(Expr)和一个运算符(BinOp)组成,而二元运算的表达式又是表达式(Expr)的一种。通过这样的语法定义,就可以使用Irony的Parser产生语法树了:
|
1
2
3
|
var language = new LanguageData(new ExpressionGrammar());var parser = new Parser(language);var syntaxTree = parser.Parse(input); |
怎么样,是不是非常方便?
在迁移Irony项目的同时,我还将Irony的测试工具Irony Grammar Explorer分离出来成为了一个单独的Github Repo。在你定义了上面的ExpressionGrammar类之后,编译你的程序集,然后就可以使用Irony Grammar Explorer进行测试了。比如,使用Irony Grammar Explorer打开Apworks.Querying.Parsers.Irony程序集,它将自动扫描程序集中所有的Grammar定义,然后让用户对各种Grammar进行测试。值得一提的是,在测试界面,Irony Grammar Explorer还能根据语法定义,自动产生语法高亮:
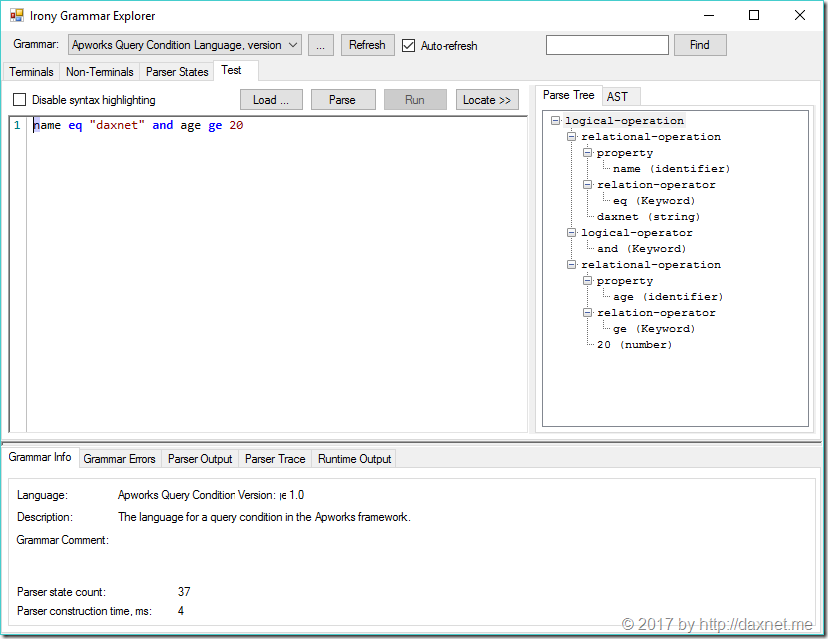
点击右边的语法树中的节点,即可定位到输入字符串的相应部分。比较有趣的一点是,在Irony Grammar Explorer的Github Repo里,还包含了一个语法定义的案例库:IronyExplorer.Samples,它包含了很多流行编程语言的语法定义。比如,下面是C# 3.5语言的语法测试效果:
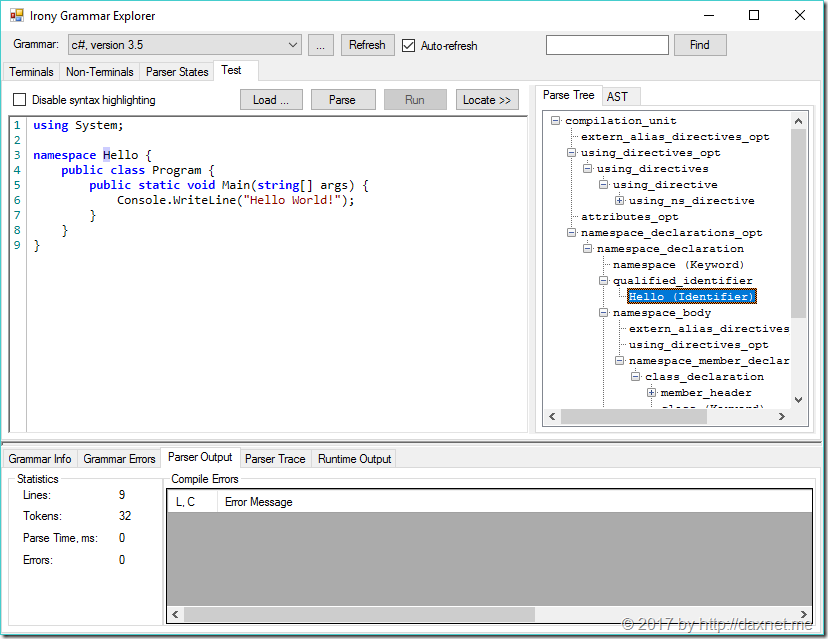
有关Irony Grammar Explorer的其它功能,我就不一一介绍了,大家可以自己实践一下。总的来说,Irony可以帮助大家快速方便地实现语法解析器,而且功能也能够满足绝大多数需求,针对.NET Core的支持,也使得Irony能够直接被应用在跨平台的.NET应用程序中,并支持Docker部署。接下来的问题就更有趣了:我已经定义了自己的语法,并使用Irony Grammar Explorer通过了测试,接下来,我如何在我的应用程序中运用这个语法?换个方式问:我拿到了语法树后,该怎么办呢?
语法树的处理
虽然我们能够将字符串文本解析成一棵语法树,能够通过语法树来体现一个字符串中各个部分的含义,以及它们之间的关系,但是如何能够让计算机来读懂这棵树,并执行相应的任务呢?这就涉及到语法树的处理问题。参考编译原理,词法分析和语法分析已经由Irony完成,接下来的语义分析,就需要我们自己写代码了。
在Irony Repo的案例代码中,我们的目的是能够解析一个四则运算表达式,并计算出结果,于是,我们定义了下面的对象模型:
因此,只需要将解析的语法树转换成上面的对象模型,也就能够通过Evaluation.Value属性,得到计算的最终结果。从代码上看,向对象模型的转换,是通过递归的方式遍历语法树实现的:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
private Evaluation PerformEvaluate(ParseTreeNode node){ switch (node.Term.Name) { case "BinaryExpression": var leftNode = node.ChildNodes[0]; var opNode = node.ChildNodes[1]; var rightNode = node.ChildNodes[2]; Evaluation left = PerformEvaluate(leftNode); Evaluation right = PerformEvaluate(rightNode); BinaryOperation op = BinaryOperation.Add; switch (opNode.Term.Name) { case "+": op = BinaryOperation.Add; break; case "-": op = BinaryOperation.Sub; break; case "*": op = BinaryOperation.Mul; break; case "/": op = BinaryOperation.Div; break; } return new BinaryEvaluation(left, right, op); case "Number": var value = Convert.ToSingle(node.Token.Text); return new ConstantEvaluation(value); } throw new InvalidOperationException($"Unrecognizable term {node.Term.Name}.");} |
以上完整代码请参考Evaluator的实现。整个案例及使用方式可以点击https://github.com/daxnet/irony#example查看。可以看到,使用Irony来实现一个四则混合运算的计算器还是非常方便的。
在Apworks中,我们需要的是能够将一个表达查询语义的语法树,转换成Lambda表达式,以便于后台数据库引擎能够直接执行Lambda表达式完成查询。通过数据库引擎执行Lambda表达式的优势是非常明显的,比如Entity Framework Core可以通过Lambda表达式生成高效的SQL语句并在数据库服务器上执行,性能方面也能兼顾得非常好。
类似的,我们使用.NET Expression的对象模型,通过遍历查询语句的语法树来生成表达式模型,最后转换成Lambda表达式即可。具体过程就不再赘述了,请参考Apworks的源代码。现在我们来看看实际效果。
假设我们的测试数据如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
Customers.Add(new Customer { Id = 1, Email = "jim@example.com", Name = "jim", DateRegistered = DateTime.Now.AddDays(-1) });Customers.Add(new Customer { Id = 2, Email = "tom@example.com", Name = "tom", DateRegistered = DateTime.Now.AddDays(-2) });Customers.Add(new Customer { Id = 3, Email = "alex@example.com", Name = "alex", DateRegistered = DateTime.Now.AddDays(-3) });Customers.Add(new Customer { Id = 4, Email = "carol@example.com", Name = "carol", DateRegistered = DateTime.Now.AddDays(-4) });Customers.Add(new Customer { Id = 5, Email = "david@example.com", Name = "david", DateRegistered = DateTime.Now.AddDays(-5) });Customers.Add(new Customer { Id = 6, Email = "frank@example.com", Name = "frank", DateRegistered = DateTime.Now.AddDays(-6) });Customers.Add(new Customer { Id = 7, Email = "peter@example.com", Name = "peter", DateRegistered = DateTime.Now.AddDays(-7) });Customers.Add(new Customer { Id = 8, Email = "paul@example.com", Name = "paul", DateRegistered = DateTime.Now.AddDays(1) });Customers.Add(new Customer { Id = 9, Email = "winter@example.com", Name = "winter", DateRegistered = DateTime.Now.AddDays(2) });Customers.Add(new Customer { Id = 10, Email = "julie@example.com", Name = "julie", DateRegistered = DateTime.Now.AddDays(3) });Customers.Add(new Customer { Id = 11, Email = "jim@example.com", Name = "jim", DateRegistered = DateTime.Now.AddDays(4) });Customers.Add(new Customer { Id = 12, Email = "brian@example.com", Name = "brian", DateRegistered = DateTime.Now.AddDays(5) });Customers.Add(new Customer { Id = 13, Email = "david@example.com", Name = "david", DateRegistered = DateTime.Now.AddDays(6) });Customers.Add(new Customer { Id = 14, Email = "daniel@example.com", Name = "daniel", DateRegistered = DateTime.Now.AddDays(7) });Customers.Add(new Customer { Id = 15, Email = "jill@example.com", Name = "jill", DateRegistered = DateTime.Now.AddDays(8) }); |
下面调试单元测试,并查看所产生的Lambda表达式,可以看到,Lambda表达式正确产生,测试顺利通过:
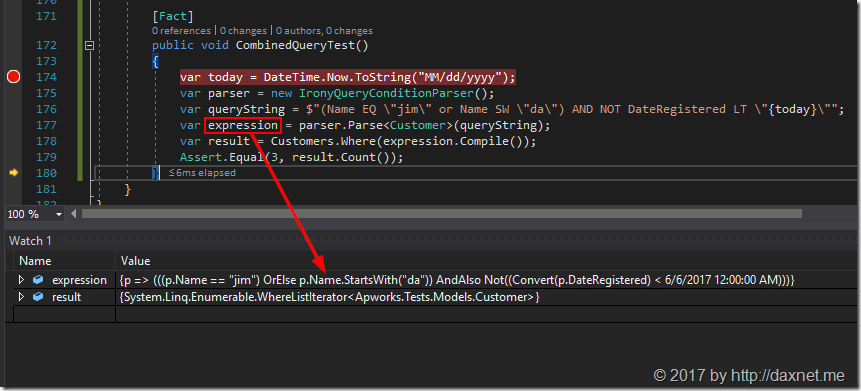
总结
本文介绍了Apworks中自定义查询语句在Apworks数据服务中的应用,并介绍了查询语句和排序语句的实现方式,与此同时对Irony Grammar Parser进行了介绍。Apworks中查询语句的实现还是相对简单的,目前不支持内嵌对象的属性查询,比如Customer.Address.Country EQ “China” 这样的查询是不支持的。为了保证实现过程相对简单快速,今后也不打算支持。如果需要用到这种内嵌对象属性的查询,请扩展DataServiceController以实现自己的特定API来完成。
接下来我会介绍Entity Framework Core在Apworks数据服务中的使用(虽然已经预告了好几次了-_-!!)。
NET Core中使用Irony的更多相关文章
- 在.NET Core中使用Irony实现自己的查询语言语法解析器
在之前<在ASP.NET Core中使用Apworks快速开发数据服务>一文的评论部分,.NET大神张善友为我提了个建议,可以使用Compile As a Service的Roslyn为语 ...
- 在ASP.NET Core中使用Apworks快速开发数据服务
不少关注我博客的朋友都知道我在2009年左右开发过一个名为Apworks的企业级应用程序开发框架,旨在为分布式企业系统软件开发提供面向领域驱动(DDD)的框架级别的解决方案,并对多种系统架构风格提供支 ...
- .NET Core中的认证管理解析
.NET Core中的认证管理解析 0x00 问题来源 在新建.NET Core的Web项目时选择“使用个人用户账户”就可以创建一个带有用户和权限管理的项目,已经准备好了用户注册.登录等很多页面,也可 ...
- ASP.NET Core 中的那些认证中间件及一些重要知识点
前言 在读这篇文章之间,建议先看一下我的 ASP.NET Core 之 Identity 入门系列(一,二,三)奠定一下基础. 有关于 Authentication 的知识太广,所以本篇介绍几个在 A ...
- Asp.net Core中使用Session
前言 2017年就这么悄无声息的开始了,2017年对我来说又是特别重要的一年. 元旦放假在家写了个Asp.net Core验证码登录, 做demo的过程中遇到两个小问题,第一是在Asp.net Cor ...
- 在ASP.NET Core中使用百度在线编辑器UEditor
在ASP.NET Core中使用百度在线编辑器UEditor 0x00 起因 最近需要一个在线编辑器,之前听人说过百度的UEditor不错,去官网下了一个.不过服务端只有ASP.NET版的,如果是为了 ...
- ASP.NET Core中的依赖注入(1):控制反转(IoC)
ASP.NET Core在启动以及后续针对每个请求的处理过程中的各个环节都需要相应的组件提供相应的服务,为了方便对这些组件进行定制,ASP.NET通过定义接口的方式对它们进行了"标准化&qu ...
- ASP.NET Core中的依赖注入(2):依赖注入(DI)
IoC主要体现了这样一种设计思想:通过将一组通用流程的控制从应用转移到框架之中以实现对流程的复用,同时采用"好莱坞原则"是应用程序以被动的方式实现对流程的定制.我们可以采用若干设计 ...
- ASP.NET Core中的依赖注入(3): 服务的注册与提供
在采用了依赖注入的应用中,我们总是直接利用DI容器直接获取所需的服务实例,换句话说,DI容器起到了一个服务提供者的角色,它能够根据我们提供的服务描述信息提供一个可用的服务对象.ASP.NET Core ...
随机推荐
- ubuntn下 apt的用法和yum的比较(转)
centos有yum安装软件,Ubuntu有apt工具. apt简单的来说,就是给Ubuntu安装软件的一种命令方式. 一.apt的相关文件 /etc/apt/sources.list 设置软件包的获 ...
- 剑指offer24:判断一个二叉树的后序遍历序列是否为二叉搜索树的后序遍历序列
public static boolean isBSTSequence(int[] s,int l, int r) { if (s == null || r <= 0) return false ...
- zjoi2015d1题解
闲来无事做了丽洁姐姐的题 t1给一棵树 每个点有点权 每次修改点权 修改后询问每个点到树的带权重心的带权距离是多少 每个点度数不超过20 很显然的一个点分树... 我们记一下 每个点的子树中的所有点到 ...
- docker基础用法
docker 架构: docker 安装前期准备: 安装centos7 ,不要在centos6 [root@node01 yum.repos.d]# uname -a Linux node01 -. ...
- P1150 Peter的烟
题目描述 Peter有n根烟,他每吸完一根烟就把烟蒂保存起来,k(k>1)个烟蒂可以换一个新的烟,那么Peter最终能吸到多少根烟呢? 输入输出格式 输入格式: 每组测试数据一行包括两个整数n( ...
- CF 1042A Benches——二分答案(水题)
题目:http://codeforces.com/problemset/problem/1042/A #include<iostream> #include<cstdio> # ...
- Ubuntu ssh免密登录
ssh免密登录工作原理 server A免登录到server B: 1.在A上生成公钥私钥. 2.将公钥拷贝给server B,要重命名成authorized_keys(从英文名就知道含义了) 3.S ...
- Java Security(JCE基本概念)
Java Security网络环境中的安全隐患计算机安全OSI参考结构模型五类安全服务八类安全机制网络环境中的安全隐患1. 存储问题: 移动存储设备存储数据没有加密存在的安全隐患 2. 通信问题: 用 ...
- Behave + Selenium(Python) 四
来自T先生 今天我们开始讲讲behave的厉害的地方. Tag文件的使用 在behave里面,如何来控制哪些case需要run,哪些case不需要run,这个时候就用Tag来控制.好了,接下来我用Ta ...
- jQuery 防止相同的事件快速重复触发
重复触发就是防止用户重复点击提交数据了,我们一般都是点击之后没反应会再次点击了,这个不但要从用户体验上来做好,还在要js或php程序脚本上做好,让用户知道点击是己提交服务器正在处理,下面我就整理从脚本 ...