Python:黑板课爬虫闯关第五关
第五关是最后一关了,至此之后黑板课就没有更新过关卡了。
第五关地址:http://www.heibanke.com/lesson/crawler_ex04/
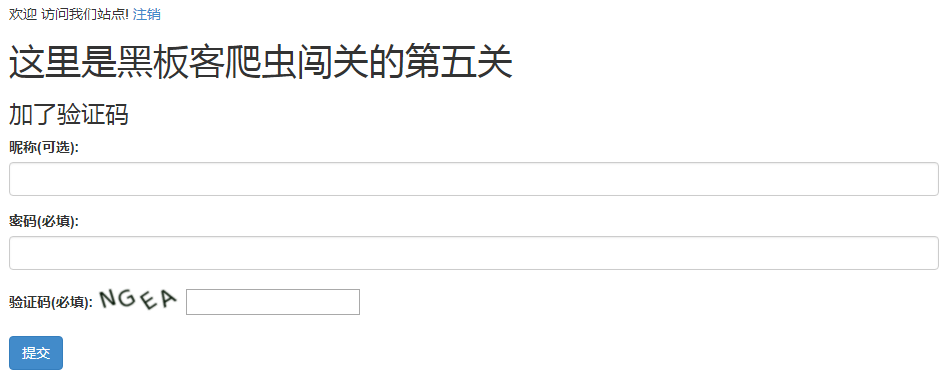
可以看到,是在第三关的基础上加了验证码。
验证码识别我们可以通过 tesserocr 来识别,tesserocr 的使用在我的前面两篇博客中有介绍。
在这里,tesserocr 的识别率不是很高,大概只有10%到15%,通过训练,也没能有啥改善,不知道是不是我弄错了,有尝试过的朋友可以给我留言。
代码如下:
import re
import requests
import time
from PIL import Image
from bs4 import BeautifulSoup
import tesserocr def main():
url_login = 'http://www.heibanke.com/accounts/login/'
url = 'http://www.heibanke.com/lesson/crawler_ex04/'
session = requests.Session()
session.get(url_login)
token = session.cookies['csrftoken']
session.post(url_login, data={'csrfmiddlewaretoken': token, 'username': 'xx', 'password': 'xx'})
psd = 0
while psd < 30:
print(f'test password {psd}')
r = session.get(url)
soup = BeautifulSoup(r.text, 'lxml')
img_tag = soup.find('img')
img_url = 'http://www.heibanke.com' + img_tag['src']
requests.get(url)
code = get_code(img_url)
if code is None:
time.sleep(1)
continue
token = session.cookies['csrftoken']
r = session.post(url, data={'csrfmiddlewaretoken': token, 'username': 'aa', 'password': psd,
'captcha_0': code[0], 'captcha_1': code[1]})
html = r.text
if '验证码输入错误' in html:
time.sleep(1)
elif '密码错误' not in html:
m = re.search('(?<=\<h3\>).*?(?=\</h3\>)', html)
print(m.group())
return
else:
time.sleep(1)
psd += 1 def get_code(url):
flag = url.split("/")[-2]
fn = flag + '.png'
with open(fn, 'wb+') as sw:
sw.write(requests.get(url).content) img = Image.open(fn)
img = img.convert('L')
result = tesserocr.image_to_text(img).strip()
print(flag, result)
if re.match('^[A-Za-z0-9]{4}$', result):
return flag, result if __name__ == '__main__':
main()
Python:黑板课爬虫闯关第五关的更多相关文章
- Python:黑板课爬虫闯关第一关
近日发现了[黑板课爬虫闯关]这个神奇的网页,练手爬虫非常的合适 地址:http://www.heibanke.com/lesson/crawler_ex00/ 第一关非常的简单 get 请求网址,在响 ...
- Python:黑板课爬虫闯关第四关
第四关地址:http://www.heibanke.com/lesson/crawler_ex03/ 一开始看到的时候有点蒙,不知道啥意思,说密码需要找出来但也没说怎么找啊. 别急,随便输了个昵称和密 ...
- Python:黑板课爬虫闯关第三关
第三关开始才算是进入正题了. 输入网址 http://www.heibanke.com/lesson/crawler_ex02/,直接跳转到了 http://www.heibanke.com/acco ...
- Python:黑板课爬虫闯关第二关
第二关依然是非常的简单 地址:http://www.heibanke.com/lesson/crawler_ex01/ 随便输入昵称呢密码,点击提交,显示如下: 这样看来就很简单了,枚举密码循环 po ...
- python3 黑板客爬虫闯关游戏(一)
这是学习python爬虫练习很好的网站,强烈推荐! 地址http://www.heibanke.com/lesson/crawler_ex00/ 第一关猜数字 很简单,直接给出代码 import ur ...
- python3 黑板客爬虫闯关游戏(四)
这关较第三关难度增加许多,主要多了并发编程 密码一共有100位,分布在13页,每页打开的时间在15秒左右,所以理所当然的想到要用并发,但是后来发现同IP访问间隔时间不能小于8秒,不然会返回404,所以 ...
- python3 黑板客爬虫闯关游戏(三)
第三关,先登录,再猜密码,这关难度较第二关大幅增加,要先去注册一个登录账号,然后打开F12,多登录几次,观察headers数据的变化 给出代码,里面注释很详细 import urllib.reques ...
- python3 黑板客爬虫闯关游戏(二)
第二关猜登录密码,需要用到urllib.request和urllib.parse 也很简单,给代码 import urllib.request as ur import urllib.parse as ...
- 嵩天老师python网课爬虫实例1的问题和解决方法
一,AttributeError: 'NoneType' object has no attribute 'children', 网页'tbody'没有子类 很明显,报错的意思是说tbody下面没有c ...
随机推荐
- 深入理解springAOP切面的特性
一张图说明情况
- list control控件的一些操作
一.添加数据 这里介绍的是最平常的添加方法,当然也有很多其他比较好的方法.这里要非常注意添加顺序.先上代码: //导入excel文档中的内容到list中 CoInitialize(NULL); if ...
- BZOJ_3289_Mato的文件管理_莫队+树状数组
BZOJ_3289_Mato的文件管理_莫队+树状数组 Description Mato同学从各路神犇以各种方式(你们懂的)收集了许多资料,这些资料一共有n份,每份有一个大小和一个编号 .为了防止他人 ...
- 关于linux下部署JavaWeb项目,nginx负责静态资源访问,tomcat负责处理动态请求的nginx配置
1.项目的运行环境 linux版本 [root@localhost ~]# cat /proc/version Linux version -.el6.x86_64 (mockbuild@x86-.b ...
- laravel 分页和共多少条 加参数的分页链接
<div class="pagers "> <span class="fs pager">共 {{$trades->total() ...
- Dashboard二次开发简明教程
Horizon简介 Horizon是OpenStack的一个子项目,用于提供一个Web前端控制台(称为Dashboard),以此来展示OpenStack的功能.通常情况下,我们都是从Horizon.D ...
- openoffice转换pdf 异常问题查找处理 errorCode 525
could not save output document; OOo errorCode: 525 该问题是由于java程序和openoffice的启动所属用户不同导致.使用以下命令查看端口和进程 ...
- 亲测可用,iptables实现NAT转发。
环境 服务器A:192.168.1.7 服务器B: 192.168.1.160 需求 实现将本机(192.168.1.7:7410)端口流量转发给(192.168.1.160:9200). 1. 内核 ...
- UML用法及状态图,活动图介绍
统一建模语言UML(Unified Modeling Language)是非专利的第三代建模和规约语言.UML是一种开放的方法,用于说明.可视化.构建和编写一个正在开发的.面向对象的.软件密集系统的制 ...
- 微服务架构 - SpringBoot整合Jooq和Flyway
在一次学习分布式跟踪系统zipkin中,发现了jooq这个组件,当时不知这个组件是干嘛的,后来抽空学习了一下,感觉这个组件还挺用的.它主要有以下作用: 通过DSL(Domain Specific La ...