Java Object Model(一)
Java作为OOP语言,抽象性不言而喻。如果需要深入了解Java语言的实现机制,则不得不对Java语言中基础的概念有清晰的了解。今天是我在cnblog上写博客的第一天,希望今天的博客可以是我成为未来"大牛"跨出的第一步。
面向对象语言中,对象概念其实挺抽象的,对于初学者甚至有开发经验的同志来说都不太容易弄明白。最近看到这篇牛人写的文章,觉得蛮受益的,和大家共同分享吧。翻译有些拙劣,"大牛"请忽略我直接看原文,嘻嘻~。
原文出处链接:http://www.programcreek.com/2011/11/what-do-java-objects-look-like-in-memory/
We know functions are implemented in memory as a stack of activation records. And we know Java methods are implemented as a stack of frames in JVM Stack and Java objects are allocated in Heap.
函数在内存中通过一堆"活动记录"(activation record,活动记录也叫栈帧)实现。我们也知道Java方法在虚拟机栈中通过一堆"栈帧"(stack frame)实现,Java对象在"堆"(Heap)中分配内存空间。
COMMENT1:
1)Java中funtion和procedure统称为method。一般来说function和procedure是有区别的(当然很多编程书上是混用的,我也是无语==!)
funtion -- 无返回值(void或构造函数那样返回值类型都没写的)的method; procedure -- 有返回值的method
2)栈帧(stack frame)也称活动记录(activation record)。method在被调用(called)时会将方法区的方法压入栈帧,栈帧中保存有局部变量,返回值类型等信息。具体内容本文不深究。
How do Java objects look like in heap? Once an object is laid out in memory, it's just a series of bytes.
Java对象在"堆"中到底长得啥样呢?一旦对象被放到内存中,此时它仅仅就是一系列的字节。
Then how do we know where to look to find a particular field? Keep an internal table inside the compiler containing the offsets of each field.
那么我们是如何知道到哪里去查看、寻找这样一个特别的字段(field)的呢?在编译器内部保存有一张包含每一个字段偏移量的表。
COMMENT2:
1)field有的译作"域"、"字段",其实都是一个意思。都是指类的成员变量(包括static成员变量,只不过static存放在方法区,属于类,所有类对象共享)
2)对象成员变量自动寻址:编译器内部会保存一张虚拟表(Virtual Table or called Vtable),包括每个对象成员变量相对于对象空间首地址(第一个成员变量)的地址偏移量,这
样就可以轻松地访问对象的成员变量了。
Here is an example of an object layout for class "Base"(B). This class does not have any method, how methods are laid out in memory is in the nextsection.
举个Base类实例对象的例子。这个类没有任何的方法,它的方法如何在内存中被安排放置将在下一部分中解释。

If we have another class "Derived"(D) extending this "Base" class. The memory layout would look like the following:
如果我们有另一个Derived类继承了Base类。内存布局情况如下:

Child object has the same memory layout as parent objects, except that it needs more space to place the newly added fields. The benefit of this layout is that a pointer of type B pointing at a D object still sees the B object at the beginning. Therefore, operations done on a D object through the B reference guaranteed to be safe, and there is no need to check what B points at dynamically.
子类对象除了需要更多空间去放置新增的字段外,其余的和父类对象有相同类型的内存布局。这样布局的好处就是:当有一个Base类引用指向Derived类对象时,引用仍然能访问内存区域开始的Base类对象。因此,所有通过Base类引用对Derived类对象上的操作是确保安全的,也就没有必要动态地去检查Base类所指向的内容。
COMMENT3:
1) pointer和reference
其实有时我在看Java英文文献的时候也是傻傻分不清到底在说那个。如果是C++那pointer和reference(引用和指针表面上是两码事,引用在底层也是通过指针实现的)明显就是两个概念。而在Java引用和C++引用表面上根本就是不同的概念,Java中的引用更像C++的指针变量,只不过是阉割版的C++指针变量(Java引用和C++的type * const ptr等价,即ptr的值不能改变,但是ptr指向的内容可以改变)。
2) 向上造型(也称"上溯造型")语法现象
The benefit of this layout is that a pointer of type B pointing at a D object still sees the B object at the beginning.
B类(父类)的引用在指向D类对象后,仍然能够访问B对象。still sees the B object at the beginning 就说明了Object B 和Object D 开头部分内存是相同的,Object D开头的内存可以认为就是Object B。
通过上述的分析,我们看下面一道笔试题:
import static java.lang.System.out;
class SupClass {
int x = 10;
void show() {
System.out.println("SupClass");
}
}
class SubClass extends SupClass{
int x = 20;
void show() {
System.out.println("SubClass");
}
}
public class Test {
public static void main(String[] args) {
SupClass sup = new SubClass();
out.println(sup.x);
}
}
SupClass sup = new SubClass(); 父类(SupClass)引用指向子类(SubClass)对象,由于父类引用只能访问子类中从父类继承的成分,因此x = 20是不能够被sup访问的。
答案就是10,而不是20。
3)为什么父类引用可以指向子类对象而编译器不报错?
Therefore, operations done on a D object through the B reference guaranteed to be safe, and there is no need to check what B points at dynamically.
因此,所有通过Base类引用堆D对象的操作确保是安全的,不需要动态地检查Base类到底引用了啥。
这句话其实可以很好地解释为什么这种操作编译器不报错。其实仔细理解起来是这么回事,由于子类从父类继承的那部分结构与父类相同(通过super关键字,此时子类对象中多了父类的那部分内容)。父类引用可以通过子类的对象来访问子类从父类继承来的那部分,因而编译器不会报错。而且这种访问形式是安全的,既不能改变父类的内容,也不会去访问子类多出来的那部分。
4)深入堆内存
堆内存是什么?堆内存就是物理机上的一段虚拟内存(Virtual Memory)。哪啥叫虚拟内存?虚拟内存实际是硬盘的东西,只是用部分硬盘的储存容量来作为JVM的内存,显然这个内存是假的,和物理机的内存是两码事。当然由于JVM(Java Virtual Machine)就是一个虚拟计算机,因此不光是堆,其实JVM的所有内存(包括Java栈等)都是物理机中的虚拟内存,即实际硬盘中的储存空间。
JVM堆内存实际上是链表(Linked List)这种数据结构维护的,因此堆内存中的连续内存往往是指逻辑连续,物理堆内存上是不连续。
Following the same logic, the method can be put at the beginning of the objects.
根据相同的逻辑,方法可以被放在对象的开头。

However, this
approach is not efficient. If a class has many methods(e.g. M), then each
object must have O(M) pointers set. In addition, each object needs to have
space for O(M) pointers. Those make creating objects slower and objects bigger.
然而,此方法效率并不高。如果一个类有很多的方法,那么每个对象必须有一个指针集合(就是指很多指针变量而已)。除此之外,每个对象需要有空间去储存这些指针变量。这些会导致创建对象变得更慢,同时对象空间变得更大。
COMMENT4:
1)理论上我们在创建类对象时将方法写在对象内存的开头,但是相比有限的对象成员变量来说,对象的方法可能有很多,如果每次创建一个对象就需要许多指向方法的指针,那么无疑堆内存将会变得很大,同时在创建对象时会变得很慢(对象创建是从首地址开始一个一个创建的)。
2)对象不包括方法,而是包括了指向方法的指针变量。方法储存在方法区中。在这种模型(JVM不使用这种模型)中,对象在调用非静态方法时,堆中的指针变量在需要的时候通过堆中的指针变量访问方法区中相应的方法,并将其放入Java栈中,对应一个栈帧。
The optimization
approach is to create a virtual function table (or vtable) which is an array of
pointers to the member function implementations for a particular class. Create
a single instance of the vtable for each class and make each object store a
pointer to the vtable.
优化方法是创建一个特定类虚函数表,这个虚函数表是指向成员函数实现的指针数组。为每个类创建虚表的单一实例,同时让每个对象储存一个指向虚函数表的指针。
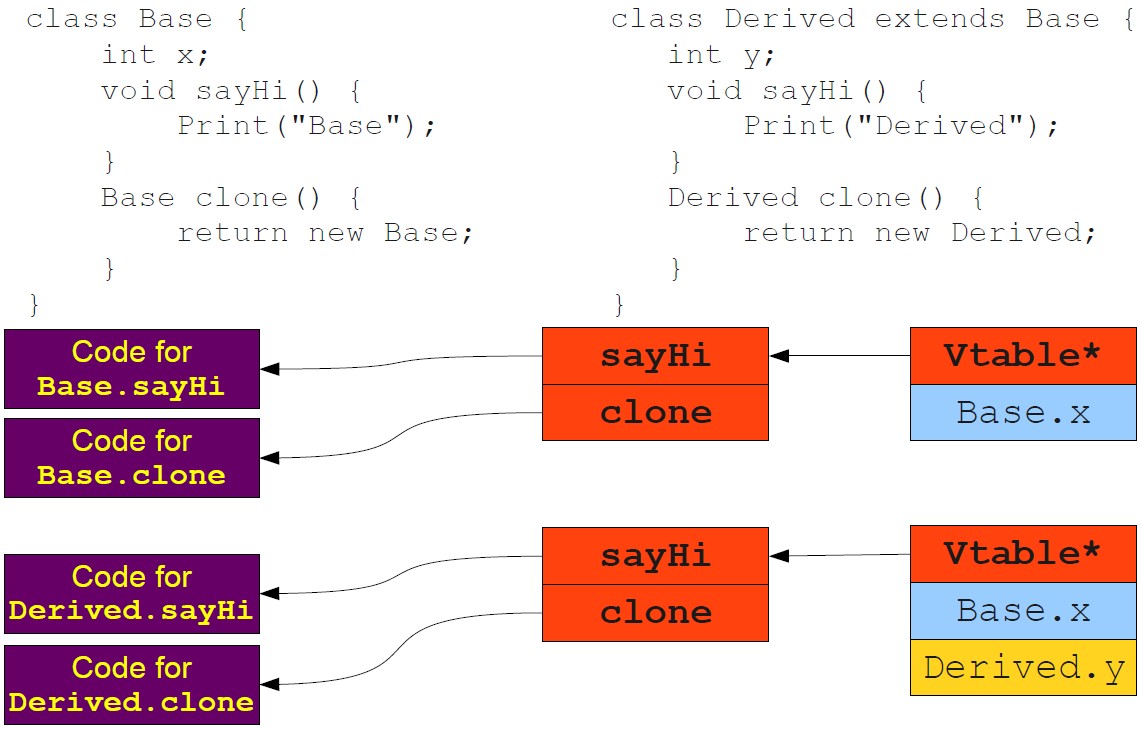
COMMENT5:
1)JVM实际使用就是上面第二种模型(方法区在存放方法的同时时,也会存放一份类虚函数表,虚函数表放方法代码)。
Code for Base.sayHi指的是方法区中的方法代码信息;sayHi指的是堆中创建的指向方法区方法的方法指针;Vtable*指的是方法指针数组集合,用于创建动态指针数组(这些动态指针指向栈中的具体栈帧),被所有类对象共享(储存在方法区)。
2)对象可以访问堆中常量池内容,说明啥?是不是说明堆中还存在一个指针指向常量池。而且访问常量池的内容仅限某个类的内容。因此可以看出,实际上堆中对象还存有.class句柄指针。当然这个是我猜的,没有啥依据。
3)我想,看到这你我都明白啥是真正意义上的对象了。对象=.class信息句柄指针(能指向方法区常量池)+虚函数表指针变量(指向方法区的方法)+对象成员变量(数据)
4)类的方法储存在方法区,被所有类的对象所共享。具体对象的虚函数表内的方法指针被创建时,会将方法区中的方法放入Java栈,这个具体的指针和栈帧绑定。这样每个类对象通过虚函数表解决了必须调用众多方法的问题,创建对象速度比第一种模型快,对象所需的堆内存空间也比第一种要小。
通过上面部分讨论,可以解决以下这几道面试题:
public class TestClass {
public static void main(String[] args) {
SupClass sup = new SubClass();
sup.show1();
sup.show2();
}
}
class SupClass {
int x = 10;
public void show1() {
System.out.println("SupClass");
}
public void show2() {
System.out.println(x);
}
}
class SubClass extends SupClass{
int x = 20;
public void show1() {
System.out.println("SubClass");
}
public void show2() {
System.out.println(x);
}
}
试题的答案是:
SubClass
20
分析:本题考查的是完全是方法的覆盖(重写override)知识点。
1)在同一个类中,如果有两个方法的方法签名相同,编译器会报错。从计算机思维来说,机器处理的必须是明确的东西,不能是不确定量,如果出现不确定量,机器会报错,因为你把它搞晕了,它不知道该选择那个。
2)在父子类关系这两个类中,子类方法签名和父类方法签名相同,属于方法覆盖。那么为什么父类引用访问子类覆盖父类的方法时只能访问子类重写版本而不能是父类版本,而且也不会出现问题?其实,在方法区中子类并没有包含父类的方法(包括构造方法),而是拥有各自代码中所写的方法。使用父类引用指向子类对象时,如果子类覆盖父类的方法,那么就会在子类方法区寻找这个方法,找到就将其放入栈中;如果找不到,由于有extends关键字,此时就会通过super指针指向父类方法区,在父类方法区寻找相应的方法。
3)父类哪些东西不能被子类继承?
Java继承机制中,超类的方法(包括构造方法)不能被派生类继承,而是通过调用机制实现。具体的内容会在后续的文章中讨论。
public class TestClass {
public static void main(String[] args) {
SupClass sup = new SubClass();
sup.show1();
sup.show2();
}
}
class SupClass {
int x = 10;
public void show1() {
System.out.println("SupClass");
}
public void show2() {
System.out.println(x);
}
}
class SubClass extends SupClass{
int x = 20;
public void show1() {
System.out.println("SubClass");
}
public void show2(int a) {
System.out.println(x);
}
}
试题的答案是:
SubClass
10
分析:本题是上题的变式,SupClass和SubClass都有2个方法,但是在子类中父类show1()被覆盖,而父类的show2()方法未被覆盖。在方法区中父类方法是父类方法,子类方法是子类方法,都是实际写的方法中哪些代码,子类方法区空间中并没有父类的方法。但在具体对象创建时,子类的虚函数表却拥有指向父类方法区方法的指针。当子类重写父类方法后,这张表其实是更新的,也就是说表中父类的方法指针被子类方法指针覆盖了。
This is the optimized approach.
上面的就是优化后的方法。
References:
1. Stanford Compilers Lectures
2. JVM
学习感悟:
1)如果国内的博客没有你需要的答案,或者不满意,最好能够去国外的社区走走看看,当然Java官方文档是一切的基础吧。
2)一些专业名词确实需要积累,比如activation record我一开始没有翻译准确,后来是通过浏览器查询才翻译准确的。
3)不要怕说错,就像可能我这篇文章有许多错的。重在和别人交流,在交流中提升自己吧。
4)有些概念可能没有表述清晰,需要进一步加强自己的语言表述能力。毕竟任何东西,自己懂和让别人懂事两码事,两种能力。
Java Object Model(一)的更多相关文章
- JAVA读取XML,JAVA读取XML文档,JAVA解析XML文档,JAVA与XML,XML文档解析(Document Object Model, DOM)
使用Document Object Model, DOM解析XML文档 也可参考我的新浪博客:http://blog.sina.com.cn/s/blog_43ac5543010190w3.html ...
- Page Object Model (Selenium, Python)
时间 2015-06-15 00:11:56 Qxf2 blog 原文 http://qxf2.com/blog/page-object-model-selenium-python/ 主题 Sel ...
- selenium page object model
Page Object Model (POM) & Page Factory in Selenium: Ultimate Guide 来源:http://www.guru99.com/page ...
- POM(project Object Model) Maven包管理依赖 pom.xml文件
什么是POM POM全称为“Project Object Model”,意思是工程对象模型.Maven工程使用pom.xml来指定工程配置信息,和其他文本信息.该配置文件以xml为格式,使用xml语法 ...
- BOM(Browser Object Model) 浏览器对象模型
JavaScript 实现是由 3 个部分组成:核心(ECMAScript),文档对象模型(DOM),浏览器对象模型(BOM) BOM(Browser Object Model) 浏览器对象模型BOM ...
- 有关BOM(Browser Object Model)的内容
包括: BOM概述 BOM模型 Window对象(常用属性和方法,窗口的打开,窗口的关闭,模态对话框,定时器) Navigator对象(遍历navigator对象的所有属性,Navigator 对象集 ...
- Selenium的PO模式(Page Object Model)[python版]
Page Object Model 简称POM 普通的测试用例代码: .... #测试用例 def test_login_mail(self): driver = self.driver driv ...
- 在C#开发中如何使用Client Object Model客户端代码获得SharePoint 网站、列表的权限情况
自从人类学会了使用火,烤制的方式替代了人类的消化系统部分功能,从此人类的消化系统更加简单,加速了人脑的进化:自从SharePoint 2010开始有了Client Side Object Model ...
- Selenium的PO模式(Page Object Model)|(Selenium Webdriver For Python)
研究Selenium + python 自动化测试有近两个月了,不能说非常熟练,起码对selenium自动化的执行有了深入的认识. 从最初无结构的代码,到类的使用,方法封装,从原始函数 ...
随机推荐
- 03_通过OpenHelper获取SqliteDatabase对象
MyOpenHelper openHelper = new MyOpenHelper(this); 类似于java的File file = new File();只是声明这个东西,但是文件还并没有真正 ...
- [poj1236]Network of Schools(targin缩点SCC)
题意:有N个学校,从每个学校都能从一个单向网络到另外一个学校.1:初始至少需要向多少个学校发放软件,使得网络内所有的学校最终都能得到软件.2:至少需要添加几条边,使任意向一个学校发放软件后,经过若干次 ...
- 使用BIND安装智能DNS服务器(三)---添加view和acl配置
智能DNS的配置主要修改named.conf文件,利用view和acl来实现. acl文件内容,这里只列出一部分,具体详细的可以参考这个网址 纯真IP库,给出了十分详细的IP地址,下载安装后,打开软件 ...
- 2.6用tr进行转换
tr可以对来自标准输入的内容进行字符替换.字符删除以及重复字符压缩.它可以将一组字符变成另一组字符,因而通常也被称为转换命令. 1.tr只能通过stdin(标准输入),而无法通过命令行参数来接受输入. ...
- 21.运行Consent Page
服务端把这个地方修改为true,需要设置 运行测试.服务端和客户端都运行起来 我们使用的用户是在这里配置的 服务端修改ConsentController 再次运行,但是页面都是乱码 openId和pr ...
- eclipse里的Maven插件安装
插件安装 打开Eclipse的Help->Install New Software,如下图所示: 2. 选择“Add..”按钮,又会弹出如下对话框: 这个对话框就是用于添加一个插件地址的.在“N ...
- 732. My Calendar III (prev)
Implement a MyCalendarThree class to store your events. A new event can always be added. Your class ...
- php UTF8 转字节数组,后使用 MD5 计算摘要
Hex.encodeHexString(md5.digest);按 UTF8 转字节数组,后使用 MD5 计算摘要,得到 16 字节数组,使用 Hex 转为长度为 32 的字符串,保持小写 bin2h ...
- (三)siege的使用
学习: ELK——http://dockone.io/article/3655 docker——http://www.testclass.net/docker/ Android Monkey压力测试— ...
- PJzhang:安全小课堂-安全软件为什么很重要,看这里!
猫宁!!! 参考链接: http://www.360.cn/webzhuanti/mianyigongju.html https://www.freebuf.com/fevents/204100.ht ...