学习笔记02(随便看看mybatis源码)
两个很有名的持久层hibernate和mybatis应该很熟悉不过了,两者最大相同点是底层都是对jdbc的封装,最大的不同点是前者是自动生成sql语句,后者是需要我们在映射文件中写出sql。
其实从以前就一直想看看mybatis源码的,由于自己太懒了就一直拖了下来,最近没啥事,就看看源码吧!
都说mybatis是对jdbc的封装当然,那到底是怎么封装的呢?眼见为实!还是跟以前一样,如果只看mybatis有点不过瘾,于是我们就顺便从最基本的jdbc开始看起!
1.简单看看JDBC
JDBC大家应该不陌生了,其实就是java对数据库CRUD操作的工具(或者叫做api),然后我们学的所有对数据库操作的框架的底层就是JDBC的一些封装,可能是框架什么的用得多了,我也经常会忘了JDBC步骤是什么,偶尔还是要拿出来看看啊!
不过我掌握JDBC的步骤就五个字 “贾琏欲执事”,其实就是“加,连,预,执,释放”,其实就是加载数据库驱动,获得连接,预处理对象,执行sql语句,释放资源。
大概的逻辑就是如此,我们大概看一下最原始的jdbc代码,没啥好说的!
public class TestJdbc {
public void insert()
{
String driver="com.mysql.jdbc.Driver";
String url="jdbc:mysql:/localhost:3306/testJdbc";
String user="root";
String password="123456";
Connection conn=null;
PreparedStatement pstmt=null;
String sql="insert into user values(?,?)";
try {
//1、注册驱动
Class.forName(driver);
//2、获取连接
conn= DriverManager.getConnection(url, user, password);
//3、创建预处理对象 并设置参数
pstmt = (PreparedStatement) conn.prepareStatement(sql);
pstmt.setString(1, "xiaowang");
pstmt.setString(2, 18);
//4、执行sql语句
pstmt.executeUpdate(sql);
//5、处理结果集,如果有的话就处理,没有就不用处理,当然insert语句就不用处理了
} catch (Exception e) {
e.printStackTrace();
}
finally{
//6、关闭资源
try {
if(pstmt!=null)pstmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
try {
if(conn!=null)conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
而且JDBC的增删改查其实分为两类,增删改是一类,执行sql语句使用pstmt.executeUpdate(),返回一个整数,1代表成功,0代表失败;查询是另外一类,执行sql语句用pstmt.executeQuery(),返回的是一个结果集ResultSet,后续的就可以对结果集进行遍历,做一些处理从而得到我们需要的数据。
2.搭建原始mybatis环境(JDK1.8+eclipse)
这里我们就看最原始的mybatis就可以了,比较直观!这回我们新建一个最普通的maven项目,目录如下:
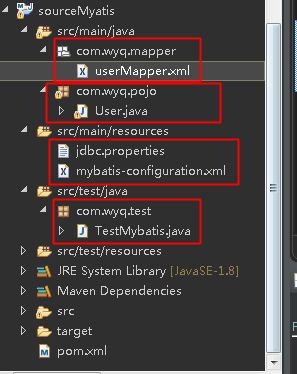
不用下mapper接口,指定命名空间即可!
数据库建表语句:
CREATE TABLE `user` (
`user_id` int(32) NOT NULL COMMENT '用户id',
`user_name` varchar(64) default NULL COMMENT '用户姓名',
`user_age` int(3) default NULL COMMENT '用户年龄',
PRIMARY KEY (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
userMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.wyq.mapper">
<resultMap id="BaseResultMap" type="com.wyq.pojo.User">
<id column="user_id" property="id" jdbcType="INTEGER"></id>
<result column="user_name" property="name" jdbcType="VARCHAR" />
<result column="user_age" property="age" jdbcType="INTEGER" />
</resultMap> <sql id="Base_Column_List">
user_id, user_name, user_age
</sql> <!-- 根据id查询 user 表数据 -->
<select id="selectUserById" resultMap="BaseResultMap" parameterType="java.lang.Integer">
select
<include refid="Base_Column_List" />
from user where user_id = #{id,jdbcType=INTEGER}
</select> <!-- 查询 user 表的所有数据 -->
<select id="selectUserAll" resultMap="BaseResultMap">
select
<include refid="Base_Column_List" />
from user
</select> <!-- 向 user 表插入一条数据 -->
<insert id="insertUser" parameterType="com.wyq.pojo.User" >
insert into
user(<include refid="Base_Column_List" />)
value(#{id,jdbcType=INTEGER},#{name,jdbcType=VARCHAR},#{age,jdbcType=INTEGER})
</insert> <!-- 根据 id 更新 user 表的数据 -->
<update id="updateUserById" parameterType="com.wyq.pojo.User">
update user set
user_name=#{name,jdbcType=VARCHAR} where user_id=#{id,jdbcType=INTEGER}
</update> <!-- 根据 id 删除 user 表的数据 -->
<delete id="deleteUserById" parameterType="java.lang.Integer">
delete from
user where user_id=#{id,jdbcType=INTEGER}
</delete>
</mapper>
User
package com.wyq.pojo;
import java.io.Serializable;
public class User implements Serializable{
public User() {
super();
}
public User(Integer id, String name, Integer age) {
super();
this.id = id;
this.name = name;
this.age = age;
}
private Integer id;
private String name;
private Integer age;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "User [id=" + id + ", name=" + name + ", age=" + age + "]";
}
}
jdbc.properties
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/testmybatis?useUnicode=true&characterEncoding=utf-8
jdbc.username=root
jdbc.password=123456
mybatis-configuration.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration> <!-- 加载数据库属性文件 -->
<properties resource="jdbc.properties">
</properties>
<!-- 可以配置多个运行环境,但是每个 SqlSessionFactory 实例只能选择一个运行环境 一、development:开发模式 二、work:工作模式 -->
<environments default="development">
<!--id属性必须和上面的default一样 -->
<environment id="development">
<transactionManager type="JDBC" />
<!--dataSource 元素使用标准的 JDBC 数据源接口来配置 JDBC 连接对象源 -->
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}" />
<property name="url" value="${jdbc.url}" />
<property name="username" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
</dataSource>
</environment>
</environments> <mappers>
<mapper resource="com/wyq/mapper/userMapper.xml"/>
</mappers>
</configuration>
TestMybatis.java
package com.wyq.test; import java.io.InputStream;
import java.util.List; import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.junit.Test; import com.wyq.pojo.User; public class TestMybatis {
private static final String NAME_SPACE = "com.wyq.mapper";
private static SqlSessionFactory sqlSessionFactory; static{
InputStream inputStream = TestMybatis.class.getClassLoader().getResourceAsStream("mybatis-configuration.xml");
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
}
/**
* 查询单个记录
*/
@Test
public void testSelectOne(){
SqlSession session = sqlSessionFactory.openSession();
User user = session.selectOne(NAME_SPACE+".selectUserById", 1);
System.out.println(user);
session.close(); } /**
* 查询多个记录
*/
@Test
public void testSelectList(){
SqlSession session = sqlSessionFactory.openSession();
List<User> listUser = session.selectList(NAME_SPACE+".selectUserAll");
if(listUser != null){
System.out.println(listUser.size());
}
session.close();
} /**
* 插入一条记录
*/
@Test
public void testInsert(){
SqlSession session = sqlSessionFactory.openSession();
User user = new User(2,"zhangsan",22);
session.insert(NAME_SPACE+".insertUser", user);
session.commit();
session.close();
} /**
* 更新一条记录
*/
@Test
public void testUpdate(){
SqlSession session = sqlSessionFactory.openSession();
User user = new User(2,"lisi",22);
session.update(NAME_SPACE+".updateUserById", user);
session.commit();
session.close();
} /**
* 删除一条记录
*/
@Test
public void testDelete(){
SqlSession session = sqlSessionFactory.openSession();
session.delete(NAME_SPACE+".deleteUserById", 2);
session.commit();
session.close();
} }
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.wyq</groupId>
<artifactId>sourceMyatis</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency> <dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.30</version>
</dependency> </dependencies> </project>
然后运行insert测试方法,看到右下角绿条就说明成功了,查看数据库,确实插入了数据!
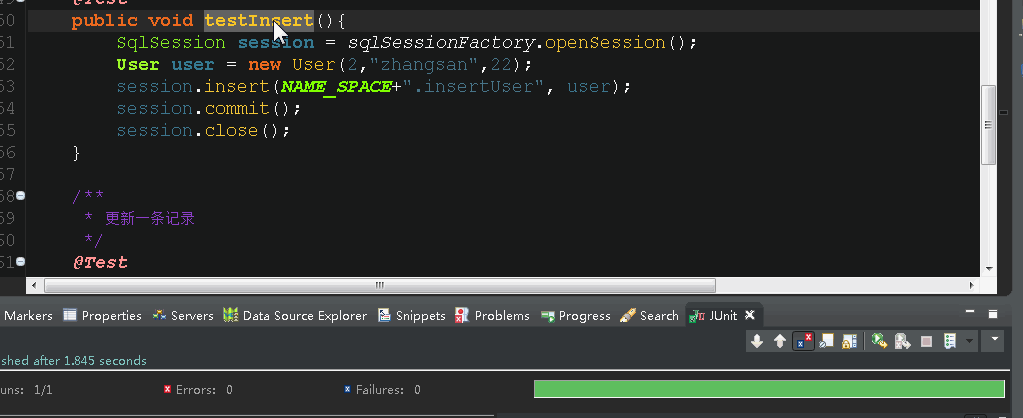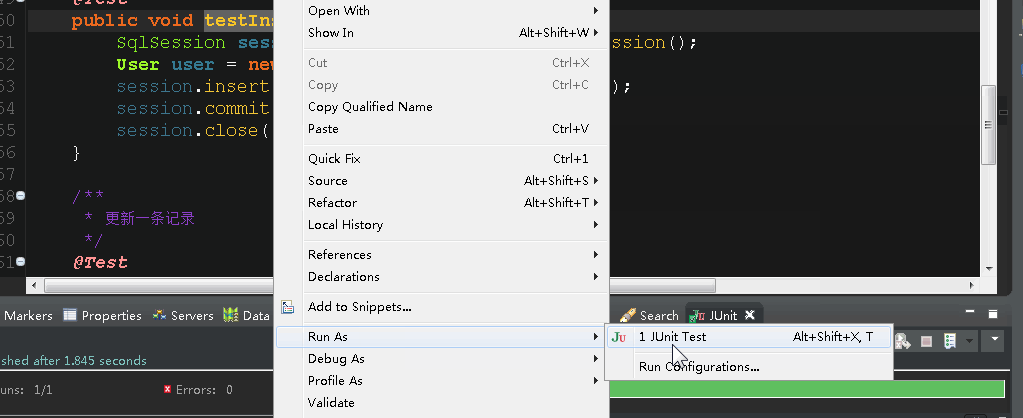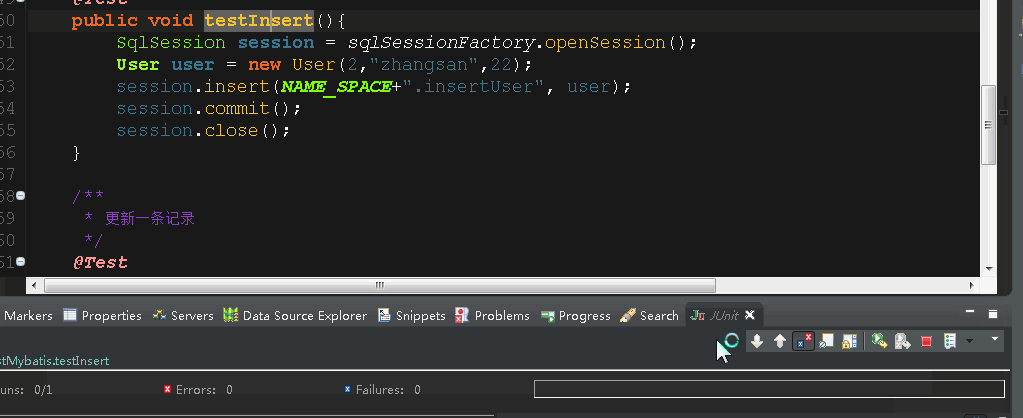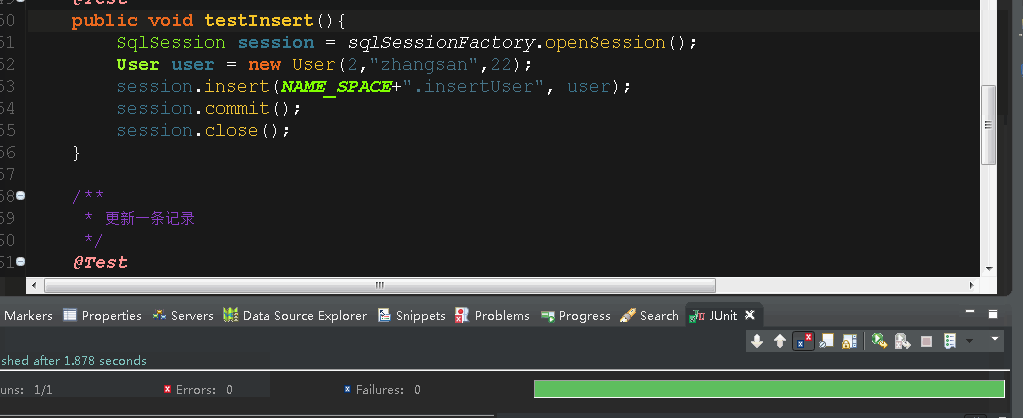
3.断点位置
我们在这里要将调试分为两个部分,一部分是调试增删改方法(其实都是调用update方法,我就以insert()方法为例),另一部分是调试查询方法,其实查一条数据和查多条数据都是通用一个List list = seleceList()方法,如果是一条数据,那就返回 list.get(0) 就可以了!



4.调试
大概有个逻辑,由于没有和spring整合,所以这里可能会涉及到事务,可能我会略过,不是重点!
加载顺序大概是这样的:先加载静态代码块中的数据首先把mybatis主配置文件加载并解析xml,并保存一下其中的数据,然后根据<mapper>标签中配置的映射文件的位置,会去加载映射文件,又是解析xml,于是就创建出来了SqlSessionFactory这个对象了,后面就是创建SqlSession对象,假如是插入方法,拿到<insert>标签所有的内容,并且将传入的参数填充进去,最后就是跟jdbc一样执行sql语句了。
4.1.SqlSessionFactory的创建
首先是build()方法;




在这里只要解析到最外层有<configuration>标签,然后就是根据这个标签解析其内部各种标签,我们可以点进去对边看一看这个parseConfiguration()方法,不做深究,就随意看看;
话说解析xml这种源码我是没多大兴趣的,因为不是dom就是sax解析,这里貌似用的是dom解析的方式,为什么呢?因为这个xml也就这么大,一次性加载到内存中也是轻而易举,假如是有十几兆大甚至几十兆大的xml,最好就用sax,可以一边加载到内存一遍解析。
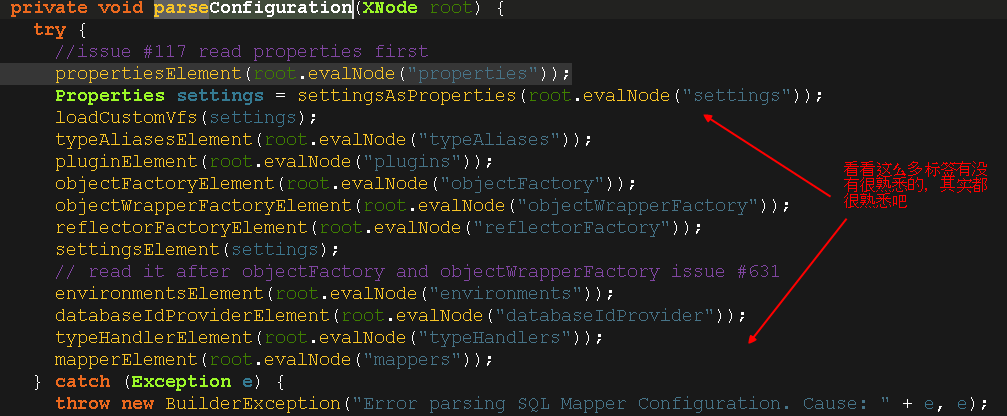
这里不得不稍微提一下,在environmentsElement(root.evalNode("environments"))这一行,方法environmentsElement()中,通过DataSourceFactory拿到我们配置的数据源DataSource,这个数据源有很多实现类,我们最终拿到的是UnpooledDataSource,在这个数据源中有个静态代码块,用于加载数据库驱动并且注册驱动,对这小块没兴趣的小伙伴可以跳过,我感觉这不是重点!我稍微截一下图,有兴趣的可以看看:

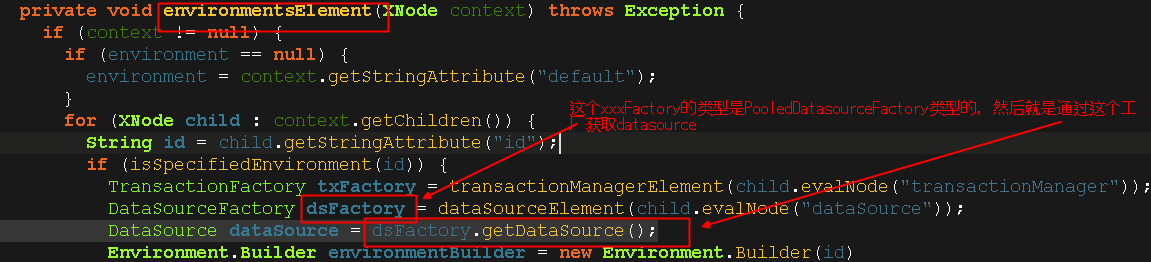
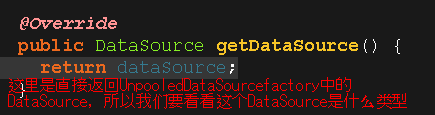


可以看到,要想得到什么类型的数据源,最开始就是要设置什么 类型的DataSourceFacatory;那,怎么设置呢?其实就是在xml中配置一下,如下图所示:
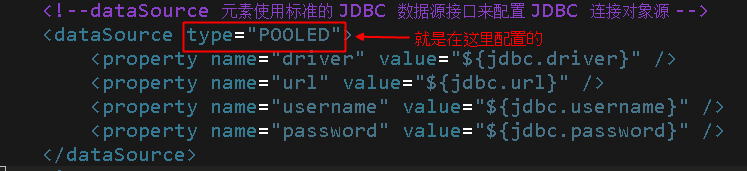
最后,将这些标签的内容解析出来保存一下,运行buile()方法,然后终于就可以建立SqlSessionFactory了;

这个很容易,不过我对怎么解析xml没有什么兴趣,所以就粗略跳过了,反正最后是得到了SqlSessionFactory这个对象了。
4.2.sqlSession的创建过程(忽略缓存)



一直到这里其实还是很容易的,就这么简简单单的创建出来了SqlSession对象,后面就是看看insert方法和select方法看看就差不多懂了!
4.3.看看insert方法
可以看到进入insert()方法,就是执行update()方法


对这里没兴趣的可以略过,不是重点!因为这里我又要随便提一下了,这两个对象分别封装成什么样子的呢?
首先是封装statement

我们可以简单看看MappedStatement这个类基本属性:

我们还可以看看怎么封装传进去的参数的,比如我们这个insert方法传进去的是一个user对象,我们进去wrapCollection(parameter)方法看看:
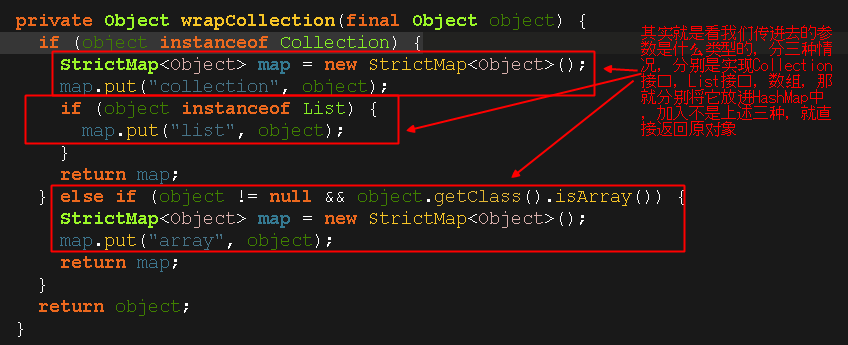
其实没多少厉害的东西,就是把这两个参数进行封装一下,然后继续执行update方法,我们接着往后看:


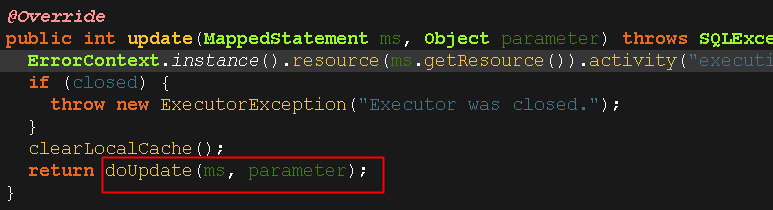
然后大概可以分为两步:
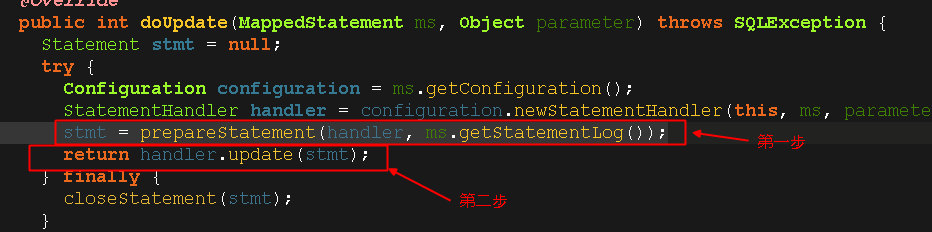
打开第一步源码,可以看到获取连接和创建预处理对象,就是跟jdbc差不多了;

打开第二步源码可以看到预处理对象执行excute()方法,和jdbc一样了,到这里insert()的分析就结束了,看,从最后的两步才能看到jdbc的影子,这是经过了多少层封装啊。。。。
而且你再看看delete()方法和update()方法,和这个insert()的逻辑都是一样,公用方法,最后都是执行excute()方法,这里就不赘述了,有兴趣的可以自己玩一玩!

4.4.看看selectone方法
既然查询一条记录和查询多条记录都是要调用selectList方法,所以我们接下来就重点看看selectList()方法
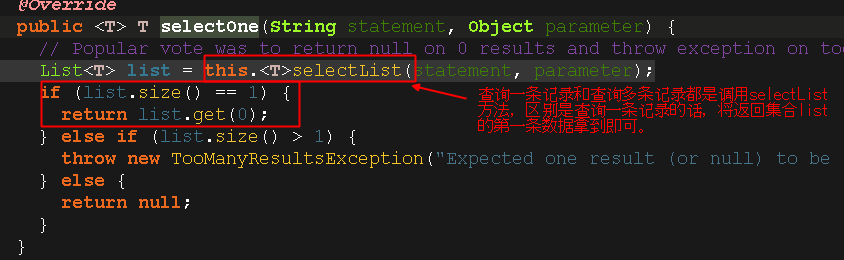
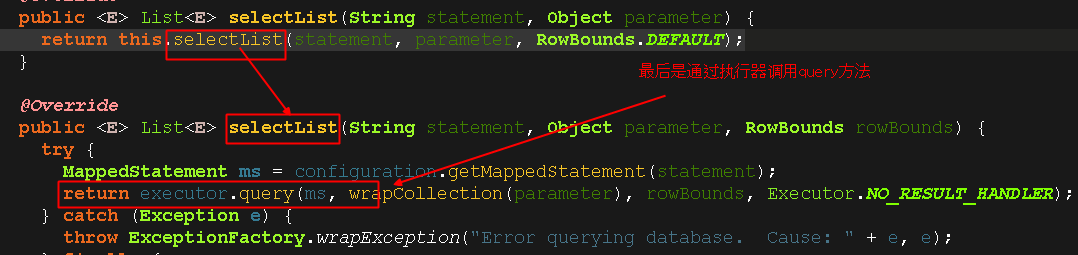


对于上图,我们第一次查询肯定没有缓存,走下面这个方法;而且由于我们是测试环境,测试方法执行完了之后,就会关闭sqlSession,同时会清除缓存,所以在测试的时候,只会走最下面的query()这个方法,不会从缓存中查数据。。。
看下图调用的这个方法名称,翻译一下就是 “从数据库中查询”;
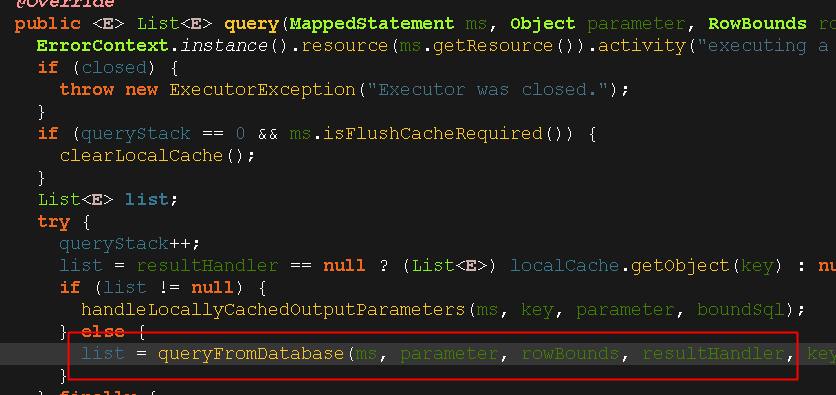
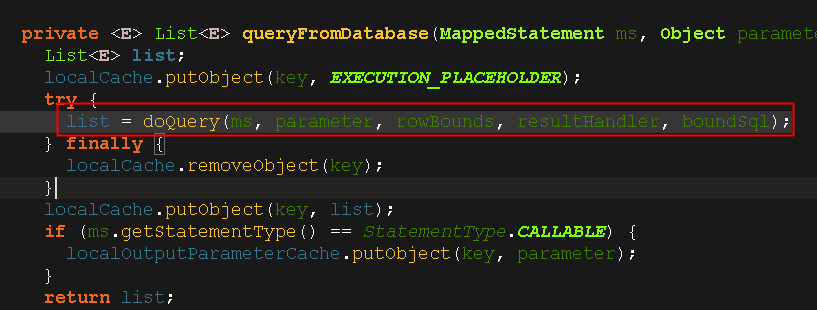
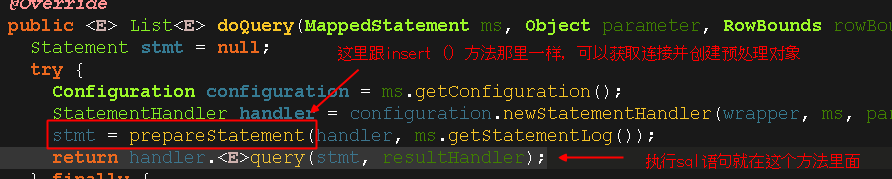

5.总结
总算将这个mybatis的源码过了一遍,怎么说呢?还是那句话,纸上得来终觉浅,绝知此事要躬行!我看别人分析源码的博客总是感觉很容易,一到我自己亲自走源码的时候会出现很多各种各样的问题,就比如切换jdk,其实很容易吧!找到环境变量修改一下jdk路径就行了,但是不知怎么的看到一篇博客用自动脚本完成切换于是花了不少时间去搞个脚本,然后由于脚本有个小bug,又在慢慢尝试;还有对某个方法有点不熟悉可能还要去查一下看别人博客中是怎么分析的;
不过总的来说是把流程过了一遍,而且我还特意忽略了很多可能影响我们看整体流程的一些步骤,留下来的在我看来应该就是最简洁的代码了!
mybatis是一个很好的持久层轻量级框架,和hibernate相比各有利弊,坏处就是写sql可能会花费程序员极大的时间,就光我们这个测试用的demo,你就可以看到userMapper.xml这个映射文件有多少东西了吧,那实际开发中的映射文件里东西更多,可想而知要多花费多少时间;好处也很明显,后期维护起来很简单,还可以随时优化sql语句;
学习笔记02(随便看看mybatis源码)的更多相关文章
- 机器学习实战(Machine Learning in Action)学习笔记————03.决策树原理、源码解析及测试
机器学习实战(Machine Learning in Action)学习笔记————03.决策树原理.源码解析及测试 关键字:决策树.python.源码解析.测试作者:米仓山下时间:2018-10-2 ...
- [shiro学习笔记]第四节 使用源码生成Shiro的CHM格式的API文档
版本号为1.2.3的shiro API chm个事故文档生成. 获取shiro源码 编译生成API文档 转换成chm格式 API 获取shiro源码 shiro官网: http://shiro.apa ...
- 并发编程学习笔记(七、Thread源码分析)
目录: 常见属性 构造函数 start() run() 常见属性: /** * 线程名称 */ private volatile String name; /** * 线程优先级 */ private ...
- Android学习笔记_48_若水新闻客户端源码剖析
一.新闻客户端布局代码 1.1 主界面布局 使用GridView实现左右可滑动菜单项,使用标签HorizontalScrollView实现水平滚动条,将创建的GridView添加到布局文件中. < ...
- mybatis源码学习(一) 原生mybatis源码学习
最近这一周,主要在学习mybatis相关的源码,所以记录一下吧,算是一点学习心得 个人觉得,mybatis的源码,大致可以分为两部分,一是原生的mybatis,二是和spring整合之后的mybati ...
- Mybatis源码学习之整体架构(一)
简述 关于ORM的定义,我们引用了一下百度百科给出的定义,总体来说ORM就是提供给开发人员API,方便操作关系型数据库的,封装了对数据库操作的过程,同时提供对象与数据之间的映射功能,解放了开发人员对访 ...
- mybatis源码学习:一级缓存和二级缓存分析
目录 零.一级缓存和二级缓存的流程 一级缓存总结 二级缓存总结 一.缓存接口Cache及其实现类 二.cache标签解析源码 三.CacheKey缓存项的key 四.二级缓存TransactionCa ...
- mybatis源码学习:基于动态代理实现查询全过程
前文传送门: mybatis源码学习:从SqlSessionFactory到代理对象的生成 mybatis源码学习:一级缓存和二级缓存分析 下面这条语句,将会调用代理对象的方法,并执行查询过程,我们一 ...
- mybatis源码学习:插件定义+执行流程责任链
目录 一.自定义插件流程 二.测试插件 三.源码分析 1.inteceptor在Configuration中的注册 2.基于责任链的设计模式 3.基于动态代理的plugin 4.拦截方法的interc ...
随机推荐
- 会话机器人Chatbot的相关资料
Chatbot简介 竹间智能简仁贤:打破千篇一律的聊天机器人 | Chatbot的潮流 重点关注其中关于情感会话机器人的介绍 当你对我不满的时候我应该怎么应对,当你无聊,跟我说你很烦的时候,我应该怎么 ...
- php递归实现无限级分类树
作者: PHP中文网|标签:PHP 递归 无限级树|2017-5-18 18:09 无限级树状图可以说是无限级栏目的一个显著特征,我们接下来就来看看两种不同的写法. 一.数据库设计 1 2 3 ...
- 在高分屏正确显示CHM文件
今天下了白色相簿2推,发现里面的chm格式的帮助文档显示不正确,又没法在应用程序直接设置系统分辨率托管,google了一下找到了这个方法: 新建 HKEY_LOCAL_MACHINE\ SOFTWAR ...
- HTTP协议简单记录
http协议的格式 1. 首行 2. 头 3. 空行 4. 体 http请求头 #Referer 请求来自哪里,如果是在http://www.baidu.com上点击链接发出的请求,那么Referer ...
- .NET开发微信小程序-Template模块开发
1.添加一个文件目录,里面放模板信息 例:我在根目录添加一个文件夹:template 然后在这个文件夹下面添加相应的页面.比如我添加一个promodel.wxml文件.主要是放商品相关的模块信息(注: ...
- python3 爬取qq音乐作者所有单曲 并且下载歌曲
1 import requests import re import json import os # 便于存放作者的姓名 zuozhe = [] headers = {'User-Agent': ' ...
- 读《图解HTTP》有感-(确认访问用户身份的认证)
写在前面 认证机制能够保证特定的资源给特定的(经过认证的)用户访问.从而保证了资源的机密性. 正文 1.为什么要认证?认证的媒介是什么? 认证的目的在于确认访问者的身份,保证资源的私有性(只有经过特定 ...
- 一分钟告诉你究竟DevOps是什么鬼?
历史回顾 为了能够更好的理解什么是DevOps,我们很有必要对当时还只有程序员(此前还没有派生出开发者,前台工程师,后台工程师之类)这个称号存在的历史进行一下回顾. 如编程之道中所言: 老一辈的程序员 ...
- mpvue-编写微信小程序总结
一.写在前面: .....最近在写一个微信小程序项目,在看完官方微信小程序开发文档后,有一种直接想"放弃"的念头: .....使用微信小程序原生框架可以快速,方便,简洁的搭建项目, ...
- Windows 安装 Vue
引言 在公司 linux 环境下安装不顺利,回家在 windows 下操作感觉到一种幸福 nginx 先安装了 nginx,其实跟 vue 没关系,只是打算用它做 web 服务,此处略过 nginx ...