Day4 《机器学习》第四章学习笔记
决策树
前几天学习了《机器学习》的前三章,前三章介绍机器学习的基础知识,接下来,第四章到第十章介绍一些经典而常用的机器学习方法,这部分算是具体的应用篇,第四章介绍了一类机器学习方法——决策树。
3.1 基本流程
决策树(decision tree)是一类常见的机器学习方法。以二分类任务为例,我们希望从给定训练数据集学得一个模型用以对新示例进行分类,这个把样本分类的任务,可看作对“当前样本属于正类嘛?”这个问题的“决策”或“判定”过程。顾名思义,决策树,就是基于树结构来进行决策的。例如我们对一个好西瓜的判定过程,如下图:
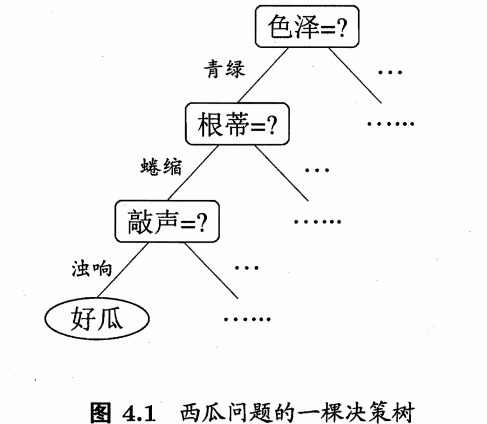
显然,决策的最终结论是我们的判断结果:“是”或者“不是”好瓜。一般的,1、一颗决策树包含一个根结点、若干个内部结点和若干个叶结点;2、叶结点对应决策结果,其他每个结点则对应一个属性测试;3、每个结点包含的样本集合根据属性测试的结果被划分到子结点中;4、根结点包含样本全集。 从根结点到每个叶结点的路径对应了一个判定测试序列。决策树学习,目的是产生一棵泛化能力强,即处理未见示例能力强的决策树,其基本流程遵循简单且直观的“分而治之(divide-and-conquer)”策略,算法如下:

显然,决策树的生成是一个递归过程。决策树算法中,有三种情形会导致递归返回:(1)当前结点包含的样本全属于同一类别,无需划分;(2)当前属性集为空,或者所有样本在所有属性上取值相同,无法划分;(3)当前结点包含样本集合为空,不能划分。(在第(2)中情形下,把当前结点标记为叶结点,并将其类别设定为该结点所含样本最多的类别;在第(3)中情形下,同样把当前结点标记为叶结点,但将其类别设定为父结点所含样本最多的类别。这两种情形处理的实质是不同的,(2)是在利用当前结点的后验分布,而(3)则把父结点的样本分布作为当前结点的先验分布。)
4.2 划分选择
有算法流程看出,决策树学习关键在第8行,即如何选择最优划分属性,一般而言,随着划分过程进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的“纯度(purity)”越来越高。
4.2.1 信息增益
“信息熵(information entropy)”是度量样本集合纯度最常用的一种指标。我们假定当前样本集合D中第k类样本所占的比例为pk(k=1,2,…,|y|),则D的信息熵定义为:
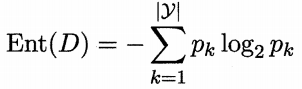
Ent(D)的值越小,D的纯度越高(理想情况就是Ent(D)的值小到0,相当于pk=1,这样的话D中样本就全属于同一类)
假定离散属性a有V个可能的取值{a1, a2, …, aV},若使用a来样本集D进行划分,则产生V个分支结点,其中v个分支结点包含D中所有在属性a上取值为aV的样本。根据信息熵定义式计算出Dv的信息熵,在考虑到不同的分支结点的样本数不同,给分支结点赋予权重|Dv|/|D|,即样本数越多的分支结点的影响越大,于是可计算出用属性a对样本集D进行划分所取得的“信息增益(information gain)”:
所以,信息增益越大,则意味着使用属性a来进行划分所获得的“纯度提升”越大,因此,我们可用信息增益来进行决策树的划分属性选择,即在算法流程4.2图中第8行选择属性 。著名的ID3(Iterative Dichotomiser迭代二分器)决策树学习算法[Quinlan, 1986]就是以信息增益为准则来选择划分属性的。
。著名的ID3(Iterative Dichotomiser迭代二分器)决策树学习算法[Quinlan, 1986]就是以信息增益为准则来选择划分属性的。
以表4.1中的西瓜数据集2.0为例:

该数据集包含17个训练样例,用以学习一棵能够预测没剥开的是不是好瓜的决策树。显然,|y| = 2。在决策树学习开始时,根结点包含D中的所有样例,其中正例占p1 = 8/17 ,反例占p2 = 9/17。于是,根据信息熵定义式计算出根结点的信息熵为:
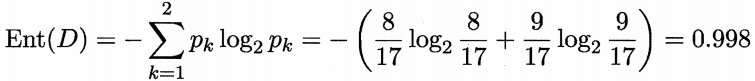
然后我们计算出当前属性集合{色泽,根蒂,敲声,纹理,脐部,触感}中每个属性的信息增益。以属性“色泽”为例,他有三个可能的取值:{青绿,乌黑,浅白}。若使用该属性对D进行划分,这可以划分为三个子集,分别记为:D1(色泽=青绿),D2(色泽=乌黑),D3(色泽=浅白)。子集D1包含编号{1,4,6,10,13,17}的样例,其中正例占p1 = 3/6 ,反例占p2 = 3/6,同理写出D2、D3的样例编号,计算出对应正例,反例比例,就可以根据信息熵定义式算出用“色泽”划分之后所得到的3个分支结点的信息熵:

根据信息增益计算式算出各属性信息增益:
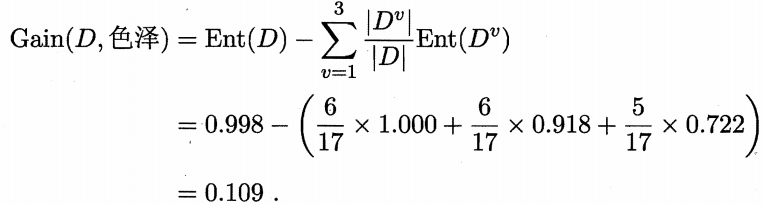
类似的我们可以计算出其他属性的信息增益:

显然,属性“纹理”的信息熵最大,于是它被选为划分属性。基于“纹理”对根结点进行划分,进而继续算出其他各属性信息增益:

可看出,“根蒂”、“脐部”、“触感”3个属性均取得了最大的信息增益,可任意选其中一个最为下一步划分属性,类似的,对每个分子结点进行上述操作,最终得到决策树如图4.4所示: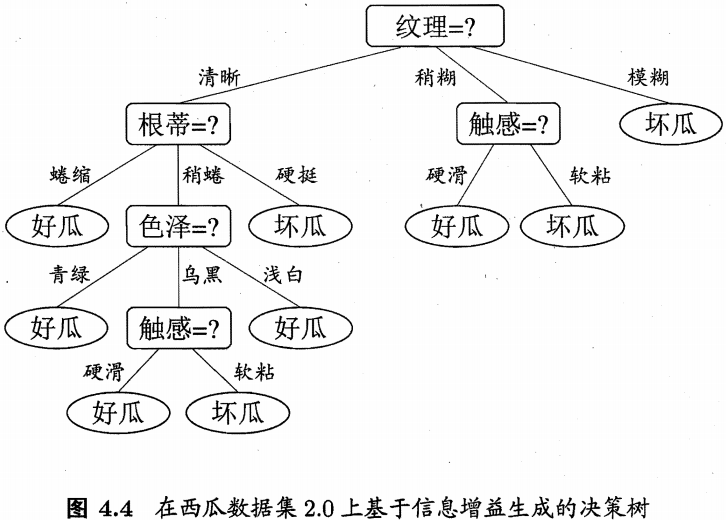
4.2.2 增益率
在上面的划分中吗,我们没有将“编号”这一栏作为划分属性,如果以编号作为属性划分样本,将产生17个分支,每个分支结点仅含一个样本,分支结点的纯度最大。然而,这样决策树显然不具有泛化能力,无法对新样本进行有效预测。
实际上,信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,著名的C4.5决策树算法[Quinlan, 1993]不直接使用信息增益,而是使用“增益率(gain ratio)”来选择最优划分属性,增益率定义为:
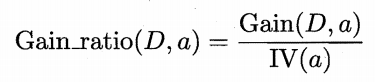
其中
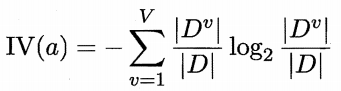
称为属性a的“固有值(intrinsic value)”[Quinlan, 1993].属性a的可能取值数目越多(即V越大),则IV(a)的值越大。
需注意的是,增益率准则对可取值数目较少的属性有所偏好,因此,C4.5算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式[Quinlan, 1993]:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
4.2.3 基尼指数
CART(Classification and Rgression Tree)决策树[Breiman et al. , 1984]使用“基尼指数(Gini index)”来选择划分属性,与4.1采用相同的符号,数据集D的纯度可用基尼值来度量: Gini(D)反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率,因此,Gini(D)越小,则数据集D的纯度越高。属性a的基尼指数定义为:
Gini(D)反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率,因此,Gini(D)越小,则数据集D的纯度越高。属性a的基尼指数定义为:
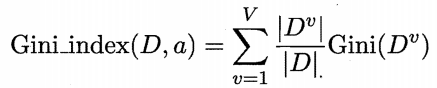
于是,我们在候选属性集合A中,选择那个使得划分后基尼指数最小的属性作为最优划分属性,即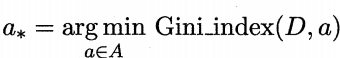
4.3 剪枝处理
剪枝(pruning)是决策树学习算法对付“过拟合”的主要手段。在决策树学习中,为了尽可能正确分类训练样本,结点划分过程将不断重复,有时会造成决策树分支过多,这时就可能因为训练样本学得“太好了”,以至于把训练样本集自身的一些特点当作所有数据都具有的一般性质而导致过拟合,因此,可通过主动去掉一些分支来降低过拟合的风险。
决策树剪枝的基本策略有“预剪枝(prepruning)”和“后剪枝(post-pruning)”[Quinlan, 1993]
4.3.1 预剪枝
4.3.2 后剪枝
4.4 连续与缺失值
4.4.1 连续值处理
4.4.2 缺失值处理
4.5 多变量决策树
(未完待续)
Day4 《机器学习》第四章学习笔记的更多相关文章
- 《Linux内核设计与实现》第四章学习笔记
<Linux内核设计与实现>第四章学习笔记 ——进程调度 姓名:王玮怡 学号:20135116 一.多任务 1.多任务操作系统的含义 多任务操作系统就是能同时并发地交 ...
- 《Linux内核设计与实现》第四章学习笔记——进程调度
<Linux内核设计与实现>第四章学习笔记——进程调 ...
- Spring实战第四章学习笔记————面向切面的Spring
Spring实战第四章学习笔记----面向切面的Spring 什么是面向切面的编程 我们把影响应用多处的功能描述为横切关注点.比如安全就是一个横切关注点,应用中许多方法都会涉及安全规则.而切面可以帮我 ...
- 《Linux命令行与shell脚本编程大全》 第十四章 学习笔记
第十四章:呈现数据 理解输入与输出 标准文件描述符 文件描述符 缩写 描述 0 STDIN 标准输入 1 STDOUT 标准输出 2 STDERR 标准错误 1.STDIN 代表标准输入.对于终端界面 ...
- Day2 《机器学习》第二章学习笔记
这一章应该算是比价了理论的一章,我有些概率论基础,不过起初有些地方还是没看多大懂.其中有些公式的定义和模型误差的推导应该还是很眼熟的,就是之前在概率论课上提过的,不过有些模糊了,当时课上学得比较浅. ...
- Day1 《机器学习》第一章学习笔记
<机器学习>这本书算是很好的一本了解机器学习知识的一本入门书籍吧,是南京大学周志华老师所著的鸿篇大作,很早就听闻周老师大名了,算是国内机器学习领域少数的大牛了吧,刚好研究生做这个方向相关的 ...
- Mudo C++网络库第四章学习笔记
C++多线程系统编程精要 学习多线程编程面临的最大思维方式的转变有两点: 当前线程可能被切换出去, 或者说被抢占(preempt)了; 多线程程序中事件的发生顺序不再有全局统一的先后关系; 当线程被切 ...
- Scala第四章学习笔记(面向对象编程)
延迟构造 DelayedInit特质是为编译器提供的标记性的特质.整个构造器被包装成一个函数并传递给delayedInit方法. trait DelayedInit { def deayedInit( ...
- 4类Storage方案(AS开发实战第四章学习笔记)
4.1 共享参数SharedPreferences SharedPreferences按照key-value对的方式把数据保存在配置文件中,该配置文件符合XML规范,文件路径是/data/data/应 ...
随机推荐
- FPGrowth
在挖掘关联规则的过程中,无可避免要处理海量的数据,也就是事务数据库如此之大,如果采用Apriori算法来挖掘,每次生成频繁k-项集的时候,可能都需要扫描事务数据库一遍,这是非常耗时的操作.那么,可以想 ...
- 如何设计一个可用的web容器
之前在另外一个平台(http://www.jointforce.com/jfperiodical/article/1035)发表的一篇文章,现在发布到自己的博客上. 开发一个web容器涉及很多不同方面 ...
- 【Android 应用开发】BluetoothServerSocket详解
一. BluetoorhServerSocket简介 1. 继承关系 public final class BluetoothServerSocket extends Object implement ...
- ionic1 打包过程 常用命令行
ionic start myapp myapp是项目名字 ionic start myapp --v2 ...
- Spring Boot 添加jersey-mvc-freemarker依赖后内置tomcat启动不了解决方案
我在我的Spring Boot 项目的pom.xml中添加了jersey-mvc-freemarker依赖后,内置tomcat启动不了. 报错信息如下: org.springframework.con ...
- 解读Raft(四 成员变更)
将成员变更纳入到算法中是Raft易于应用到实践中的关键,相对于Paxos,它给出了明确的变更过程(实践的基础,任何现实的系统中都会遇到因为硬件故障等原因引起的节点变更的操作). 显然,我们可以通过sh ...
- win8 JDK环境变量不生效
执行where java 看一下路径对不对,如果对的话就把system32下面的3个java相关的exe删了即可,如果路径不对就修改环境变量.
- centos 5.3 安装(samba 3.4.4)
centos 5.3 安装(samba 3.4.4) 博客分类: 操作系统 Linux 随着Linux的普及,如何共享Linux下的文件成为用户关心的问题.其实,几乎所有的Linux发行套件都提供 ...
- Ubuntu 18.04 启动root账号并授权远程登录
Ubuntu 18.04 刚刚上市2个月,下载安装,尝尝鲜~ 安装界面看上去舒服许多, 安装的速度也较之前17.04 和16.04 都快了许多.抱歉,未截图. Ubuntu 安装完成后默认不启动roo ...
- mysql安装与配置(以mysql-5.7.10-winx64为例)
一.在官网上下载相应的mysql安装包,本人下载的是:mysql-5.7.10-winx64 (Windows (x86, 64-bit), ZIP Archive) 附下载地址:http://dev ...