python爬站长之家写一个信息搜集器
前言:
不知道写什么好,绕来绕去还是写回爬虫这一块。
之前的都爬了一遍。这次爬点好用一点的网站。
0x01:
自行备好requests模块
目标站:http://tool.chinaz.com/
0x2:
代码:
import optparse
import requests
import re
import sys
from bs4 import BeautifulSoup
def main():
usage="[-z Subdomain mining]" \
"[-p Side of the station inquiries]" \
"[-x http status query]"
parser=optparse.OptionParser(usage)
parser.add_option('-z',dest="Subdomain",help="Subdomain mining")
parser.add_option('-p',dest='Side',help='Side of the station inquiries')
parser.add_option('-x',dest='http',help='http status query')
(options,args)=parser.parse_args()
if options.Subdomain:
subdomain=options.Subdomain
Subdomain(subdomain)
elif options.Side:
side=options.Side
Side(side)
elif options.http:
http=options.http
Http(http)
else:
parser.print_help()
sys.exit()
def Subdomain(subdomain):
print('-----------Subdomains quickly tap-----------')
url="http://m.tool.chinaz.com/subdomain/?domain={}".format(subdomain)
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r=requests.get(url,headers=header).content
g = re.finditer('<td>\D[a-zA-Z0-9][-a-zA-Z0-9]{0,62}\D(\.[a-zA-Z0-9]\D[-a-zA-Z0-9]{0,62})+\.?</td>', str(r))
for x in g:
lik="".join(str(x))
opg=BeautifulSoup(lik,'html.parser')
for link in opg.find_all('td'):
lops=link.get_text()
print(lops)
def Side(side):
print('--------Side of the station inquiries--------')
url="http://m.tool.chinaz.com/same/?s={}".format(side)
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r=requests.get(url,headers=header).content
g=r.decode('utf-8')
ksd=re.finditer('<a href=.*?>[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+\.?</a>',str(g))
for l in ksd:
ops="".join(str(l))
pods=BeautifulSoup(ops,'html.parser')
for xsd in pods.find_all('a'):
sde=re.findall('[a-zA-z]+://[^\s]*',str(xsd))
low="".join(sde)
print(low)
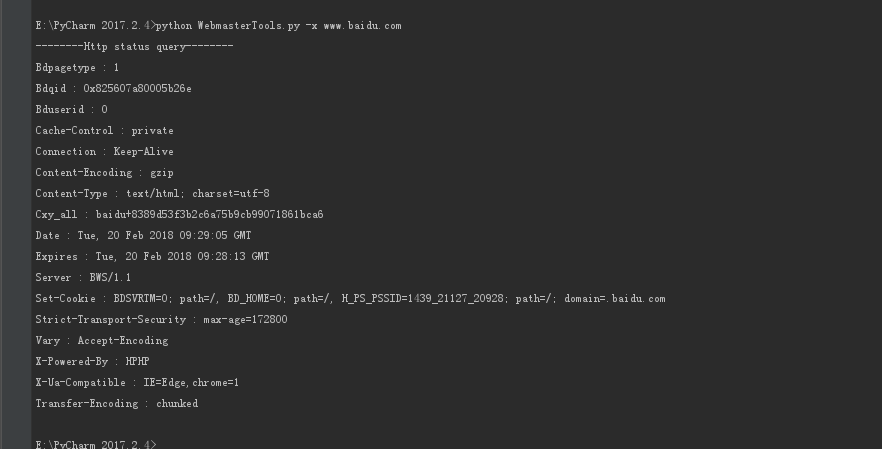
def Http(http):
print('--------Http status query--------')
url="http://{}".format(http)
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r=requests.get(url,headers=header)
b=r.headers
for sdw in b:
print(sdw,':',b[sdw])
if __name__ == '__main__':
main()
运行截图:
-h 帮助
-z 子域名挖掘
-p 旁站查询
-x http状态查询
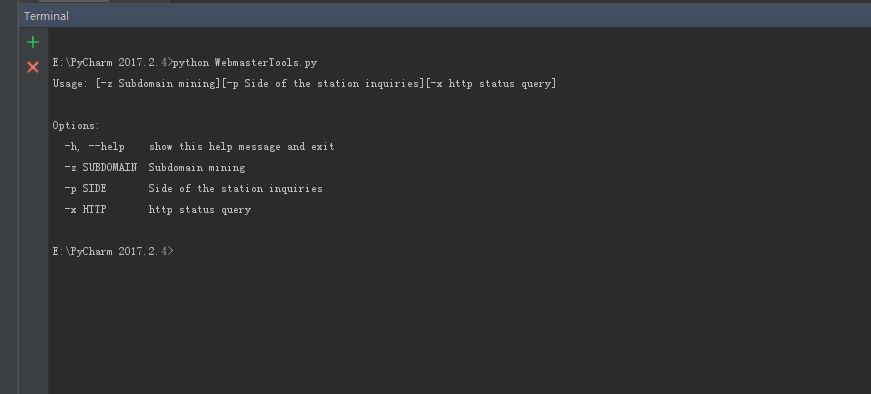
-z 截图
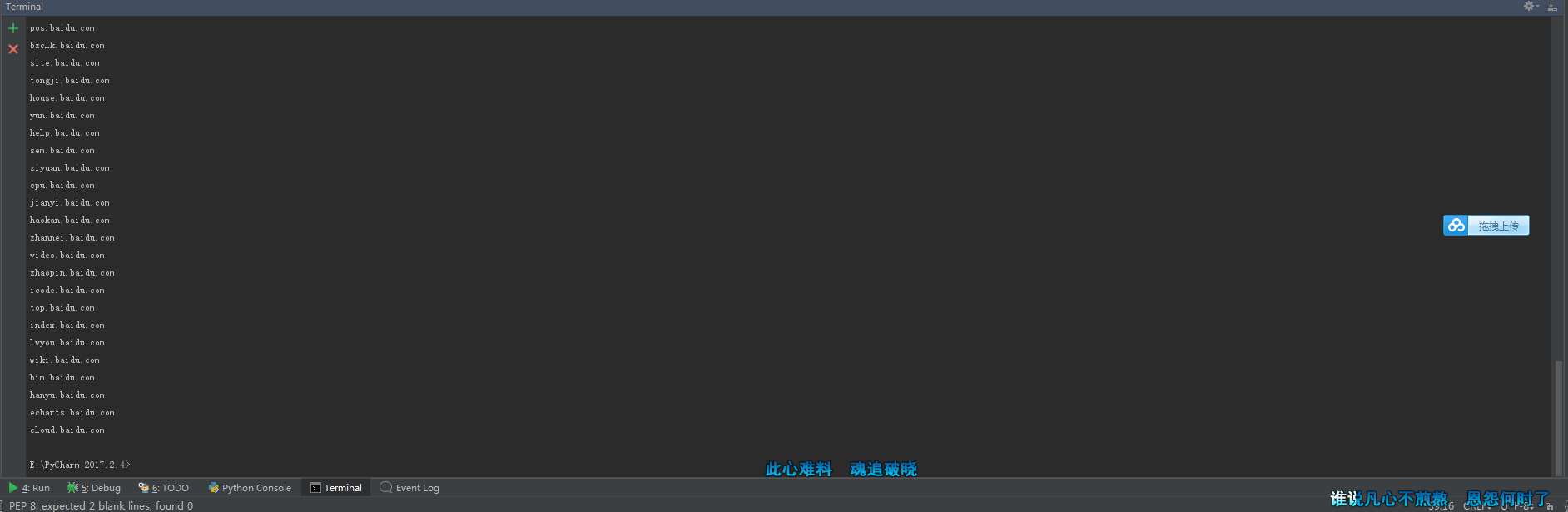
-p 截图

-x 截图
距离上学还有5天。啊啊啊啊啊啊啊啊啊啊啊
python爬站长之家写一个信息搜集器的更多相关文章
- 使用python爬取MedSci上的期刊信息
使用python爬取medsci上的期刊信息,通过设定条件,然后获取相应的期刊的的影响因子排名,期刊名称,英文全称和影响因子.主要过程如下: 首先,通过分析网站http://www.medsci.cn ...
- python爬取当当网的书籍信息并保存到csv文件
python爬取当当网的书籍信息并保存到csv文件 依赖的库: requests #用来获取页面内容 BeautifulSoup #opython3不能安装BeautifulSoup,但可以安装Bea ...
- python 拼写检查代码(怎样写一个拼写检查器)
原文:http://norvig.com/spell-correct.html 翻译:http://blog.youxu.info/spell-correct.html 怎样写一个拼写检查器 Pete ...
- Python+Flask+Gunicorn 项目实战(一) 从零开始,写一个Markdown解析器 —— 初体验
(一)前言 在开始学习之前,你需要确保你对Python, JavaScript, HTML, Markdown语法有非常基础的了解.项目的源码你可以在 https://github.com/zhu-y ...
- 用 EPWA 写一个 图片播放器 PicturePlayer
用 EPWA 写一个 图片播放器 PicturePlayer . 有关 EPWA,见 <我发起并创立了一个 EPWA 的 开源项目> https://www.cnblogs.com ...
- Python的scrapy之爬取链家网房价信息并保存到本地
因为有在北京租房的打算,于是上网浏览了一下链家网站的房价,想将他们爬取下来,并保存到本地. 先看链家网的源码..房价信息 都保存在 ul 下的li 里面 爬虫结构: 其中封装了一个数据库处理模 ...
- python写一个信息收集四大件的脚本
0x0前言: 带来一首小歌: 之前看了小迪老师讲的课,仔细做了些笔记 然后打算将其写成一个脚本. 0x01准备: requests模块 socket模块 optparser模块 time模块 0x02 ...
- Python爬取链家二手房源信息
爬取链家网站二手房房源信息,第一次做,仅供参考,要用scrapy. import scrapy,pypinyin,requests import bs4 from ..items import L ...
- 零基础爬虫----python爬取豆瓣电影top250的信息(转)
今天利用xpath写了一个小爬虫,比较适合一些爬虫新手来学习.话不多说,开始今天的正题,我会利用一个案例来介绍下xpath如何对网页进行解析的,以及如何对信息进行提取的. python环境:pytho ...
随机推荐
- cesium编程入门(六)添加 3D Tiles,并调整位置,贴地
添加 3D Tiles,并调整位置 3D Tiles 是什么 3DTiles数据集是cesium小组AnalyticlGraphics与2016年3月定义的一种数据集,3DTiles数据集以分块.分级 ...
- Android简介(一)
Android构架 Android的系统架构和其操作系统一样,采用了分层的架构.从架构图看,android分为四个层,从高层到低层分别是应用程序层.应用架构层.系统运行库层和Linux核心层. 1. ...
- [转载]织梦CMS首页调用分类信息栏目及列表方法
原文地址:织梦CMS首页调用分类信息栏目及列表方法作者:小武哥 不懂代码,搜索学习一晚上,都是说调用特定栏目分类信息列表的,用这个代码 {dede:arclistsg row='10' titlele ...
- HTML5 Audio/Video 标签,属性,方法,事件汇总 (转)
标签属性:src:音乐的URLpreload:预加载autoplay:自动播放loop:循环播放controls:浏览器自带的控制条 1 http://www.abc.com/test.mp3&quo ...
- Uva 1599 Ideal Path - 双向BFS
题目连接和描述以后再补 这题思路很简单但还真没少折腾,前后修改提交了七八次才AC...(也说明自己有多菜了).. 注意问题: 1.看清楚原题的输入输出要求,刚了书上的中文题目直接开撸,以为输入输出都是 ...
- 小白的Python之路 day5 hashlib模块
hashlib模块 一.概述 用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法 二.算法的演 ...
- android 基础03 -- Intent
Android 中的 Intent 是将要执行的操作的一种抽象的描述,是一个用于Android 各个组件之间传递消息的对象. Intent 的基本用法 Intent 基本的使用方法主要有三种: 启动一 ...
- java实现最小生成树的prim算法和kruskal算法
在边赋权图中,权值总和最小的生成树称为最小生成树.构造最小生成树有两种算法,分别是prim算法和kruskal算法.在边赋权图中,如下图所示: 在上述赋权图中,可以看到图的顶点编号和顶点之间邻接边的权 ...
- MyCat 启蒙:分布式系统的数据库架构演变
文章首发于[博客园-陈树义],点击跳转到原文<MyCat 启蒙:分布式系统的数据库架构演变> 单数据库架构 一个项目在初期的时候,为了尽可能快地验证市场,其对业务系统的最大要求是快速实现. ...
- Spring Cloud Zuul网关 Filter、熔断、重试、高可用的使用方式。
时间过的很快,写springcloud(十):服务网关zuul初级篇还在半年前,现在已经是2018年了,我们继续探讨Zuul更高级的使用方式. 上篇文章主要介绍了Zuul网关使用模式,以及自动转发机制 ...