re--模块【转】
为什么要学正则表达式
实际上爬虫一共就四个主要步骤:
- 明确目标 (要知道你准备在哪个范围或者网站去搜索)
- 爬 (将所有的网站的内容全部爬下来)
- 取 (去掉对我们没用处的数据)
- 处理数据(按照我们想要的方式存储和使用)
对于文本的过滤或者规则的匹配,最强大的就是正则表达式,是Python爬虫世界里必不可少的神兵利器。
什么是正则表达式
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 给定的字符串是否符合正则表达式的过滤逻辑(“匹配”);
- 通过正则表达式,从文本字符串中获取我们想要的特定部分(“过滤”)。
正则表达式匹配规则

Python 的 re 模块
在 Python 中,我们可以使用内置的 re 模块来使用正则表达式。
有一点需要特别注意的是,正则表达式使用 对特殊字符进行转义,所以如果我们要使用原始字符串,只需加一个 r 前缀,示例:
r'chuanzhiboke\t\.\tpython'
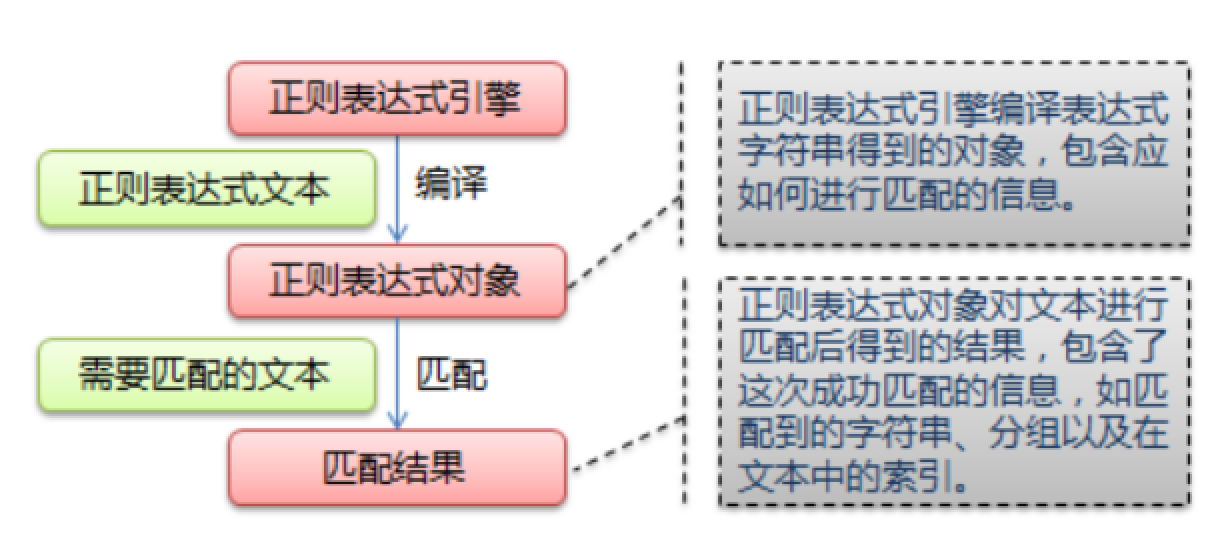
re 模块的一般使用步骤如下:
使用
compile()函数将正则表达式的字符串形式编译为一个Pattern对象通过
Pattern对象提供的一系列方法对文本进行匹配查找,获得匹配结果,一个 Match 对象。- 最后使用
Match对象提供的属性和方法获得信息,根据需要进行其他的操作
compile 函数
compile 函数用于编译正则表达式,生成一个 Pattern 对象,它的一般使用形式如下:
import re
# 将正则表达式编译成 Pattern 对象
pattern = re.compile(r'\d+')
在上面,我们已将一个正则表达式编译成 Pattern 对象,接下来,我们就可以利用 pattern 的一系列方法对文本进行匹配查找了。
Pattern 对象的一些常用方法主要有:
- match 方法:从起始位置开始查找,一次匹配
- search 方法:从任何位置开始查找,一次匹配
- findall 方法:全部匹配,返回列表
- finditer 方法:全部匹配,返回迭代器
- split 方法:分割字符串,返回列表
- sub 方法:替换
match 方法
match 方法用于查找字符串的头部(也可以指定起始位置),它是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果。它的一般使用形式如下:
match(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。因此,当你不指定 pos 和 endpos 时,match 方法默认匹配字符串的头部。
当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
>>> import re
>>> pattern = re.compile(r'\d+') # 用于匹配至少一个数字
>>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配
>>> print m
None
>>> m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
>>> print m
None
>>> m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
>>> print m # 返回一个 Match 对象
<_sre.SRE_Match object at 0x10a42aac0>
>>> m.group(0) # 可省略 0
'12'
>>> m.start(0) # 可省略 0
3
>>> m.end(0) # 可省略 0
5
>>> m.span(0) # 可省略 0
(3, 5)
在上面,当匹配成功时返回一个 Match 对象,其中:
group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);
start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;
- end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;
- span([group]) 方法返回 (start(group), end(group))。
再看看一个例子:
>>> import re
>>> pattern = re.compile(r'([a-z]+) ([a-z]+)', re.I) # re.I 表示忽略大小写
>>> m = pattern.match('Hello World Wide Web')
>>> print m # 匹配成功,返回一个 Match 对象
<_sre.SRE_Match object at 0x10bea83e8>
>>> m.group(0) # 返回匹配成功的整个子串
'Hello World'
>>> m.span(0) # 返回匹配成功的整个子串的索引
(0, 11)
>>> m.group(1) # 返回第一个分组匹配成功的子串
'Hello'
>>> m.span(1) # 返回第一个分组匹配成功的子串的索引
(0, 5)
>>> m.group(2) # 返回第二个分组匹配成功的子串
'World'
>>> m.span(2) # 返回第二个分组匹配成功的子串
(6, 11)
>>> m.groups() # 等价于 (m.group(1), m.group(2), ...)
('Hello', 'World')
>>> m.group(3) # 不存在第三个分组
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: no such group
------------------------------------------------------------------------------------------------------
search 方法
search 方法用于查找字符串的任何位置,它也是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果,它的一般使用形式如下:
search(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。
当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
让我们看看例子:
>>> import re
>>> pattern = re.compile('\d+')
>>> m = pattern.search('one12twothree34four') # 这里如果使用 match 方法则不匹配
>>> m
<_sre.SRE_Match object at 0x10cc03ac0>
>>> m.group()
'12'
>>> m = pattern.search('one12twothree34four', 10, 30) # 指定字符串区间
>>> m
<_sre.SRE_Match object at 0x10cc03b28>
>>> m.group()
'34'
>>> m.span()
(13, 15)
再来看一个例子:
# -*- coding: utf-8 -*-
import re
# 将正则表达式编译成 Pattern 对象
pattern = re.compile(r'\d+')
# 使用 search() 查找匹配的子串,不存在匹配的子串时将返回 None
# 这里使用 match() 无法成功匹配
m = pattern.search('hello 123456 789')
if m:
# 使用 Match 获得分组信息
print 'matching string:',m.group()
# 起始位置和结束位置
print 'position:',m.span()
执行结果:
matching string: 123456
position: (6, 12)
------------------------------------------------------------------------------------------------------
findall 方法
上面的 match 和 search 方法都是一次匹配,只要找到了一个匹配的结果就返回。然而,在大多数时候,我们需要搜索整个字符串,获得所有匹配的结果。
findall 方法的使用形式如下:
findall(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。
findall 以列表形式返回全部能匹配的子串,如果没有匹配,则返回一个空列表。
看看例子:
import re
pattern = re.compile(r'\d+') # 查找数字
result1 = pattern.findall('hello 123456 789')
result2 = pattern.findall('one1two2three3four4', 0, 10)
print result1
print result2
执行结果:
['123456', '789']
['1', '2']
再先看一个栗子:
# re_test.py
import re
#re模块提供一个方法叫compile模块,提供我们输入一个匹配的规则
#然后返回一个pattern实例,我们根据这个规则去匹配字符串
pattern = re.compile(r'\d+\.\d*')
#通过partten.findall()方法就能够全部匹配到我们得到的字符串
result = pattern.findall("123.141593, 'bigcat', 232312, 3.15")
#findall 以 列表形式 返回全部能匹配的子串给result
for item in result:
print item
运行结果:
123.141593
3.15
------------------------------------------------------------------------------------------------------
finditer 方法
finditer 方法的行为跟 findall 的行为类似,也是搜索整个字符串,获得所有匹配的结果。但它返回一个顺序访问每一个匹配结果(Match 对象)的迭代器。
看看例子:
# -*- coding: utf-8 -*-
import re
pattern = re.compile(r'\d+')
result_iter1 = pattern.finditer('hello 123456 789')
result_iter2 = pattern.finditer('one1two2three3four4', 0, 10)
print type(result_iter1)
print type(result_iter2)
print 'result1...'
for m1 in result_iter1: # m1 是 Match 对象
print 'matching string: {}, position: {}'.format(m1.group(), m1.span())
print 'result2...'
for m2 in result_iter2:
print 'matching string: {}, position: {}'.format(m2.group(), m2.span())
执行结果:
<type 'callable-iterator'>
<type 'callable-iterator'>
result1...
matching string: 123456, position: (6, 12)
matching string: 789, position: (13, 16)
result2...
matching string: 1, position: (3, 4)
matching string: 2, position: (7, 8)
------------------------------------------------------------------------------------------------------
split 方法
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
split(string[, maxsplit])
其中,maxsplit 用于指定最大分割次数,不指定将全部分割。
看看例子:
import re
p = re.compile(r'[\s\,\;]+')
print p.split('a,b;; c d')
执行结果:
['a', 'b', 'c', 'd']
------------------------------------------------------------------------------------------------------
sub 方法
sub 方法用于替换。它的使用形式如下:
sub(repl, string[, count])
其中,repl 可以是字符串也可以是一个函数:
如果 repl 是字符串,则会使用 repl 去替换字符串每一个匹配的子串,并返回替换后的字符串,另外,repl 还可以使用 id 的形式来引用分组,但不能使用编号 0;
如果 repl 是函数,这个方法应当只接受一个参数(Match 对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
- count 用于指定最多替换次数,不指定时全部替换。
看看例子:
import re
p = re.compile(r'(\w+) (\w+)') # \w = [A-Za-z0-9]
s = 'hello 123, hello 456'
print p.sub(r'hello world', s) # 使用 'hello world' 替换 'hello 123' 和 'hello 456'
print p.sub(r'\2 \1', s) # 引用分组
def func(m):
return 'hi' + ' ' + m.group(2)
print p.sub(func, s)
print p.sub(func, s, 1) # 最多替换一次
执行结果:
hello world, hello world
123 hello, 456 hello
hi 123, hi 456
hi 123, hello 456
------------------------------------------------------------------------------------------------------
匹配中文
在某些情况下,我们想匹配文本中的汉字,有一点需要注意的是,中文的 unicode 编码范围 主要在 [u4e00-u9fa5],这里说主要是因为这个范围并不完整,比如没有包括全角(中文)标点,不过,在大部分情况下,应该是够用的。
假设现在想把字符串 title = u'你好,hello,世界' 中的中文提取出来,可以这么做:
import re
title = u'你好,hello,世界'
pattern = re.compile(ur'[\u4e00-\u9fa5]+')
result = pattern.findall(title)
print result
注意到,我们在正则表达式前面加上了两个前缀 ur,其中 r 表示使用原始字符串,u 表示是 unicode 字符串。
执行结果:
[u'\u4f60\u597d', u'\u4e16\u754c']
注意:贪婪模式与非贪婪模式
- 贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配 ( * );
- 非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配 ( ? );
- Python里数量词默认是贪婪的。
示例一 : 源字符串:abbbc
- 使用贪婪的数量词的正则表达式
ab*,匹配结果: abbb。*决定了尽可能多匹配 b,所以a后面所有的 b 都出现了。
- 使用非贪婪的数量词的正则表达式
ab*?,匹配结果: a。即使前面有
*,但是?决定了尽可能少匹配 b,所以没有 b。
示例二 : 源字符串:aa<div>test1</div>bb<div>test2</div>cc
使用贪婪的数量词的正则表达式:
<div>.*</div>匹配结果:
<div>test1</div>bb<div>test2</div>
这里采用的是贪婪模式。在匹配到第一个“
</div>”时已经可以使整个表达式匹配成功,但是由于采用的是贪婪模式,所以仍然要向右尝试匹配,查看是否还有更长的可以成功匹配的子串。匹配到第二个“</div>”后,向右再没有可以成功匹配的子串,匹配结束,匹配结果为“<div>test1</div>bb<div>test2</div>”
使用非贪婪的数量词的正则表达式:
<div>.*?</div>匹配结果:
<div>test1</div>
正则表达式二采用的是非贪婪模式,在匹配到第一个“
</div>”时使整个表达式匹配成功,由于采用的是非贪婪模式,所以结束匹配,不再向右尝试,匹配结果为“<div>test1</div>”。
侵权删:
笔记来自传智播客课件, 感谢传智.
re--模块【转】的更多相关文章
- npm 私有模块的管理使用
你可以使用 NPM 命令行工具来管理你在 NPM 仓库的私有模块代码,这使得在项目中使用公共模块变的更加方便. 开始前的工作 你需要一个 2.7.0 以上版本的 npm ,并且需要有一个可以登陆 np ...
- node.js学习(三)简单的node程序&&模块简单使用&&commonJS规范&&深入理解模块原理
一.一个简单的node程序 1.新建一个txt文件 2.修改后缀 修改之后会弹出这个,点击"是" 3.运行test.js 源文件 使用node.js运行之后的. 如果该路径下没有该 ...
- ES6模块import细节
写在前面,目前浏览器对ES6的import支持还不是很好,需要用bable转译. ES6引入外部模块分两种情况: 1.导入外部的变量或函数等: import {firstName, lastName, ...
- Python标准模块--ContextManager
1 模块简介 在数年前,Python 2.5 加入了一个非常特殊的关键字,就是with.with语句允许开发者创建上下文管理器.什么是上下文管理器?上下文管理器就是允许你可以自动地开始和结束一些事情. ...
- Python标准模块--Unicode
1 模块简介 Python 3中最大的变化之一就是删除了Unicode类型.在Python 2中,有str类型和unicode类型,例如, Python 2.7.6 (default, Oct 26 ...
- Python标准模块--Iterators和Generators
1 模块简介 当你开始使用Python编程时,你或许已经使用了iterators(迭代器)和generators(生成器),你当时可能并没有意识到.在本篇博文中,我们将会学习迭代器和生成器是什么.当然 ...
- 自己实现一个javascript事件模块
nodejs中的事件模块 nodejs中有一个events模块,用来给别的函数对象提供绑定事件.触发事件的能力.这个别的函数的对象,我把它叫做事件宿主对象(非权威叫法),其原理是把宿主函数的原型链指向 ...
- 理解nodejs模块的scope
描述 原文档地址:https://docs.npmjs.com/misc/scope 所有npm模块都有name,有的模块的name还有scope.scope的命名规则和name差不多,同样不能有ur ...
- nodejs模块发布及命令行程序开发
前置技能 npm工具为nodejs提供了一个模块和管理程序模块依赖的机制,当我们希望把模块贡献出去给他人使用时,可以把我们的程序发布到npm提供的公共仓库中,为了方便模块的管理,npm规定要使用一个叫 ...
- 开始学nodejs——net模块
net模块的组成部分 详见 http://nodejs.cn/api/net.html 下面整理出了整个net模块的知识结构,和各个事件.方法.属性的用法 net.Server类 net.Socket ...
随机推荐
- hdu6313( 2018 Multi-University Training Contest 2)
bryce1010模板 http://acm.hdu.edu.cn/showproblem.php?pid=6313 参考dls的讲解: 以5*5的矩阵为例: 后一列分别对前一列+0+1+2+3+4操 ...
- foreach循环与迭代器循环 删除插入元素的区别
(1)仅对其遍历而不修改容器大小时,只使用foreach循环 (2)需要边遍历边修改容器大小时(插入删除元素),只使用迭代器循环 import java.util.HashMap;import ja ...
- String的小笔记
String类的对象是不可变的! 在使用String类的时候要始终记着这个观念.一旦创建了String对象,它就不会改变. String类中也有可以改变String中字符串的方法,但只要是涉及改变的方 ...
- java中的线程安全是什么?什么叫线程安全?什么叫不安全?
java中的线程安全是什么: 就是线程同步的意思,就是当一个程序对一个线程安全的方法或者语句进行访问的时候,其他的不能再对他进行操作了,必须等到这次访问结束以后才能对这个线程安全的方法进行访问 什么叫 ...
- docker命令自动安装
docker命令自动安装 操作 操作就是执行两句脚本 curl -fsSL get.docker.com -o get-docker.sh 这句命令会在当前文件夹下下载一个get-docker.sh的 ...
- Linux下环境搭建(三)——jmeter+ant配置
在linux环境下,使用jmeter做接口自动化,做好了前两步的准备工作后,怎能少了主角jmeter+ant了,今天就来说下jmeter+ant的配置方式. jmeter配置 jmeter下载地址:h ...
- LINUX 安装JDK (rpm格式和tar.gz格式)
谷歌博客地址:http://tsaiquinn.blogspot.com/2014/10/linux-jdk-rpmtargz.html JDK rpm方式: 我使用的是SecureCRT,先下载了然 ...
- spring 上传附件
jsp: <form class='uk-form' action="savelead" method="post" enctype="mult ...
- php 正则符号说明
preg_match_all ("/<b>(.*)<\/b>/U", $userinfo, $pat_array); preg_match_all (&qu ...
- 洛谷 P2617 Dynamic Ranking
题目描述 给定一个含有n个数的序列a[1],a[2],a[3]……a[n],程序必须回答这样的询问:对于给定的i,j,k,在a[i],a[i+1],a[i+2]……a[j]中第k小的数是多少(1≤k≤ ...