requests+多进程poll+pymongo实现抓取小说
今天看着有个很吸引人的小说作品信息:一家只在深夜开门营业的书屋,欢迎您的光临。
作为东野奎吾《深夜食堂》漫画的fans,看到这个标题按捺不住我的好奇心........
所以我又抓下来了,总共52章,下面有源码,写的有点乱哦,凑合看看,关键看结果,@~@。。。。
代码写完,几秒钟就抓取下来,比下载效率高不少,小激动~~~~~~
readme>>>环境python2,我的python2还有多长寿命;其他內库依赖见代码体现
# coding:utf-8 from multiprocessing import Pool
from lxml import etree
import requests
import pymongo def save_mongo(data):
client = pymongo.MongoClient('60.205.211.210',27017)
db = client.test
collection = db.shenyeshuwu
collection.insert(dict(data))
print('--------%s---------存储完毕' %data['title']) def parse_content(url):
resp = requests.get(url).content
html = etree.HTML(resp)
contents = html.xpath('//*[@id="j_chapterBox"]/div[2]/div/div[2]/p/text()|//*[@id="j_chapterBox"]/div[1]/div/div[2]/p/text()')
return contents def parse_html(html):
'''
[{
'title':title,
'url':url,
'content':content
}]
'''
page = etree.HTML(html)
article_url_list = page.xpath('//ul[@class="cf"]/li/a')
for i in article_url_list:
url = 'http:' + i.xpath('./@href')[0]
# print(url)
title = i.xpath('./text()')[0]
# print(title)
time = i.xpath('./@title')[0]
# print(time)
con = parse_content(url)
# print(con)
data = {
'url': url,
'title': title,
'time': time,
'content': con
}
print(data)
save_mongo(data) def get_page(url):
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36'
}
resp = requests.get(url,headers=header).content
parse_html(resp) def main():
url = 'https://book.qidian.com/info/1011335417#Catalog'
# get_page(url)
# 使用进程池 map(func,iterable)
pool = Pool(4)
# pool.map(parse_content,data)
pool.apply_async(get_page,args=(url,))
pool.close()
pool.join() if __name__ == '__main__':
main()
如往常,把截图展示下:
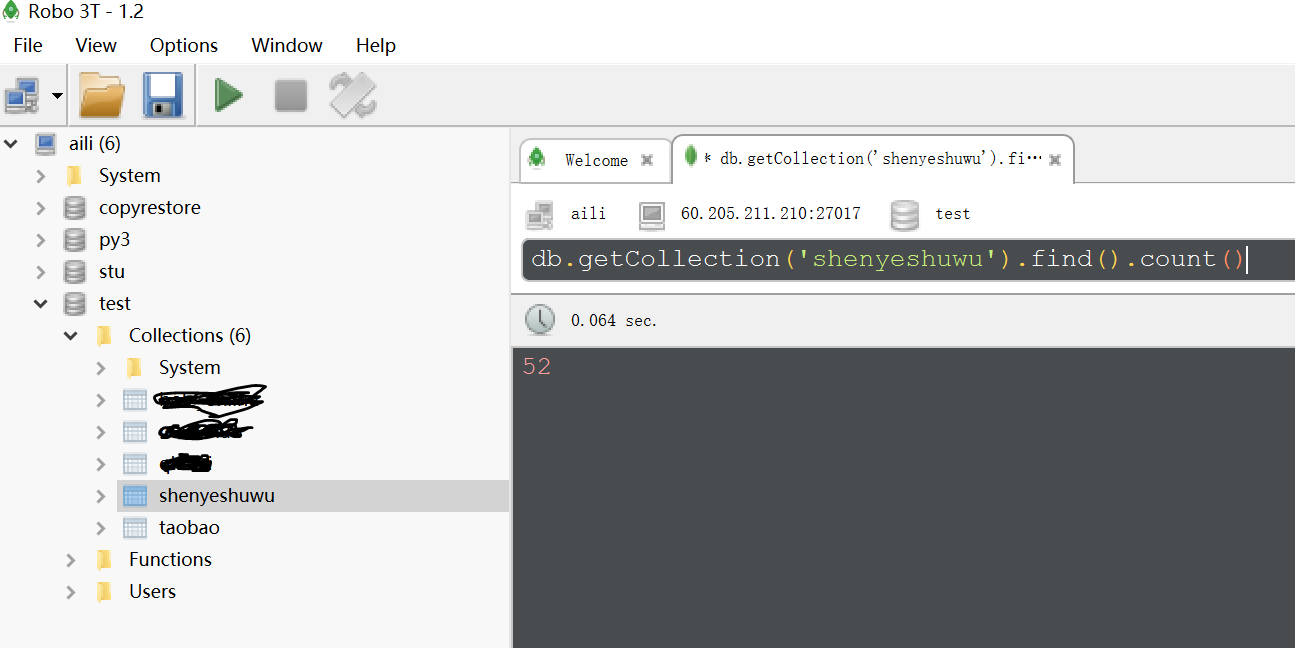
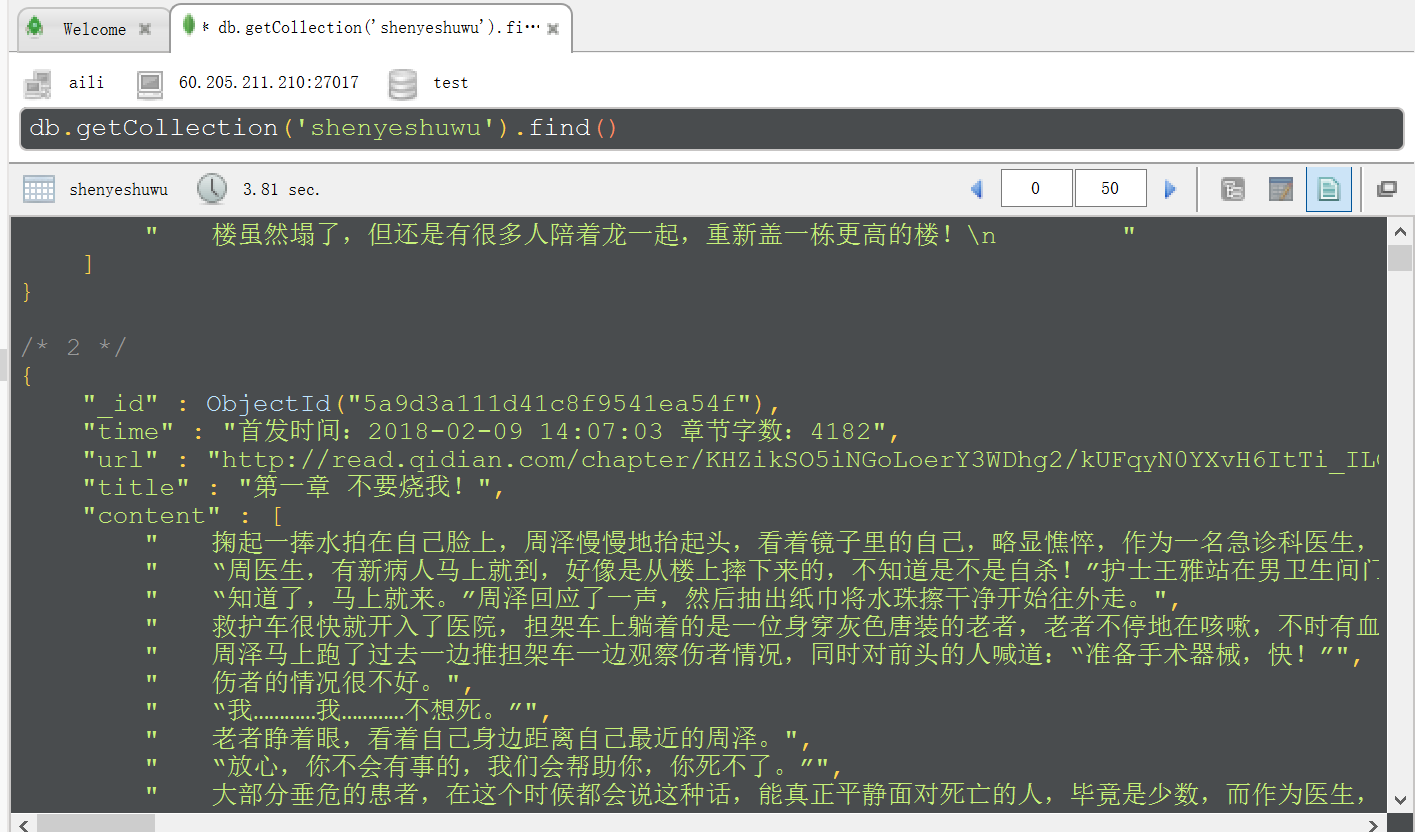
requests+多进程poll+pymongo实现抓取小说的更多相关文章
- C# 爬虫 抓取小说
心血来潮,想研究下爬虫,爬点小说. 通过百度选择了个小说网站,随便找了一本小书http://www.23us.so/files/article/html/13/13655/index.html. 1. ...
- C# 爬虫 正则、NSoup、HtmlAgilityPack、Jumony四种方式抓取小说
心血来潮,想爬点小说.通过百度选择了个小说网站,随便找了一本小说http://www.23us.so/files/article/html/13/13655/index.html. 1.分析html规 ...
- Python抓取小说
Python抓取小说 前言 这个脚本命令MAC在抓取小说写,使用Python它有几个码. 代码 # coding=utf-8 import re import urllib2 import chard ...
- scrapy抓取小说
用scrapy建立一个project,名字为Spider scrapy startproject Spider 因为之前一直用的是电脑自带的python版本,所以在安装scrapy时,有很多问题,也没 ...
- python requests 模拟登陆网站,抓取数据
抓取页面数据的时候,有时候我们需要登陆才可以获取页面资源,那么我们需要登陆以后才可以跳转到对应的资源页面,那么我们需要通过模拟登陆,登陆成功以后再次去抓取对应的数据. 首先我们需要通过手动方式来登陆一 ...
- python爬虫之抓取小说(逆天邪神)
2022-03-06 23:05:11 申明:自我娱乐,对自我学习过程的总结. 正文: 环境: 系统:win10, python版本:python3.10.2, 工具:pycharm. 项目目标: 实 ...
- Python 爬虫-抓取小说《盗墓笔记-怒海潜沙》
最近想看盗墓笔记,看了一下网页代码,竟然不是js防爬虫,那就用简单的代码爬下了一节: """ 爬取盗墓笔记小说-七星鲁王宫 """ from ...
- Python 爬虫-抓取小说《鬼吹灯之精绝古城》
想看小说<鬼吹灯之精绝古城>,可是网页版的好多广告,还要一页一页的翻,还无法复制,于是写了个小爬虫,保存到word里慢慢看. 代码如下: """ 爬取< ...
- jsoup使用样式class抓取数据时空格的处理
最近在研究用android和jsoup抓取小说数据,jsoup的使用可以参照http://www.open-open.com/jsoup/;在抓纵横中文网永生这本书的目录内容时碰到了问题, 永生的书简 ...
随机推荐
- HSSF、XSSF和SXSSF区别以及Excel导出优化
之前有写过运用POI的HSSF方式导出数据到Excel(见:springMVC中使用POI方式导出excel至客户端.服务器实例),但这种方式当数据量大到一定程度时容易出现内存溢出等问题. 首先,PO ...
- iOS 组件化 —— 路由设计思路分析
原文 前言 随着用户的需求越来越多,对App的用户体验也变的要求越来越高.为了更好的应对各种需求,开发人员从软件工程的角度,将App架构由原来简单的MVC变成MVVM,VIPER等复杂架构.更换适合业 ...
- 04_Javascript初步第三天
事件 内联模型.脚本模型,DOM2级模型 <!--内联模型--> <input type="button" value="bt1" oncli ...
- Java基础知识(一)
类与对象 1.对象:客观存在的一切事物称之为对象 类:具有相同属性和方法的对象的集合 2.类:属性,方法 3.修饰符: public protected 默认(不写) private 任何地方 ...
- JDK安装及Tomcat安装
JDK安装及Tomcat安装 JDK 解压JDK到常用盘符 D为例 Tomcat安装 将tomcat.zip解压到常用的根目录下,我这里以D盘为例.这样就算安装好了! 接下来开始配置环境变量,打开环境 ...
- appium问题整理
在刚进入appium的世界时,遇到无数的坑,趟过无数的浑水,现在整理一些常用的报错讯息,供大家参考 1.org.openqa.selenium.remote.UnreachableBrowserExc ...
- 【Spring】HttpMessageConverter的作用及替换
相信使用过Spring的开发人员都用过@RequestBody.@ResponseBody注解,可以直接将输入解析成Json.将输出解析成Json,但HTTP 请求和响应是基于文本的,意味着浏览器和服 ...
- Golang时间格式化
PHP中格式化时间很方便,只需要一个函数就搞定: date("Y-m-d H:i:s") 而在Golang中,用的是"2006-01-02 15:04:05"这 ...
- MySQL用户授权与权限
MySQL权限如下表 权限名字 权限说明 Context CREATE 允许创建新的数据库和表 Databases, tables, or indexes DROP 允许删除现有数据库.表和视图 Da ...
- Springboot security cas源码陶冶-ExceptionTranslationFilter
拦截关键的两个异常,对异常进行处理.主要应用异常则跳转至cas服务端登录页面 ExceptionTranslationFilter#doFilter-逻辑入口 具体操作逻辑如下 public void ...