大数据之路- Hadoop环境搭建(Linux)
前期部署
1.JDK
2.上传HADOOP安装包
2.1官网:http://hadoop.apache.org/
2.2下载hadoop-2.6.1的这个tar.gz文件,官网:
https://archive.apache.org/dist/hadoop/common/hadoop-2.6.1/
下载成功后,把这个tar.gz包上传到服务器上,命令:
通过SecureCRT软件alt+p打开SFTP,然后把这个文件上传
上传成后,解压
tar -xvzf hadoop-2.6..tar.gz
然后把解压后的文件移动到/usr下,改名为hadoop
命令:
mv hadoop-2.6. /usr/hadoop

然后开始把hadoop的命令加到环境变量里面去
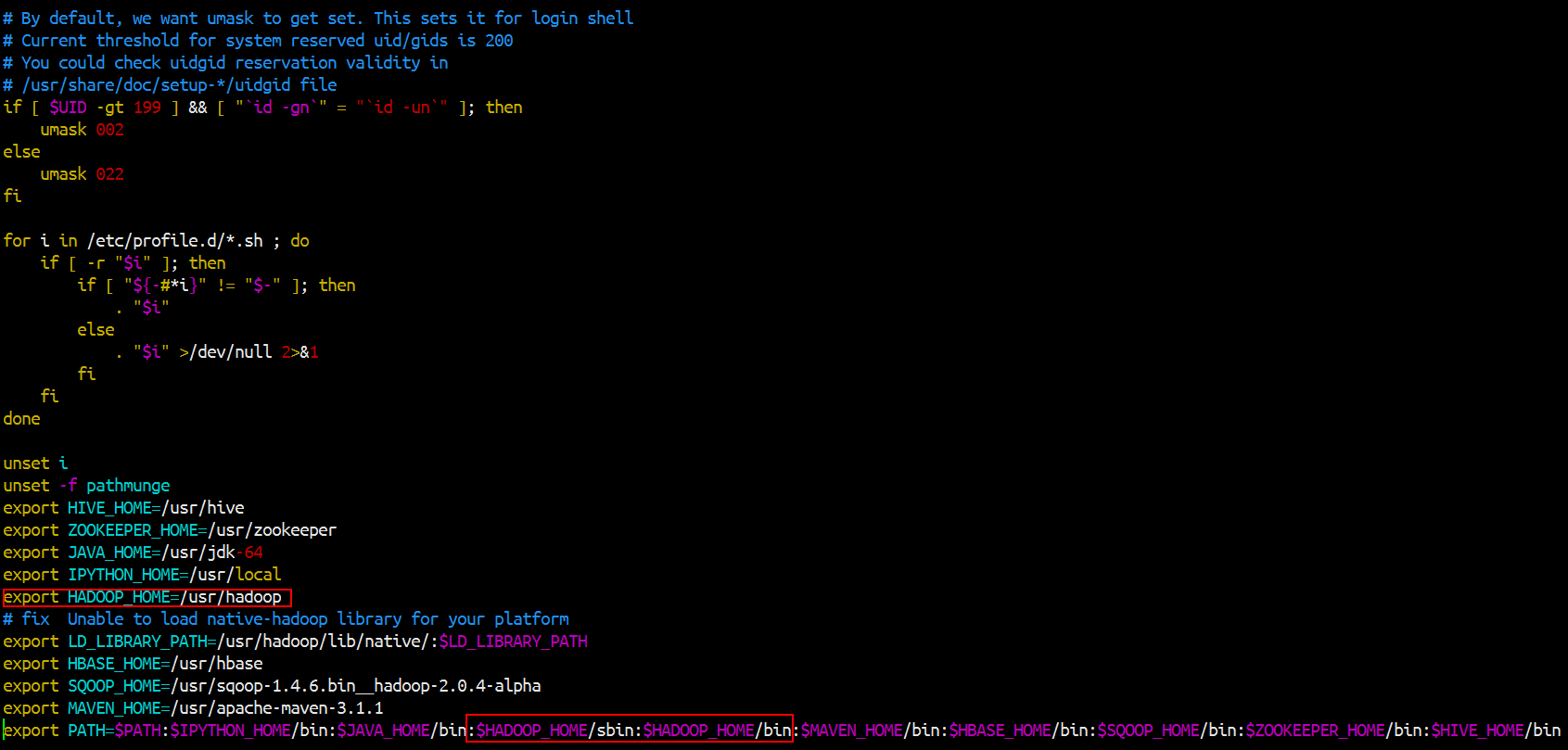
然后记得source一下
然后再修改配置文件,配置文件查看查看官网:
http://hadoop.apache.org/docs/r2.6.5/hadoop-project-dist/hadoop-common/SingleCluster.html
最简化配置如下:(在/usr/hadoop/etc/hadoop)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdp-node-01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name> //指定进程工作目录,数据存放目录
<value>/home/HADOOP/apps/hadoop-2.6./tmp</value>
</property>
//设置保留副本的数量,即备份的数量,默认是3。客户端把文件交给fds之后,fds保留的副本数量
<property>
<name>dfs.replication</name>
<value></value>
</property>
vim mapre-site.xml
mapreduce要放在一个资源调度平台上面跑,所以需要指定资源调度平台yarn,默认是local,不是在集群上运行
192.168.1.88 srv01
192.168.1.89 srv02
192.168.1.90 srv03
scp /etc/profile srv02:/etc/ //记得到srv02去source它的profile文件
scp /etc/profile srv03:/etc/ //记得到srv02去source它的profile文件
scp -R /usr/hadoop srv02:/usr/hadoop
scp -R /usr/hadoop srv03:/usr/hadoop
hadoop格式化是为了生成fsimage文件。
hdfs namenode -format

可以在浏览器上看到hadoop集群状态
namenode的ip加上50070端口
http://192.168.1.88:50070/
配置HDFS垃圾回收
fs.trash.interval
描述:检查点被删除的分钟数。如果为零,垃圾功能将被禁用。可以在服务器和客户端上配置此选项。如果垃圾桶被禁用服务器端,则客户端配置被检查。如果在服务器端启用垃圾箱,则使用服务器上配置的值,并忽略客户端配置值。
例子:7天后自动清理
<property>
<name>fs.trash.interval</name>
<value>7 * 24 * 60</value>
</property>
NameNode启动过程详解
namenode的数据存放在两个地方,一个是内存,一个是磁盘(edits,fsimage)
第一次启动HDFS
1.format : 格式化hdfs
2.make image : 生成image文件
3.start NameNode:read fsimage
4.start Datenode : datanode 向 NameNdoe 注册,汇报 block report ,
5.create dir /user/xxx/temp :写入edits文件
6.put files /user/xxx/tmp(*=site,xml) :写入edites文件
7.delete file /user/xxx/tmp/(core-site.xml):写入edits文件
对dfs的操作都会记录到edits里面
第二次启动hdfs:
1.启动NameNode,读取fsimage里面的镜像文件,读取edits文件,因为edits记录着上一次hdfs的操作,写入一个新的fsimage,创建一个新的edits记录操作
2.start Datenode : datanode 向 NameNdoe 注册,汇报 block report ,
3.create dir /user/xxx/temp :写入edits文件
4.put files /user/xxx/tmp(*=site,xml) :写入edites文件
5.delete file /user/xxx/tmp/(core-site.xml):写入edits文件
6.Secondly NameNode定期将edits文件和fsimage文件合并成一个新的fsimage文件替换掉NameNode上面的fsimage
另:手动编译hadoop记得要联网,因为它是用maven管理的,很多依赖需要下载
大数据之路- Hadoop环境搭建(Linux)的更多相关文章
- 大数据学习之Hadoop环境搭建
一.Hadoop的优势 1)高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理. 2)高扩展性:在集群间分配任务数据,可方便的 ...
- 《OD大数据实战》Hive环境搭建
一.搭建hadoop环境 <OD大数据实战>hadoop伪分布式环境搭建 二.Hive环境搭建 1. 准备安装文件 下载地址: http://archive.cloudera.com/cd ...
- 《OD大数据实战》Hue环境搭建
官网: http://archive.cloudera.com/cdh5/cdh/5/hue-3.7.0-cdh5.3.6/ 一.Hue环境搭建 1. 下载 http://archive.cloude ...
- 《OD大数据实战》Oozie环境搭建
一.Oozie环境搭建 1. 下载oozie-4.0.0-cdh5.3.6.tar.gz 下载地址:http://archive.cloudera.com/cdh5/cdh/5/ 2. 解压 tar ...
- 《OD大数据实战》MongoDB环境搭建
一.MongonDB环境搭建 1. 下载 https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.0.6.tgz 2. 解压 tar -zxvf ...
- 《OD大数据实战》HBase环境搭建
一.环境搭建 1. 下载 hbase-0.98.6-cdh5.3.6.tar.gz 2. 解压 tar -zxvf hbase-0.98.6-cdh5.3.6.tar.gz -C /opt/modul ...
- 《OD大数据实战》Storm环境搭建
一.环境搭建 1. 下载 http://www.apache.org/dyn/closer.lua/storm/apache-storm-0.9.6/apache-storm-0.9.6.tar.gz ...
- 《OD大数据实战》Flume环境搭建
一.CentOS 6.4安装Nginx http://shiyanjun.cn/archives/72.html 二.安装Flume 1. 下载flume-ng-1.5.0-cdh5.3.6.tar. ...
- Linux集群搭建与Hadoop环境搭建
今天是8月19日,距离开学还有15天,假期作业完成还是遥遥无期,看来开学之前的恶补是躲不过了 今天总结一下在Linux环境下安装Hadoop的过程,首先是对Linux环境的配置,设置主机名称,网络设置 ...
随机推荐
- 服务器性能之CPU
有时我们会发现开发的应用在CPU核数一样的虚拟服务器上性能表现出较大的差异,这是为什么呢?上次有童鞋问到我这样一个问题,所以我根据自己的理解给大家简说下! CPU生产商为了提高CPU的性能,通常做法是 ...
- 拿wordpress站的一个小技巧
记得09年时wp爆过一个重置管理口令的漏洞, 现在用法差不多, 也是我刚刚发现, 网上也没找到有讲述关于这个的. 前提:是在有注入点(注入点的话可以通过寻找插件漏洞获得.), 密码解不开, 无法out ...
- 单选复选框的js代码取值
单选框 复选框选中后的js代码处理 <script type="text/javascript"> function check(){ document.getElem ...
- hadoop 使用和javaAPI
hadoop的安装,见http://www.powerxing.com/install-hadoop/,简略版教程见http://www.powerxing.com/install-hadoop-si ...
- Mysql processlist命令
Mysql processlist命令 mysqladmin -uroot -proot processlist mysql 查看当前连接数 命令: show processlist; 如果是ro ...
- Oracle Sequence用plsql修改
在plsql中,打开Objects窗口 找Sequences文件夹>你需要修改的Sequence 选中你需要修改的sequence,右键edit(编辑) OK!
- 在EA中用ER图生成数据库
ER图 E-R图也称实体-联系图(Entity Relationship Diagram).提供了表示实体类型.属性和联系的方法.用来描写叙述现实世界的概念模型. 实体就是看的见摸得着或者能被人感知接 ...
- cocos2d-x-3.1 国际化strings.xml解决乱码问题 (coco2d-x 学习笔记四)
今天写程序的时候发现输出文字乱码,尽管在实际开发中把字符串写在代码里是不好的做法.可是有时候也是为了方便,遇到此问题第一时间在脑子里面联想到android下的strings.xml来做国际化.本文就仅 ...
- 记录下关于ejabberd及XMPP的官网链接
ejabberd中文翻译 ——http://wiki.jabbercn.org/Ejabberd2:安装和操作指南 XMPP中文翻译: http://wiki.jabbercn.org/XEP-012 ...
- 16 nginx实现负载均衡
一:nginx实现负载均衡-----------------原理-------------------------- (1) 反向代理后端如果有多台服务器,自然可形成负载均衡,但proxy_pass如 ...