R语言-用户细分
案例:通过使用R语言的聚类算法将用户进行合理的划分,找出对超市贡献度,光临度最高的优质客户,对后期的推广有更深远的影响
1.导入包
library(dplyr)
library(reshape2)
library(cluster)
library(fpc)
library(mclust)
2.加载数据集
options(digits = 18) #小数可以显示到第18位
lss_all_cust_ls_info <- read.table('E:\\Udacity\\Data Analysis High\\R\\R_Study\\高级课程代码\\数据集\\第一天\\1顾客细分\\lss_all_cust_ls_info.txt',header=T,sep='\t')
head(lss_all_cust_ls_info)
lss_cust_payment <- read.table('E:\\Udacity\\Data Analysis High\\R\\R_Study\\高级课程代码\\数据集\\第一天\\1顾客细分\\lss_cust_payment.txt',header=T,sep='\t')
head(lss_cust_payment)
lss_cust_spend_info <- read.table('E:\\Udacity\\Data Analysis High\\R\\R_Study\\高级课程代码\\数据集\\第一天\\1顾客细分\\lss_cust_spend_info.txt',header=T,sep='\t')
head(lss_cust_spend_info)
3.查看数据集
#客户信息
head(lss_all_cust_ls_info)
str(lss_all_cust_ls_info)
summary(lss_all_cust_ls_info) #支付信息
head(lss_cust_payment)
str(lss_cust_payment)
summary(lss_cust_payment) #商品信息
head(lss_cust_spend_info)
str(lss_cust_spend_info)
summary(lss_cust_spend_info)
4.数据集预处理(将三个数据集合并成一个数据集,通过cust_id进行关联)
data_cat_wide = dcast(lss_cust_spend_info,cust_id~ls_category,value.var = "ls_spd_share")
head(data_cat_wide)
names(data_cat_wide)
data_cat_wide = data_cat_wide[,-2]
#dim(data_cat_wide)
#summary(data_cat_wide) data_payment_wide = dcast(lss_cust_payment,cust_id~payment_category_desc,value.var = "payment_amount_share")
head(data_payment_wide)
#dim(data_payment_wide) ### 3. join data
##把三张表进行合并,通过cust_id来进行列合并
cust_all = merge(lss_all_cust_ls_info,data_payment_wide, by="cust_id")
cust_all_fnl = merge(cust_all,data_cat_wide, by="cust_id")
## 查看合并后的结果
head(cust_all_fnl,10) dim(cust_all_fnl)
summary(cust_all_fnl)

结论:将所有的纵向表转换成横向表,同时把所有数据集的所有字段汇总到一张表
5.数据清洗
## 提取出客户ID和性别
cust_id = cust_all_fnl[,1]
cust_sex = cust_all_fnl[,2] ## 去除客户ID和性别,同时将除了这两个列之外的缺失值填充0
cust_all_fnl2 = cust_all_fnl[,-c(1,2)]
cust_all_fnl2[is.na(cust_all_fnl2)] =0 ## 把性别缺失值变成1.5
cust_sex [is.na(cust_sex )] =1.5 ##把处理后的数据合并
cust_all_fnl = data.frame(cust_id,cust_sex,cust_all_fnl2)
head(cust_all_fnl)
#summary(cust_all_fnl) ## 对于异常值进行处理,如果百分比小于0,则变成0,如果百分比大于1 则等于1
dim(cust_all_fnl)
for(i in 7:dim(cust_all_fnl)[2])
{
cust_all_fnl[,i][cust_all_fnl[,i]<0] = 0
cust_all_fnl[,i][cust_all_fnl[,i]>1] = 1
} dim(cust_all_fnl)
## 去除礼品字段,因为0值较多,会给后期的聚类操作带来影响
mydata = cust_all_fnl[,-28]
dim(mydata)
summary(mydata)

结论:生成一张所有属性的统计值,查看是否还有NA的值
6.选择K值
# 如果数据集中的变量过多,要先使用主成分分析找到影响因子在95%以上的列即可
# 选择K使得差异最小,下降幅度最小
comp = scale(mydata[,-1]) wss <- (nrow(comp)-1)*sum(apply(comp,2,var)) for (i in 2:15) wss[i] <- sum(kmeans(comp,centers=i)$withinss)
plot(1:15, wss, type="b", xlab="Number of Clusters",ylab="Within groups sum of squares")
7.使用K-media找到中心点的坐标
# 如果数据量较大,首先应对数据进行抽样,然后在找中心点
s = sample(1:dim(mydata)[1],2000,replace = F)
clus = 4
medk = pam(scale(mydata[s,-1]),clus,trace=T)
plotcluster(scale(mydata[s,-1]),medk$clustering)
table(medk$clustering)
Kcenter = medk$medoids

8.使用K-mean进行聚类
# 每次抽取1000个点进行聚类
k = kmeans(scale(mydata[,-1]),centers = Kcenter,nstart = 25,iter.max = 1000)
plotcluster(scale(mydata),k$cluster)
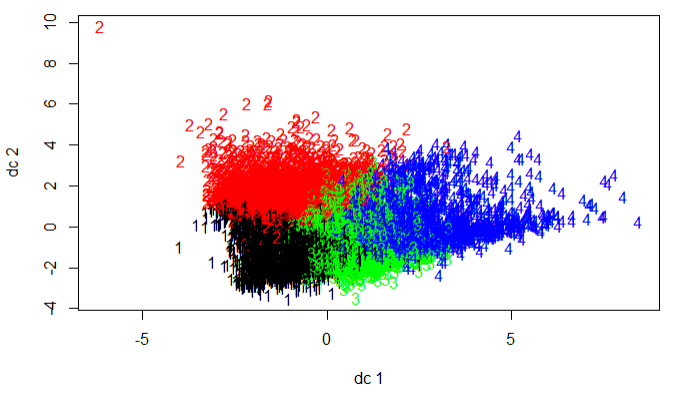
结论:k-means的好处是速度快,但是中心点不稳定,k-media的好处是中心点稳定但是速度慢,此案例结合两者,先通过抽样的方式找出中心点,再将中心点带入到k-means中,即可得到聚类的样本
9.生成结果
# 对每个变量求均值
mydata_mean_sd = aggregate(scale(mydata),by=list(k$cluster),FUN=mean)
head(mydata_mean_sd)
10.输出到本地
# 写入到csv文件
write.csv(mydata_mean_sd,'E:\\Udacity\\Data Analysis High\\R\\R_Study\\高级课程代码\\数据集\\第一天\\1顾客细分\\mydata_mean_sd.csv') # 写入数据库
data_sql <- data.frame(mydata, cluster=k$cluster)
data_sql_out = data_sql[,c(1,dim(data_sql)[2])]
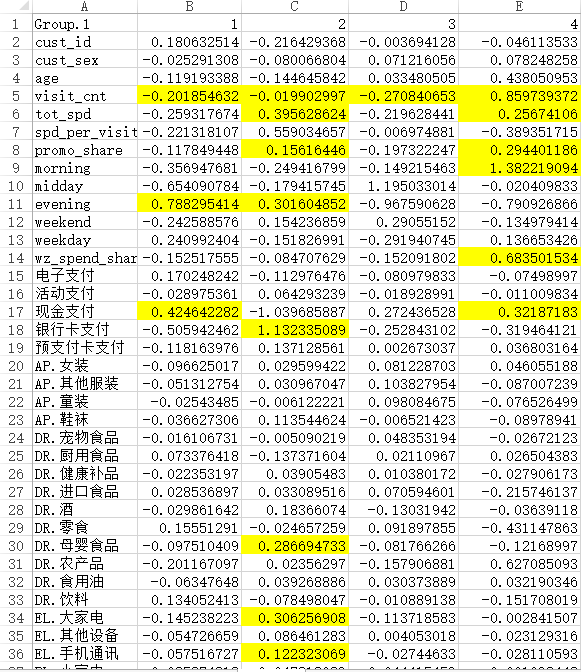

结论:通过生成的csv文件,我们可以得出如下结论:
通过tot_spend可以得出2,4组的顾客对超市的贡献度较大,其中2类客户是最应该保留的优质客户
通过promo_share可以得出4类客户对折扣较为敏感
通过wz_spend_share可以得出4类用户最喜欢参与打5折的活动
通过对比购物时间段来看1,2类用户喜欢晚上购物,3类用户喜欢下午的时候购物,4类用户喜欢早上购物
通过对比支付方式1,3,4组大部分是现金支付,2组客户喜欢用银行卡支付
通过对比消费商品可得出结论:
2类客户喜欢购买大家电,手机通讯设备,母婴食品的高价格产品
4类客户喜欢购买生鲜,蔬菜等农产品
1类客户喜欢购买一些零食,饮料之类的商品
3类客户是散客,会不定期的购买一些商品
针对1类客户,在下午的时间段可以对零食,饮料进行一些促销和活动
针对2类客户,在晚上的时间段,一些大商品的家电,手机等高价格的产品做一些捆绑销售,同时定期去推送一些新的手机,电器,母婴食品的信息,会有不错的销售业绩
针对4类客户,在早上对农产品,生鲜,肉类等商品可以进行一些打折,买一赠一的,兑换券等活动,提升生鲜商品的业绩
针对3类用户,不是超市的重点客户,暂时不知道如何提升到店率
数据集:https://github.com/Mounment/R-Project
R语言-用户细分的更多相关文章
- 【转】R语言知识体系概览
摘要:R语言的知识体系并非语法这么简单,如果都不了R的全貌,何谈学好R语言呢.本文将展示介绍R语言的知识体系结构,并告诉读者如何才能高效地学习R语言. 最近遇到很多的程序员都想转行到数据分析,于是就开 ...
- R语言——包的添加和使用
R是开源的软件工具,很多R语言用户和爱好者都会扩展R的功能模块,我们把这些模块称为包.我们可以通过下载安装这些已经写好的包来完成我们需要的任务工作. 包下载地址:https://cran.r-proj ...
- R语言实战实现基于用户的简单的推荐系统(数量较少)
R语言实战实现基于用户的简单的推荐系统(数量较少) a<-c(1,1,1,1,2,2,2,2,3,3,3,4,4,4,5,5,5,5,6,6,7,7) b<-c(1,2,3,4,2,3,4 ...
- 微软的R语言发行版本MRO及开发工具RTVS
(此文章同时发表在本人微信公众号"dotNET每日精华文章",欢迎右边二维码来关注.) 题记:微软在收购R语言的开发商后,也独立发行或在自己的产品中集成了R语言,这里就介绍下它们包 ...
- R 语言编码风格指南
R 语言是一门主要用于统计计算和绘图的高级编程语言.这份 R 语言编码风格指南旨在让我们的 R代码更容易阅读.分享和检查.以下规则系与 Google 的 R 用户群体协同设计而成. 概要: R编码风格 ...
- Ubuntu下安装R语言和开发环境
[简介]R是用于统计分析.绘图的语言和操作环境.R是属于GNU系统的一个自由.免费.源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具. [R语言的安装]官网:https://www.r-pr ...
- 大数据平台R语言web UI应用架构 设计与开发
1. 系统拓扑图 在日常业务分析中,R是非常常用的分析工具,而当数据量较大时,用R语言需要需用更多的时间来完成训练模型,spark作为大规模数据处理框架,采用内存计算,可以短时间内完成大量的数据的处理 ...
- R语言介绍
R语言简介 R语言是一种为统计计算和图形显示而设计的语言环境,是贝尔实验室(Bell Laboratories)的Rick Becker.John Chambers和Allan Wilks开发的S语言 ...
- 来自 Google 的 R 语言编码风格指南
来自 Google 的 R 语言编码风格指南R 语言是一门主要用于统计计算和绘图的高级编程语言. 这份 R 语言编码风格指南旨在让我们的 R 代码更容易阅读.分享和检查. 以下规则系与 Google ...
随机推荐
- Hadoop压缩
为什幺要压缩? 压缩会提高计算速度?这是因为mapreduce计算会将数据文件分散拷贝到所有datanode上,压缩可以减少数据浪费在带宽上的时间,当这些时间大于压缩/解压缩本身的时间时,计算速度就会 ...
- openstack-ocata-身份验证2
Identity service 一.身份服务概述 OpenStack身份管理服务提供一个单点集成身份验证.授权和目录服务. 身份服务通常是第一个服务用户与之交互.一旦身份验证,最终用户可以使用自己的 ...
- 区块链 PoW 与 PoS 的纷争
最近在研究区块链,可能会有一些非前端文章,感兴趣的可以关注关注哟. 有关注区块链的,肯定会经常看到这两个名词 -- PoW 与 PoS.但是很多人对他们的含义的理解存在很多偏差.那么他们的含义与区别是 ...
- android判断网络是否可用
private boolean isNetworkConnected(Context context) { ConnectivityMannger cManager = (ConnectivityMa ...
- <CEPH中国-深圳站-技术交流会演讲PPT> YY云平台Ceph Block应用实践 & 我写的书 《CEPH实战》
YY云平台Ceph Block应用实践 http://s3.yyclouds.com/public/YY%E4%BA%91%E5%B9%B3%E5%8F%B0Ceph%E5%AE%9E%E8%B7%B ...
- linux redis基础应用 主从服务器配置
Redis基础应用 redis是一个开源的可基于内存可持久化的日志型,key-value数据库redis的存储分为内存存储,磁盘存储和log文件三部分配置文件中有三个参数对其进行配置 优势:和memc ...
- zTree实现地市县三级级联报错(二)
zTree实现地市县三级级联 1.具体报错如下 2014-05-10 23:29:13 [com.mchange.v2.async.ThreadPoolAsynchronousRunner$PoolT ...
- Caused by:org.hibernate.DuplicateMappingException:Duplicate class/entity/ mapping
1.错误描述 java.lang.ExceptionInInitializerError Caused by:org.hibernate.InvalidMappingException:Could n ...
- 2017java文件操作(读写操作)
java的读写操作是学java开发的必经之路,下面就来总结下java的读写操作. 从上图可以开出,java的读写操作(输入输出)可以用"流"这个概念来表示,总体而言,java的读写 ...
- Django学习-15-Cookie
Cookie 1.如果没有cookie,那么所有的网站都不能登录 2.客户端浏览器上的文件,keyvalues形式存储的,类似字典 ...