C++内存深入理解
转载地址:http://www.cnblogs.com/DylanWind/archive/2009/01/12/1373919.html
前部分原创,转载请注明出处,谢谢!
class Base
{
public:
int m_base;
}; class DerivedA: public Base
{
public:
int m_derivedA;
}; class DerivedB: public Base
{
public:
int m_derivedB;
}; class DerivedC: public DerivedA, public DerivedB
{
public:
int m_derivedC;
};
类结构图:
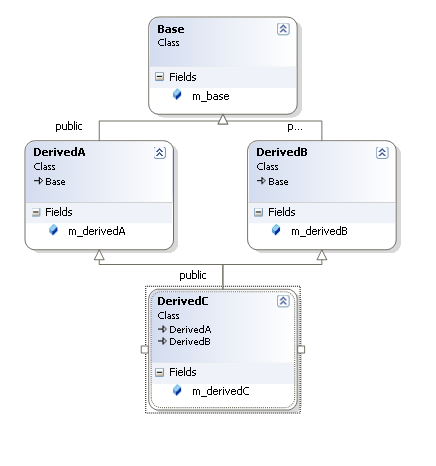
内存分布图:
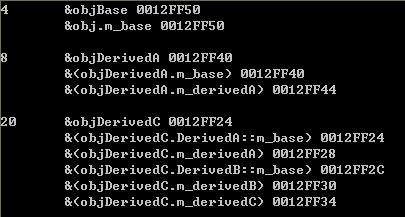
DerivedC:
DerivedA::m_base
m_derivedA
DerivedB::m_base
m_derivedB
m_derivedC
====================================================
如果DerivedB 和 DerivedC 都是虚继承 , 即 virtual public Base
这时内存布局:

DerivedC:
objDerivedA::vbptr
objDerivedA::m_derivedA
objDerivedB::vbptr
objDerivedB::m_derivedB
m_derivedC
m_base 只有一份
类似于这个:

=================================================================
Base, DerivedA, DerivedB 各增加一个虚函数

DerivedB::m_derivedB 18
若子类没有新定义virtual函数 此时子类的布局是 :
低地址 -> 高地址
父类的元素(没有vfptr),子类的元素(没有vfptr).
若子类有新定义virtual函数 此时子类的布局是 :
低地址 -> 高地址
vfptr,指向vtable, 父类的元素(没有vfptr), 子类的元素
不管子类没有新定义virtual函数 此时子类的布局是 :
低地址 -> 高地址
如果子类有新定义的virtual函数,那么在父类的vfptr(也就是第一个vptr)对应的vtable中添加一个函数指针.
若子类没有新定义virtual函数 此时子类的布局是 :
低地址 -> 高地址
为什么这里会出现vbptr,因为虚基类派生出来的类中,虚基类的对象不在固定位置(猜测应该是在内存的尾部),需 要一个中介才能访问虚基类的对象.所以虽然没有virtual函数,子类也需要有一个vbptr,对应的vtable中需要有一项指向 虚基类.
若子类有新定义virtual函数 此时子类的布局是与没有定义新virtual函数内存布局一致.但是在vtable中会多出新增的虚函数的指针.
|
——谈VC++对象模型 译者前言 一个C++程序员,想要进一步提升技术水平的话,应该多了解一些语言的语意细节。对于使用VC++的程序员来说,还应该了解一些VC++对于C++的诠释。Inside the C++ Object Model虽然是一本好书,然而,书的篇幅多一些,又和具体的VC++关系小一些。因此,从篇幅和内容来看,译者认为本文是深入理解C++对象模型比较好的一个出发点。 本文原文出处为MSDN。如果你安装了MSDN,可以搜索到C++ Under the Hood。否则也可在网站上找到 http://msdn.microsoft.com/archive/default.asp?url=/archive/en-us/dnarvc/html/jangrayhood.asp 。 1 前言 了解你所使用的编程语言究竟是如何实现的,对于C++程序员可能特别有意义。首先,它可以去除我们对于所使用语言的神秘感,使我们不至于对于编译器干的活感到完全不可思议;尤其重要的是,它使我们在Debug和使用语言高级特性的时候,有更多的把握。当需要提高代码效率的时候,这些知识也能够很好地帮助我们。 本文着重回答这样一些问题: 对每个语言特性,我们将简要介绍该特性背后的动机,该特性自身的语意(当然,本文决不是“C++入门”,大家对此要有充分认识),以及该特性在微软的VC++中是如何实现的。这里要注意区分抽象的C++语言语意与其特定实现。微软之外的其他C++厂商可能提供一个完全不同的实现,我们偶尔也会将VC++的实现与其他实现进行比较。 2 类布局 本节讨论不同的继承方式造成的不同内存布局。 2.1 C结构(struct) 由于C++基于C,所以C++也“基本上”兼容C。特别地,C++规范在“结构”上使用了和C相同的,简单的内存布局原则:成员变量按其被声明的顺序排列,按具体实现所规定的对齐原则在内存地址上对齐。所有的C/C++厂商都保证他们的C/C++编译器对于有效的C结构采用完全相同的布局。这里,A是一个简单的C结构,其成员布局和对齐方式都一目了然
struct A { 译者注:从上图可见,A在内存中占有8个字节,按照声明成员的顺序,前4个字节包含一个字符(实际占用1个字节,3个字节空着,补对齐),后4个字节包含一个整数。A的指针就指向字符开始字节处。 2.2 有C++特征的C结构 当然了,C++不是复杂的C,C++本质上是面向对象的语言:包含继承、封装,以及多态。原始的C结构经过改造,成了面向对象世界的基石——类。除了成员变量外,C++类还可以封装成员函数和其他东西。然而,有趣的是,除非为了实现虚函数和虚继承引入的隐藏成员变量外,C++类实例的大小完全取决于一个类及其基类的成员变量!成员函数基本上不影响类实例的大小。 这里提供的B是一个C结构,然而,该结构有一些C++特征:控制成员可见性的“public/protected/private”关键字、成员函数、静态成员,以及嵌套的类型声明。虽然看着琳琅满目,实际上只有成员变量才占用类实例的空间。要注意的是,C++标准委员会不限制由“public/protected/private”关键字分开的各段在实现时的先后顺序,因此,不同的编译器实现的内存布局可能并不相同。(在VC++中,成员变量总是按照声明时的顺序排列)。
struct B { 译者注:B中,为何static int bsm不占用内存空间?因为它是静态成员,该数据存放在程序的数据段中,不在类实例中。 2.3 单继承 C++提供继承的目的是在不同的类型之间提取共性。比如,科学家对物种进行分类,从而有种、属、纲等说法。有了这种层次结构,我们才可能将某些具备特定性质的东西归入到最合适的分类层次上,如“怀孩子的是哺乳动物”。由于这些属性可以被子类继承,所以,我们只要知道“鲸鱼、人”是哺乳动物,就可以方便地指出“鲸鱼、人都可以怀孩子”。那些特例,如鸭嘴兽(生蛋的哺乳动物),则要求我们对缺省的属性或行为进行覆盖。
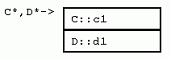
struct C {
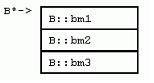
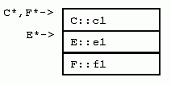
struct D : C { 既然派生类要保留基类的所有属性和行为,自然地,每个派生类的实例都包含了一份完整的基类实例数据。在D中,并不是说基类C的数据一定要放在D的数据之前,只不过这样放的话,能够保证D中的C对象地址,恰好是D对象地址的第一个字节。这种安排之下,有了派生类D的指针,要获得基类C的指针,就不必要计算偏移量了。几乎所有知名的C++厂商都采用这种内存安排(基类成员在前)。在单继承类层次下,每一个新的派生类都简单地把自己的成员变量添加到基类的成员变量之后。看看上图,C对象指针和D对象指针指向同一地址。 2.4 多重继承 大多数情况下,其实单继承就足够了。但是,C++为了我们的方便,还提供了多重继承。 比如,我们有一个组织模型,其中有经理类(分任务),工人类(干活)。那么,对于一线经理类,即既要从上级经理那里领取任务干活,又要向下级工人分任务的角色来说,如何在类层次中表达呢?单继承在此就有点力不胜任。我们可以安排经理类先继承工人类,一线经理类再继承经理类,但这种层次结构错误地让经理类继承了工人类的属性和行为。反之亦然。当然,一线经理类也可以仅仅从一个类(经理类或工人类)继承,或者一个都不继承,重新声明一个或两个接口,但这样的实现弊处太多:多态不可能了;未能重用现有的接口;最严重的是,当接口变化时,必须多处维护。最合理的情况似乎是一线经理从两个地方继承属性和行为——经理类、工人类。 C++就允许用多重继承来解决这样的问题: struct Manager ... { ... }; 这样的继承将造成怎样的类布局呢?下面我们还是用“字母类”来举例:
struct E {
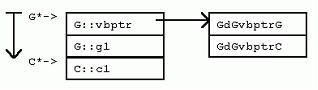
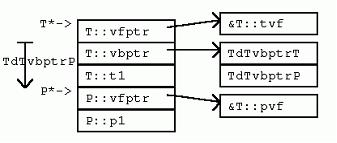
struct F : C, E { 观察类布局,可以看到F中内嵌的E对象,其指针与F指针并不相同。正如后文讨论强制转化和成员函数时指出的,这个偏移量会造成少量的调用开销。 具体的编译器实现可以自由地选择内嵌基类和派生类的布局。VC++按照基类的声明顺序先排列基类实例数据,最后才排列派生类数据。当然,派生类数据本身也是按照声明顺序布局的(本规则并非一成不变,我们会看到,当一些基类有虚函数而另一些基类没有时,内存布局并非如此)。 2.5 虚继承 回到我们讨论的一线经理类例子。让我们考虑这种情况:如果经理类和工人类都继承自“雇员类”,将会发生什么? 很不幸,在C++中,这种“共享继承”被称为“虚继承”,把问题搞得似乎很抽象。虚继承的语法很简单,在指定基类时加上virtual关键字即可。
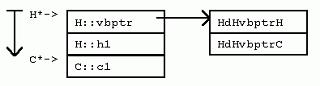
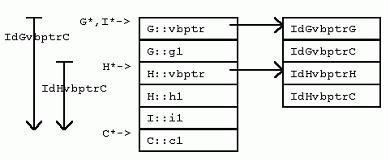
struct G : virtual C {
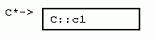
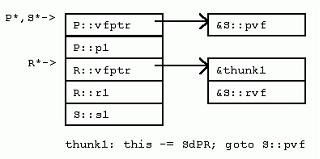
struct H : virtual C { 在VC++中,对每个继承自虚基类的类实例,将增加一个隐藏的“虚基类表指针”(vbptr)成员变量,从而达到间接计算虚基类位置的目的。该变量指向一个全类共享的偏移量表,表中项目记录了对于该类而言,“虚基类表指针”与虚基类之间的偏移量。 其它的实现方式中,有一种是在派生类中使用指针成员变量。这些指针成员变量指向派生类的虚基类,每个虚基类一个指针。这种方式的优点是:获取虚基类地址时,所用代码比较少。然而,编译器优化代码时通常都可以采取措施避免重复计算虚基类地址。况且,这种实现方式还有一个大弊端:从多个虚基类派生时,类实例将占用更多的内存空间;获取虚基类的虚基类的地址时,需要多次使用指针,从而效率较低等等。 在VC++中,G拥有一个隐藏的“虚基类表指针”成员,指向一个虚基类表,该表的第二项是GdGvbptrC。(在G中,虚基类对象C的地址与G的“虚基类表指针”之间的偏移量(当对于所有的派生类来说偏移量不变时,省略“d”前的前缀))。比如,在32位平台上,GdGvptrC是8个字节。同样,在I实例中的G对象实例也有“虚基类表指针”,不过该指针指向一个适用于“G处于I之中”的虚基类表,表中一项为IdGvbptrC,值为20。 观察前面的G、H和I,我们可以得到如下关于VC++虚继承下内存布局的结论: 该布局安排使得虚基类的位置随着派生类的不同而“浮动不定”,但是,非虚基类因此也就凑在一起,彼此的偏移量固定不变。 3 成员变量 介绍了类布局之后,我们接着考虑对不同的继承方式,访问成员变量的开销究竟如何。 没有继承。没有任何继承关系时,访问成员变量和C语言的情况完全一样:从指向对象的指针,考虑一定的偏移量即可。 单继承。由于派生类实例与其基类实例之间的偏移量是常数0,所以,可以直接利用基类指针和基类成员之间的偏移量关系,如此计算得以简化。 多重继承。虽然派生类与某个基类之间的偏移量可能不为0,然而,该偏移量总是一个常数。只要是个常数,访问成员变量,计算成员变量偏移时的计算就可以被简化。可见即使对于多重继承来说,访问成员变量开销仍然不大。 虚继承。当类有虚基类时,访问非虚基类的成员仍然是计算固定偏移量的问题。然而,访问虚基类的成员变量,开销就增大了,因为必须经过如下步骤才能获得成员变量的地址:获取“虚基类表指针”;获取虚基类表中某一表项的内容;把内容中指出的偏移量加到“虚基类表指针”的地址上。然而,事情并非永远如此。正如下面访问I对象的c1成员那样,如果不是通过指针访问,而是直接通过对象实例,则派生类的布局可以在编译期间静态获得,偏移量也可以在编译时计算,因此也就不必要根据虚基类表的表项来间接计算了。 I* pi; 当访问类继承层次中,多层虚基类的成员变量时,情况又如何呢?比如,访问虚基类的虚基类的成员变量时?一些实现方式为:保存一个指向直接虚基类的指针,然后就可以从直接虚基类找到它的虚基类,逐级上推。VC++优化了这个过程。VC++在虚基类表中增加了一些额外的项,这些项保存了从派生类到其各层虚基类的偏移量。 4 强制转化 如果没有虚基类的问题,将一个指针强制转化为另一个类型的指针代价并不高昂。如果在要求转化的两个指针之间有“基类-派生类”关系,编译器只需要简单地在两者之间加上或者减去一个偏移量即可(并且该量还往往为0)。 F* pf; C和E是F的基类,将F的指针pf转化为C*或E*,只需要将pf加上一个相应的偏移量。转化为C类型指针C*时,不需要计算,因为F和C之间的偏移量为0。转化为E类型指针E*时,必须在指针上加一个非0的偏移常量dFE。C++规范要求NULL指针在强制转化后依然为NULL,因此在做强制转化需要的运算之前,VC++会检查指针是否为NULL。当然,这个检查只有当指针被显示或者隐式转化为相关类型指针时才进行;当在派生类对象中调用基类的方法,从而派生类指针被在后台转化为一个基类的Const “this” 指针时,这个检查就不需要进行了,因为在此时,该指针一定不为NULL。 正如你猜想的,当继承关系中存在虚基类时,强制转化的开销会比较大。具体说来,和访问虚基类成员变量的开销相当。 I* pi; 一般说来,当从派生类中访问虚基类成员时,应该先强制转化派生类指针为虚基类指针,然后一直使用虚基类指针来访问虚基类成员变量。这样做,可以避免每次都要计算虚基类地址的开销。见下例。 /* before: */ ... pi->c1 ... pi->c1 ... 5 成员函数 一个C++成员函数只是类范围内的又一个成员。X类每一个非静态的成员函数都会接受一个特殊的隐藏参数——this指针,类型为X* const。该指针在后台初始化为指向成员函数工作于其上的对象。同样,在成员函数体内,成员变量的访问是通过在后台计算与this指针的偏移来进行。 P有一个非虚成员函数pf(),以及一个虚成员函数pvf()。很明显,虚成员函数造成对象实例占用更多内存空间,因为虚成员函数需要虚函数表指针。这一点以后还会谈到。这里要特别指出的是,声明非虚成员函数不会造成任何对象实例的内存开销。现在,考虑P::pf()的定义。 这里P:pf()接受了一个隐藏的this指针参数,对于每个成员函数调用,编译器都会自动加上这个参数。同时,注意成员变量访问也许比看起来要代价高昂一些,因为成员变量访问通过this指针进行,在有的继承层次下,this指针需要调整,所以访问的开销可能会比较大。然而,从另一方面来说,编译器通常会把this指针缓存到寄存器中,所以,成员变量访问的代价不会比访问局部变量的效率更差。 5.1 覆盖成员函数 和成员变量一样,成员函数也会被继承。与成员变量不同的是,通过在派生类中重新定义基类函数,一个派生类可以覆盖,或者说替换掉基类的函数定义。覆盖是静态(根据成员函数的静态类型在编译时决定)还是动态(通过对象指针在运行时动态决定),依赖于成员函数是否被声明为“虚函数”。 Q从P继承了成员变量和成员函数。Q声明了pf(),覆盖了P::pf()。Q还声明了pvf(),覆盖了P::pvf()虚函数。Q还声明了新的非虚成员函数qf(),以及新的虚成员函数qvf()。
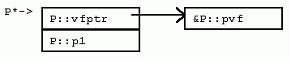
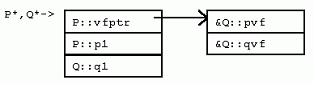
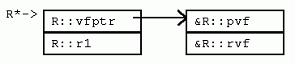
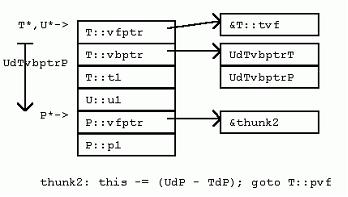
struct Q : P { 对于虚函数调用来说,调用哪个成员函数在运行时决定。不管“->”操作符左边的指针表达式的类型如何,调用的虚函数都是由指针实际指向的实例类型所决定。比如,尽管ppq的类型是P*,当ppq指向Q的实例时,调用的仍然是Q::pvf()。 为了实现这种机制,引入了隐藏的vfptr成员变量。一个vfptr被加入到类中(如果类中没有的话),该vfptr指向类的虚函数表(vftable)。类中每个虚函数在该类的虚函数表中都占据一项。每项保存一个对于该类适用的虚函数的地址。因此,调用虚函数的过程如下:取得实例的vfptr;通过vfptr得到虚函数表的一项;通过虚函数表该项的函数地址间接调用虚函数。也就是说,在普通函数调用的参数传递、调用、返回指令开销外,虚函数调用还需要额外的开销。 回头再看看P和Q的内存布局,可以发现,VC++编译器把隐藏的vfptr成员变量放在P和Q实例的开始处。这就使虚函数的调用能够尽量快一些。实际上,VC++的实现方式是,保证任何有虚函数的类的第一项永远是vfptr。这就可能要求在实例布局时,在基类前插入新的vfptr,或者要求在多重继承时,虽然在右边,然而有vfptr的基类放到左边没有vfptr的基类的前面(如下)。 class CA { int a;}; class CB { int b;}; class CL : public CB, public CA { int c;}; 以上的类继承, 对CL类说, 他的内存布局是 int b; int a; int c; 但是, 改造CA如下: class CA { int a; virtual void seta( int _a ) { a = _a; } }; 同样继承顺序的CL, 内存中布局是 vfptr int a; int b; int c; CA被提到CB前面, 这样的布局是因为 class 的布局就是 vfptr肯定要放在最前面. 许多C++的实现会共享或者重用从基类继承来的vfptr。比如,Q并不会有一个额外的vfptr,指向一个专门存放新的虚函数qvf()的虚函数表。Qvf项只是简单地追加到P的虚函数表的末尾。如此一来,单继承的代价就不算高昂。一旦一个实例有vfptr了,它就不需要更多的vfptr。新的派生类可以引入更多的虚函数,这些新的虚函数只是简单地在已存在的,“每类一个”的虚函数表的末尾追加新项。 5.2 多重继承下的虚函数 如果从多个有虚函数的基类继承,一个实例就有可能包含多个vfptr。考虑如下的R和S类: struct S : P, R { 这里R是另一个包含虚函数的类。因为S从P和R多重继承,S的实例内嵌P和R的实例,以及S自身的数据成员S::s1。注意,在多重继承下,靠右的基类R,其实例的地址和P与S不同。S::pvf覆盖了P::pvf()和R::pvf(),S::rvf()覆盖了R::rvf()。 因为S::pvf()覆盖了P::pvf()和R::pvf(),在S的虚函数表中,相应的项也应该被覆盖。然而,我们很快注意到,不光可以用P*,还可以用R*来调用pvf()。问题出现了:R的地址与P和S的地址不同。表达式(R*)ps与表达式(P*)ps指向类布局中不同的位置。因为函数S::pvf希望获得一个S*作为隐藏的this指针参数,虚函数必须把R*转化为S*。因此,在S对R虚函数表的拷贝中,pvf函数对应的项,指向的是一个“调整块”的地址,该调整块使用必要的计算,把R*转换为需要的S*。 在微软VC++实现中,对于有虚函数的多重继承,只有当派生类虚函数覆盖了多个基类的虚函数时,才使用调整块。 5.3 地址点与“逻辑this调整” 考虑下一个虚函数S::rvf(),该函数覆盖了R::rvf()。我们都知道S::rvf()必须有一个隐藏的S*类型的this参数。但是,因为也可以用R*来调用rvf(),也就是说,R的rvf虚函数槽可能以如下方式被用到: 当然,在debugger中,必须对这种this调整进行补偿。 所以,当覆盖非最左边的基类的虚函数时,MSC++一般不创建调整块,也不增加额外的虚函数项。 5.4 调整块 正如已经描述的,有时需要调整块来调整this指针的值(this指针通常位于栈上返回地址之下,或者在寄存器中),在this指针上加或减去一个常量偏移,再调用虚函数。某些实现(尤其是基于cfront的)并不使用调整块机制。它们在每个虚函数表项中增加额外的偏移数据。每当虚函数被调用时,该偏移数据(通常为0),被加到对象的地址上,然后对象的地址再作为this指针传入。 ps->rvf(); 这种方法的缺点是虚函数表增大了,虚函数的调用也更加复杂。 现代基于PC的实现一般采用“调整—跳转”技术: 5.5 虚继承下的虚函数 T虚继承P,覆盖P的虚成员函数,声明了新的虚函数。如果采用在基类虚函数表末尾添加新项的方式,则访问虚函数总要求访问虚基类。在VC++中,为了避免获取虚函数表时,转换到虚基类P的高昂代价,T中的新虚函数通过一个新的虚函数表获取,从而带来了一个新的虚函数表指针。该指针放在T实例的顶端。 在此U增加了一个成员变量,从而改变了P的偏移。因为VC++实现中,T::pvf()接受的是嵌套在T中的P的指针,所以,需要提供一个调整块,把this指针调整到T::t1之后(该处即是P在T中的位置)。 5.6 特殊成员函数 本节讨论编译器合成到特殊成员函数中的隐藏代码。 5.6.1 构造函数和析构函数 正如我们所见,在构造和析构过程中,有时需要初始化一些隐藏的成员变量。最坏的情况下,一个构造函数要执行如下操作: * 如果是“最终派生类”,初始化vbptr成员变量,调用虚基类的构造函数; (注意:一个“最终派生类”的实例,一定不是嵌套在其他派生类实例中的基类实例) 所以,如果你有一个包含虚函数的很深的继承层次,即使该继承层次由单继承构成,对象的构造可能也需要很多针对虚函数表的初始化。 * 合成并初始化虚函数表成员变量 在VC++中,有虚基类的类的构造函数接受一个隐藏的“最终派生类标志”,标示虚基类是否需要初始化。对于析构函数,VC++采用“分层析构模型”,代码中加入一个隐藏的析构函数,该函数被用于析构包含虚基类的类(对于“最终派生类”实例而言);代码中再加入另一个析构函数,析构不包含虚基类的类。前一个析构函数调用后一个。 5.6.2 虚析构函数与delete操作符 假如A是B的父类, 实际上,很多人这样总结:当且仅当类里包含至少一个虚函数的时候才去声明虚析构函数。 考虑结构V和W。 为了实现上述语意,VC++扩展了其“分层析构模型”,从而自动创建另一个隐藏的析构帮助函数——“deleting析构函数”,然后,用该函数的地址来替换虚函数表中“实际”虚析构函数的地址。析构帮助函数调用对该类合适的析构函数,然后为该类有选择性地调用合适的delete操作符。 6 数组 堆上分配空间的数组使虚析构函数进一步复杂化。问题变复杂的原因有两个: 虽然从严格意义上来说,数组delete的多态行为C++标准并未定义,然而,微软有一些客户要求实现该行为。因此,在MSC++中,该行为是用另一个编译器生成的虚析构帮助函数来完成。该函数被称为“向量delete析构函数”(因其针对特定的类定制,比如WW,所以,它能够遍历数组的每个元素,调用对每个元素适用的析构函数)。 7 异常处理 简单说来,异常处理是C++标准委员会工作文件提供的一种机制,通过该机制,一个函数可以通知其调用者“异常”情况的发生,调用者则能据此选择合适的代码来处理异常。该机制在传统的“函数调用返回,检查错误状态代码”方法之外,给程序提供了另一种处理错误的手段。 因为C++是面向对象的语言,很自然地,C++中用对象来表达异常状态。并且,使用何种异常处理也是基于“抛出的”异常对象的静态或动态类型来决定的。不光如此,既然C++总是保证超出范围的对象能够被正确地销毁,异常实现也必须保证当控制从异常抛出点转换到异常“捕获”点时(栈展开),超出范围的对象能够被自动、正确地销毁。 int main() { void f(int i) { void g(int j) { 这段程序会抛出异常。在main中,加入了处理异常的try & catch框架,当调用f(0)时,f构造z1,调用g(0)后,再构造z2,再调用g(-1),此时g发现参数为负,抛出X异常对象。我们希望在某个调用层次上,该异常能够得到处理。既然g和f都没有建立处理异常的框架,我们就只能希望main函数建立的异常处理框架能够处理X异常对象。实际上,确实如此。当控制被转移到main中异常捕获点时,从g中的异常抛出点到main中的异常捕获点之间,该范围内的对象都必须被销毁。在本例中,z2和z1应该被销毁。 谈到异常处理的具体实现方式,一般情况下,在抛出点和捕获点都使用“表”来表述能够捕获异常对象的类型;并且,实现要保证能够在特定的捕获点真正捕获特定的异常对象;一般地,还要运用抛出的对象来初始化捕获语句的“实参”。通过合理地选择编码方案,可以保证这些表格不会占用过多的内存空间。 异常处理的开销到底如何?让我们再考虑一下函数f。看起来f没有做异常处理。f确实没有包含try,catch,或者是throw关键字,因此,我们会猜异常处理应该对f没有什么影响。错!编译器必须保证一旦z1被构造,而后续调用的任何函数向f抛回了异常,异常又出了f的范围时,z1对象能被正确地销毁。同样,一旦z2被构造,编译器也必须保证后续抛出异常时,能够正确地销毁z2和z1。 要实现这些“展开”语意,编译器必须在后台提供一种机制,该机制在调用者函数中,针对调用的函数抛出的异常动态决定异常环境(处理点)。这可能包括在每个函数的准备工作和善后工作中增加额外的代码,在最糟糕的情况下,要针对每一套对象初始化的情况更新状态变量。例如,上述例子中,z1应被销毁的异常环境当然与z2和z1都应该被销毁的异常环境不同,因此,不管是在构造z1后,还是继而在构造z2后,VC++都要分别在状态变量中更新(存储)新的值。 所有这些表,函数调用的准备和善后工作,状态变量的更新,都会使异常处理功能造成可观的内存空间和运行速度开销。正如我们所见,即使在没有使用异常处理的函数中,该开销也会发生。 幸运的是,一些编译器可以提供编译选项,关闭异常处理机制。那些不需要异常处理机制的代码,就可以避免这些额外的开销了。 8 小结 好了,现在你可以写C++编译器了(开个玩笑)。 |




C++内存深入理解的更多相关文章
- 移动端测试===Android内存管理: 理解App的PSS
Android内存管理: 理解App的PSS 原文链接:http://www.littleeye.co/blog/2013/06/11/android-memory-management-unders ...
- 摘:Windows系统内存计数器理解解析_备忘录_51Testing软件测试网...
[原创]Windows系统内存计数器理解解析 2008-05-13 11:42:23 / 个人分类:性能测试 说明:本文的计数器以Windows2003为准. 序言;F9n)\%V1a6Z C)?ZV ...
- 【VS开发】程序员对内存的理解
程序员对内存的理解 在C和C++语言开发中,指针.内存一直是学习的重点.因为C语言作为一种偏底层的中低级语言,提供了大量的内存直接操作的方法,这一方面使程序的灵活度最大化,同时也为bug埋下很多隐患. ...
- UCOS 内存管理理解 创建任务
OS_MEM *OSMemCreate (void *addr, INT32U nblks, INT32U blksize, INT8U *err) { ................... ...
- Android Dalvikvm 内存管理理解
网上非常多文件介绍了 jvm 内存管理的理论,但在 Dalvikvm 中,到底是怎样实现的. 这几天猛看了 Dalvikvm 的源码,说一下我的理解: 在大层面上讲跟理论一样,jvm 把内存分成了一些 ...
- C# 通俗说 内存的理解
一.概念 堆栈是什么? 在说堆栈之前,先说说内存是神马? 内存:程序在运行的过程,电脑需要不断通过CPU进行计算,这个计算的过程会读取并产生运算的数据,这些数据需要一个存储容器存放.这个容器,这就是内 ...
- Java内存 模型理解
概述 在正式讲Java内存模型之前,我们先了解一些物理计算机并发问题,然后一点点的引出Java内存模型的由来. 多任务处理在现在计算机操作系统中几乎是一项必备的功能.这不单是因为计算机计算能力强大,更 ...
- Java内存虚拟机理解
对于Java程序员,在虚拟机自动内存管理机制的帮助下,不需要再为每一个操作写配对的释放资源操作,不容易出现内存泄露和内存溢出问题.加深对Java虚拟机的理解,有助于在发现问题时精准定位问题,排 ...
- JVM内存简单理解
1.首先简单说一下CPU与内存之间的关系 CPU运转速度快,磁盘的读写速度远远不及CPU运转速度,所以设计了内存来缓冲CPU等待磁盘读写:随着CPU的发展,内存读写也远远跟不上CPU的读写速度,CPU ...
随机推荐
- 基于Qt的手机程序----口袋理财
主页面 记账模块 制定目标 备忘录
- python“# -*- coding: UTF-8 -*-”
python跑一趟红 python脚本文件中,python编译器是使用ascii码来解释脚本内容.如果.py源文件中包含中文,会报错(注释也报错).所以文件开头加上"# -*- coding ...
- linux下数学运算器:expr命令(shell中完成数学运算)
expr用法 expr命令一般用于整数值,但也可用于字符串.一般格式为: expr argument operator argument expr也是一个手工命令行计数器. $expr 10 ...
- 【Python】Shell MD5使用的那些事
MD5 应该是用的非常多的算法,就自己使用经验说说吧. 场景 算法层面不多说了,维基百科,还有很多文章都有说明. 主要用过的场景 密码存储,现在基本没怎么有使用的了,毕竟破解容易了很多 API校验,现 ...
- 【公开课】【阿里在线技术峰会】魏鹏:基于Java容器的多应用部署技术实践
对于公开课,可能目前用不上这些,但是往往能在以后想解决方案的时候帮助到我.以下是阿里对公开课的整理 摘要: 在首届阿里巴巴在线峰会上,阿里巴巴中间件技术部专家魏鹏为大家带来了题为<基于Java容 ...
- hive:(group by, having;order by)的使用;group by+多个字段,以及wiki说的group by两种使用限制验证
hive> select * from app_data_stats_historical where os='1' group by dt limit 100; 出现结果如下: 2014-01 ...
- InfiniDB 修改一行的效率?
InfiniDB引擎的DML速度比较慢,无论设置自动提交开关为关闭或开启,插入性能都很糟糕,但更新和删除的效率还可以,并且不支持truncate表操作. 删,改 效率高 插入,效率低(测试,在数据量稍 ...
- SpriteBuilder中时间线播放音效的弊端
当你美滋滋的在时间线中播放音效的时候,你要想到音效时间线并不适于播放同步于游戏事件的声音,比如碰撞和加速时. 它同样不能被用来播放背景循环的声音,这就本质上拒绝了通过timeline播放背景音乐.甚至 ...
- ANDROID 中设计模式的采用--行为模式
1 职责链模式 职责链模式的意图为:使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系.将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止.使多个对象都有 ...
- 事件/委托机制(event/delegate)(Unity3D开发之十七)
猴子原创,欢迎转载.转载请注明: 转载自Cocos2Der-CSDN,谢谢! 原文地址: http://blog.csdn.net/cocos2der/article/details/46539433 ...