Spark:如何替换sc.parallelize(List(item1,item2)).collect().foreach(row=>{})为并行?
代码场景:
1)设定的几种数据场景,遍历所有场景:依次统计满足每种场景条件下的数据,并把统计结果存入hive;
2)已有代码如下:
case class IndoorOTTCalibrateBuildingVecotrLegend(oid: Int, minHeight: Int, maxHeight: Int, minGridIDCount: Int, maxGridIDCount: Int, heightType: Int) extends Serializable
// 实例化建筑物区间段:按照栅格的个数(面积)、楼的高度(商场等场景)来划分场景
val buildingHeightLegends = List(
IndoorOTTCalibrateBuildingVecotrLegend(1, 1, 30, 1, 21, BuildingCalibrateHeightType.HeightType1.toString.toInt),
IndoorOTTCalibrateBuildingVecotrLegend(2, 1, 30, 21, 45, BuildingCalibrateHeightType.HeightType2.toString.toInt),
IndoorOTTCalibrateBuildingVecotrLegend(3, 1, 30, 45, 100, BuildingCalibrateHeightType.HeightType3.toString.toInt),
IndoorOTTCalibrateBuildingVecotrLegend(4, 30, 50, 1, 21, BuildingCalibrateHeightType.HeightType4.toString.toInt),
IndoorOTTCalibrateBuildingVecotrLegend(5, 30, 50, 21, 45, BuildingCalibrateHeightType.HeightType5.toString.toInt),
IndoorOTTCalibrateBuildingVecotrLegend(6, 30, 50, 45, 100, BuildingCalibrateHeightType.HeightType6.toString.toInt),
IndoorOTTCalibrateBuildingVecotrLegend(7, 50, 5000, 1, 100, BuildingCalibrateHeightType.HeightType7.toString.toInt)
)
spark.sparkContext.parallelize(buildingHeightLegends).collect().foreach(buildingHeightLegend => {
generateSampleBySenceType(spark, p_city, p_hour_start, p_hour_end, p_fpb_day, p_day_sample, linkLossCalibrateParameter, buildingHeightLegend)
})
备注:
在generateSampleBySenceType()函数内部包含有:
spark.sql(s"""
|xxx
|where t10.heihgt>=${buildingHieghtLegend.MinHeight} and t10.height<${buildingHieghtLegend.MaxHeight}
|and t10.gridcount<=${buildingHieghtLegend.MinGridIDCount} and t10.gridcount>${buildingHieghtLegend.MaxGridIDCount}
|""".stripMargin)
如果把代码修改:
val buildingHeightLegends_df = spark.sqlContext.createDataFrame(buildingHeightLegends)
buildingHeightLegends_df.createOrReplaceTempView("temp_buildingheightlegends") sql(s"""|select * from temp_buildingheightlegends""".stripMargin).repartition(buildingHeightLegends.length).foreachPartition(rows => {
for (row <- rows) {
val buildingHeightLegend = new IndoorOTTCalibrateBuildingVecotrLegend(
row.getAs[Int]("oid"),
row.getAs[Int]("minheight"),
row.getAs[Int]("maxheight"),
row.getAs[Int]("mingrididcount"),
row.getAs[Int]("maxgrididcount"),
row.getAs[Int]("heighttype"))
generateSampleBySenceType(spark, p_city, p_hour_start, p_hour_end, p_fpb_day, p_day_sample, linkLossCalibrateParameter, buildingHeightLegend)
}
})
则会提示:generateSampleBySenceType()内部sql代码位置抛出SparkSession为NULL的异常。
修改方案:
把buildingHeightLegends注册为临时表temp_buildingHeightLegends,去掉外层的foreach,之后在generateSampleBySenceType()内部把temp_buildingHeightLegends与其他结果集合进行cross join:
测试代码如下:
-- 场景表
CREATE TABLE [dbo].[test_senceitems](
[sencetype] [int] NULL,
[minheight] [int] NULL,
[maxheight] [int] NULL,
[mingridcount] [int] NULL,
[maxgridcount] [int] NULL
)
INSERT [dbo].[test_senceitems] ([sencetype], [minheight], [maxheight], [mingridcount], [maxgridcount]) VALUES (1, 1, 30, 1, 21)
INSERT [dbo].[test_senceitems] ([sencetype], [minheight], [maxheight], [mingridcount], [maxgridcount]) VALUES (2, 1, 30, 21, 45)
INSERT [dbo].[test_senceitems] ([sencetype], [minheight], [maxheight], [mingridcount], [maxgridcount]) VALUES (3, 1, 30, 45, 100)
INSERT [dbo].[test_senceitems] ([sencetype], [minheight], [maxheight], [mingridcount], [maxgridcount]) VALUES (4, 30, 50, 1, 21)
INSERT [dbo].[test_senceitems] ([sencetype], [minheight], [maxheight], [mingridcount], [maxgridcount]) VALUES (5, 30, 50, 21, 45)
INSERT [dbo].[test_senceitems] ([sencetype], [minheight], [maxheight], [mingridcount], [maxgridcount]) VALUES (6, 30, 50, 45, 100)
INSERT [dbo].[test_senceitems] ([sencetype], [minheight], [maxheight], [mingridcount], [maxgridcount]) VALUES (7, 50, 5000, 1, 100) -- 业务过滤统计表
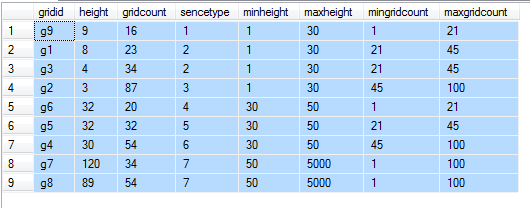
CREATE TABLE [dbo].[test_grid](
[gridid] [nvarchar](50) NULL,
[height] [int] NULL,
[gridcount] [int] NULL
) INSERT [dbo].[test_grid] ([gridid], [height], [gridcount]) VALUES (N'g1', 8, 23)
INSERT [dbo].[test_grid] ([gridid], [height], [gridcount]) VALUES (N'g2', 3, 87)
INSERT [dbo].[test_grid] ([gridid], [height], [gridcount]) VALUES (N'g3', 4, 34)
INSERT [dbo].[test_grid] ([gridid], [height], [gridcount]) VALUES (N'g4', 30, 54)
INSERT [dbo].[test_grid] ([gridid], [height], [gridcount]) VALUES (N'g5', 32, 32)
INSERT [dbo].[test_grid] ([gridid], [height], [gridcount]) VALUES (N'g6', 32, 20)
INSERT [dbo].[test_grid] ([gridid], [height], [gridcount]) VALUES (N'g7', 120, 34)
INSERT [dbo].[test_grid] ([gridid], [height], [gridcount]) VALUES (N'g8', 89, 54)
INSERT [dbo].[test_grid] ([gridid], [height], [gridcount]) VALUES (N'g9', 9, 16)
替换generateSampleBySenceType()内部sql(s"""|""".stripMargin)代码类似如下:
select t10.*,t11.*
from test_grid t10
cross join test_senceitems t11
where t10.height>=t11.minheight and t10.height<t11.maxheight
and t10.gridcount>=t11.mingridcount and t10.gridcount<t11.maxgridcount
Spark:如何替换sc.parallelize(List(item1,item2)).collect().foreach(row=>{})为并行?的更多相关文章
- 单表千亿电信大数据场景,使用Spark+CarbonData替换Impala案例
[背景介绍] 国内某移动局点使用Impala组件处理电信业务详单,每天处理约100TB左右详单,详单表记录每天大于百亿级别,在使用impala过程中存在以下问题: 详单采用Parquet格式存储,数据 ...
- arrayObj.splice(start, deleteCount, [item1[, item2[, . . . [,itemN]]]])
测试方法 function test(){ var arr = [0,1,2,3]; arr.splice(1,1,'a');//case console.dir(arr); } case1: arr ...
- Spark(二)【sc.textfile的分区策略源码分析】
sparkcontext.textFile()返回的是HadoopRDD! 关于HadoopRDD的官方介绍,使用的是旧版的hadoop api ctrl+F12搜索 HadoopRDD的getPar ...
- Spark算子--first、count、reduce、collect、lookup
转载请标明出处http://www.cnblogs.com/haozhengfei/p/4b8582c8dde1529abb11e4ccc8296171.html first.count.reduce ...
- Spark学习之路(四)—— RDD常用算子详解
一.Transformation spark常用的Transformation算子如下表: Transformation算子 Meaning(含义) map(func) 对原RDD中每个元素运用 fu ...
- Spark 系列(四)—— RDD常用算子详解
一.Transformation spark 常用的 Transformation 算子如下表: Transformation 算子 Meaning(含义) map(func) 对原 RDD 中每个元 ...
- 【spark】常用转换操作:sortByKey()和sortBy()
1.sortByKey() 功能: 返回一个根据键排序的RDD 示例 val list = List(("a",3),("b",2),("c" ...
- Spark_Transformation和Action算子
Transformation 和 Action 常用算子 一.Transformation 1.1 map 1.2 filter 1.3 flatMap ...
- 入门大数据---Spark_Transformation和Action算子
一.Transformation spark 常用的 Transformation 算子如下表: Transformation 算子 Meaning(含义) map(func) 对原 RDD 中每个元 ...
随机推荐
- Python 中的登陆获取数据跳转页面(不含数据库)
简单表单和模板: import os.path import tornado.httpserver import tornado.ioloop import tornado.options impor ...
- Java多线程JUC
1. volatile 关键字 多线程访问的时候,一个比较严重的问题就是内存不可见,其实在内存访问的时候每一个线程都有一个自己的缓冲区,每次在做修改的时候都是从主存取到数据,然后放到自己的缓冲区中,在 ...
- ELK学习笔记(三)单台服务器多节点部署
一般情况下单台服务器只会部署一个ElasticSearch node,但是在学习过程中,很多情况下会需要实现ElasticSearch的分布式效果,所以需要启动多个节点,但是学习开发环境(不想开多个虚 ...
- JDBC(通俗易懂)简单的操作(增、删、改、查)
项目所写的类: 说明:①.DButil 动态加载数据库驱动,以及获取java.sql.Connection的对象. ②.Personmodel 数据库列(栏位)所对应的字段,定义了相应的set和get ...
- 介绍C语言指针
最近心态不太好,但是还是控制自己刷一下算法题,但是看着多次出现的 “Segmentation fault”,心态又爆炸啦.我只想说:“我也早觉得有写一点东西的必要了.离三月十八日也已有两星期,忘却的救 ...
- Matlab绘图基础——绘制三维曲线
%% 绘制三维曲线 %plot3函数,其中每一组x,y,z组成一组曲线的坐标参数,选项的定义和plot函数相同. %1.当x,y,z是同维向量时,则x,y,z 对应元素构成一条三维曲线. x0 = 0 ...
- Java注解(1)-注解基础
注解(Annotation)是在JAVA5中开始引入的,它为在代码中添加信息提供了一种新的方式.注解在一定程度上把元数据与源代码文件结合在一起,正如许多成熟的框架(Spring)所做的那样.那么,注解 ...
- SSH三大框架整合案例
SSH三大框架的整合 SSH三个框架的知识点 一.Hibernate框架 1. Hibernate的核心配置文件 1.1 数据库信息.连接池配置 1.2 Hibernate信息 1.3 映射配置 ...
- 构造函数与析构函数(construction undergoing)
构造函数和析构函数 一.构造函数: 1.普通构造函数:在对象被创建时利用特定的值构造对象,将对象初始化到一个特定的状态. 特性:构造函数的函数名和类名相同:没有返回值:在对象被创建时被自动调用:如果有 ...
- JavaScript(第二十一天)【DOM元素尺寸和位置】
学习要点: 1.获取元素CSS大小 2.获取元素实际大小 3.获取元素周边大小 本章,我们主要讨论一下页面中的某一个元素它的各种大小和各种位置的计算方式,以便更好的理解. 一.获取元素CSS大小 ...