TensorFlow-谷歌深度学习库 手把手教你如何使用谷歌深度学习云平台
自己的电脑跑cnn, rnn太慢? 还在为自己电脑没有好的gpu而苦恼? 程序一跑一俩天连睡觉也要开着电脑训练?
如果你有这些烦恼何不考虑考虑使用谷歌的云平台呢?注册之后即送300美元噢~下面我就来介绍一下谷歌云平台的使用。
1 配置谷歌云平台项目(GCP Project)
https://console.cloud.google.com/cloud-resource-manager

按照谷歌的向导你可以一步一步创建一个新的项目。这个项目就是你本地的项目并想放在云上跑的东西。
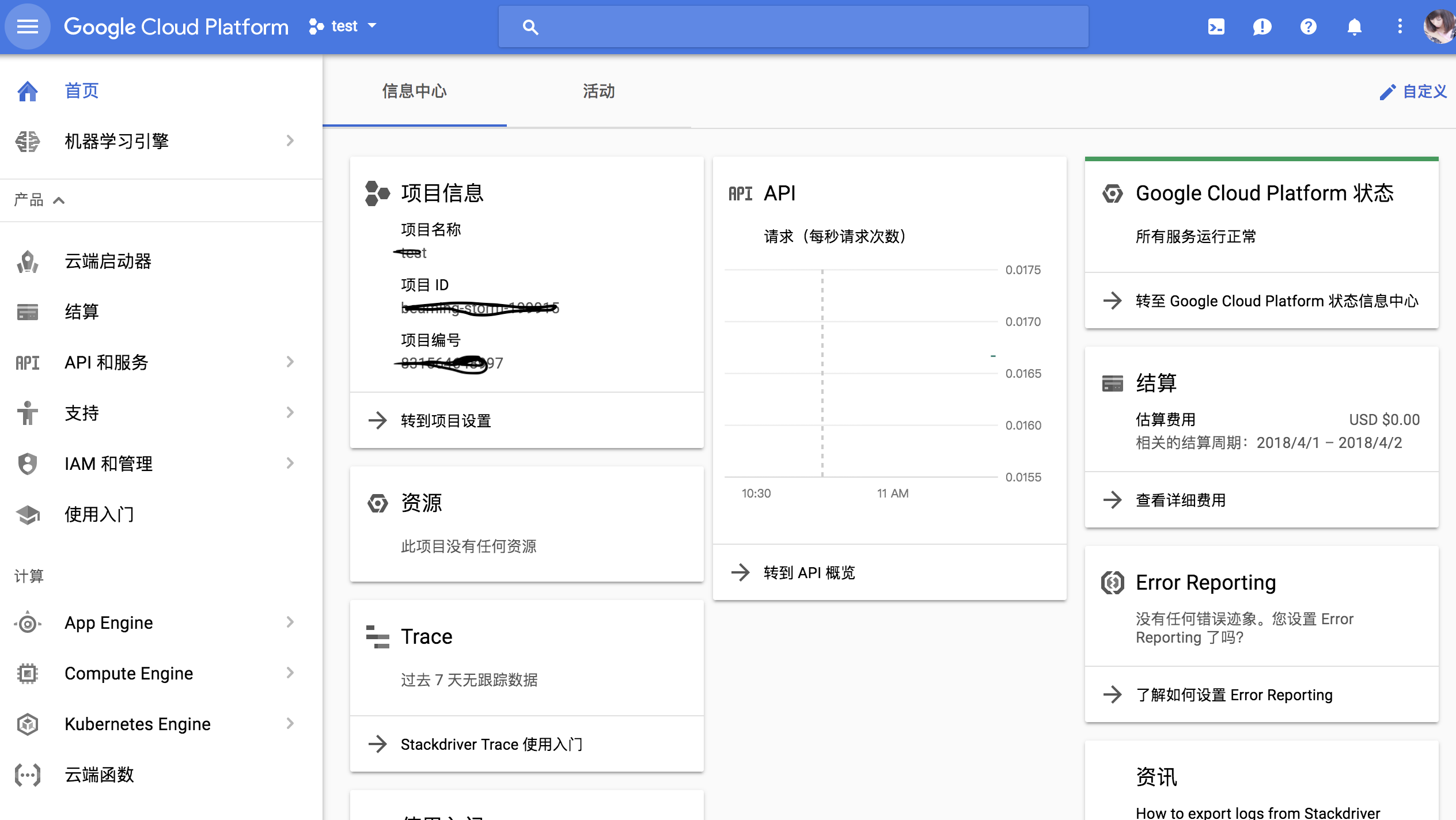
点击创建项目,输入新建的项目名称,等一下下你的新项目就创建好啦。新的项目的dashboard如下所示。
2 将这个项目绑定一个付款账号,当然谷歌给了你300刀,如果你只是做一些小项目仅供个人学习的话300刀应该是足够的。
https://cloud.google.com/billing/docs/how-to/modify-project
如果你还没有一个付款账号,会提示你先创建一个账号, 总之你要关联你的账号到你新建的项目。
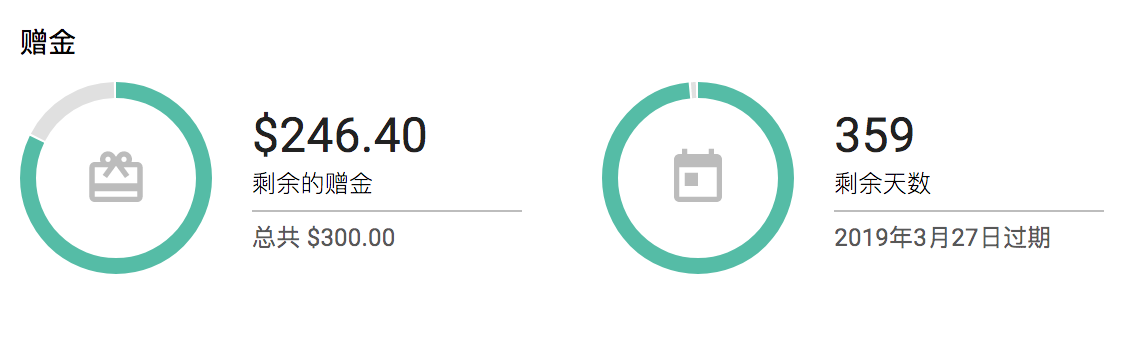
设置完毕后你会看到谷歌给你的赠金信息
3.启用API,在 Google Cloud Platform 中注册您的应用以使用 Google Cloud Machine Learning EngineGoogle Compute Engine API
https://console.cloud.google.com/flows/enableapi?apiid=ml.googleapis.com,compute_component
选择要注册API的项目。显示正在启用API。你讲看到下面这个界面

4 设置凭据
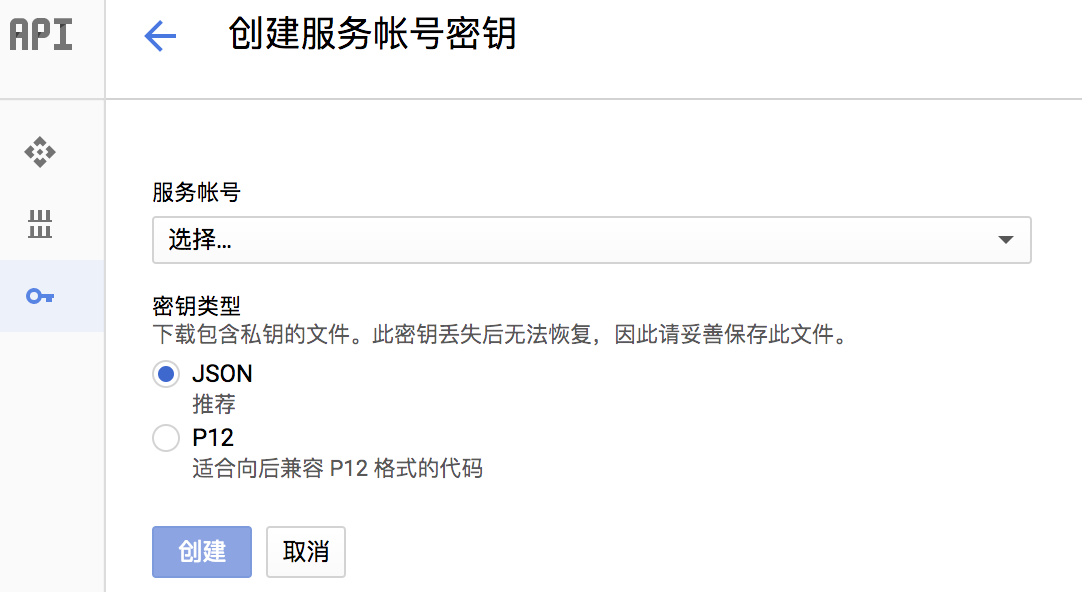
新建一个服务账号,角色为项目的所有者。点击创建后一个包含了你的私钥的json文件将下载到你的本地所指定的路径。
设置环境变量GOOGLE_APPLICATION_CREDENTIALS为你保存以上json文件的路径。比如mac os用户在terminal中输入如下(引号中为你本地的json文件路径):
export GOOGLE_APPLICATION_CREDENTIALS="/home/user/Downloads/service-account-file.json"
5 当以上都设置完毕后,接下来要下载和初始化cloud sdk啦
https://cloud.google.com/sdk/docs/
下载完成后,初始化cloud sdk~
在terminal中进入你存放sdk的路径,输入一下
> sh ./google-cloud-sdk/install.sh

选择是否帮助完善cloud sdk
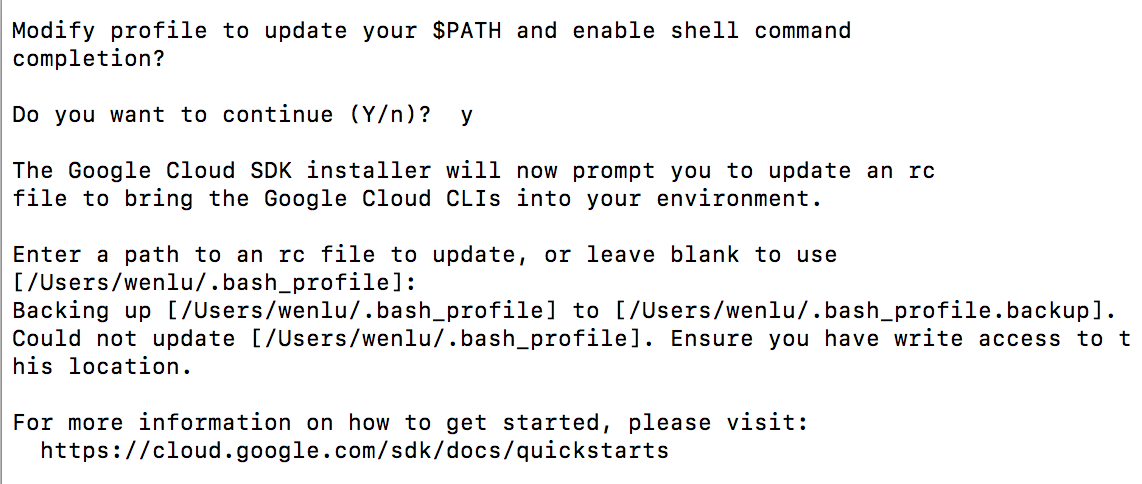
选择是否需要更新$PATH, 如果更新你可以在命令行中任何路径下使用google cloud命令。然后会提示你输入你个路径,或直接为空使用默认。
这里我选择的是为空。如果是mac用户不知道会不会遇到和我相同的问题,就是路径没有设置成功。我的解决办法如下:
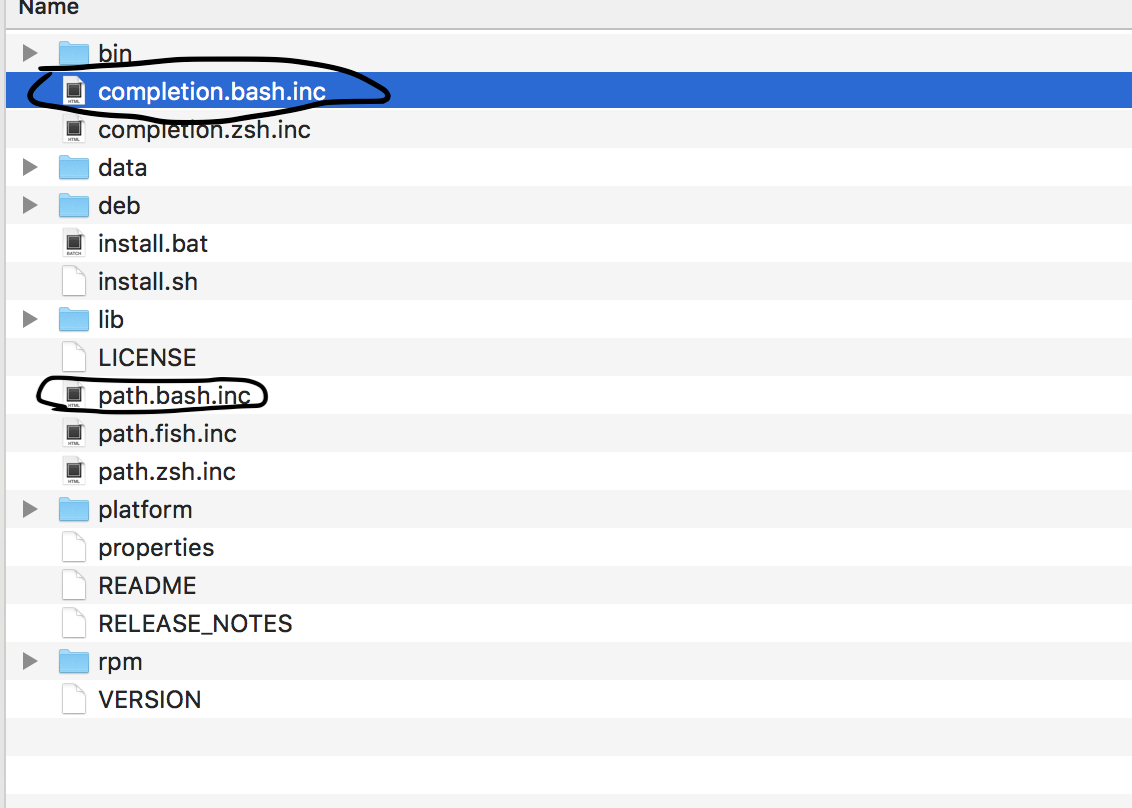
在命令行中source completion.bash.inc 和 path.bash.inc两个文件。
USER-MBP:Google_Cloud_Compute_Engine$ source /Users/.../.../.../google-cloud-sdk/path.bash.inc
USER-MBP:Google_Cloud_Compute_Engine$ source /Users/.../.../.../google-cloud-sdk/completion.bash.inc
运行gcloud init初始化sdk
./google-cloud-sdk/bin/gcloud init
以上我们完成了想要使用谷歌深度学习平台的配置,总结一下就是创建一个项目,设置结算信息关联项目,创建服务账号密钥并设置环境变量, 下载初始化sdk。
接下来的重头戏当然就是把我们本地的代码放到谷歌云上训练啦~~~
1.打包你的训练模型
https://cloud.google.com/ml-engine/docs/packaging-trainer
第一步 使用推荐的项目结构

创建一个空的setup.py文件, 在trainer文件夹中创建一个空的__init__.py
2. 确认你云端上保存你的所用中间或最终输出结果(比如checkpoint文件)的路径, 这一步很重要!!!!否则你不知道在哪找你训练的参数呀!
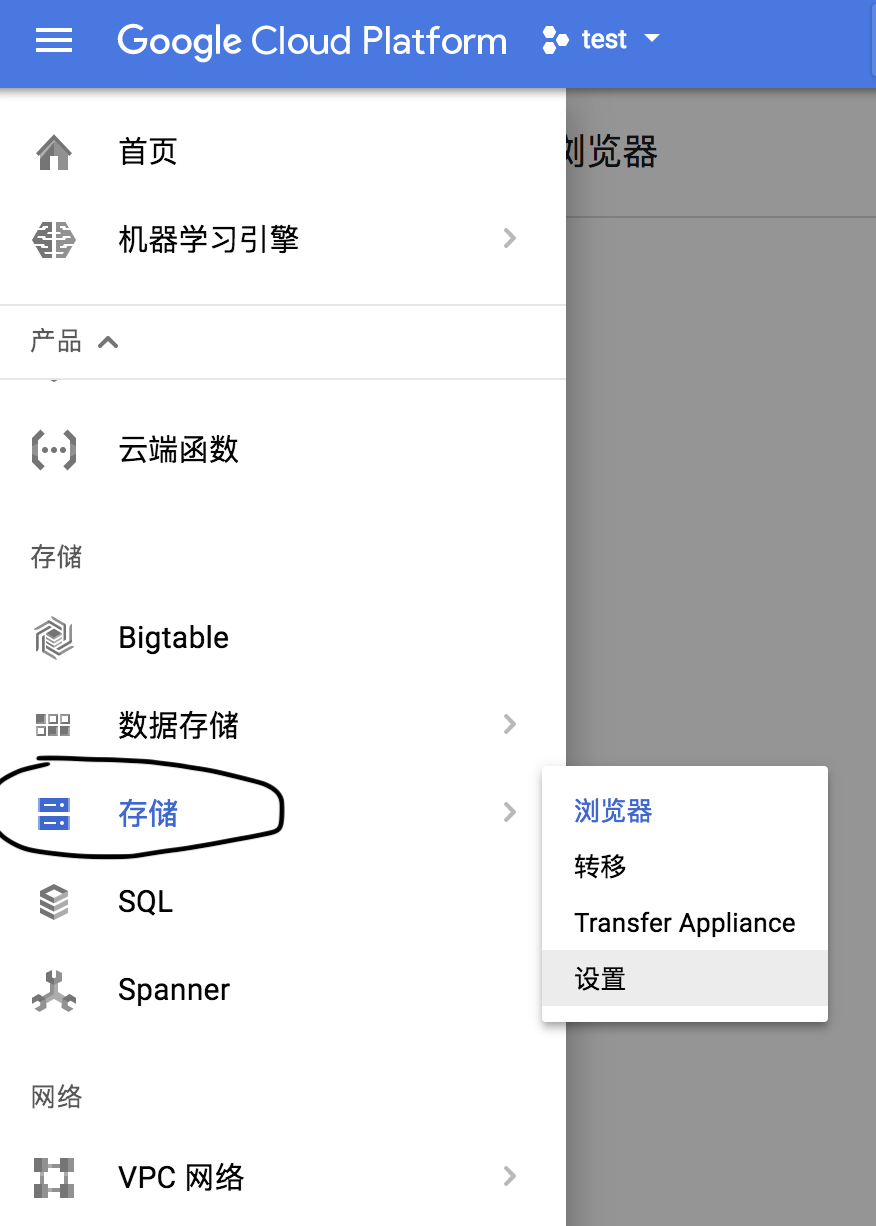
在Google Cloud Platfrom左侧的导航栏中选择存储,创建存储分区

如上图所示,创建一个分区,选择regional,位置为us-east1可以使用gpu!!!而且比较便宜呀~~~
这样你在云端上就有了一个路径,比如我的情况就是gs://yzm_bucket
创建完成后,在你本地的代码中把你所有的输出路径都要替换成你的云端路径。这样在云端训练时才能把结果也保存在云端。
比如这样:path_to_latest_checkpoint_file = saver.save(sess, 'gs://yzm_bucket/log/latest.ckpt')
3. 确认本地代码中所需要的依赖
需要查看cloud ml runtime的版本信息 -> https://cloud.google.com/ml-engine/docs/runtime-version-list
目前的化Cloud ML runtime最新版本为1.6, 支持python 3.5。 查看你想使用的版本有没有所有你所依赖的包。 如果你的程序用pip安装了一些python模块(如pillow)但是使用的runtime版本中并不包含这些包,你需要手动设置你的包依赖。 请在setup.py中(如果你用标准的项目结构,就是你traniner的根目录即它的上一层)添加如下信息:
from setuptools import find_packages
from setuptools import setup REQUIRED_PACKAGES = ['some_PyPI_package>=1.0'] setup(
name='trainer',
version='0.1',
install_requires=REQUIRED_PACKAGES,
packages=find_packages(),
include_package_data=True,
description='My trainer application package.'
)
4. 使用gcloud ml-engine jobs submit training提交你要运行的训练任务
https://cloud.google.com/sdk/gcloud/reference/ml-engine/jobs/submit/training
gcloud ml-engine jobs submit training JOB
--module-name=MODULE_NAME [--config=CONFIG] [--job-dir=JOB_DIR] [--labels=[KEY=VALUE,…]]
[--package-path=PACKAGE_PATH] [--packages=[PACKAGE,…]] [--python-version=PYTHON_VERSION]
[--region=REGION] [--runtime-version=RUNTIME_VERSION] [--scale-tier=SCALE_TIER]
[--staging-bucket=STAGING_BUCKET] [--async | --stream-logs] [GCLOUD_WIDE_FLAG …] [-- USER_ARGS …]
比如像这样:
$ gcloud ml-engine jobs submit training my_job \
--module-name trainer.task \
--staging-bucket gs://my-bucket \
--package-path /my/code/path/trainer \
--packages additional-dep1.tar.gz,dep2.whl
gcloud ml-engine jobs submit training 后面是任务的名称(唯一标识任务的名称,不可以和之前提交的任务名重复),
module-name 为trainer.task, task就是你程序的入口python文件,在标准项目结构中叫做task.py的那个文件, trainer为标准项目结构中trainer文件夹。
staging-bucket 为google cloud上的路径,指定你把你的代码文件上传到哪在运行程序的时候可以在那个路径上找到你的源码。这里存在了叫做my-bucket的云路径上。
package-path 为你本地到trainer文件夹的路径,也就是你把trainer文件夹存在了本地的什么位置 除了以上参数你可能还需要以下参数
[--job-dir=JOB_DIR]
job-dir 指明了在云端你想要把输出存在什么位置, 如果你已经在代码中指明,此步可以省略。
[--python-version=PYTHON_VERSION]
python-version:如果你是用python 3,请明确在这里声明否则默认为python 2
[--runtime-version=RUNTIME_VERSION]
runtime-version:最新版本为1.6,支持python 3
如果你考虑使用GPU,也请设置参数如下。
https://cloud.google.com/ml-engine/docs/using-gpus
To use GPUs in the cloud, configure your training job to access GPU-enabled machines:
Set the scale tier to
CUSTOM.Configure each task (master, worker, or parameter server) to use one of the GPU-enabled machine types below, based on the number of GPUs and the type of accelerator required for your task:
standard_gpu: A single NVIDIA Tesla K80 GPUcomplex_model_m_gpu: Four NVIDIA Tesla K80 GPUscomplex_model_l_gpu: Eight NVIDIA Tesla K80 GPUsstandard_p100: A single NVIDIA Tesla P100 GPU (Beta)complex_model_m_p100: Four NVIDIA Tesla P100 GPUs (Beta)
在本地保存config.yaml文件,并在里写入你想要指定的gpu配置信息。
trainingInput:如果是新手
scaleTier: CUSTOM
masterType: complex_model_m_gpu
workerType: complex_model_m_gpu
parameterServerType: large_model
workerCount: 9
parameterServerCount: 3scaleTier推荐使用BASIC_GPU而不是CUSTOM
然后在命令中多加一个参数
--config /my/code/path/to/config.yaml
比如我的情况,代码如下:
gcloud ml-engine jobs submit training beta330 --module-name trainer.task --staging-bucket gs://yzm_bucket --package-path /Users/wenlu/PycharmProjects/Google_Cloud_Compute_Engine/yzm_recognition/trainer --python-version=3.5 --runtime-version=1.6 --config /Users/wenlu/PycharmProjects/Google_Cloud_Compute_Engine/yzm_recognition/trainer/config.yaml
这就是在谷歌云端跑tensorflow的全部啦~~~~
成功的化,terminal会出现以下
Job [beta330] submitted successfully.
Your job is still active. You may view the status of your job with the command
$ gcloud ml-engine jobs describe beta330
or continue streaming the logs with the command
$ gcloud ml-engine jobs stream-logs beta330
jobId: beta330
state: QUEUED
在谷歌云端机器学习引擎中的job中出现如下:
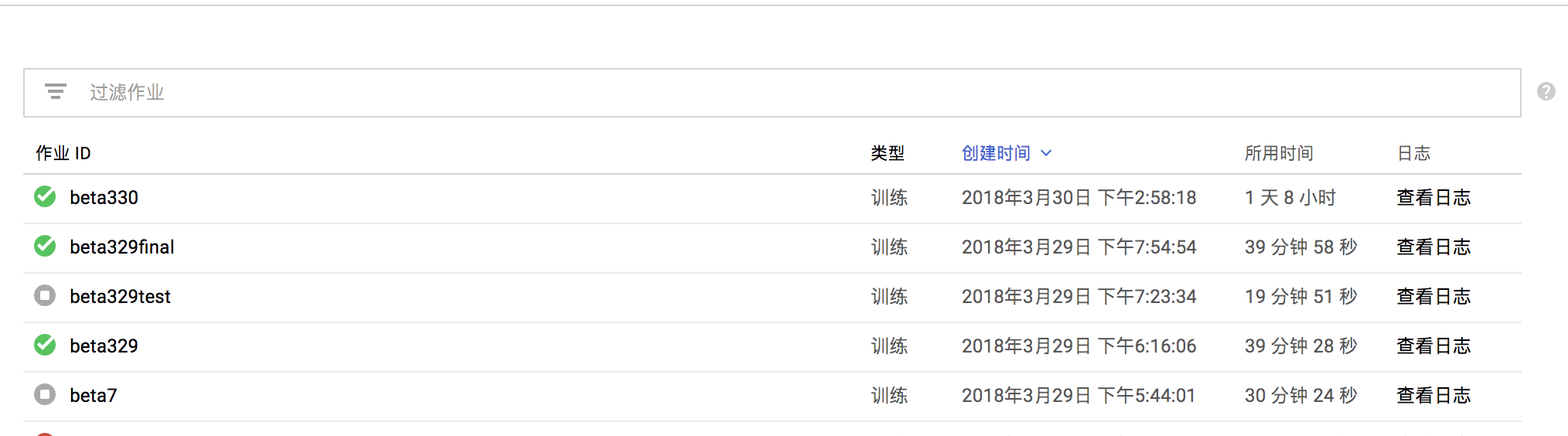
你可以即时的查看日志信息,什么地方出错了输出的loss是多少了准确率已经到多少了之类之类的~~如果失败了你也可以看到traceback来研究哪个地方导致程序出错了。
而在我的云端存储中,输出是这个样子的:

好啦~大概就是这样吧。如果你有任何疑问欢迎留言提问哈。
TensorFlow-谷歌深度学习库 手把手教你如何使用谷歌深度学习云平台的更多相关文章
- 不用写代码就能实现深度学习?手把手教你用英伟达 DIGITS 解决图像分类问题
2006年,机器学习界泰斗Hinton,在Science上发表了一篇使用深度神经网络进行维数约简的论文 ,自此,神经网络再次走进人们的视野,进而引发了一场深度学习革命.深度学习之所以如此受关注,是因为 ...
- SpringCloud学习之手把手教你用IDEA搭建入门项目(三)
本篇博客是承接上一篇<手把手教你用IDEA搭建SpringCloud入门项目(二)>,不清楚的请到我的博客空间查看后再看本篇博客,上面两篇博客成功创建了一个简单的SpringCloud项目 ...
- SpringCloud学习之手把手教你用IDEA搭建入门项目(二)
本篇博客是承接上一篇<手把手教你用IDEA搭建SpringCloud入门项目(一)>,不清楚的请到我的博客空间查看后再看本篇博客 1)先创建一个Eureka服务注册中心模块,用来作为服务的 ...
- SpringCloud学习之手把手教你用IDEA搭建入门项目(一)
SpringCloud简单搭建 jdk:1.8开发工具:IDEA注:需要了解springcloud 1.创建最简单的Maven项目 1)开始创建一个新的项目 2)创建一个空模板的maven项目,用 ...
- 《手把手教你学C语言》学习笔记(2)---学习C语言的目标和方法
一.学习C语言的目标主要是: 熟练掌握C语言的关键字,语法规则,程序控制等: 掌握基本的数据结构,数组.链表.栈和队列等: 掌握C语言中指针和内存.数组与指针.函数与指针.变量和指针.结构体和指针.硬 ...
- 《手把手教你学C语言》学习笔记(1)---C语言的特点
学习C语言的原因,主要是需要使用C语言编程,我用故我学,应该是最主要的原因了. C语言的定位:C语言严格意义上只能算是中级语言,是面向过程编程语言的集大成者,虽然这种语言有很多的问题,但总体而言是瑕不 ...
- 手把手教你学node.js之学习使用外部模块
学习使用外部模块 目标 建立一个 lesson2 项目,在其中编写代码. 当在浏览器中访问 http://localhost:3000/?q=alsotang 时,输出 alsotang 的 md5 ...
- 《手把手教你学C语言》学习笔记(8)--- 运算符和表达式
C语言编程的核心是指针和库,而库的核心就是函数,函数的基本组成部分就是语句. C语言合法表达式加上分号(语句结束符)构成C函数的基本部分语句.如果只有分号没有表达式就构成空语句,空语句常常用来形成占位 ...
- 《手把手教你学C语言》学习笔记(4)---代码规范
编程过程中需要遵守编译器的各种约定,例如以下代码: 1 #include <stdio.h> 2 3 int main(int argc, char **argv) 4 { 5 print ...
随机推荐
- 在VCS仿真器中使用FSDB[转载]
来源:https://www.cnblogs.com/catannie/p/8099331.html FSDB(Fast Signal Database)是Verdi支持的文件格式,用于保存仿真产生的 ...
- 如何解决Reporting Services目录数据库文件存在的问题
打开MSSQL数据库管理系统的安装目录,例如:C:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA,C:\是你 ...
- Python模块之hashlib模块、logging模块
一.hashlib模块 hashlib模块介绍:hashlib这个模块提供了摘要算法,例如 MD5.hsa1 摘要算法又称为哈希算法,它是通过一个函数,把任意长度的数据转换为一个长度固定的数据串,这个 ...
- HTTP请求过程-域名解析和TCP三次握手建立链接
我们在浏览器输入http://www.baidu.com想要进入百度首页,但是这是个域名,没法准确定位到服务器的位置,所以需要通过域名解析,把域名解析成对应的ip地址,然后通过ip地址查找目的主机.整 ...
- python xlsxwriter库生成图表的应用
xlsxwriter可能用过的人并不是很多,不过使用后就会感觉,他的功能让你叹服,除了可以按要求生成你所需要的excel外 还可以加上很形象的各种图,比如柱状图.饼图.折线图等. 请看本人生成的: 这 ...
- php基础知识(三)---常用函数--2017-04-16
常用函数如下:(红色为重点) 1.取字符串的长度 echo strlen("hello"); 2.echo strcmp("字符串1","字符串2&q ...
- Throwable.异常
异常: 在运行期间发生的不正常情况. 在JAVA中用类的形式对异常的情况进行了类的封装. 这些描述不正常情况的类就称为异常类. 异常类就是java通过面向对象的思想将问题封装成了对象.用异常类对问题进 ...
- mysql备份并转移数据
一.使用mysqldump进行备份 直接输入命令mysqldump会发现提示命令不存在,是由于系统默认会查找/usr/bin下的命令,如果这个命令不在这个目录下, 自然会找不到命令,并报错.知道了问题 ...
- table_rows查询优化
日常应用运维工作中,Dev或者db本身都需要统计表的行数,以此作为应用或者维护的一个信息参考.也许很多人会忽略select count(*) from table_name类似的sql对数据库性能的影 ...
- Knowledge point
静态网页的特点:以htm.html.sbtml.xml.js.css等为后缀扩展名. 1)程序在客户浏览器端解析,不需要读取数据库,性能和效率较高: 2)后端没有数据库支持,所以和用户的交互性差,功能 ...