ambari安装集群下安装kafka manager
简介:
不想通过kafka shell来管理kafka已创建的topic信息,想通过管理页面来统一管理和查看kafka集群。所以选择了大部分人使用的kafka manager,我一共有一台主机master和三台节点slave1,slave2,slave3,一共有三个zookeeper server和三个kafka broker,分别在master,slave1,slave2。所以我把kafka manager安装在了slave3的服务器上面。
一、启动kafka的JMX端口的访问
至于JMX是什么,可以自己百度一下。启动JMX主要是为了kafka manger可以通过JMX端口来监听kafka的状态等。kafka启动的时候是没有启动JMX的,所以需要去修改kafka的启动脚本,来使kafka启动的时候启动JMX。
[root@master ~]# cd /usr/hdp/current/kafka-broker/bin/
[root@master ~]# vi kafka-server-start.sh
#添加下面标红的代码到指定位置
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
export JMX_PORT=""
fi
上面的操作需要在三台kafka集群上都要操作,修改完以后通过页面,重启所有的kafka集群。然后再到master,slave1,slave2上查看9999端口是否启用
[root@master bin]# lsof -i:9999
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 55123 kafka 90u IPv6 76911524 0t0 TCP *:distinct (LISTEN)
二、安装kafka manager
1、安装sbt编译环境
[root@master ~]# curl https://bintray.com/sbt/rpm/rpm |tee /etc/yum.repos.d/bintray-sbt-rpm.repo
[root@master ~]# yum install sbt
2、下载kafka-manager
访问网址https://github.com/yahoo/kafka-manager/releases下载最新版的kafka-manager,然后解压、编译。
[root@slave3 ~]# cd kafka-manager-1.3.3.17
[root@slave3 kafka-manager-1.3.3.17]# sbt clean dist
编译完以后,生成的包会在kafka-manager/target/universal 下面。生成的包只需要java环境就可以运行了,在部署的机器上不需要安装sbt。
3、复制编译好的压缩包,在需要部署的kafka机器上解压即可
[root@slave3 kafka-manager-1.3.3.17]# cp target/universal/kafka-manager-1.3.3.17.zip /usr/hdp/2.6.3.0-235/
[root@slave3 kafka-manager-1.3.3.17]# cd /usr/hdp/2.6.3.0-235/
[root@slave3 2.6.3.0-235]# unzip kafka-manager-1.3.3.17.zip
4、修改application.conf,把kafka-manager.zkhosts改为自己的zookeeper服务器地址
[root@slave3 2.6.3.0-235]# cd kafka-manager-1.3.3.17
[root@slave3 kafka-manager-1.3.3.17]# vi conf/application.conf
#修改的代码
kafka-manager.zkhosts="master:2181,slave1:2181,slave2:2181"
5、启动
[root@slave3 kafka-manager-1.3.3.17]# nohup bin/kafka-manager -Dconfig.file=conf/application.conf &
默认http端口是9000,可以通过命令行参数传递:./kafka-manager -Dhttp.port=9001
6、访问
访问地址 http://slave3:9000
创建kafka集群的名称,点击Add Cluster来进行创建,cluster name为kafka集群的别名自定义,zookeeper hosts填写master:2181,slave1:2181,slave2:2181。kafka version选择ambari版本里面相应的kafka版本。勾选具体配置是除开JMX with SSL不勾选,其余的全部勾选。
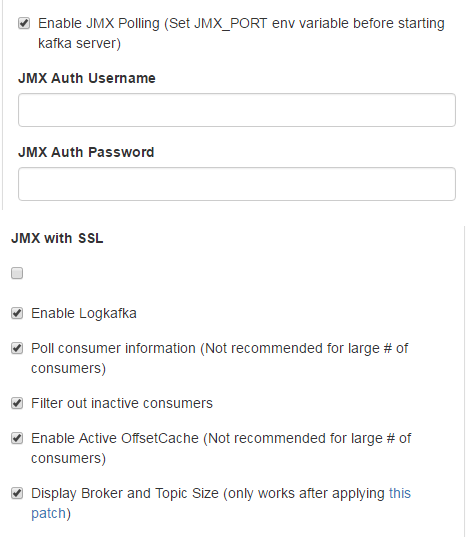
然后点击save就可以了。
7、在kafka manager里面删除topic的时候发现删除不了,但是topic的名称变成了红色。然后我修改了ambari里面kafka的delete.topic.enable的参数为true。然后就可以正常的删除topic了。至于刚才的还是红色test已经没法删除了,参考 https://blog.csdn.net/fengzheku/article/details/50585972 来对zookeeper上面的数据进行删除就可以了。
ambari安装集群下安装kafka manager的更多相关文章
- ambari安装集群下python连接hbase之安装thrift
简介: python连接hbase是需要通过thrift连进行连接的,ambari安装的服务中貌似没有自带安装hbase的thrift,我是看配置hbase的配置名称里面没有thrift,cdh版本的 ...
- 给ambari集群里的kafka安装基于web的kafka管理工具Kafka-manager(图文详解)
不多说,直接上干货! 参考博客 基于Web的Kafka管理器工具之Kafka-manager的编译部署详细安装 (支持kafka0.8.0.9和0.10以后版本)(图文详解)(默认端口或任意自定义端口 ...
- 一脸懵逼学习KafKa集群的安装搭建--(一种高吞吐量的分布式发布订阅消息系统)
kafka的前言知识: :Kafka是什么? 在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算.kafka是一个生产-消费模型. Producer:生产者,只负责数 ...
- Cloudera Manager 安装集群遇到的坑
Cloudera Manager 安装集群遇到的坑 多次安装集群,但每次都不能顺利,都会遇到很多很多的坑,今天就过去踩过的坑简单的总结一下,希望已经踩了的和正在踩的童鞋能够借鉴一下,希望对你们能有所帮 ...
- 给Ambari集群里安装可视化分析利器工具Hue步骤(图文详解)
扩展博客 以下,是我在手动的CDH版本平台下,安装Hue. CDH版本大数据集群下搭建Hue(hadoop-2.6.0-cdh5.5.4.gz + hue-3.9.0-cdh5.5.4.tar.gz) ...
- 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
不多说,直接上干货! Impala和Hive的关系(详解) 扩展博客 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解) 参考 horton ...
- (转)linux下weblogic12c集群的安装部署
本文介绍linux下weblogic12c集群的安装部署,版本12c,其他版本操作会有所不同,但其大体操作基本都是一样的 关于weblogic的集群,在此就不多做介绍了,如果有不了解的朋友可以百度搜索 ...
- VMware下Hadoop 2.4.1完全分布式集群平台安装与设置
1 VM下Ubuntu安装和配置 1.1 安装Ubuntu系统 这个就不说了,不知道的可以去看看其他的博文. 1.2 集群配置 搭建一个由3台机器组成的集群: IP user/passw ...
- Hadoop集群分布式安装
一 整体介绍 1.1 硬件环境 本文使用三台服务器搭建hadoop集群,使用Centos7.5系统,服务器均有独立ip 1.2 部署的软件 部署服务:namenode(HA),resourcemana ...
随机推荐
- Android启动过程分析
Android系统启动过程 首先看一张Android框架结构图 Linux内核启动之后就到Android Init进程,进而启动Android相关的服务和应用. 启动的过程如下图所示:(图片来自网上, ...
- Unity UGUI图文混排源码(二)
Unity UGUI图文混排源码(一):http://blog.csdn.net/qq992817263/article/details/51112304 Unity UGUI图文混排源码(二):ht ...
- (四十一)数据持久化的NSCoding实现 -实现普通对象的存取
NSCoding可以用与存取一般的类对象,需要类成为NSCoding的代理,并且实现编码和解码方法. 假设类Person有name和age两个属性,应该这样设置类: .h文件: #import < ...
- 网站开发进阶(三十二)HTML5之FileReader的使用
HTML5之FileReader的使用 HTML5定义了FileReader作为文件API的重要成员用于读取文件,根据W3C的定义,FileReader接口提供了读取文件的方法和包含读取结果的事件模型 ...
- Unity热更新之C#反射加载程序集
用C#反射加载程序集的方式可以动态的从assetBundle资源包或其他资源包里加载脚本到工程中,即便是原工程中不存在的脚本. 我这里就用加载本地assetBundle的方式来进行讲解了,加载网络上的 ...
- 理解WebKit和Chromium:Chromium资源磁盘缓存
转载请注明原文地址:http://blog.csdn.net/milado_nju ## 概述 想象一下,如果没有磁盘缓存的世界.当用户访问网页的时候,每次浏览器都需要从网站下载网页,图片,JS等资源 ...
- kettle简介(整体架构,运行方式,使用方法)
项目负责人Matt的说法:把各种数据放到一个壶里,然后呢,以一种你希望的格式流出.呵呵,外国人都很有联想力.看了提供的文档,然后对发布程序的简单试用后,可以很清楚得看到Kettle的四大块: Chef ...
- 开源框架VTMagic的使用介绍
VTMagic 有很多开发者曾尝试模仿写出类似网易.腾讯等应用的菜单分页组件,但遍观其设计,大多都比较粗糙,不利于后续维护和扩展.琢磨良久,最终决定开源这个耗时近两年打磨而成的框架,以便大家可以快速实 ...
- 修改Tomcat访问的端口号
修改Tomcat端口号步骤: 1.找到Tomcat目录下的conf文件夹 2.进入conf文件夹里面找到server.xml文件 3.打开server.xml文件 4.在server.xml文件里面找 ...
- iOS监听模式系列之NSNotificationCenter的简单使用
NSNotificationCenter 对于这个没必要多说,就是一个消息通知机制,类似广播.观察者只需要向消息中心注册感兴趣的东西,当有地方发出这个消息的时候,通知中心会发送给注册这个消息的对象.这 ...