SQL Server 一列或多列重复数据的查询,删除(转载)
业务需求
最近给公司做一个小工具,把某个数据库(数据源)的数据导进另一个数据(目标数据库)。要求导入目标数据库的数据不能出现重复。但情况是数据源本身就有重复的数据。所以要先清除数据源数据。
于是就把关于重复数据的查询和处理总结一下。这里只可虑基于数据库解决方案。不考虑程序的实现。
环境为:SQL Server 2008
基于数据库的解决方案
数据库测试表dbo.Member
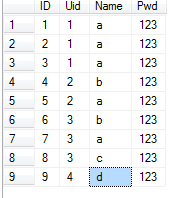
一、单列重复
一,带有having条件的分组查询方法
(1)查询某一列重复记录
语句:
SELECT Name FROM dbo.Member t WHERE Name IN (SELECT Name FROM dbo.Member GROUP BY Name HAVING COUNT(Name)>1 ) ORDER BY t.Name
查询结果:

(2)查询某一列不重复的记录
语句:
SELECT * FROM dbo.Member WHERE ID IN (SELECT MIN(ID) FROM dbo.Member GROUP BY Name)
查询结果:
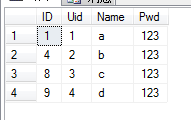
(3)清除某一列重复的数据
语句:
DELETE FROM dbo.Member WHERE ID NOT IN (SELECT MIN(ID) FROM dbo.Member GROUP BY Name)
执行结果:
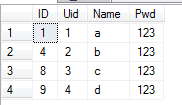
解释:上面的例子只保存了各自Name的最小值。
二,DISTINCT 的用法
温馨提醒:
不支持多列统计
Oracle和DB2数据库也适用
利用distinct关键字返回唯一不同的值
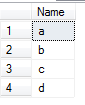
(1)查询某一列不重复数据
语句:
SELECT DISTINCT Name FROM dbo.Member
结果集:
(2)DISTINCT 查询多列不重复(如果查询的列有任何一个不重复,则这条记录视为不重复)
语句:
SELECT DISTINCT Name,Uid FROM dbo.Member
查询结果

DISTINCT 用于统计 语句
SELECT COUNT(DISTINCT(Name)) FROM dbo.Member
二、多列重复
数据表结构
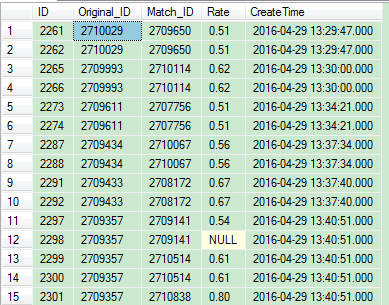
查找Original_ID和Match_ID这两列值重复的行
SQL语句
SELECT m.* FROM dbo.Match m,(
SELECT Original_ID,Match_ID
FROM dbo.Match
GROUP BY Original_ID,Match_ID
HAVING COUNT(1)>1
) AS m1
WHERE m.Original_ID=m1.Original_ID AND m.Match_ID=m1.Match_ID
查询结果

SQL Server 一列或多列重复数据的查询,删除(转载)的更多相关文章
- SQL Server使用 LEFT JOIN ON LIKE进行数据关联查询
这是来新公司写的第一篇文章,使用LEFT JOIN ON LIKE处理一下这种问题: SQL视图代码如下: CREATE View [dbo].[VI_SearchCN] AS --搜索产品的文件 ( ...
- SQL Server 一列或多列重复数据的查询,删除
业务需求 最近给公司做一个小工具,把某个数据库(数据源)的数据导进另一个数据(目标数据库).要求导入目标数据库的数据不能出现重复.但情况是数据源本身就有重复的数据.所以要先清除数据源数据. 于是就把关 ...
- 关于SQL Server数据库中的标识列
一.标识列的定义以及特点 SQL Server中的标识列又称标识符列,习惯上又叫自增列. 该种列具有以下三种特点: 1.列的数据类型为不带小数的数值类型 2.在进行插入(Insert)操作时,该列的值 ...
- SQL Server如何在变长列上存储索引
这篇文章我想谈下SQL Server如何在变长列上存储索引.首先我们创建一个包含变长列的表,在上面定义主键,即在上面定义了聚集索引,然后往里面插入80000条记录: -- Create a new t ...
- SQL Server缺省约束、列约束和表约束
SQL Server缺省约束是SQL Server数据库中的一种约束,下面就为您介绍SQL Server缺省约束.列约束和表约束的定义方法啊,供您参考. SQL Server缺省约束 SQL Serv ...
- SQL Server中Id自增列的最大Id是多少
什么是自增列 在SQL Server中可以将Id列设为自增.即无需为Id指定值,由SQL Server自动给该列赋值,每新增一列Id的值加一,初始值为1. 需要注意的是即使将原先添加的所有数据都删除, ...
- 浅析SQL Server数据库中的伪列以及伪列的含义
SQL Server中的伪列 下午看QQ群有人在讨论(非聚集)索引的存储,说,对于聚集索引表,非聚集索引存储的是索引键值+聚集索引键值:对于非聚集索引表,索引存储的是索引键值+RowId,这应该是一个 ...
- SQL Server 2016新特性:列存储索引新特性
SQL Server 2016新特性:列存储索引新特性 行存储表可以有一个可更新的列存储索引,之前非聚集的列存储索引是只读的. 非聚集的列存储索引支持筛选条件. 在内存优化表中可以有一个列存储索引,可 ...
- Sql Server中判断表、列不存在则创建的方法[转]
一.Sql Server中如何判断表中某列是否存在 首先跟大家分享Sql Server中判断表中某列是否存在的两个方法,方法示例如下: 比如说要判断表A中的字段C是否存在两个方法: 第一种方法 ? ...
随机推荐
- esxi存储(外部共享存储)
vSphere 基础物理架构中存储是一个非常关键的部分,没有好的存储,虚拟化也就没有存在的价值,并且它能够决定其系统性能的高低和如vMotion等高级功能能否实现.所以本次重点介绍vSphere中的存 ...
- Vue学习小结(二)
接上一批,小结(二). 三.导航内容(含左侧导航及顶部面包屑导航) 其实导航条主要根据element-ui的教程进行编写,官网:http://element-ui.cn/#/zh-CN/compone ...
- 越来越火的"中台"是什么
很多企业都将促进业务与科技的深度融合作为发展战略,也都想学学阿里的中台战略,其实,除了中台战略之外,基于企业级业务架构设计来实现组件化开发也是企业数字化转型的优选路径,是弥合业务与技术之间“数字鸿沟” ...
- 带着新人看java虚拟机05(多线程篇)
上一篇我们主要是把一些基本概念给说了一下以及怎么简单的使用线程池,我们这一节就来看看线程池的实现: 1.线程池基本参数 以Executors.newFixedThreadPool()这种创建方式为例: ...
- SpringBoot从零单排 ------初级入门篇
有人说SSM已死,未来是SpringBoot和SpringCloud的天下,这个观点可能有点极端,但不可否认的是已经越来越多的公司开始使用SpringBoot.所以我将平时学习SpringBoot的内 ...
- SpringCloud学习系列之二 ----- 服务消费者(Feign)和负载均衡(Ribbon)使用详解
前言 本篇主要介绍的是SpringCloud中的服务消费者(Feign)和负载均衡(Ribbon)功能的实现以及使用Feign结合Ribbon实现负载均衡. SpringCloud Feign Fei ...
- python全栈目录
Python Python开发[第一篇]:初识 Python开发[第二篇]:基本数据类型 Python开发[第三篇]:函数 Python开发[第四篇]:杂货铺 Python开发[第五篇]:模块 Pyt ...
- 《SQL CookBook 》笔记-准备工作
目录 准备 1.建立员工表--EMP 2.建立部门表--DEPT 3.EMP表和DEPT表插入数据 4.建立透视表T1,并插入数据 5.建立透视表T10,并插入数据 第二章 shanzm 准备 1.建 ...
- MYSQL 主从复制,读写分离(8)
Mysql 数据库的主从复制方案,是其自带的功能,并且主从复制并不是复制磁盘上的数据文件,而是通过binlog日志复制到需要同步的服务器上. 一 主从复制的原理实现 原理图解说: 数据库更改 生成数据 ...
- HDP 2.6 requires libtirpc-devel
HDP 2.6 requires libtirpc-devel 个问题,截止 Mustafa Kemal MAYUK 2017年06月30日 06:30 hadoopPowerSystems Hell ...