各种优化方法总结比較(sgd/momentum/Nesterov/adagrad/adadelta)
前言
这里讨论的优化问题指的是,给定目标函数f(x),我们须要找到一组參数x。使得f(x)的值最小。
本文下面内容如果读者已经了解机器学习基本知识,和梯度下降的原理。
SGD
SGD指stochastic gradient descent,即随机梯度下降。是梯度下降的batch版本号。
对于训练数据集,我们首先将其分成n个batch,每一个batch包括m个样本。我们每次更新都利用一个batch的数据。而非整个训练集。
即:
当中。η为学习率,gt为x在t时刻的梯度。
这么做的优点在于:
- 当训练数据太多时。利用整个数据集更新往往时间上不显示。batch的方法能够降低机器的压力,而且能够更快地收敛。
- 当训练集有非常多冗余时(相似的样本出现多次),batch方法收敛更快。以一个极端情况为例。若训练集前一半和后一半梯度同样。那么如果前一半作为一个batch,后一半作为还有一个batch。那么在一次遍历训练集时,batch的方法向最优解前进两个step,而总体的方法仅仅前进一个step。
Momentum
SGD方法的一个缺点是,其更新方向全然依赖于当前的batch。因而其更新十分不稳定。
解决这一问题的一个简单的做法便是引入momentum。
momentum即动量,它模拟的是物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向。同一时候利用当前batch的梯度微调终于的更新方向。
这样一来,能够在一定程度上添加稳定性,从而学习地更快,而且还有一定摆脱局部最优的能力:
当中,ρ 即momentum,表示要在多大程度上保留原来的更新方向,这个值在0-1之间,在训练開始时,因为梯度可能会非常大,所以初始值一般选为0.5;当梯度不那么大时,改为0.9。η 是学习率,即当前batch的梯度多大程度上影响终于更新方向,跟普通的SGD含义同样。ρ 与 η 之和不一定为1。
Nesterov Momentum
这是对传统momentum方法的一项改进,由Ilya Sutskever(2012 unpublished)在Nesterov工作的启示下提出的。
其基本思路例如以下图(转自Hinton的coursera公开课lecture 6a):
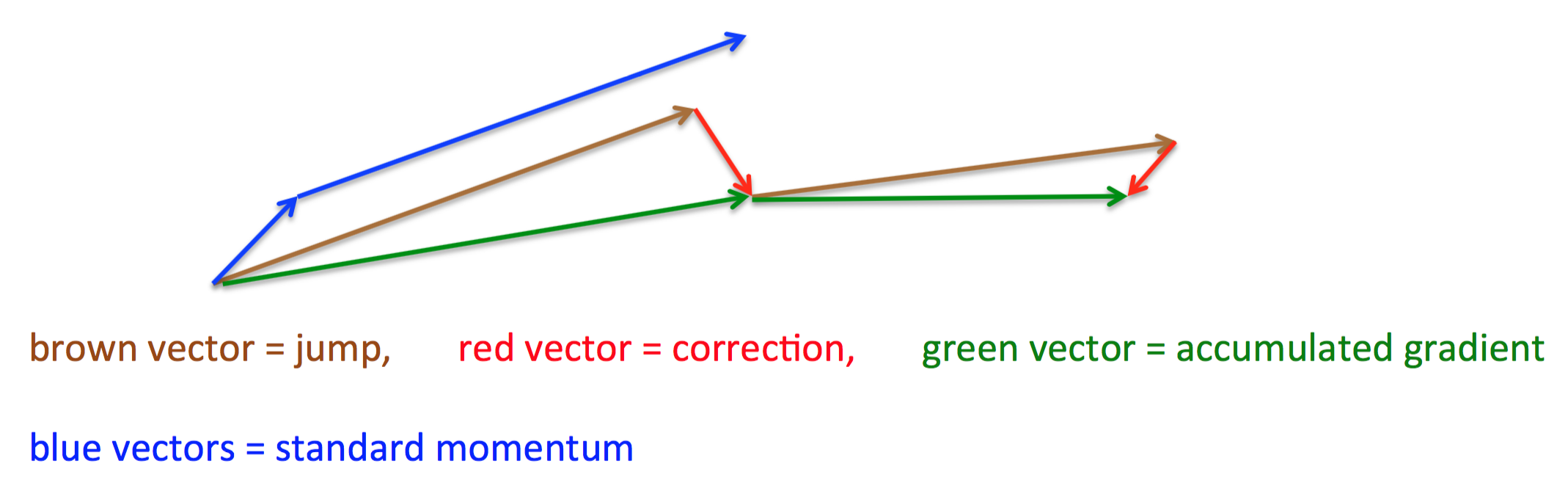
首先,依照原来的更新方向更新一步(棕色线)。然后在该位置计算梯度值(红色线),然后用这个梯度值修正终于的更新方向(绿色线)。
上图中描写叙述了两步的更新示意图。当中蓝色线是标准momentum更新路径。
公式描写叙述为:
Adagrad
上面提到的方法对于全部參数都使用了同一个更新速率。可是同一个更新速率不一定适合全部參数。比方有的參数可能已经到了仅须要微调的阶段。但又有些參数因为相应样本少等原因,还须要较大幅度的调动。
Adagrad就是针对这一问题提出的,自适应地为各个參数分配不同学习率的算法。其公式例如以下:
当中gt 同样是当前的梯度,连加和开根号都是元素级别的运算。eta 是初始学习率。因为之后会自己主动调整学习率,所以初始值就不像之前的算法那样重要了。而ϵ是一个比較小的数,用来保证分母非0。
其含义是,对于每一个參数。随着其更新的总距离增多,其学习速率也随之变慢。
Adadelta
Adagrad算法存在三个问题
- 其学习率是单调递减的,训练后期学习率非常小
- 其须要手工设置一个全局的初始学习率
- 更新xt时。左右两边的单位不同一
Adadelta针对上述三个问题提出了比較美丽的解决方式。
首先,针对第一个问题,我们能够仅仅使用adagrad的分母中的累计项离当前时间点比較近的项,例如以下式:
这里ρ是衰减系数,通过这个衰减系数。我们令每一个时刻的gt随之时间依照ρ指数衰减。这样就相当于我们仅使用离当前时刻比較近的gt信息。从而使得还非常长时间之后,參数仍然能够得到更新。
针对第三个问题,事实上sgd跟momentum系列的方法也有单位不统一的问题。sgd、momentum系列方法中:
相似的,adagrad中,用于更新Δx的单位也不是x的单位。而是1。
而对于牛顿迭代法:
当中H为Hessian矩阵。因为其计算量巨大。因而实际中不常使用。其单位为:
注意,这里f无单位。因而,牛顿迭代法的单位是正确的。
所以,我们能够模拟牛顿迭代法来得到正确的单位。注意到:
这里,在解决学习率单调递减的问题的方案中,分母已经是∂f∂x的一个近似了。这里我们能够构造Δx的近似,来模拟得到H−1的近似,从而得到近似的牛顿迭代法。详细做法例如以下:
能够看到,如此一来adagrad中分子部分须要人工设置的初始学习率也消失了,从而顺带攻克了上述的第二个问题。
各个方法的比較
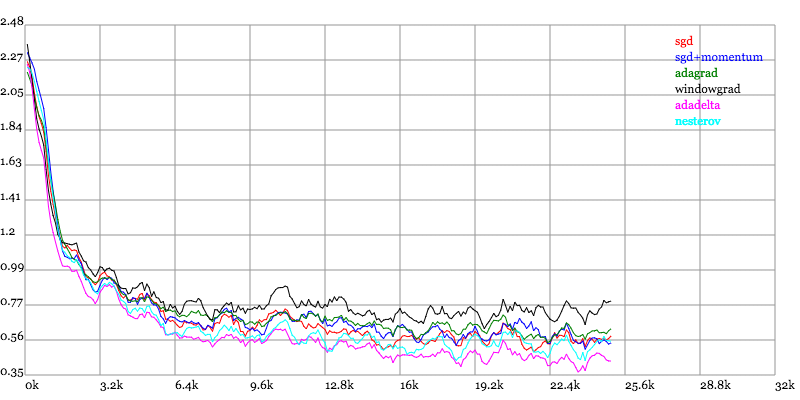
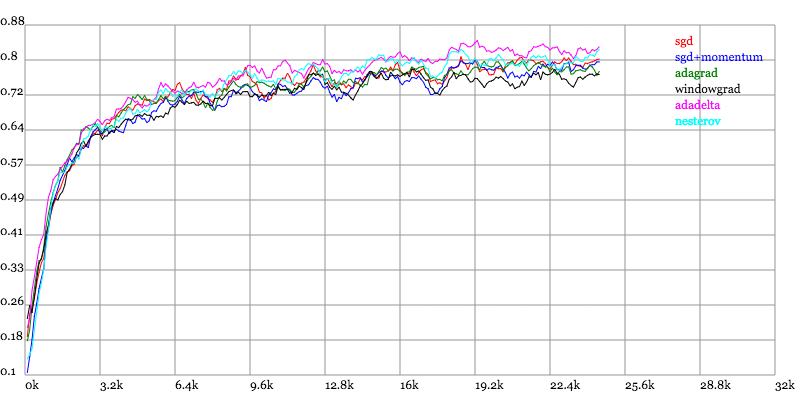
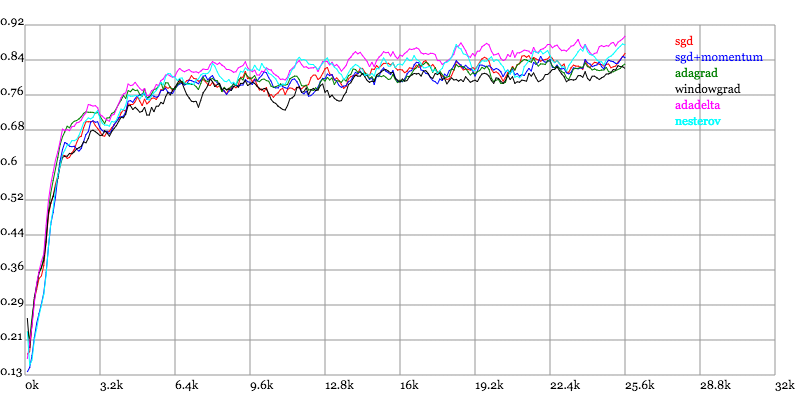
Karpathy做了一个这几个方法在MNIST上性能的比較,其结论是:
adagrad相比于sgd和momentum更加稳定,即不须要怎么调參。而精调的sgd和momentum系列方法不管是收敛速度还是precision都比adagrad要好一些。
在精调參数下,一般Nesterov优于momentum优于sgd。而adagrad一方面不用怎么调參,还有一方面其性能稳定优于其它方法。
实验结果图例如以下:
Loss vs. Number of examples seen
Testing Accuracy vs. Number of examples seen
Training Accuracy vs. Number of examples seen
其它总结文章
近期看到了一个非常棒的总结文章,除了本文的几个算法。还总结了RMSProp跟ADAM(当中ADAM是眼下最好的优化算法,不知道用什么的话用它就对了)
各种优化方法总结比較(sgd/momentum/Nesterov/adagrad/adadelta)的更多相关文章
- 各种优化方法总结比较(sgd/momentum/Nesterov/adagrad/adadelta)
前言 这里讨论的优化问题指的是,给定目标函数f(x),我们需要找到一组参数x,使得f(x)的值最小. 本文以下内容假设读者已经了解机器学习基本知识,和梯度下降的原理. SGD SGD指stochast ...
- 各种优化方法总结比较(sgd/momentum/Nesterov/adagrad/adadelta)
前言 这里讨论的优化问题指的是,给定目标函数f(x),我们需要找到一组参数x,使得f(x)的值最小. 本文以下内容假设读者已经了解机器学习基本知识,和梯度下降的原理. Batch gradient d ...
- 深度学习常见的优化方法(Optimizer)总结:Adam,SGD,Momentum,AdaGard等
机器学习的常见优化方法在最近的学习中经常遇到,但是还是不够精通.将自己的学习记录下来,以备不时之需 基础知识: 机器学习几乎所有的算法都要利用损失函数 lossfunction 来检验算法模型的优劣, ...
- 几种优化方法的整理(SGD,Adagrad,Adadelta,Adam)
参考自: https://zhuanlan.zhihu.com/p/22252270 常见的优化方法有如下几种:SGD,Adagrad,Adadelta,Adam,Adamax,Nadam 1. SG ...
- 机器学习优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)
SGD: 此处的SGD指mini-batch gradient descent,关于batch gradient descent, stochastic gradient descent, 以及 mi ...
- 优化器,SGD+Momentum;Adagrad;RMSProp;Adam
Optimization 随机梯度下降(SGD): 当损失函数在一个方向很敏感在另一个方向不敏感时,会产生上面的问题,红色的点以“Z”字形梯度下降,而不是以最短距离下降:这种情况在高维空间更加普遍. ...
- 【python实现卷积神经网络】优化器的实现(SGD、Nesterov、Adagrad、Adadelta、RMSprop、Adam)
代码来源:https://github.com/eriklindernoren/ML-From-Scratch 卷积神经网络中卷积层Conv2D(带stride.padding)的具体实现:https ...
- 优化方法总结以及Adam存在的问题(SGD, Momentum, AdaDelta, Adam, AdamW,LazyAdam)
优化方法总结以及Adam存在的问题(SGD, Momentum, AdaDelta, Adam, AdamW,LazyAdam) 2019年05月29日 01:07:50 糖葫芦君 阅读数 455更多 ...
- 深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam) 深度学习笔记(一):logistic分类 深度学习笔记(二):简单神经网络,后向传播算法及实现 ...
随机推荐
- python-day5-格式化输入
python格式化输入包含'%'调用,及format方法 使用‘%’进行格式化输出 #最简单的字符串传参 tpl='i am %s '%'alex' >>>i am alex #字符 ...
- 堆STL和重载运算符
大根堆: 1.priority_queue<int> q;[默认 2. priority_queue< node,vector<node>,less<node> ...
- C#的一些基本问题
静态类和静态变量静态类的定义:static class 类名 静态方法和变量必须使用类名来引用,而不能使用实例化后的对象,因为,静态变量不属于任何实例,而是共有的. 非静态类里面既可以定义静态方法也可 ...
- HDU——2089 不要62
不要62 Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submis ...
- FreeBSD利用 ports 來安裝軟體
FreeBSD利用 ports 來安裝軟體 利用 ports 來安裝軟體 FreeBSD 的 ports 就是別人已經編譯過,安裝測試沒問題了,他們將軟體編譯時所需的組態設定.編譯程序及安裝程序, ...
- BZOJ3884 上帝与集合的正确用法 【欧拉定理】
题目 对于100%的数据,T<=1000,p<=10^7 题解 来捉这道神题 欧拉定理的一般形式: \[a^{m} \equiv a^{m \mod \varphi(p) + [m \ge ...
- Linux PC开发环境搭建建议
搭建Linux PC开发环境 很早之前整理的在Linux(ubuntu)系统下搭建 PC开发环境的工具的推荐和简单说明,尽管现在有些已经不再使用,但还是要备份一下,作为以后的参考: package: ...
- https总结
http与https不能互相发送ajax请求,因为跨域了. http页面请求https静态资源可以,但是https请求http静态资源会提示错误. 总之,宽松的可以请求严格的,但是严格的不能请求宽松的 ...
- (转载--修改)使用Xcode9的Instruments检测解决iOS内存泄露
作为一名iOS开发攻城狮,在苹果没有出ARC(自动内存管理机制)时,我们几乎有一半的开发时间都耗费在这么管理内存上.后来苹果很人性的出了ARC,虽然在很大程度上,帮助我们开发者节省了精力和时间.但是我 ...
- Java之Jenkins工具【转】
1.1 前言 Jenkins是一个用Java编写的开源的持续集成工具.在与Oracle发生争执后,项目从Hudson项目独立. Jenkins提供了软件开发的持续集成服务.它运行在Servlet容器中 ...