Python基础-week03 集合 , 文件操作 和 函数详解
一.集合及其运算
1.集合的概念
集合是一个无序的,不重复的数据组合,它的主要作用如下
*去重,把一个列表变成集合,就自动去重了
*关系测试,测试两组数据之前的交集、并集、差集、子集、父级、对称差集,判断没有交集等关系
2.常用操作:
1):集合的增删改查:
#http://www.cnblogs.com/Jame-mei
#集合的增删改查等基本操作 list1=set([1,3,5,7]) #1.增加
list1.add(9) #添加单项,update添加多项。
list1.add('a')
print (list1):
{1, 3, 5, 7, 9,'a'} =======================================
#2.删除
list1.remove(1) #删除指定单个,如果指定不存在报错
list1.pop() #删除任意并返回
list1.discard('absdf') ##删除指定单个,如果指定不存在返回None值(不报错) print (list1):
{3, 5, 7}
======================================= #3.修改
list1.update([2,4,6]) #注意这里格式,为列表的格式!!
list1.update(['a','A','b','C'])
print (list1)#(输出后,会添加到集合里,顺序是随机的!)
{1, 2, 3, 4, 5, 6, 7, 'b', 'C', 'a', 'A'} list2=set('') #注意这里的类型为字符串类型!
list2.update('')
list3.update(('',''))
print (list2)
print (list2)#(输出后,会添加到即合理里,顺序是随机的!)
{'', '', '', '', '', '','','',''} list3=set((1,2,3,4)) #注意这里的类型为元祖!
list3.update((456,)) #添加单个元祖的时候,必须要加,逗号,不然会报错。
print (list3) #
{1, 2, 3, 4, 456} list4=set({'name':'小明','sex':'男'}) #添加字典到集合中
list4.update({'age':25,'address':'abc'}) print (list4)#输出后,只有key
{'sex', 'name', 'address', 'age'} ======================================== #4.查看 #1):长度
print(len(list1)) #2):查看元素是否在集合中(列表,字典,集合,字符串都可以用in 或者not in来判断!!!)
print (5 in list1)
#3):查看元素是否不是list1中
print (9 not in list1) #4):测试list1是否是list2的子集
list2=set([1,3,5,7,9]) print(list1.issubset(list2))
#运算符
print (list1<=list2) #5):测试list2是否是list1的父级
print(list2.issuperset(list1))
#运算符
print (list2>=list1) #还有并集 | ,差集 - ,对称差集 ^,浅coyp: list1.copy等等
2):常见的集合运算和集合运算符
#Author Jame-Mei #1.去除除列表中重复值
list1=[1,3,5,7,1,2,4,7] list1=set(list1)
print (list1,type(list1)) output:
{1, 2, 3, 4, 5, 7} <class 'set'>
=========================================================================================>>>>>>>> #2.取交集:关系测试
list1=set([1,3,6,7,9])
list2=set([2,4,6,7,8])
#其中重复为6,7
print (list1,list2):
{1, 3, 6, 7, 9} {2, 4, 6, 7, 8} #list3为交集的元素
list3=list1.intersection(list2)
print (list3):
{6, 7} #交集元算符:& (两边无先后顺序)
list1 & list2
=========================================================================================>>>>>>>> #2.取并:union()
list1=set([1,3,5])
list2=set([2,4,6]) list3=list1.union(list2)
print (list3):
{1, 2, 3, 4, 5, 6} #并集运算符:| (两边无先后顺序)
list1 | list2
=========================================================================================>>>>>>>> #3.差集:求list1和list2共有的以外的,各自的元素。
list1=set([1,3,5,7,9])
list2=set([2,4,6,7,9]) #取list1的差集,list2中没有的,属于list1的。
list3=list1.difference(list2)
print (list3):
{1, 3, 5} #取list2的差集,list1中没有的,属于list2的。
list4=list2.difference(list1)
print (list4):
{2, 4, 6} #差集运算符: - (在左边,不在右边)
list1 - list2 list2 - list1(差集的元素在list2中,不在list1中)
=========================================================================================>>>>>>>> #4.子集:list1是否是list2的子集(儿子),list1里面有的list2都有,list2里面有的,list1不一定有(list2包括list1)
list1=set([1,3,5])
list2=set([1,3,5,7,9])
print (list1.issubset(list2)):
True
=========================================================================================>>>>>>>> #5.父级:list1是否是list2的父级(父亲),list1包括list2,list1里面有的list不一定有,list2有的list1一定有。
list2=set([1,3,5])
list1=set([1,3,5,7,9])
print(list1.issuperset(list2)):
True
=========================================================================================>>>>>>>> #6.对称差集:去除2者重复后的所有元素,或者这两者的差集相加,(互相都没有的和)就是对称差集。
list2=set([1,3,5,8,10,12])
list1=set([1,3,5,7,9]) print (list1.symmetric_difference(list2)):
{7, 8, 9, 10, 12} #对称差集的元算符: ^ (返回一个新的 set 包含 list1 和 list2 中不重复的元素 ,无顺序关系!)
list1 ^ list2 =========================================================================================>>>>>>>>
#7.判断没有交集,True=没有交集,False=有交集。
list1=set([1,3,5])
list2=set([2,4,6]) flag=list1.isdisjoint(list2)
print(flag):
True
二.文件读与写详解(1-3)
*对文件操作流程:
1):打开文件,得到文件句柄并赋值给一个变量
2):通过句柄对文件进行操作
3):关闭文件
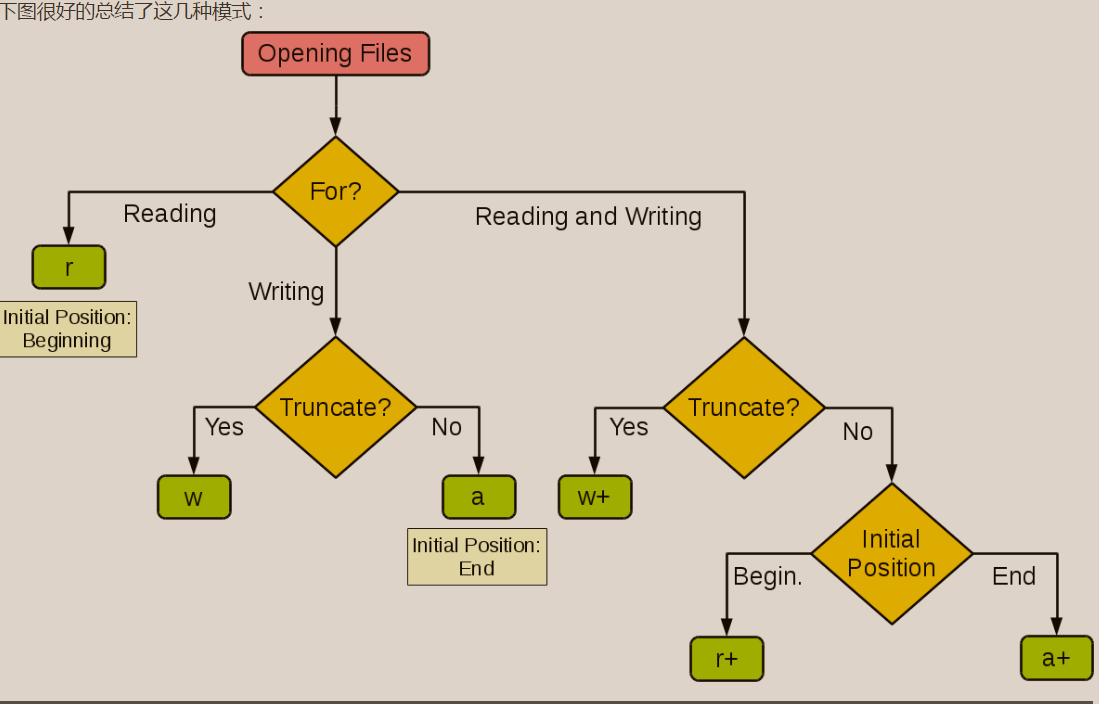
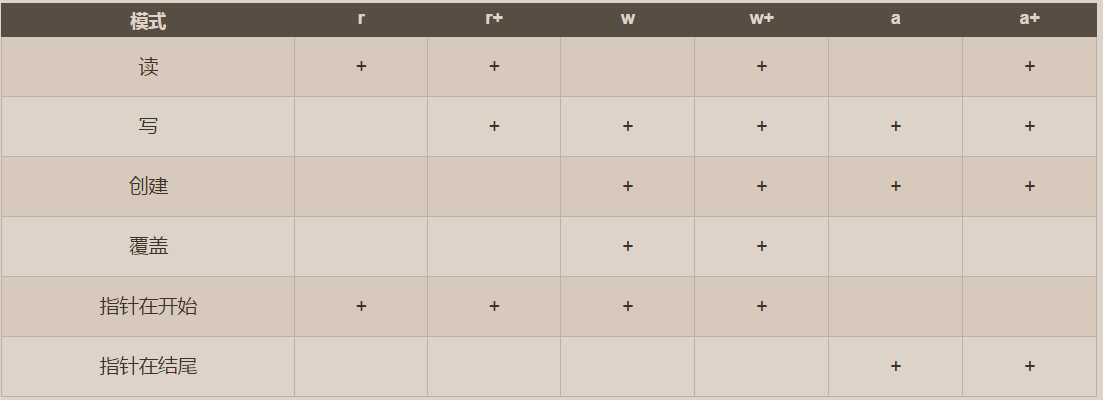
*打开文件的模式有:
- r,只读模式(默认)。
- w,只写模式。【不可读;不存在则创建;存在则删除内容;】
- a,追加模式。【可读; 不存在则创建;存在则只追加内容;】
"+" 表示可以同时读写某个文件:
- r+,可读写文件。【可读;可写;可追加】
- w+,写读
- a+,追加读写!
"U"表示在读取时,可以将 \r \n \r\n自动转换成 \n (与 r 或 r+ 模式同使用)
- rU
- r+U
"b"表示处理二进制文件(如:FTP发送上传ISO镜像文件,linux可忽略,windows处理二进制文件时需标注)
- rb
- wb
- ab
1.文件的基本操作
#Author:Jame Mei
#在当前目录新建yesterdaytext和yesterday两个文件 '''#1.默认方式为'r'的方式打开读取文件
file1=open("yesterdaytext",encoding='UTF-8').read()
print (file1)
''' """
#2.读取改进款,f为文件句柄(记录文件的文件名、文件位置,文件大小等等),'r'打开文件的模式:注意位置,不写默认r模式。
f=open('yesterdaytext','r',encoding='utf-8')
data1=f.read()
data2=f.read()
print (data1) #data1正常输出!!
print ("=========data2=====发现data2为空....无法再从头读一遍!===")
print (data2)
""" '''#3.写覆盖模式w
f=open("yesterday",'w',encoding='utf-8')
f.write("我爱北京天安门\n")
f.write("天安门上红旗飘扬")
''' '''#4.写追加模式a
f=open("yesterday",'a',encoding='utf-8') f.write("one night beijin,我留下很多情!")
f.write('\n不敢在午夜问路,怕惊醒了帝都的魂!')
'''
2.文件操作的一些方法
#Author http://www.cnblogs.com/Jame-mei '''#1.读文件的前五行
f=open('yesterdaytext','r',encoding='utf-8') 方法1:(计数法)
count=0
for line in f:
if count<5:
print (line.strip())
else:
break
count+=1 方法2:(最简法)
for i in range(5):
print (f.readline().strip()) 方法3:(取小标法)
for index,line in enumerate(f.readlines()):
if index<5:
print (line.strip())
else:
break
''' '''#2.读取文件,跳过第十行显示分割线(打印出来发现第十行被print覆盖了,源文件没改变)!
f=open('yesterdaytext','r',encoding='utf-8')
方法1:(下标法)
for index,line in enumerate(f.readlines()):
if index==9:
print ('-------------------------------------我是分割线------------------------------')
continue
print (line.strip()) 方法2:计数法:
count=0
for line in f:
if count==9:
print ('----------------------第10行分割线--------------------')
else:
print (line.strip())
count+=1 ''' '''#3.readline只适合读取小文件,用下面的方式来读,效率高,内存中只保存一行,适合数据了大的场景!!
#f相当于迭代器
count=0
f=open('yesterdaytext','r',encoding='utf-8')
for line in f:
if count==9:
print ('---------------------------过滤第10行-------------------------->>>>>>>>>>>>>>')
count += 1
continue
print (line.strip())
count+=1
''' '''#4.对于read()读过一遍后,无法再从头读,进行解答。
#重要函数readline(),seek()!
上文疑问实例预览:
data1=f.read()
data2=f.read()
print (data1) #data1正常输出!!
print ("=========data2=====发现data2为空....无法再从头读一遍!===")
print (data2) #解决:
f=open('yesterdaytext','r',encoding='utf-8')
print (f.tell()) #告诉目前光标的位置!
print (f.readline()) #读取一行
print (f.readline()) #读取2行后,我现在想返回?
#print (f.read(5)) #去读指定的个数字符
print (f.tell()) f.seek(0)#返回开头的光标的位置!
#f.seek(10) #把光标移动到第10个字符前,readline()从第10个字符读到第一行的结尾。
print (f.readline())
print (f.tell()) #又到了读完第一行的光标位置!
''' '''#5.enconding()方法,fileno()方法读取文件的内存里的编号,isatty()判断是否一个底层不可打印设备。
f=open('yesterdaytext','r',encoding='utf-8')
print(f.encoding):
utf-8
print (f.fileno()):
3
print (f.isatty()):
False
''' '''#6.seekable ,判断是否可以移动。readable(),writeable()
f=open('yesterdaytext','r',encoding='utf-8') print (f.seekable()):
True
print (f.readable()):
True
print (f.writable()):
False
''' '''#7.flush(),在windows或者linux的终端窗口下效果比较明显,防止断电没有从内存中写入到磁盘。
#closed判断文件是否关闭了,没有关闭False!
f=open('yesterday02','w',encoding='utf-8')
f.write("hello") #在dos下写过之后,查看yesterday02并没有写入,flush()之后才能看到存储到文件中。
f.flush() print (f.closed):
False
''' '''#8.truncate()截断,w如果不写会清空文件,a如果不写默认不操作。写了10,从第10个字符截断,后面的删除。
f=open('yesterday02','a',encoding='utf-8')
#f.truncate()
f.seek(10) #光标跳到第10个字符,截图前20个,后面的删除!!
f.truncate(20)
'''
实现windows or linux安装进度条打印效果:
#Author:Jame Mei
import sys,time #实现windows安装进度条显示..........
for i in range(30):
sys.stdout.write("#")
sys.stdout.flush()
time.sleep(0.3)
3.文件操作的重要参数操作:
r+、w+、a+、rb、wb等
#Author: http://www.cnblogs.com/Jame-mei
'''#1.open()的r+(读写)参数实例,打开读并追加这个比较常用!!
f=open('yesterdaytext','r+',encoding='utf-8')
count=0
for lin in f:
if count==3:
f.write("\n>>>>>打印前三行,开始w的操作>>>") #发现无论如何都无法在第三行之后写,只能从最后开始追加写入!!
count+=1 print(f.readline())
count+=1
''' '''#2.open()的w+(写读)参数实例,依然和r+一样,只能从文件的末尾追加写入!这个应用场景比较少
f=open('yesterday02','w+',encoding='utf-8')
f.write("123456789\n")
f.write("23456789\n")
f.write("3456789\n") print(f.tell())
f.seek(10)
print (f.tell()) print (f.readline()) f.write("456789")
f.close()
''' '''#3.open()的a+ 追加读写,a不能读其他和a+一样
f=open('yesterdaytext','a+',encoding='utf-8')
f.seek(0) #如果不移动到文件开头,读出来的为空白! print(f.readline()) f.write('a+++++++光标移动到开始了,依然会追加到末尾!')
#a+存在则光标移动到最后,不存在则创建。
''' #4.open()的rb,wb:以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。
'''f=open('yesterdaytext','rb') #可以以2进制的方式读出来,不进行解码decode()的话,会带b''的方式显示。
print (f.readline())
print (f.readline().decode()) #解码成utf-8格式显示
#如果不去掉enconfing='utf-8'则会valueError: binary mode doesn't take an encoding argument #rb+以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。
f=open('yesterday02','rb+')
print (f.readline())
f.write("2222".encode()) #会在第二行写入,在这行甚至后面行会被覆盖!
print (f.readline())
f.write("111111111111111".encode()) #wb以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。
f=open('yesterday02','wb') #二进制写模式,要把字符串转换bytes
f.write("cedfg".encode()) #encode默认utf-8
#字符串如果不转换成bytes,则出现:TypeError: a bytes-like object is required, not 'str' #wb+以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。
f=open('yesterday02','wb+')
print (f.readline().decode())
f.write('2222222222222222'.encode())
'''
4.with语句
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
|
1
2
3
|
with open('log','r') as f: ... |
如此方式,当with代码块执行完毕时,内部会自动关闭并释放文件资源。
在Python 2.7 后,with又支持同时对多个文件的上下文进行管理,即:
|
1
2
|
with open('log1') as obj1, open('log2') as obj2: pass |
Python官方建议如果一行不要超过80个字符,所以建议同时打开过个文件的时候这样写比较规范,而且方便观看:

三.文件修改详解
1.修改文件中的内容:
思路1:找到需要修改的地方后,修改后另存到新的文件中。
思路2:需要打开2个文件,一个文件读r,一个文件负责写w。
f_old=open('yesterdaytext','r',encoding='utf-8')
f_new=open('yesterdaytext.bak','w',encoding='utf-8')
'''
for line in f_old:
if '肆意的快乐等我享受' in line:
line=line.replace('肆意的快乐等我享受','肆意的快乐等Jame享受')
f_new.write(line) #省略if下面和else下面都写这句,反正都需要执行的操作。
f_old.close()
f_new.close()
2.作业程序练习
程序1: 实现简单的shell sed替换功能
#Author Jame-Mei
import sys f_old=open('oldfile','r',encoding='utf-8')
f_new=open('oldfile.bak','w',encoding='utf-8') find_str=sys.argv[1] #向脚本里传需要查找字符串-参数1
replace_str=sys.argv[2] #向脚本传替换的字符串-参数2 for line in f_old:
if find_str in line:
line=line.replace(find_str,replace_str) f_new.write(line) #去除else,更加简洁 f_old.close()
f_new.close()
程序2:修改haproxy配置文件
需求如下:
需求:
1、查
输入:www.oldboy.org
获取当前backend下的所有记录 2、新建
输入:
arg = {
'bakend': 'www.oldboy.org',
'record':{
'server': '100.1.7.9',
'weight': 20,
'maxconn': 30
}
} 3、删除
输入:
arg = {
'bakend': 'www.oldboy.org',
'record':{
'server': '100.1.7.9',
'weight': 20,
'maxconn': 30
}
} 原配置文件:
global
log 127.0.0.1 local2
daemon
maxconn 256
log 127.0.0.1 local2 info
defaults
log global
mode http
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
option dontlognull listen stats :8888
stats enable
stats uri /admin
stats auth admin:1234 frontend oldboy.org
bind 0.0.0.0:80
option httplog
option httpclose
option forwardfor
log global
acl www hdr_reg(host) -i www.oldboy.org
use_backend www.oldboy.org if www backend www.oldboy.org
server 100.1.7.9 100.1.7.9 weight 20 maxconn 3000
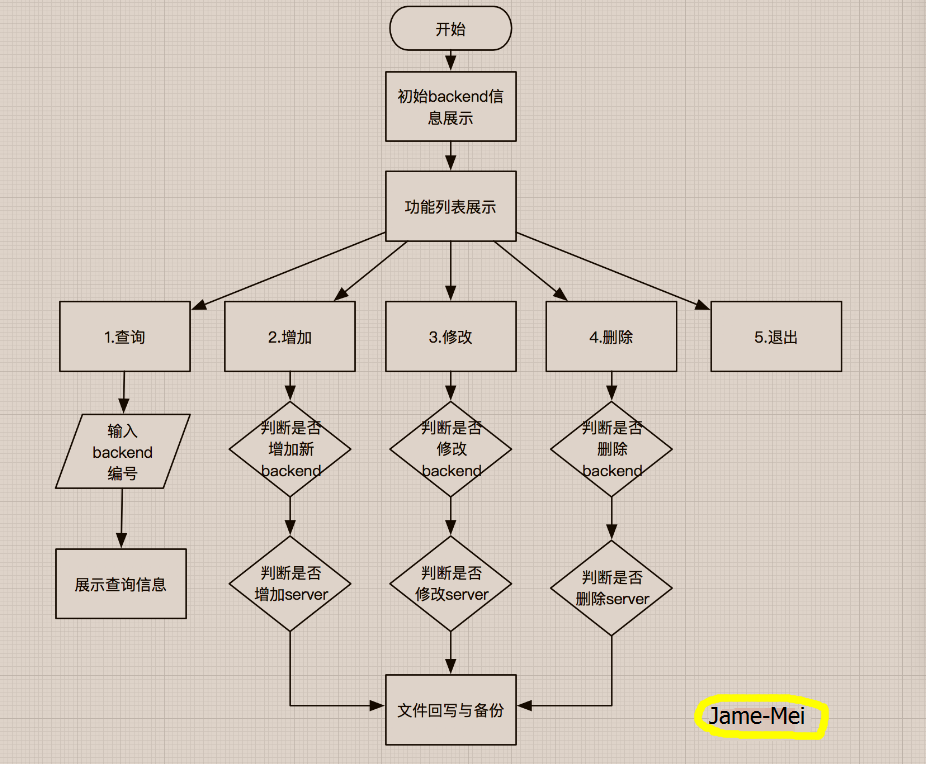
实现过程:
1):流程思维导图
2):代码
# Author: www.cnblogs.com/Jame-mei import os,sys def numif(number_input): # 判断输入是否为数字
while not number_input.isdigit(): # 输入不是数字就进入循环
number_input = input('\033[31m 输入%s不是数字,请重新输入!\033[0m' % number_input) # 提示重新输入
number = number_input
return number def show_list(file): # 查询显示并将文本生成程序需要的字典和列表
backend_list = []
backend_all_dict = {}
backend_dict = {}
server_list = []
with open(file,'r') as f: # 读取haproxy文件
for line in f: line = line.strip()
if line.startswith('backend') == True: # 判断是否是backend开头,读取backend信息写到backend_list中
backend_name = line.split()[1]
backend_list.append(backend_name) # 将文件中backend加到列表中
server_list = [] # 清空server_list里的记录,遇到新backend可以输入新的server_list elif line.startswith('server') == True: # 判断是否是server开头,读取server信息写到backend_all_dict中
backend_dict['name'] = line.split()[1] # 读取文件中server的name
backend_dict['IP'] = line.split()[2] # 读取文件中server的IP
backend_dict['weight'] = line.split()[4] # 读取文件中server的weight
backend_dict['maxconn'] = line.split()[6] # 读取文件中server的maxconn
server_list.append(backend_dict.copy()) # 将backend中的信息加到server_list中,此处需要用copy
backend_all_dict[backend_name] = server_list # 将server信息对应backend存到字典中 return (backend_list,backend_all_dict) # 返回backend和server信息 def backend_show(backend_list): # 展示backend列表内容
backend_show_dict = {}
print("-------------------------------------------------")
print("\t\t\t欢迎来到HAproxy文件配置平台")
print("-------------------------------------------------")
print("backend列表信息如下:")
for k,v in enumerate(backend_list,1): # 逐行读取backend信息并展示
print(k, v)
backend_show_dict[str(k)] = v
return backend_show_dict # 返回backend和对应编号 def server_show(backend_input,backend_all_dict): # 展示backend下server内容
server_show_dict = {}
server_list = backend_all_dict[backend_input]
for k,v in enumerate(server_list,1): # 编号展示server信息
print(k,"name:",v['name'],"\tIP:",v['IP'],"\tweight:",v['weight'],"\tmaxconn:",v['maxconn'])
server_show_dict[k] = v
return server_show_dict # 返回编号对应的server字典 def action_list(): # 显示操作列表和编号,并返回操作编号
print("-------------------------------------------------")
print("操作清单如下:")
print('''
1.查询backend和server信息
2.添加backend和server信息
3.修改backend和server信息
4.删除backend和server信息
5.退出
''')
print("-------------------------------------------------")
action_num = numif(input("请输入需要操作的编号:(请输入数字)"))
return action_num def inquiry(inquiry_input): # 定义查询功能
while True:
if inquiry_input in backend_show_dict: # 编号输入分支
backend_input = backend_show_dict[inquiry_input] # 输入编号得到backend
print(backend_input, ":")
server_show(backend_input, backend_all_dict) # 调用server_show,展示backend下server
break elif inquiry_input in backend_show_dict.values(): # backend名称输入分支
print(inquiry_input, ":")
server_show(inquiry_input, backend_all_dict) # 调用server_show,展示backend下server
break else: # 校验异常输入
inquiry_input = input("输入错误,请重新输入:") def add(add_input,file): # 定义添加功能
(backend_list, backend_all_dict) = show_list(file)
while True:
if add_input in backend_show_dict: #添加原有backend下server
add_dict = {}
add_dict['name'] = input("请输入需增加server名称:")
add_dict['IP'] = input("请输入需增加IP地址:")
add_dict['weight'] = input("请输入需增加weight值:")
add_dict['maxconn'] = input("请输入需增加maxcoon值:")
backend_name_add = backend_list[int(add_input)-1] for dict in backend_all_dict[backend_name_add]: # 实现IP已存在,更新weight信息和maxconn信息
if add_dict['IP'] in dict.values():
dict['weight'] = add_dict['weight']
dict['maxconn'] = add_dict['maxconn']
break else: # IP不存在,就将server增加到backend下
backend_all_dict[backend_name_add].append(add_dict) backup(file,backend_name_add,backend_all_dict) # 调用backup函数,将新增内容读写到文件中
print('''name:%s IP:%s weight:%s maxconn:%s已添加成功'''%(
add_dict['name'],add_dict['IP'],add_dict['weight'],add_dict['maxconn'])) # 提示添加成功
break else: # 添加新backend下的server
add_dict = {}
add_dict['name'] = input("请输入%s下新增server名称:"%add_input)
add_dict['IP'] = input("请输入%s下新增IP地址:"%add_input)
add_dict['weight'] = input("请输入%s下新增weight值:"%add_input)
add_dict['maxconn'] = input("请输入%s下新增maxcoon值:"%add_input)
backend_name_add = add_input
backend_all_dict[backend_name_add] = add_dict # 将新增backend和对应server存到字典中 file_new = "%s_new" % file # 新建一个文件,用来新增数据
with open(file, 'r') as f_read, open(file_new, 'a+') as f_write: # 读取file文件,追加backend信息
for line in f_read:
f_write.write(line)
f_write.write("\nbackend %s" % backend_name_add) # 追加backend信息
server_line_write = '\n\t\tserver {name} {IP} weight {weight} maxconn {maxconn}\n' # 追加server信息
f_write.write(server_line_write.format(**add_dict)) # 格式化输出 os.system('mv %s %s_backup' % (file, file)) # 将file文件名改为file_backup
os.system('mv %s %s' % (file_new, file)) # 将file_new文件名改为file,实现备份
print("\nbackend %s" % backend_name_add)
print('''name:%s IP:%s weight:%s maxconn:%s已添加成功''' % (
add_dict['name'], add_dict['IP'], add_dict['weight'], add_dict['maxconn'])) # 提示添加成功
break def revise(revise_input): # 定义修改功能
revise_dict = {}
if revise_input in backend_show_dict: # 判断输入是否存在
backend_revise = backend_show_dict[revise_input] # 通过编号获取backend
revise_choise = input("是否需要修改该backend名称:%s;确认请按'y',按任意键继续:"%backend_revise) # 确认是否修改backend名,输入y修改,否则继续修改
if revise_choise == 'y':
backend_revise_new = input("请输入修改后的backend名:") # 修改backend名
backend_all_dict[backend_revise_new] = backend_all_dict.pop(backend_revise) # 将旧backend的server对应到修改后的backend上
revise_choise_server = input("是否需要继续修改%s下的server:确认请按'y',按任意键继续:"%backend_revise_new) # 询问是否继续修改
if revise_choise_server == 'y': # 继续修改server
server_revise_dict = server_show(backend_revise_new, backend_all_dict) # 展示server信息
server_revise_num = numif(input("请输入需要修改的server编号:")) # 获取需要修改的server编号
revise_dict['name'] = input("请输入修改后的name:")
revise_dict['IP'] = input("请输入修改后的IP:")
revise_dict['weight'] = input("请输入修改后的weight:")
revise_dict['maxconn'] = input("请输入修改后的maxconn:")
server_revise_dict[int(server_revise_num)] = revise_dict # 通过编号修改server信息
server_revise_dict_backup = {}
server_revise_dict_backup[backend_revise_new] = server_revise_dict.values() # 将修改的server信息对应到修改后的backend存到字典中
backup(file, backend_revise, server_revise_dict_backup,backend_revise_new) # 调用backup函数,操作文件 else: # 不修改server,只修改了backend
backup(file, backend_revise, backend_all_dict,backend_revise_new)
else: # 未修改backend名情况时修改server信息
server_revise_dict = server_show(backend_revise, backend_all_dict)
server_revise_num = numif(input("请输入需要修改的server编号:")) # 获取需修改的server编号
revise_dict['name'] = input("请输入修改后的name:")
revise_dict['IP'] = input("请输入修改后的IP:")
revise_dict['weight'] = input("请输入修改后的weight:")
revise_dict['maxconn'] = input("请输入修改后的maxconn:")
server_revise_dict[int(server_revise_num)] = revise_dict # 修改的server信息对应到编号中存到字典中
server_revise_dict_backup = {}
server_revise_dict_backup[backend_revise] = server_revise_dict.values() # 将修改后的server信息对应backend存到字典中
backup(file,backend_revise,server_revise_dict_backup) # 调用backup函数,操作文件
else: # 输入错误提示重新输入
revise_input_return = input("需修改backend不存在,请重新输入:")
revise(revise_input_return) def delete(delete_input): # 定义删除功能
if delete_input in backend_show_dict:
backend_delete = backend_show_dict[delete_input]
delete_choise = input("是否需要删除该backend:%s;确认请按'y',按任意键继续:"%backend_delete)
if delete_choise == 'y': # 判断是否删除backend信息
del backend_all_dict[backend_delete] # 在backend与server总字典中删除backend
backup(file, backend_delete, backend_all_dict) # 调用backup函数,操作文件 else: # 删除server
server_delete_dict = server_show(backend_delete, backend_all_dict)
server_delete_num = int(numif(input("请输入需要删除的server编号:"))) # 除判断是否时数字外,还需转换为整数型
while True: # 删除backend下的server循环
if server_delete_num in server_delete_dict: # 判断输入编号是否存在
server_delete_dict.pop(server_delete_num)
server_delete_dict_backup = {}
server_delete_dict_backup[backend_delete] = server_delete_dict.values()
backup(file, backend_delete, server_delete_dict_backup) # 调用backup函数,操作文件
break
else:
server_delete_num = input("输入编号不存在,请重新输入:") # 提示输入错误 def backup(file,backend_name_action,backend_backup_dict,*backend_name_revise): # 定义文档备份与回写功能
file_new = "%s_new"%file
add_flag = False # 为跳过原backend下server存在
with open(file,'r') as f_read , open(file_new,'w+') as f_write: # 同时打开读文件和写文件
for line in f_read: # 读取每行信息
backend_name = "backend %s" % backend_name_action
backend_name_revise = "".join(tuple(backend_name_revise)) # 修改功能会传参,将元组转换为字符串
if line.strip() == backend_name: # 读取某行中有参数中的backend
if backend_name_action not in backend_backup_dict and backend_name_revise not in backend_backup_dict: # 为了删除backend而存在
add_flag = True
pass elif backend_name_revise in backend_backup_dict: # 判断修改功能中修改后backend存在与字典中
line_revise = "backend %s\n" % backend_name_revise
f_write.write(line_revise)
for add_dict in backend_backup_dict[backend_name_revise]: # 逐行读取修改backend下的server信息
server_line_write = '\t\tserver {name} {IP} weight {weight} maxconn {maxconn}\n'
f_write.write(server_line_write.format(**add_dict)) # 格式化输出
add_flag = True else:
f_write.write(line) # 将此行写在文件中
for add_dict in backend_backup_dict[backend_name_action]: # 读取该backend下所有server信息
server_line_write = '\t\tserver {name} {IP} weight {weight} maxconn {maxconn}\n'
f_write.write(server_line_write.format(**add_dict))
add_flag = True elif line.strip().startswith("server") == True and add_flag == True: # 为了跳过原backend下的server
pass else: # 写无用行
f_write.write(line)
add_flag = False # 写下无用行后可以继续循环 os.system('mv %s %s_backup' % (file, file))
os.system('mv %s %s' % (file_new, file)) def backend_exit(): #定义退出功能
flag_exit = True
b_input = input("操作完毕退出请按'b':")
while flag_exit:
if b_input == 'b':
flag_exit = False
return flag_exit else:
return backend_exit() #使用尾递归优化,加上return帮助直接退出,而不需要递归一层层退出 flag = True # 主函数开始
while flag:
flag_main = True
flag_action = True
file = 'haproxy' # 文件名赋值
(backend_list, backend_all_dict) = show_list(file) # 调用show_list函数获取backend和server信息
backend_show_dict = backend_show(backend_list) # 展示backend信息
action_num = action_list() # 展示功能项,并输入操作编号
while flag_main:
if action_num == '':
inquiry(input("请输入需要查询的backend编号或名称:"))
flag_main = backend_exit()
break if action_num == '':
add(input("请输入需要添加的现有backend编号或新backend名称:"), file)
flag_main = backend_exit()
break if action_num == '':
revise(input("请输入需要修改的backend编号或名称:"))
flag_main = backend_exit()
break if action_num == '':
delete(input("请输入需要删除的backend编号或名称:"))
flag_main = backend_exit()
break if action_num == '':
sys.exit() elif action_num not in range(5): # 当输入不在编号中,提示并重新输入
print("\033[31;1m输入错误请重新输入!\033[0m")
flag_main = False
对haproxy.conf增删改查
四.字符编码转化详解(1-2)
1.字符编码与转码
详细文章:
http://www.cnblogs.com/linhaifeng/articles/5950339.html 林海峰老师
http://www.cnblogs.com/yuanchenqi/articles/5956943.html(中文博客整理)
http://www.diveintopython3.net/strings.html(英文文档)
需知:
1.在python2默认编码是ASCII, python3里默认是unicode
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
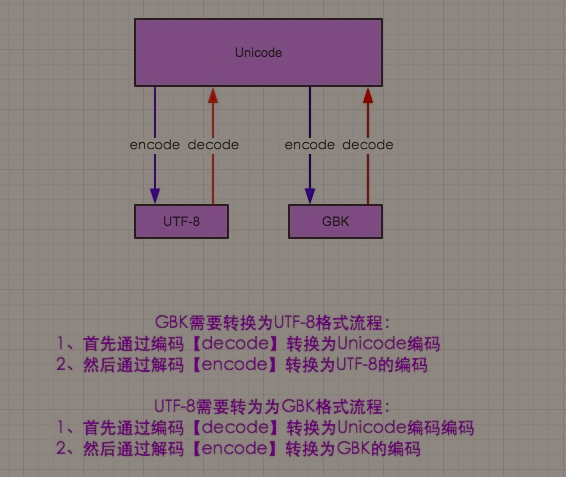
GBK-->UTF-8的转换,依靠unicode来进行(如下图,是适合py2.x,学Py3的也可以作为了解!):
2.字符编码与转码的实例
1):基于py2.7:
#Author:http://www.cnblogs.com/Jame-mei
#-*-coding:utf-8-*-
#注意,基于py2.7必须要加utf-8的解释器 import sys print (sys.getdefaultencoding()) '''
#1.utf-8 转换成gbk
s = '您好'
s_to_unicode=s.decode('utf-8')
print (s_to_unicode)
s_to_gbk=s_to_unicode.encode("gbk")
print (s_to_gbk)#这个在linux终端显示上调整为gbk,才能显示。 #2.gbk转换成utf-8
gbk_to_utf8=s_to_gbk.decode("gbk").encode("utf-8")
print(gbk_to_utf8) ''' '''
#简易版:utf-8转出成gbk
#utf-8是unicode的扩展集,是可以直接打印的,gbk和unicode必须要经过转换才行。
s=u'您好' #将utf-8直接转换成unicode编码!
print(s)
s_to_gbk=s.encode("gbk")
print (s_to_gbk)#这个在linux终端显示上调整为gbk,才能显示。 #2.gbk转换成utf-8
gbk_to_utf8=s_to_gbk.decode("gbk").encode("utf-8")
print(gbk_to_utf8)
''' #3.utf-8转换成gb2312
s="您好"
s_gb2312=s.decode("utf-8").encode("gb2312")
print (s_gb2312) #4.gb2312转换成gbk
gb2312_to_gbk=s_gb2312.decode("gb2312").encode("gbk")
print (gb2312_to_gbk) #5.utf-8转换成gbk
gb2312_to_utf=s.decode("utf-8").encode("gbk")
print (gb2312_to_gbk)
python2.7
2):基于py3.6:
#Author:http://www.cnblogs.com/Jame-mei
#-*-coding:utf-8-*-
#基于python3.x版本 import sys
print (sys.getdefaultencoding()) #1.将utf-8转换成gbk
'''
str="你哈"
str_gbk=str.encode("gbk")
print (str_gbk)
#encode("gbk"):b'\xc4\xe3\xb9\xfe'
#encode()为默认utf-8:b'\xe4\xbd\xa0\xe5\x93\x88' 2.将gbk转成utf-8
gbk_to_utf8=str_gbk.decode("gbk").encode("utf-8")
print (gbk_to_utf8)
''' #3.py3.x中将utf-8转换成gb2312
s="我爱北京天安门"
s_gb2312=s.encode("gb2312") #默认就是unicode,不用再decode,喜大普奔
print (s_gb2312) #4.然后将gb2312转换成utf-8
gb2312_to_unicode=s_gb2312.decode("gb2312")
print (gb2312_to_unicode) unicode_to_utf8=s_gb2312.decode("gb2312").encode("utf-8")
print (unicode_to_utf8) '''
总结:
python3.x默认为2种数据类型:默认unicode和bytes类型,其中utf-8为unicode的扩展,所以utf-8可以直接encode("gbk")转换成gbk
但是gbk不能直接转换成utf-8,需要decode("gbk")再encode("utf-8")才行。 python3中,将unicode转换成gbk,utf8,gb2312类型的时候,同时显示为bytes类型。
''' '''
思考区:
str="你哈" #这里python默认数据类型为unicode编码,coding:gbk只是修改了文件的编码方式。
print (str.encode('gbk'))
print (str.encode('utf-8'))
print (str.encode('utf-8').decode('utf-8').encode('gb2312')) #转换成gb2312,与gbk的bytes结果一样,是因为gbk向下兼容gb2312! '''
python3.6
3.如果对编码格式还是迷茫,请看看alex的鸡汤文:
1)先说python2:
- py2里默认编码是ascii
- 文件开头那个编码声明是告诉解释这个代码的程序 以什么编码格式 把这段代码读入到内存,因为到了内存里,这段代码其实是以bytes二进制格式存的,不过即使是2进制流,也可以按不同的编码格式转成2进制流,你懂么?
- 如果在文件头声明了#_*_coding:utf-8*_,就可以写中文了, 不声明的话,python在处理这段代码时按ascii,显然会出错, 加了这个声明后,里面的代码就全是utf-8格式了
- 在有#_*_coding:utf-8*_的情况下,你在声明变量如果写成name=u"大保健",那这个字符就是unicode格式,不加这个u,那你声明的字符串就是utf-8格式
- utf-8 to gbk怎么转,utf8先decode成unicode,再encode成gbk
2)再说python3:
- py3里默认文件编码就是utf-8,所以可以直接写中文,也不需要文件头声明编码了,干的漂亮
- 你声明的变量默认是unicode编码,不是utf-8, 因为默认即是unicode了(不像在py2里,你想直接声明成unicode还得在变量前加个u), 此时你想转成gbk的话,直接your_str.encode("gbk")即可以
- 但py3里,你在your_str.encode("gbk")时,感觉好像还加了一个动作,就是就是encode的数据变成了bytes里,我擦,这是怎么个情况,因为在py3里,str and bytes做了明确的区分,你可以理解为bytes就是2进制流,你会说,我看到的不是010101这样的2进制呀, 那是因为python为了让你能对数据进行操作而在内存级别又帮你做了一层封装,否则让你直接看到一堆2进制,你能看出哪个字符对应哪段2进制么?什么?自己换算,得了吧,你连超过2位数的数字加减运算都费劲,还还是省省心吧。
- 那你说,在py2里好像也有bytes呀,是的,不过py2里的bytes只是对str做了个别名(python2里的str就是bytes, py3里的str是unicode),没有像py3一样给你显示的多出来一层封装,但其实其内部还是封装了的。 这么讲吧, 无论是2还是三, 从硬盘到内存,数据格式都是 010101二进制到-->b'\xe4\xbd\xa0\xe5\xa5\xbd' bytes类型-->按照指定编码转成你能看懂的文字
编码应用比较多的场景应该是爬虫了,互联网上很多网站用的编码格式很杂,虽然整体趋向都变成utf-8,但现在还是很杂,所以爬网页时就需要你进行各种编码的转换,不过生活正在变美好,期待一个不需要转码的世界。
最后,编码is a piece of fucking shit, noboby likes it.
五.函数与函数式编程(1-2)
1.函数基本语法及特性
函数一词来源于数学,但编程中的「函数」概念,与数学中的函数是有很大不同的,具体区别,我们后面会讲,编程中的函数在英文中也有很多不同的叫法。在BASIC中叫做subroutine(子过程或子程序),在Pascal中叫做procedure(过程)和function,在C中只有function,在Java里面叫做method。
定义: 函数是指将一组语句的集合通过一个名字(函数名)封装起来,要想执行这个函数,只需调用其函数名即可
特性:
- 减少重复代码
- 使程序变的可扩展
- 使程序变得易维护
语法定义:
|
1
2
3
4
|
def sayhi():#函数名 print("Hello, I'm nobody!")sayhi() #调用函数 |
可以带参数:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#下面这段代码a,b = 5,8c = a**bprint(c)#改成用函数写def calc(x,y): res = x**y return res #返回函数执行结果c = calc(a,b) #结果赋值给c变量print(c) |
2.函数的应用场景:
#Author:http://www.cnblogs.com/Jame-mei def func1():
'''定义一个函数:test1'''
print ('in the func1')
return 0 def fun2():
'''定义一个过程(没有返回值的函数!):test2'''
print ('in the func2') x=func1() y=fun2() print ('func1 return is %s' %x)
#print('func1 return is {_x}'.format(_x=x)) 与%s输出相同
#func1 return is 0 print ('func2 return is {_y}'.format(_y=y))
#func2 return is None
1):定义函数和过程
#Author:http://www.cnblogs.com/Jame-mei
import time def logger():
#time_format='%Y-%m-%d %X' ===>%F %X
time_format='%F %X'
time_current=time.strftime(time_format)
with open('test_def','a+') as f:
f.write("%s end action\n" %time_current) #2.可扩展 def test1():
print ('in the test1')
logger() #1.代码重用,3.一致性等 def test2():
print ('in the test2')
logger() def test3():
print ('in the test3')
logger() test1()
test2()
test3()
2):函数的优点
现在老板让你写一个监控程序,监控服务器的系统状况,当cpu\memory\disk等指标的使用量超过阀值时即发邮件报警,你掏空了所有的知识量,写出了以下代码 while True:
if cpu利用率 > 90%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接 if 硬盘使用空间 > 90%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接 if 内存占用 > 80%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
上面的代码实现了功能,但即使是邻居老王也看出了端倪,老王亲切的摸了下你家儿子的脸蛋,说,你这个重复代码太多了,每次报警都要重写一段发邮件的代码,太low了,这样干存在2个问题: 代码重复过多,一个劲的copy and paste不符合高端程序员的气质
如果日后需要修改发邮件的这段代码,比如加入群发功能,那你就需要在所有用到这段代码的地方都修改一遍
你觉得老王说的对,你也不想写重复代码,但又不知道怎么搞,老王好像看出了你的心思,此时他抱起你儿子,笑着说,其实很简单,只需要把重复的代码提取出来,放在一个公共的地方,起个名字,以后谁想用这段代码,就通过这个名字调用就行了,如下 def 发送邮件(内容)
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接 while True: if cpu利用率 > 90%:
发送邮件('CPU报警') if 硬盘使用空间 > 90%:
发送邮件('硬盘报警') if 内存占用 > 80%:
发送邮件('内存报警') 你看着老王写的代码,气势恢宏、磅礴大气,代码里透露着一股内敛的傲气,心想,老王这个人真是不一般,突然对他的背景更感兴趣了,问老王,这些花式玩法你都是怎么知道的? 老王亲了一口你儿子,捋了捋不存在的胡子,淡淡的讲,“老夫,年少时,师从京西沙河淫魔银角大王 ”, 你一听“银角大王”这几个字,不由的娇躯一震,心想,真nb,怪不得代码写的这么6, 这“银角大王”当年在江湖上可是数得着的响当当的名字,只可惜后期纵欲过度,卒于公元2016年, 真是可惜了,只留下其哥哥孤守当年兄弟俩一起打下来的江山。 此时你看着的老王离开的身影,感觉你儿子跟他越来越像了。。。
3):函数的监控使用场景
六.函数式编程之参数详解(1-2)
1.函数的返回值详解
#Author:http://www.cnblogs.com/Jame-mei
#注释:函数的返回值的实例 def test1():
print ('in the test1')
#output:in the test1,下面的print就不输出了,因为遇到了return
return 0
#print ('in the test2') def test2():
print ('in the test2')
return test3() #把test3()函数作为返回值,也叫高阶函数! def test3():
print ('in the test3')
return 1,'hello',['alex','jame','oldboy'],{'alex':28,'oldboy':45,'jame':27},(2,3,4,5) def test4():
print ('in the test4') x=test1()
y=test2()
z=test3()
m=test4() print (x)
# print (y)
##(1, 'hello', ['alex', 'jame', 'oldboy'], {'alex': 28, 'oldboy': 45, 'jame': 27}, (2, 3, 4, 5)) print (z)#把字符串,数字,列表,字典,元祖都返回到一个元祖里。
#(1, 'hello', ['alex', 'jame', 'oldboy'], {'alex': 28, 'oldboy': 45, 'jame': 27}, (2, 3, 4, 5)) print (m) #没有return,则返回None 函数的返回值
总结:
1).不同返回值类型
*函数中没有return ,返回None。
*函数中 return 返回中只有1个变量时候,为返回值为object对象。
例如return (2),return [2],return 'hello'分别返回是2,[2],hello单个元素。
*函数中 return 返回中有多个变量时候,会把多个变量包含在一个元祖中,返回一个元祖!
例如 return (2,) ,返回的一个元祖(2,) return 2,'hello',(2,3,4) ,返回(2, 'hello', (2, 3, 4)) 元祖。
*函数中 return另外一个函数test3(),则返回只test3()的返回值
(2, 'hello', (2, 3, 4))
2).函数为什么要返回值?
为后面的程序调用,通过返回值的来进行判断,从而完成相关代码的逻辑。
2.形参和实参
形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量。
实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值。
形参和实参的区别:形参是虚拟的,不占用内存,形参变量只有在被调用的时候才分配内存。实参是一个变量,占用内存空间,数据传送单向,实参传给形参,形参不能传给实参!

1):默认参数
默认参数的特点:调用函数时候,默认参数非必须传(可以默认不写,也可以用位置参数重新赋值,也可以在最后用关键字重新赋值)
默认参数的用途:1.默认安装参数 2.默认端口参数等等预设的默认。
1默认参数
def stu_register01(name, age, country, course):
print("----注册学生信息------")
print("姓名:", name)
print("age:", age)
print("国籍:", country)
print("课程:", course) stu_register01("王山炮", 22, "CN", "python_devops")
stu_register01("张叫春", 21, "CN", "linux") output:
----注册学生信息------
姓名: 王山炮
age: 22
国籍: CN
课程: python_devops
----注册学生信息------
姓名: 张叫春
age: 21
国籍: CN
课程: linux #===================>改造为默认参数调用,默认参数必须放在最后,调用的时候也需要按照顺序。
def stu_register02(name, age,course,country="CN"):
print("----注册学生信息------")
print("姓名:", name)
print("age:", age)
print("国籍:", country)
print("课程:", course) stu_register02("张叫春", 21, "CN", "linux") #逻辑错误,默认值会被课程覆盖,顺序很重要。
stu_register02("金妍希", 21,"舞蹈") #不填写国籍,默认中国
stu_register02("Tom", 22,"python_devops",country="US") #修改默认国籍 output:
----注册学生信息------
姓名: 张叫春
age: 21
国籍: linux
课程: CN #这里会被覆盖!!
----注册学生信息------
姓名: 金妍希
age: 21
国籍: CN
课程: 舞蹈
----注册学生信息------
姓名: Tom
age: 22
国籍: US
课程: python_devops
2):位置参数 和 3)关键字参数
def test(x,y):
print (x)
print (y) #1.位置参数调用(与形参顺序一一对应!)
test(1,2) #2.关键字参数调用(与形参顺序无关,与关键字对应!)
test(y=3,x=4) #3.既有位置参数又有关键字参数,以位置参数优先!!
#3.1.关键字+位置参数(执行错误,第一个为关键字参数调用,第二个参数也应该是关键字才行!)
test(x=1,4) #3.2.位置参数+关键字混用
test(3,y=5) #(执行正确,第一个参数与位置相关,第二个必须要位置参数的值,或者关键参数y=...)
#test(3,x=4) #(执行错误,第一个参数与位置相关,关键参数应该顺序是y=...) #4.大于2个位置参数和关键参数的混用情况,关键参数不能写在位置参数前面的!
def test2(x,y,z):
print (x,y,z) #test2(3,y=2,6) #执行错误,关键字参数应该放在位置参数后面.
#test2(1,2,x=3) #执行错误,最后一个只能是z.
test2(1,2,z=3) #执行正确,最后一个参数对应为z
test2(1,z=3,y=2) #执行正确,后面两个都为关键字参数与顺序无关 #以上实例多练习体会其中的原理!不一一帖出来了。
4):参数组(非固定参数)
1): *args :把N个参数转换成元祖的方式,其中*args接受N个位置参数!
def test3(*args): #*args也可以自定义为 *jame
print(args) test3(1,2,3,4,5) #得到一个元祖(1,2,3,4,5) test3(*['a','b']) #相当于*args=*['a','b'],得到('a', 'b') test3(['x','y','z'],['','',''])
#相当于args=tunple(['x','y','z']),得到(['x', 'y', 'z'],)
#当为2个列表时候,得到, (['x','y','z'],['1', '2', '3']) #x位置参数不能放在 *args后面!!
def test4(x,*args):
print (x)
print (args) test4(1,'a','b',2,3,4)
'''
output:
1
('a', 'b', 2, 3, 4)
'''
2): **kwargs:把N个参数转换成字典的方式,其中**kwargs接受N个关键字参数!
def test4(**kwargs):
print (kwargs)
print(kwargs['name']) #输出字典的key-value!
print (kwargs['age'])
print (kwargs['sex']) #方式1
test4(name='jame',age='',sex='男',address='Shanghai')
'''
output:
输出一个字典
{'name': 'jame', 'age': '27', 'sex': '男', 'address': 'Shanghai'}
jame
27
男
''' #方式2
test4(**{'name':'tom','age':8,'sex':'女'}) #**{}==**kwargs
'''
output:
{'name': 'tom', 'age': 8}
tom
8
女
'''
3): **kwargs与位置参数混用,**kwargs放在位置参数的后面。
def test5(name,**kwargs):
print (name)
print (kwargs) #1.只填写位置参数name,**kwargs省略输出一个控的字典
test5('Jack')
'''
output:
Jack
{}
''' #2.位置参数和**kwargs都填写,注意age,sex不带''/"",不要跟字典搞混淆了。
test5('kater',age=18,sex='boy') '''
output:
kater
{'age': 18, 'sex': 'boy'} ''' #3.位置参数和**kwargs作为一个字典的方式和2.结果一样,感觉更加清晰! test5('Alice',**{'age':16,'sex':'girl'})
'''
output:
Alice
{'age': 16, 'sex': 'girl'}
'''
4):顺序参数,默认参数和**kwargs混用(优先级:顺序参数>默认参数>**kwargs关键字参数)
def test06(name,**kwargs,age=18): #报错,age=18默认参数不能放在最后,参数组(关键字参数)一定要往后放! def test06(name,age=18,**kwargs):
print(name,age,kwargs) test06('python',20,sex='unknow',address='US') #age为默认值可以不写,也可以写20,为了易读性最好写age=30等等
'''
output:
python
20
{'sex': 'unknow', 'address': 'US'}
''' #test06('python',20,sex='unknow',address='US',age=38)
# #前面如果给默认值赋值了,再**kwargs中指定关键字age则报错!!尽量不要这么写,容易歧义混乱! test06('python',sex='unknow',address='US',age=38) #不写age,在**kwargs后面参数中又指定了age=38,最后替代默认值20
'''
output:
python 38 {'sex': 'unknow', 'address': 'US'} '''
5):顺序参数,默认值参数,*args , **kwargs混用( 优先级: 顺序参数 > 默认值参数 > *args(接受位置参数) > **kwargs(接受关键字参数) )
def test07 (name,age=18,*args,**kwargs):
print (name)
print (age)
print (args)
print (kwargs) test07('dog',20,sex='unknow',address='doghome')
'''
输出:
dog
20
() #因为*args接受的是位置参数,不能是关键字参数,所以为空!
{'sex': 'unknow', 'address': 'doghome'}
''' test07('cat',9,1,2,3,sex='catgirl',adress='cathome')
'''
输出:
cat
9
(1, 2, 3)
{'sex': 'catgirl', 'adress': 'cathome'}
'''
七.函数式编程与函数不同
函数是Python内建支持的一种封装,我们通过把大段代码拆成函数,通过一层一层的函数调用,就可以把复杂任务分解成简单的任务,这种分解可以称之为面向过程的程序设计。函数就是面向过程的程序设计的基本单元。
函数式编程中的函数这个术语不是指计算机中的函数(实际上是Subroutine),而是指数学中的函数,即自变量的映射。也就是说一个函数的值仅决定于函数参数的值,不依赖其他状态。比如sqrt(x)函数计算x的平方根,只要x不变,不论什么时候调用,调用几次,值都是不变的。
Python对函数式编程提供部分支持。由于Python允许使用变量,因此,Python不是纯函数式编程语言。
简单说,"函数式编程"是一种"编程范式"(programming paradigm),也就是如何编写程序的方法论。
主要思想是把运算过程尽量写成一系列嵌套的函数调用。举例来说,现在有这样一个数学表达式:
(1 + 2) * 3 - 4
传统的过程式编程,可能这样写:
var a = 1 + 2;
var b = a * 3;
var c = b - 4;
函数式编程要求使用函数,我们可以把运算过程定义为不同的函数,然后写成下面这样:
var result = subtract(multiply(add(1,2), 3), 4);
这段代码再演进以下,可以变成这样
add(1,2).multiply(3).subtract(4)
这基本就是自然语言的表达了。再看下面的代码,大家应该一眼就能明白它的意思吧:
merge([1,2],[3,4]).sort().search("2")
因此,函数式编程的代码更容易理解。
要想学好函数式编程,不要玩py,玩Erlang,Haskell,
八.局部变量与全局变量的作用域(1-2)
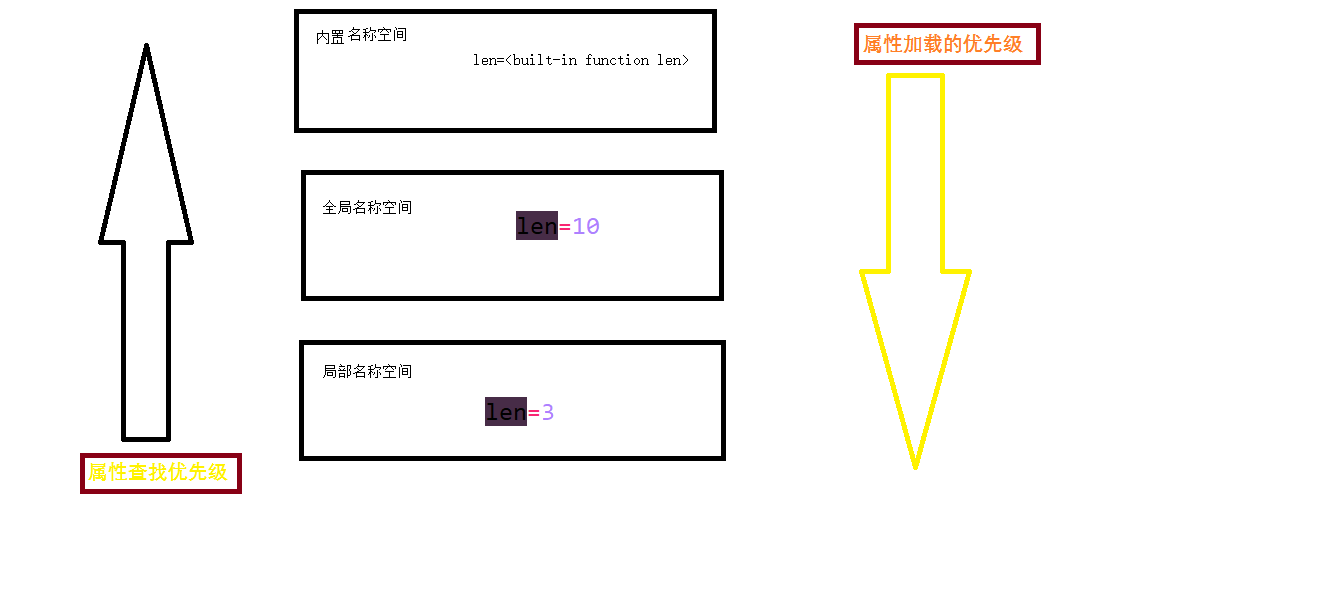
在子程序中定义的变量称为局部变量,在程序的一开始定义的变量称为全局变量。
#Author:http://www.cnblogs.com/Jame-mei school='oldboy linux' #定义全局变量 #局部变量和全局变量
def change_name(name):
global school #强制声明修改全局变量!
school='Mage linux'
print ('Before change',name,school)
name='Alex Li' #局部变量,作用域在函数内部生效。
print ('After change',name)
age=12 name='Jame'
change_name(name)
print (name) #依然是Jame,没有发生变化。
#print (age) #NameError: name 'age' is not defined,局部变量作用域只在函数change_name中。 print ('global school:',school) #全局变量由oldboy linux--->mage linux
实例2:编程规范 禁止在函数内部修改/定义 global 全局变量!
def change_name():
global name
name='Jame-mei' change_name()
print (name)
输出:
Jame-mei
实例3:编程规范 禁止修改global全局变量(单独的字符串和整数),列表、字典、集合、类等复杂数据类型可以修改。
names=['Alex','oldboy','mage']
def change_name():
names[0]='金角大王'
print (names) change_name() #全局变量 #字符串,整数不可以修改,其他的可以修改!
#列表,字典,集合,类等可以修改。
九.递归
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
函数递归调用,在调用一个函数的过程中又直接或间接地调用了自己称之为函数的递归调用
本质就是一个重复的过程,必须有两个明确的阶段
#1、回溯:一层一层地递归调用下去,没进入下一层问题的规模都应该有所减少
#2、递推:递归必须要有一个明确的结束条件,在满足该条件的情况下会终止递归,
往回一层一层地结束调用
递归特性:
1. 必须有一个明确的结束条件。
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少。
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
堆栈扫盲http://www.cnblogs.com/lln7777/archive/2012/03/14/2396164.html
实例1:栈内存溢出实例保护机制
def calc(n):
print (n)
return calc(n+1) calc(1) 输出:
991
992
993
994
995
996
997
998Traceback (most recent call last):
File "E:/pythonwork/s14/day03/def_digui.py", line 11, in <module>
calc(1)
File "E:/pythonwork/s14/day03/def_digui.py", line 7, in calc
return calc(n+1)
File "E:/pythonwork/s14/day03/def_digui.py", line 7, in calc
return calc(n+1)
File "E:/pythonwork/s14/day03/def_digui.py", line 7, in calc
return calc(n+1)
[Previous line repeated 993 more times]
File "E:/pythonwork/s14/day03/def_digui.py", line 6, in calc
print (n)
RecursionError: maximum recursion depth exceeded while calling a Python object
递归次数过多,保护耗尽资源停止
实例2:给递归一个结束条件
def calc(n):
print(n)
if int(n/2) >0:
return calc(int(n/2))
print (n) calc(10) 输出:
10
5
2
1
1 Process finished with exit code 0
4.递归 vs while 循环
递归只需要把控住结束或进入递归的条件即可,至于循环次数或者嵌套的层数无需考虑。
'''
# 直接
# import sys
# print(sys.getrecursionlimit())
# sys.setrecursionlimit(10000) # def foo(n):
# print('from foo',n)
# foo(n+1)
#
# foo(0) # 间接
# def bar():
# print('from bar')
# foo()
#
# def foo():
# print('from foo')
# bar()
#
# foo() # def foo():
# print('from foo')
# foo()
#
# foo() # age(5) = age(4) + 2
# age(4) = age(3) + 2
# age(3) = age(2) + 2
# age(2) = age(1) + 2
# age(1) = 18 # age(n) = age(n-1) + 2 #n > 1
# age(n) = 18 #n=1
# # def age(n):
# if n == 1:
# return 18
# return age(n-1) + 2
#
#
# print(age(5)) # l=[1,[2,[3,[4,[5,[6,[7,[8,[9,]]]]]]]]]
#
# def tell(l):
# for item in l:
# if type(item) is list:
# #item 是列表
# # 再次调用本身的逻辑,传入item
# tell(item)
# else:
# #item是单独的元素
# print(item)
#
# tell(l) # 数字列表,数字是从小到大排列的
nums=[3,11,13,15,23,27,43,51,72,81,93,101] # 算法:就是如何高效地解决某一个具体问题的方法
# l1=[3,11,13,15,23,27]
# l2=[23,27]
# l3=[23] def binary_search(nums,find_num):
print(nums)
if len(nums) == 0:
print('not exists')
return
mid_index=len(nums) // 2
if find_num > nums[mid_index]:
# in the right
nums=nums[mid_index+1:]
# 重复调用本身的逻辑,传入新的nums
binary_search(nums,find_num) elif find_num < nums[mid_index]:
# in the left
nums=nums[:mid_index]
# 重复调用本身的逻辑,传入新的nums
binary_search(nums,find_num)
else:
print('find it') binary_search(nums,94)
递归 vs while循环
十.高阶函数和匿名函数
1.高阶函数
变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。
def add(x,y,f):
return f(x) + f(y) res = add(3,-6,abs) print(res)
2.匿名函数
匿名函数就是不需要显式的指定函数
|
1
2
3
4
5
6
7
8
|
#这段代码def calc(n): return n**nprint(calc(10))#换成匿名函数calc = lambda n:n**nprint(calc(10)) |
你也许会说,用上这个东西没感觉有毛方便呀,如果是这么用,确实没毛线改进,不过匿名函数主要是和其它函数搭配使用的呢,如下
|
1
2
3
|
res = map(lambda x:x**2,[1,5,7,4,8])for i in res: print(i) |
输出:
1
25
49
16
64
3.匿名函数的实例操作
# 有名函数:可以通过名字重复使用
# def foo():
# print('from foo')
#
# foo() #匿名函数:临时用一次以后不会再用了
# def sum2(x,y):
# return x + y
# print(sum2) # sum2=lambda x,y:x + y
# print(sum2)
# res=sum2(1,2)
# print(res) # 定义匿名函数就是定义出了一个函数的内存
# res=(lambda x,y:x + y)(1,2)
# print(res) salaries={
'egon':300000,
'alex':100000000,
'wupeiqi':10000,
'yuanhao':2000
} # print(max([11,22,33,44]))
# print(max(salaries)) # def func(k):
# return salaries[k] # print(max(salaries,key=lambda x:salaries[x]))
# for k in salaries:
# res=func(k) # 将func的返回值当做比较依据 # print(min(salaries,key=lambda x:salaries[x])) # num=[3,1,4,9]
# l=sorted(num) # 默认从小到大排
# l=sorted(num,reverse=True) # 从大到小排
# print(l) # salaries={
# 'egon':300,
# 'alex':100000000,
# 'wupeiqi':10000,
# 'yuanhao':2000
# } # 按照薪资高低排序人名
# print(sorted(salaries,key=lambda x:salaries[x])) # 了解
# map,reduce,filter
# map:映射
names=['alex','lxx','wxx']
# chicken=map(lambda x:x+'_dsb',names)
# print(chicken)
# print(list(chicken)) # l=[name+'_dsb' for name in names]
# print(l) # filter:过滤
# names=['alex_teacher','lxx_teacher','wxx_teacher','egon_boss']
# res=filter(lambda x:x.endswith('teacher'),names) #filter会"for循环"names,取出来每一个名字,然后传给指定的函数,如果函数的返回值为True,则留下该名字
# for item in res:
# print(item) # l=(name for name in names if name.endswith('teacher'))
# print(list(l)) # reduce:合并
from functools import reduce
l=['a','b','c','d','e'] # res=reduce(lambda x,y:x+y,l,'AAA') #
#'AAA' + 'a'='AAAa'
#'AAAa' + 'b' = 'AAAab'
#'AAAab' + 'c' # print(res) # res=reduce(lambda x,y:x+y,l) #'a','b'
# print(res) # res=reduce(lambda x,y:x+y,range(0,101))
# print(res)
十一.作业
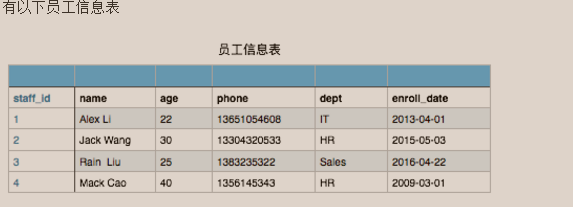
当然此表你在文件存储时可以这样表示
|
1
|
1,Alex Li,22,13651054608,IT,2013-04-01 |
现需要对这个员工信息文件,实现增删改查操作
- 可进行模糊查询,语法至少支持下面3种:
- select name,age from staff_table where age > 22
- select * from staff_table where dept = "IT"
- select * from staff_table where enroll_date like "2013"
- 查到的信息,打印后,最后面还要显示查到的条数
- 可创建新员工纪录,以phone做唯一键,staff_id需自增
- 可删除指定员工信息纪录,输入员工id,即可删除
- 可修改员工信息,语法如下:
- UPDATE staff_table SET dept="Market" WHERE where dept = "IT"
注意:以上需求,要充分使用函数,请尽你的最大限度来减少重复代码!
代码地址:https://gitee.com/meijinmeng/Sqltest.git
Python基础-week03 集合 , 文件操作 和 函数详解的更多相关文章
- Python 基础之集合相关操作与函数和字典相关函数
一:集合相关操作与相关函数 1.集合相关操作(交叉并补) (1)intersection() 交集 set1 = {"one","two","thre ...
- Python基础7:文件操作
[ 文件操作] 1 对文件操作流程 打开文件,得到文件句柄并赋值给一个变量 通过句柄对文件进行操作 关闭文件 现有文件如下: 昨夜寒蛩不住鸣. 惊回千里梦,已三更. 起来独自绕阶行. 人悄悄,帘外月胧 ...
- python基础3之文件操作、字符编码解码、函数介绍
内容概要: 一.文件操作 二.字符编码解码 三.函数介绍 一.文件操作 文件操作流程: 打开文件,得到文件句柄并赋值给一个变量 通过句柄对文件进行操作 关闭文件 基本操作: #/usr/bin/env ...
- python基础知识-day7(文件操作)
1.文件IO操作: 1)操作文件使用的函数是open() 2)操作文件的模式: a.r:读取文件 b.w:往文件里边写内容(先删除文件里边已有的内容) c.a:是追加(在文件基础上写入新的内容) d. ...
- python基础学习笔记——文件操作
文件操作 初始文件操作 使用Python来读写文件是非常简单的操作,我们使用open()函数来打开一个文件,获取到文件句柄,然后通过文件句柄就可以进行各种各样的操作了 根据打开方式的不同能够执行的操作 ...
- python基础dict,集合,文件
字典是一种key:value的数据类型dict1{ 'stud1':'孙礼昭', 'stud2':'slz', 'stud3':'sunlizhao',}dict是无序的,key是唯一的 天生去重增 ...
- Python基础知识(八)----文件操作
文件操作 一丶文件操作初识 ###f=open('文件名','模式',编码): #open() # 调用操作系统打开文件 #mode #对文件的操作方式 #encoding # 文件的编码格式 存储编 ...
- python基础八之文件操作
python的文件操作 1,打开文件 编码方式要和文件的编码方式相同! #open('路径','打开方式','指定编码方式') f = open(r'E:\pycharm\学习\day8\test', ...
- Python基础之 一 文件操作
文件操作 流程: 1:打开文件,得到文件句柄并赋值给一个变量 2:通过句柄对文件进行操作 3:关闭文件 模式解释 r(读) , w(写) ,a(附加)r+(读写的读), w+(读写的写),a+(读附加 ...
随机推荐
- uvm_analysis_port——TLM1事务级建模方法(二)
UVM中的TLM1端口,第一类是用于uvm_driver 和uvm_sequencer连接端口,第二类是用于其他component之间连接的端口,如uvm_monitor和uvm_scoreboard ...
- CentOS-7系统安装配置
CentOS 7 系统安装配置 服务器相关设置如下: 操作系统:CentOS 7.3.1611 IP地址:192.168.3.30 网关:192.168.3.1 DNS:8.8.8.8 8.8.4.4 ...
- window下安装scala搭载Intellij IDE
最近由于公司业务需求,要用到scala,编写还是windows下较好,linux下运行比较靠谱,废话少说,直接上步骤! 1.首先安装java环境 jdk下载地址:http://www.oracle.c ...
- springMvc-对servletApi的支持以及把后台对象以json方式传到前台
1.对servletApi的支持:request.response以及session.cookie的支持 2.把后台代码以json格式向前台输出: 代码: package com.java.contr ...
- 使用SAP云平台的destination消费Internet上的OData service
通过SAP云平台上的destination我们可以消费Internet上的OData service或者其他通过HTTP方式暴露出来的服务. 创建一个新的destination: 维护如下属性: 点击 ...
- IOS 绘制条纹背景
@interface NJViewController () @property (weak, nonatomic) IBOutlet UITextView *contentView; - (IBAc ...
- tensorflow构建CNN模型时的常用接口函数
(1)tf.nn.max_pool()函数 解释: tf.nn.max_pool(value, ksize, strides, padding, data_format='NHWC', name=No ...
- codeforces 1114C
题目连接 : https://codeforces.com/contest/1114/problem/C 题目大意:给一个整数n(1e18>=n>=0),和一个整数k(1e12>=k ...
- matlab中size函数总结
size(A)函数是用来求矩阵的大小的. 比如说一个A是一个3×4的二维矩阵: 1.size(A) %直接显示出A大小 输出:ans= 3 4 2.s=size(A)%返回一个行向量s,s的第一个元素 ...
- 梁勇(Danniel Liang) java教材例题:java程序购买额按税率求营业税 java中数值保留2位小数的方法
package com.swift; import java.util.Scanner; public class PurchaseTaxDecimalsTwo { public static voi ...