第十四章——循环神经网络(Recurrent Neural Networks)(第二部分)
本章共两部分,这是第二部分:
第十四章——循环神经网络(Recurrent Neural Networks)(第一部分)
第十四章——循环神经网络(Recurrent Neural Networks)(第二部分)
14.4 深度RNN
堆叠多层cell是很常见的,如图14-12所示,这就是一个深度RNN。
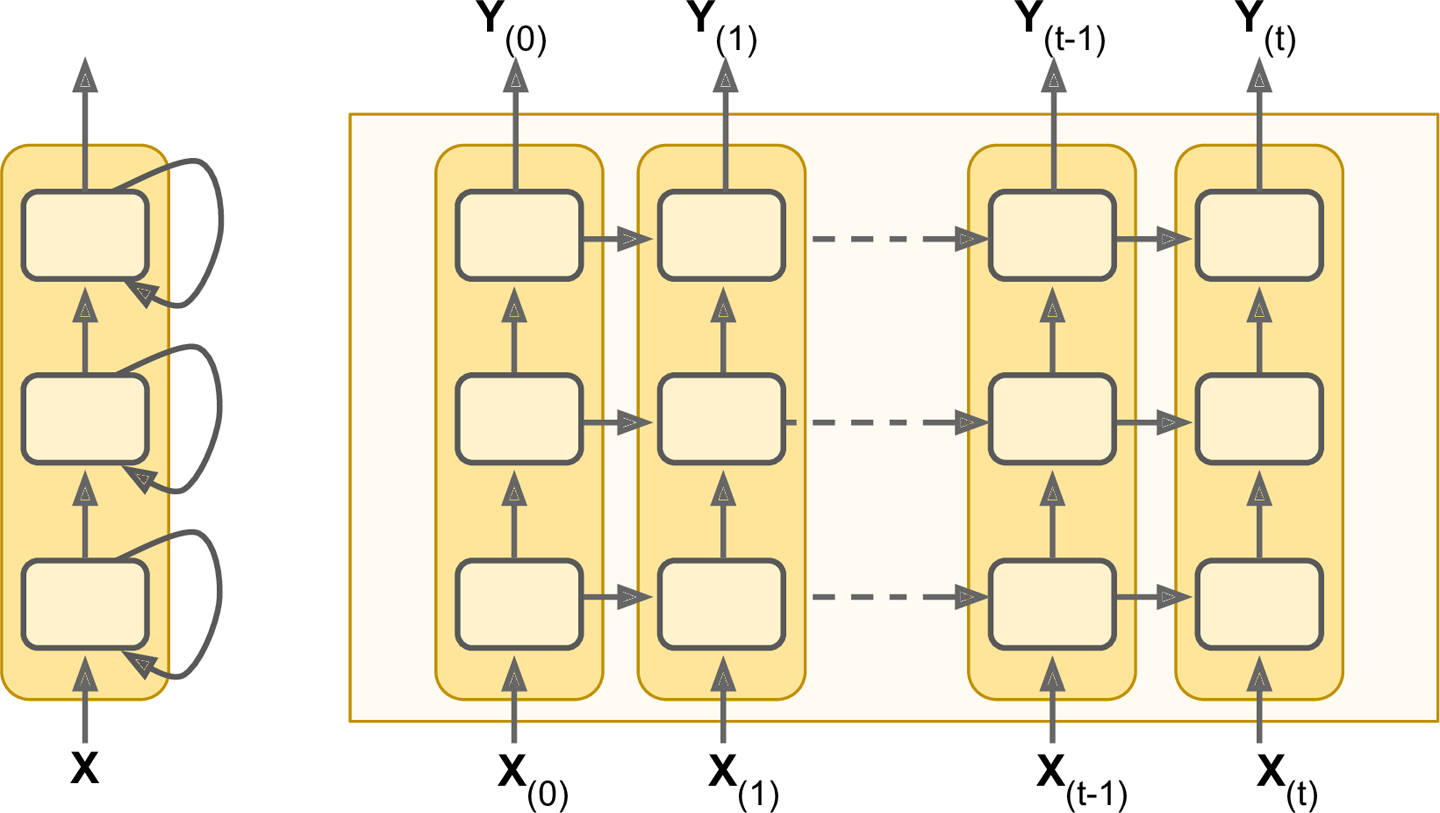
图14-12 深度RNN(左),随时间展开(右)
在TensorFlow中实现深度RNN,需要创建多个cell并将它们堆叠到一个MultiRNNCell中。下面的代码创建了三个完全相同的cell(也可以创建三个拥有不同神经元个数的cell):
n_neurons = 100
n_layers = 3 basic_cell = tf.contrib.rnn.BasicRNNCell(num_units=n_neurons)
multi_layer_cell = tf.contrib.rnn.MultiRNNCell([basic_cell] * n_layers)
outputs, states = tf.nn.dynamic_rnn(multi_layer_cell, X, dtype=tf.float32)
14.4.1 多GPU分布式训练深度RNN
先跳过
14.4.2 应用Dropout
如果创建了一个很深的RNN,可能会造成过拟合。为防止过拟合,常用的技术就是dropout(在第十一章介绍过)。可以简单地在RNN之前或者之后增加一个dropout层,但如果想在RNN层之间使用dropout,需要使用DropoutWrapper。下面的代码在RNN每层的输入都应用dropout,drop概率是50%。
keep_prob = 0.5 cell = tf.contrib.rnn.BasicRNNCell(num_units=n_neurons)
cell_drop = tf.contrib.rnn.DropoutWrapper(cell, input_keep_prob=keep_prob)
multi_layer_cell = tf.contrib.rnn.MultiRNNCell([cell_drop] * n_layers)
rnn_outputs, states = tf.nn.dynamic_rnn(multi_layer_cell, X, dtype=tf.float32)
如果是要在输出使用dropout,可以设置put_keep_prob。
上面代码存在很大的问题,就是会在训练和测试时都应用dropout(回忆一下十一章,dropout只能在训练的时候使用)。不幸的是,DropoutWrapper还不支持is_training占位符。所以要么自己实现一个DropoutWrapper,要么创建两个图(一个用于训练,一个用于测试)。
14.4.3 训练时刻过多的难点
在长序列上训练RNN,需要运行好多个时刻,使得RNN被展开为一个很深的模型。和任何其他的模型一样也会遭受梯度消失(爆炸)问题(十一章)。 之前提到的技巧对深度展开RNN也是有效的:合适的参数初始化、不饱和激活函数(比如ReLU)、Batch Normalization、Gradient Clipping、faster optimizers。不过,如果用RNN去处理很长(比如100)的序列,训练将变得极其缓慢。
最简单最常见的解决方案是,训练的时候只展开一部分时刻,这被称作truncated backpropagation through time。在TensorFlow中实现是,只需截掉一部分输入序列即可。不过这也有一个问题,那就是模型不能学习长期模式(long-term patterns)。一个变通方案是使得缩短的训练数据同时包含最新的和陈旧的训练数据(比如,一个序列包含前五个月的月度数据,前五周的数据,以及前五天的数据)。不过这一方案也是有局限的:如果去年的详细数据真的很重要,怎么办?如果前年有一件很明显的大事必须考虑在内(比如选举结果),那又怎么办?
除了训练时间长,RNN面临的另一个问题是随着长时间运行,前期记忆的淡忘。事实上随着数据穿过RNN,每一时刻都有一些信息丢失掉。不久之后,RNN的状态中就找不到第一次所输入数据的踪迹了。这可能是致命的。比如,在电影评论上面做情感分析。开头一句话是“我爱这部电影”,但剩下的问题都是在累积该电影还能改进的地方。如果RNN忘掉了开头那几个字,很可能就误解了这个评论。未解决这一问题,多种类型的具有长期记忆(long-term memory)功能的cell被引入,最出名的就是LSTM cell。
14.5 LSTM Cell
长短期记忆(Long Short-Term Memory,LSTM)cell由Sepp Hochreiter和Jürgen Schmidhuber于1997年提出。随后经历了很多研究者的改进,比如Alex Graves,Haşim Sak,Wojciech Zaremba等。如果把LSTM cell看作黑盒,它和一个基本的cell差不多,只不过表现更好:训练是更容易收敛,更容易发现数据中的长期依赖。在TensorFlow中,可以简单地使用BasicLSTMCell替换掉BasicRNNCell:
lstm_cell = tf.contrib.rnn.BasicLSTMCell(num_units=n_neurons)
LSTM cell要管理两个状态向量,为了性能原因它们默认是分开的。可以在创建BasicLSTMCell的时候设置state_is_tuple=False来改变这一行为。
图14-13是一个基本的LSTM cell:
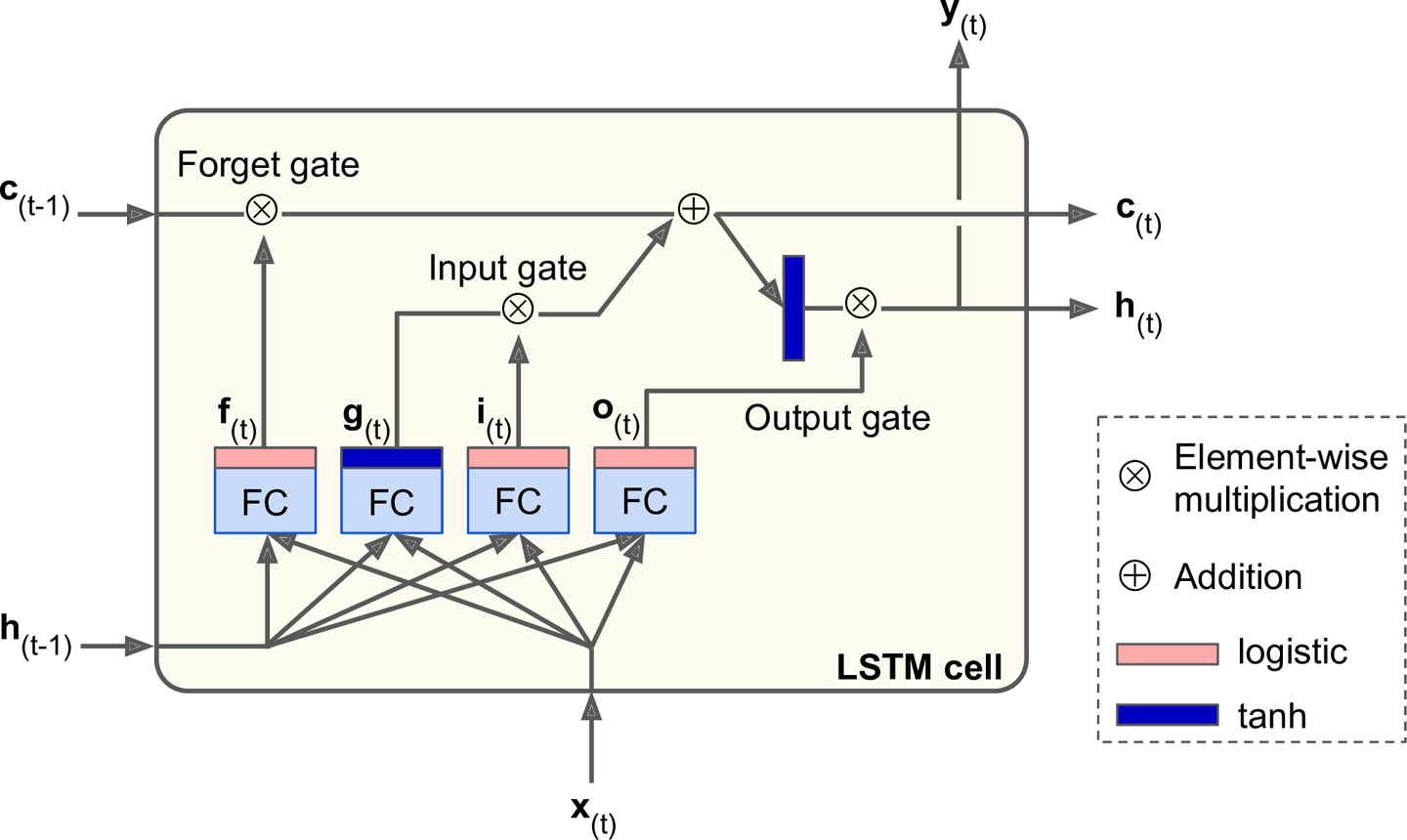
图14-13 LSTM cell
如果不看中间的淡黄色盒子,LSTM cell和常规的cell是类似的,除了它的状态被切分为了两个向量:$\textbf{h}_{(t)}$和$\textbf{c}_{(t)}$(c代表cell)。可以将$\textbf{h}_{(t)}$看做短期状态,$\textbf{c}_{(t)}$代表长期记忆。
现在来看一下盒子中到底是什么逻辑。核心思想就是,这一神经网络可以学习长期状态中应该保持什么,应该丢掉什么,应该读取什么。当长期状态$\textbf{c}_{(t-1)}$从左到右穿过神经网络时,它首先通过一个遗忘门(forget gate),丢掉一些记忆,然后通过加法运算增加一些新的记忆,增加的记忆是经过输入门(input gate)筛选过的。其结果$\textbf{c}_{(t)}$被直接输出了,不经过任何变换。所有,在每一时刻,都有一些信息被丢掉,一些信息被添加。此外,经过刚才的加法运算,长期记忆会被复制一份,先应用tanh函数,然后又经过输出门(output gate)过滤,参与生成短期记忆$\textbf{h}_{(t)}$(与这一时刻的输出$\textbf{y}_{(t)}$相等)。接着让我们看一下,新的记忆是从哪来的,以及这些门是如何工作的。
首先,当前时刻的输入$\textbf{x}_{(t)}$和前一时刻的短期记忆$\textbf{h}_{(t-1)}$供应给4个不同的全连接层。这4个全连接层有不同的目的:
- 最重要的一层是输出$\textbf{g}_{(t)}$的那个。它拥有类似基本cell的分析当前时刻输入$\textbf{x}_{(t)}$和前一时刻短期记忆$\textbf{h}_{(t-1)}$的角色。对于基本的cell,$\textbf{y}_{(t)}$和$\textbf{h}_{(t)}$会直接输出。不过LSTM cell的这一层不会直接输出,还会部分地保存在长期记忆中。
- 另外的三层是门控制器(gate controllers)。他们使用logistic激活函数,输出的范围是0到1。其输出用于按元素点乘运算。所以如果输出0,门被关闭;如果输出1,门被打开。明确来讲:
- 遗忘门(forget gate,由$\textbf{f}_{(t)}$控制)决定哪些长期记忆应该被遗忘。
- 输入门(input gate,由$\textbf{i}_{(t)}$控制)决定$\textbf{g}_{(t)}$的哪些内容应该被添加到长期记忆。
- 输出门(output gate,由$\textbf{o}_{(t)}$控制)决定哪些长期记忆应该被读取和输出。
LSTM一个实例输出的计算公式:
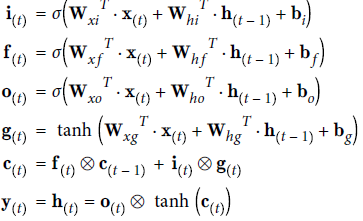
其中,
- $W_{xi},W_{xf},W_{xo},W_{xg}$是4个全连接层关于输入向量$\textbf{x}_{(t)}$的权重矩阵。
- $W_{hi},W_{hf},W_{ho},W_{hg}$是4个全连接层关于短期记忆$\textbf{h}_{(t-1)}$的权重矩阵。
- $b_{i},b_{f},b_{o},b_{g}$是4个全连接层的偏置项。TensorFlow会将$b_{f}$初始化为全是1的矩阵,而不是全是0,这会使得训练初期没有东西被遗忘。
14.5.1 Peephole Connections
在基本的LSTM cell中,控制门的状态只由当前时刻的输入$\textbf{x}_{(t)}$和前一时刻的短期记忆$\textbf{h}_{(t-1)}$决定。如果让长期记忆也参与控制门的管理可能会更好一点。这一思想由Felix Gers和Jürgen Schmidhuber在2000年提出。他们提出了一种LSTM变种,增加了一个被称作peephole connections的连接:前一时刻长期记忆$\textbf{c}_{(t-1)}$也作为遗忘门和输出门控制器的一个输入,当前时刻长期记忆$\textbf{c}_{(t)}$也作为输出门控制器的一个输入。
在TensorFlow中实现peephole connections,可以用LSTMCell代替BasicLSTMCell并设置use_peepholes=True:
lstm_cell = tf.contrib.rnn.LSTMCell(num_units=n_neurons, use_peepholes=True)
还有很多其他的LSTM cell变种,最有名的要数GRU cell。
14.6 GRU Cell
Gated Recurrent Unit (GRU) cell在2014年的一篇论文中提出, 该论文同时提出了我们先前提到的Encoder–Decoder神经网络。
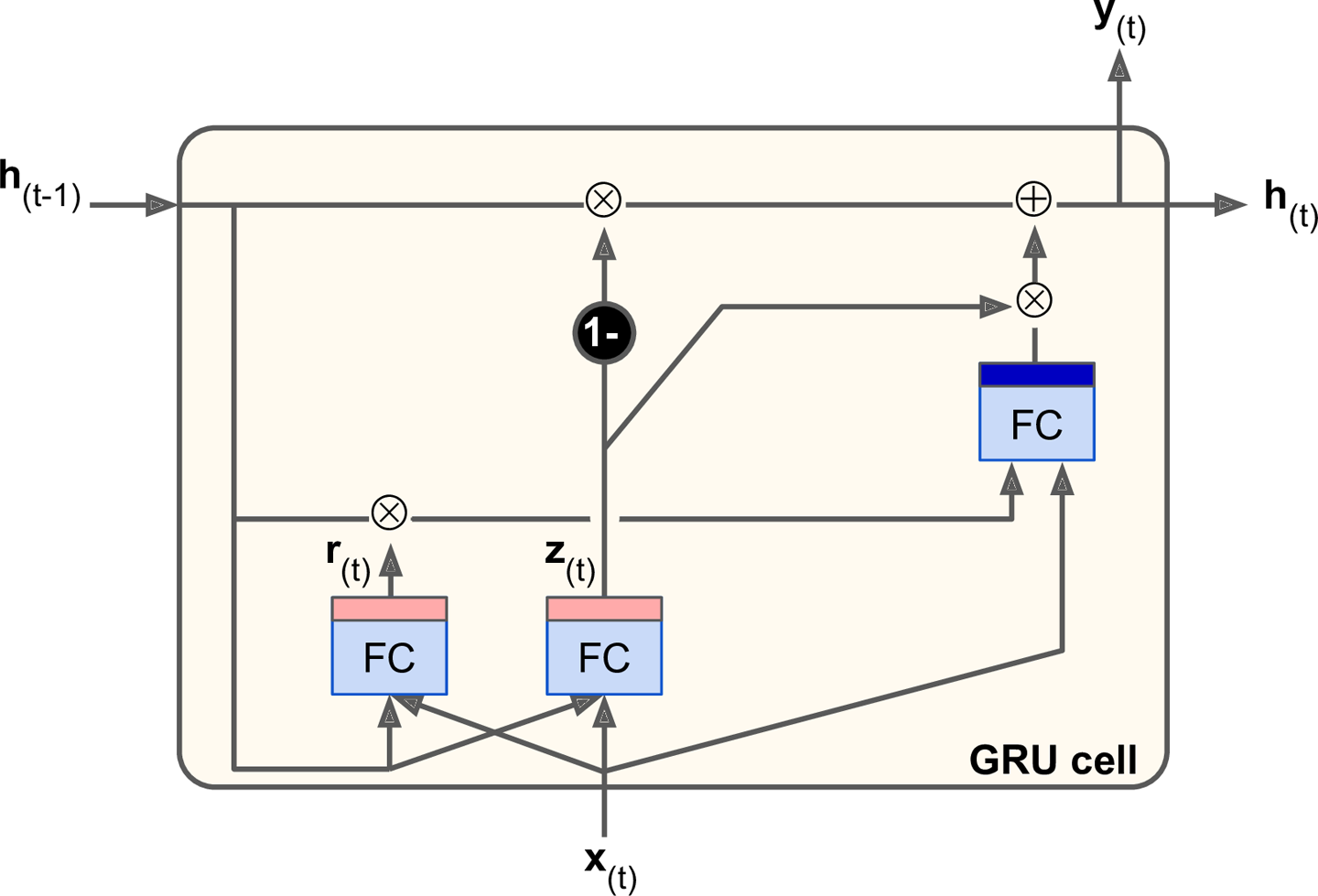
图14-14 GRU cell
GRU cell是LSTM cell的简化版,但是表现的同样好(2015年的论文LSTM: A Search Space Odyssey表明,所有LSTM变种的表现大致相同)。主要简化的部分如下:
- 两个状态向量被合并成了单独的$\textbf{h}_{(t)}$。
- 一个门控制器($\textbf{z}_{(t)}$)同时控制遗忘门和输入门。如果门控制器输出1,输入门被打开同时遗忘门被关闭。如果控制器输出0,输入门被关闭同时遗忘门被打开。换句话说,如果一个记忆需要被存储,那么该位置原先的记忆会被清除。
- 不再使用输出门,整个状态矩阵都会输出。不会,有一个新的门控制器($\textbf{h}_{(r)}$),来控制先前的哪些记忆需要传递给主层。
GRU一个实例输出的计算公式:
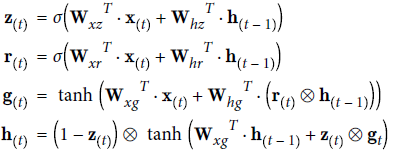
在TensorFlow中创建GRU cell:
gru_cell = tf.contrib.rnn.GRUCell(num_units=n_neurons)
LSTM和GRU cells是近些年RNNs取得成功的重要原因,尤其是在自然语言处理领域。
14.7 自然语言处理
大部分最先进的nlp应用,比如机器翻译,自动摘要,语法分析,情感分析等等,都基于(或部分基于)RNNs。本节需要提取了解一下TensorFlow的Word2Vec和Seq2Seq教程。
14.7.1 Word Embeddings
首先要解决的,就是词表示的问题(对于中文来讲,一般第一步是分词。英文有天然的空格对词进行分割。当然中文不进行分词也是可以的,比如以单字或者二字串作为特征)。词表示的一个方案是one-hot向量。假设词表有50000个词,那么第n个词表示为一个50000维向量,第n个位置是1,其他位置全是0。然而,词表这么大,这一稀疏表示效率很低。
更理想的是,我们希望相同意义的词有相似的表示形式,以便模型可以将其学到的模式推广到所有相似的词。比如,如果模型学到“I drink milk”是一个有效的句子,并且知道“milk”和“water”近似但是和“shoes”差别较大,那模型就能知道“I drink water”也是一个合法的句子,而“I drink shoes”很可能不是。
一个常见的解决方案是,用一个更小更稠密的向量(比如150维)来表示词表中的每个词,这被称作embedding。并且需要一个神经网络通过训练,找到每个词最好的embedding。训练初期,embedding都是随机选择的,但是通过反向传播会变得越来越好。这意味着相似的词会收敛到相似的向量,并且向量的维度可能会有实际的意义。比如,向量的不同维可能会表示性别,单数/复数(英语的单复数),形容词/名称,等等。(更多信息可参考Christopher Olah的著名博客,以及Sebastian Ruder的一系列博客)
在TensorFlow中,需要创建一个变量来表示词表中每个词的embedding(会被随机初始化):
vocabulary_size = 50000
embedding_size = 150
embeddings = tf.Variable(tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
然后假设你想把“I drink milk”这句话提供给神经网络进行训练。预处理的第一步是将句子表示成已知单词的列表。比如去掉不必要的特殊字符,将字典外的单字表示成一个预定义的标记(比如“[UNK]”),将数字替换成“[NUM]”,将URLs替换成“[URL]”,等等。如果是字典内的单词,就将其表示为它在字典中的id(从0到49999),比如[72, 3335, 288]。此时,就可以使用embedding_lookup()函数来获取相应的embedding了:
train_inputs = tf.placeholder(tf.int32, shape=[None]) # from ids...
embed = tf.nn.embedding_lookup(embeddings, train_inputs) # ...to embeddings
如果你的模型学到了不错的word embeddings,就可以高效地使用在所有nlp应用中了。
14.7.2 基于Encoder–Decoder神经网络的机器翻译
首先我们看一个简单的机器翻译模型,将英语句子译为法语,如图14-15:
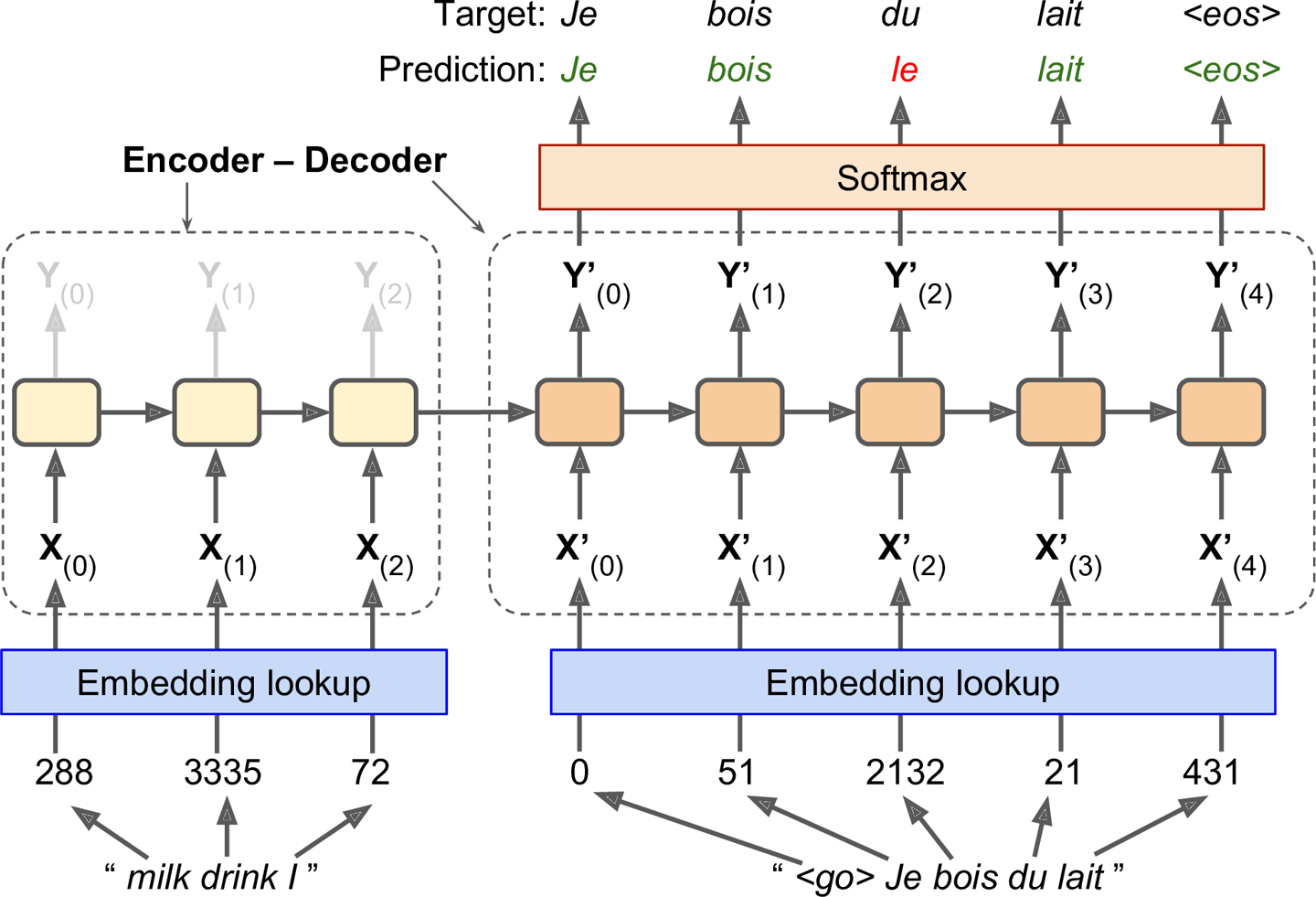
图14-15 一个简单的机器翻译模型
英语句子作为encoder的输入,decoder输出法语译文。法语的真实译文是decoder的输入,不过向后推了一个时刻(第一个时刻的输入是<go>,第二个时刻的输入才是Je)。换句话说,decoder在当前时刻的输入,应该是其上一时刻的输出(尽管实际上并不是这个输出)。decoder的输入以语句起始符号(比如<go>)开头,输出以语句终止符号(比如<eos>)结尾。
作为encoder输入的英语句子是被颠倒了的。比如“I drink milk”转换成了“milk drink I”。这确保了英语句子的开头在最后输入给了encoder,并最先由decoder翻译。
在每一步,decoder输出译文词典(本例中是法语词典)中每一个词的分值,然后再由Softmax层将分值转换成概率。比如,在第一步中,“Je”的概率可能是20%,“Tu”的概率可能是1%,等等。概率最大的单词将被输出。这与常规的分类任务很相似,所以可以用softmax_cross_entropy_with_logits()函数训练该模型。
在用模型做预测的时候(训练之后),并没有目标语句输入给decoder。简单地把前一时期的输出作为当前时期的输入就可以了。如图14-17(图中省略掉了embedding lookup):
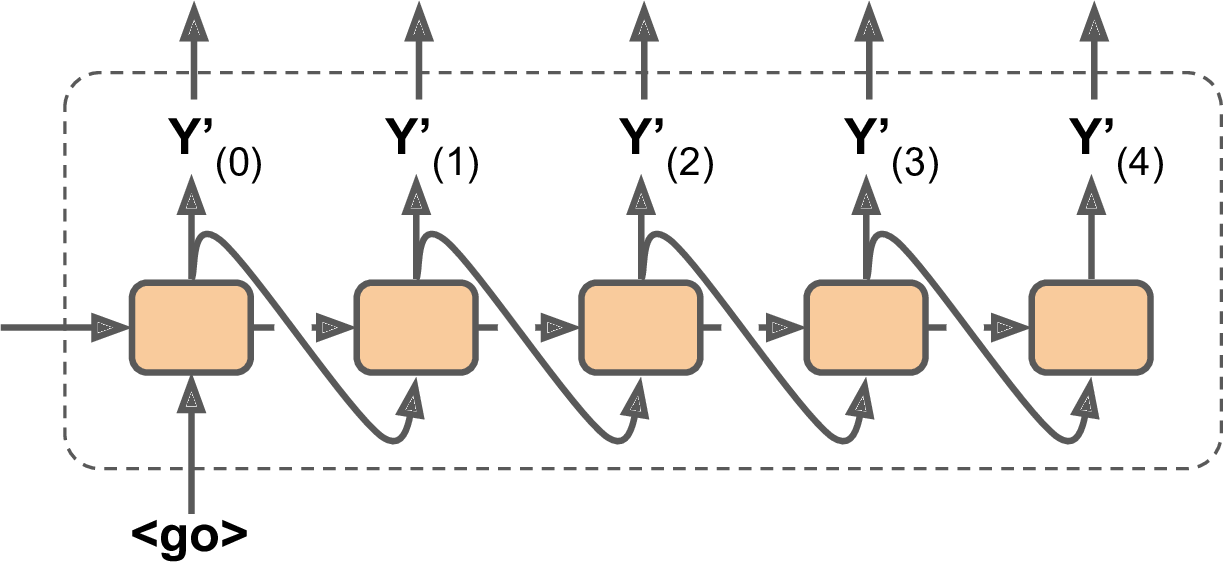
图14-16 预测时期,将前一步的输出,作为当前步的输入
现在,我们已经知道机器翻译的整体架构了。不过,如果查看TensorFlow的sequence-to-sequence教程,并学习rnn/translate/seq2seq_model.py(位于TensorFlow models)的源码,会发现有些不同:
- 首先,我们假设了所有的输入序列(包括encoder和decoder)都是定长的。但是很明显,句子的长度是不定的。这有多种处理方式——比如,static_rnn()和dynamic_rnn()函数使用sequence_length参数来描述句子的长度。不过,教程中使用了另一个方案(可能是由于性能原因):将一个句子切割成不同的组,每组长度相同(比如,一个矩阵的1-6个单词分为一组,7-12个单词分为另一组,等等)。较短的组使用特殊标记(比如“<pad>”)进行填充。例如“I drink milk”转换成“<pad> <pad> <pad> milk drink I”,然后翻译为“Je bois du lait <eos> <pad>”。当然,我们希望忽略EOS之后的内容。教程中的实现方式是使用一个target_weights向量,。比如对于目标语句“Je bois du lait <eos> <pad>”,这一向量是[1.0, 1.0, 1.0, 1.0, 1.0, 0.0](进行填充的位置就是0.0)。
- 其次,由于词表很大,输出每个词可能的概率去计算交叉熵是很慢的。一个解决方案是decoder输出一个小得多的向量,比如1000维,然后使用抽样技术估计损失。这一Sampled Softmax技术在2015年被提出。在TensorFlow中可以使用sampled_softmax_loss()函数。
- 其次,教程中的实现使用了attention机制(attention mechanism)。RNN的attention机制超出了本书的范围,不过可以参考machine translation,machine reading,image captions。
- 最后,教程中的实现使用了tf.nn.legacy_seq2seq模块,这使得创建多种Encoder–Decoder模型变得简单。比如,embedding_rnn_seq2seq()创建的Encoder–Decoder模型自动进行word embeddings。
第十四章——循环神经网络(Recurrent Neural Networks)(第二部分)的更多相关文章
- 第十四章——循环神经网络(Recurrent Neural Networks)(第一部分)
由于本章过长,分为两个部分,这是第一部分. 这几年提到RNN,一般指Recurrent Neural Networks,至于翻译成循环神经网络还是递归神经网络都可以.wiki上面把Recurrent ...
- 循环神经网络(Recurrent Neural Networks, RNN)介绍
目录 1 什么是RNNs 2 RNNs能干什么 2.1 语言模型与文本生成Language Modeling and Generating Text 2.2 机器翻译Machine Translati ...
- 详解循环神经网络(Recurrent Neural Network)
本文结构: 模型 训练算法 基于 RNN 的语言模型例子 代码实现 1. 模型 和全连接网络的区别 更细致到向量级的连接图 为什么循环神经网络可以往前看任意多个输入值 循环神经网络种类繁多,今天只看最 ...
- 循环神经网络(RNN, Recurrent Neural Networks)介绍(转载)
循环神经网络(RNN, Recurrent Neural Networks)介绍 这篇文章很多内容是参考:http://www.wildml.com/2015/09/recurrent-neur ...
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
原文地址: http://blog.csdn.net/heyongluoyao8/article/details/48636251# 循环神经网络(RNN, Recurrent Neural Netw ...
- 《转》循环神经网络(RNN, Recurrent Neural Networks)学习笔记:基础理论
转自 http://blog.csdn.net/xingzhedai/article/details/53144126 更多参考:http://blog.csdn.net/mafeiyu80/arti ...
- 深度学习四从循环神经网络入手学习LSTM及GRU
循环神经网络 简介 循环神经网络(Recurrent Neural Networks, RNN) 是一类用于处理序列数据的神经网络.之前的说的卷积神经网络是专门用于处理网格化数据(例如一个图像)的神经 ...
- “全栈2019”Java第二十四章:流程控制语句中决策语句switch下篇
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- 进击的Python【第十四章】:Web前端基础之Javascript
进击的Python[第十四章]:Web前端基础之Javascript 一.javascript是什么 JavaScript 是一种轻量级的编程语言. JavaScript 是可插入 HTML 页面的编 ...
随机推荐
- Angular为什么选择TypeScript?
原文地址:https://vsavkin.com/writing-angular-2-in-typescript-1fa77c78d8e8 本文转自:http://www.chinacion.cn/a ...
- Awesome Big Data List
https://github.com/onurakpolat/awesome-bigdata A curated list of awesome big data frameworks, resour ...
- removeElement
Description: Given an array and a value, remove all instances of that value in place and return the ...
- Django+xadmin打造在线教育平台(五)
目录 在线教育平台(一) 在线教育平台(二) 在线教育平台(三) 在线教育平台(四) 在线教育平台(五) 在线教育平台(六) 在线教育平台(七) 在线教育平台( ...
- Jupyter-notebook 导出时不显示Input[]代码
参考: https://stackoverflow.com/questions/34818723/export-notebook-to-pdf-without-code 1. 第一个方式是直接在 ...
- 对C#热更新方案ILRuntime的探究
转载请标明出处:http://www.cnblogs.com/zblade/ 对于游戏中的热更,目前主流的解决方案,分为Lua(ulua/slua/xlua/tolua)系和ILRuntime代表的c ...
- 爬虫值requests库
requests简介 简介 Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库 ,使用起来比urllib简洁很多 因为是第三方库, ...
- PAT1056:Mice and Rice
1056. Mice and Rice (25) 时间限制 100 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue Mice an ...
- 网络Socket编程及实例
1 TCP和UDP介绍 在介绍TCP和UDP之前,有必要先介绍下网络体系结构的各个层次. 1.1 网络体系结构 协议:控制网络中信息的发送和接收.定义了通信实体之间交换报文的格式和次序,以及在报文传 ...
- linux编译安装时常见错误解决办法
This article is post on https://coderwall.com/p/ggmpfa 原文链接:http://www.bkjia.com/PHPjc/1008013.html ...