Python爬虫之urllib模块2
Python爬虫之urllib模块2
本文来自网友投稿
作者:PG-55,一个待毕业待就业的二流大学生。
看了一下上一节的反馈,有些同学认为这个没什么意义,也有的同学觉得太简单,关于BeautifulSoup和lxml在后续的教程都会有。这里我记录的是我学习和思考的一个过程,我不是编程高手,非常感谢玄魂老师能给我这个机会,在公众号发布这种入门文章。
上一课我们成功的下载了页面的第一篇文章,这一课我们的目标是怎么把第一页的所有文章都下载下来。还是先继续我们上一节课的内容。我们这次爬取的网页还是http://tuilixue.com/zhentantuilizhishi/list_4_1.html
上一次课我们说了怎么去获取第一条的文章链接,现在我们再来爬取本页后面剩下的链接。我们先来看看上次我们爬取链接用的代码。

获取后面的链接我们能不能如法炮制呢,我们先来试试。我们把代码写成下面那样
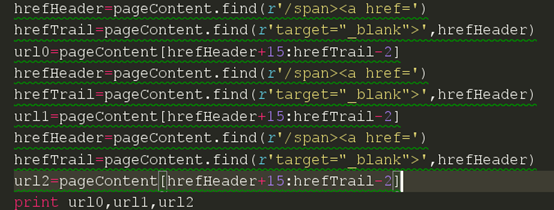
然后我们现在来试试
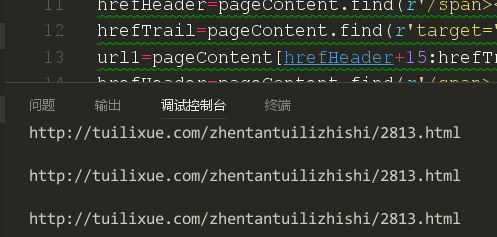
结果我们发现我们试图获取的三条链接都是一样的,可以看出,这还是本页的第一篇文章的链接。证明我们这种方法是不可行的。我们回想一下上一节课我们讲的定位链接使用函数

就是这个find函数,我们看看帮助,我们发现了我们可以自定义开始寻找的下标和寻找结束的下标。我们从html里面发现我们想要爬取的链接相隔都不是很远,都处在同一个div下面。于是我们来试试,从第一条链接后面开始寻找第二条链接。
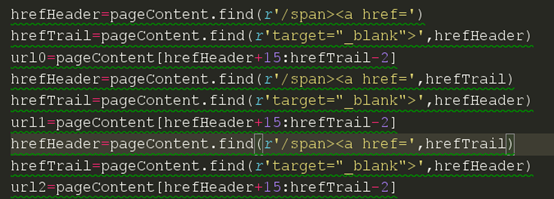
这里我们要注意后面两条代码,我们选择了开始的下标是从上一条链接的尾部开始的。现在我们来试试是否可以获取正确的链接。
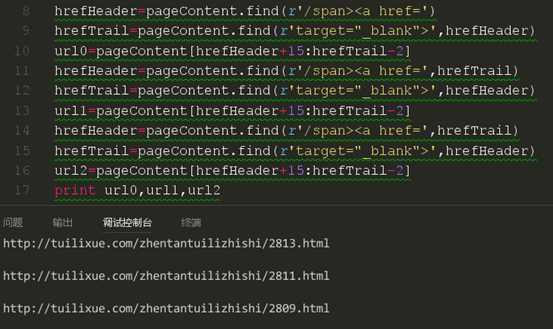
现在我们获取到了三条不同的链接,我们再通过对比html来看看我是否获取的是正确的链接。

从结果来看,我们的代码成功的获取了本页的前几篇文章的链接。关于怎么获取剩下的链接我们应该有头绪了。当然,这里一页只有10篇文章,也就是只有10个链接,我们可以把我们的获取链接的代码复制10次,可是如果一页有20篇,30篇,50甚至是100篇呢,难道我们也要将代码复制那么多的次数,肯定不能,也不科学。很多同学现在已经知道要用循环来做了,但是这个要怎么循环,从哪里循环呢?我们再来看看我们上面的代码,我们发现除了第一条链接获取的代码不一样,后面两条链接获取的代码都是一样的,这时我们就知道我们应该从第二条链接获取代码进行循环了。
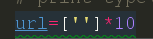
这里我们要先定义一个列表对获取的链接进行存储,因为是10篇文章,所以这里定义的就是一个10个元素的空的字符串列表。下面是我们循环的代码块。

这里结束一下我们为什么不是从0开始进行赋值,大家注意到没有,我们是从第二条文章链接看是循环的,那么第一条的文章链接在哪呢?当然是存储在了列表的第一个位置,也就是下标为0的那个位置了,关于range后面的范围,大家知道是包下不包上的就行了,就是说在range(x,y)的循环中,循环是从x开始,到y-1结束的,不包括y本身。我们现在来运行一下我们的代码看看是否获取的是正确的链接。
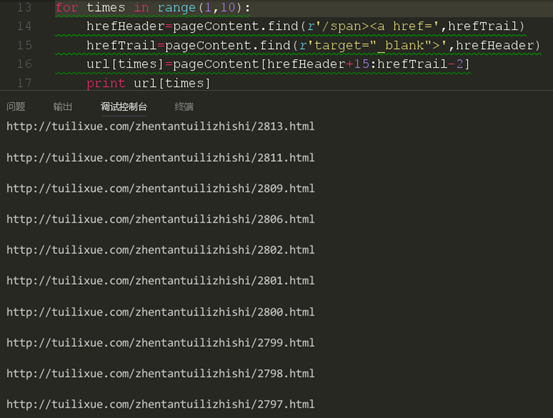
然后再次对比html

这时我们发现我们获取了链接是正确的,那么我们就要开始进行下载了。还是上一节课的代码,不过我们进行修改一些地方。因为上次只是单个链接,这次我们有一个链接列表,所以我们应该采取循环进行下载。我们要对下载重新写一个循环了。

我们现在来试试,这是上一节课我们成功下载的第一篇文章

我们现在删掉他。

现在我们看到文件夹里面是什么都没有的,我们现在开始下载。
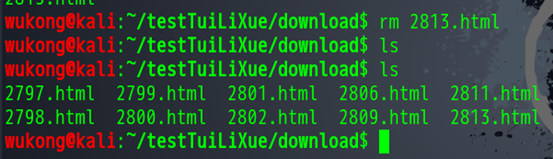
我们这就下载完了,我打开其中一个看看。还是注意地址栏上面的链接。
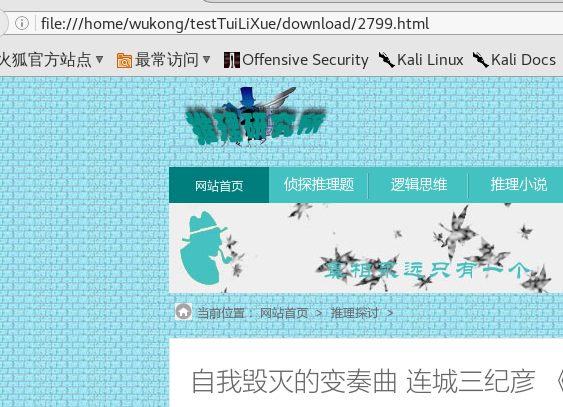

可以看出我们获取的文章是正确的。因为篇幅有限,我就不一个一个去打开截图了,大家自己可以根据自己实际环境敲一下代码。
类似的功能有很多值得改进的点,大家可以发表自己的观点,进行讨论。
Python爬虫之urllib模块2的更多相关文章
- Python爬虫之urllib模块1
Python爬虫之urllib模块1 本文来自网友投稿.作者PG,一个待毕业待就业二流大学生.玄魂工作室未对该文章内容做任何改变. 因为本人一直对推理悬疑比较感兴趣,所以这次爬取的网站也是平时看一些悬 ...
- Python爬虫教程-09-error 模块
Python爬虫教程-09-error模块 今天的主角是error,爬取的时候,很容易出现错,所以我们要在代码里做一些,常见错误的处,关于urllib.error URLError URLError ...
- python爬虫之urllib库(二)
python爬虫之urllib库(二) urllib库 超时设置 网页长时间无法响应的,系统会判断网页超时,无法打开网页.对于爬虫而言,我们作为网页的访问者,不能一直等着服务器给我们返回错误信息,耗费 ...
- python爬虫之urllib库(一)
python爬虫之urllib库(一) urllib库 urllib库是python提供的一种用于操作URL的模块,python2中是urllib和urllib2两个库文件,python3中整合在了u ...
- Python爬虫之urllib.parse详解
Python爬虫之urllib.parse 转载地址 Python 中的 urllib.parse 模块提供了很多解析和组建 URL 的函数. 解析url 解析url( urlparse() ) ur ...
- python爬虫之urllib库(三)
python爬虫之urllib库(三) urllib库 访问网页都是通过HTTP协议进行的,而HTTP协议是一种无状态的协议,即记不住来者何人.举个栗子,天猫上买东西,需要先登录天猫账号进入主页,再去 ...
- 孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块
孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块 (完整学习过程屏幕记录视频地址在文末) 从今天起开始正式学习Python的爬虫. 今天已经初步了解了两个主要的模块: ...
- 练手爬虫用urllib模块获取
练手爬虫用urllib模块获取 有个人看一段python2的代码有很多错误 import re import urllib def getHtml(url): page = urllib.urlope ...
- Python爬虫练习(requests模块)
Python爬虫练习(requests模块) 关注公众号"轻松学编程"了解更多. 一.使用正则表达式解析页面和提取数据 1.爬取动态数据(js格式) 爬取http://fund.e ...
随机推荐
- C++与Java通过WebService通信(上)
一. 前言 本篇讲述如果通过C++客户端访问Java服务端发布的SOAP模式的WebService接口.文档中的样例代码拷贝出去即可运行,所有的代码都是本地测试OK的:本文不但解决了接口调用的问题,同 ...
- body里面的onload和window.onload的区别
区别:body里面的onload是在“页面加载完成后执行的动作” window里面的onload是在“页面加载时执行的动作” 例子:在html页面中有一个大图片,想要在图片显示出来后提示一个消息框“图 ...
- 用js实现左右阴影的切换
<!doctype html><html><head><meta charset="utf-8"><title>无标题文 ...
- 分布式协调服务-Zookeeper
什么是 zookeeper? Zookeeper 是google的chubby一个开源实现,是hadoop的分布式协调服务 它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名 ...
- win10环境下利用pyinstaller把python代码(.py)打包成可执行文件(.exe)
前言 最近写了一个小小的检测程序,python写起来只需要短短一百行,可是打包起来就没有C那么容易了.下面记录一下我艰难的"打包"过程. 方法一:py2exe py2exe是一种经 ...
- WordPress制作圆形头像友情链接页面的方法
网上看见过很多种友情链接页面,我比较喜欢的是圆形头像的这种,先看看效果吧:传送门 就是这种上面是圆形的友链用户头像,下面是友链用户网站名,然后鼠标移上去头像会旋转,怎么实现这种效果呢?我在网上找了很多 ...
- 学习JAVA的几大优处
首先:简单:我们都知道Java是目前使用较为广泛的网络编程语言之一.他容易学而且很好用,如果你学习过C++语言,你会觉得C++和 Java很像,因为Java中许多基本语句的语法和C++一样,像常用的循 ...
- Android Studio设置字体和主题
步骤:File >> settings >> Appearance & Behavior >> Appearance >> ...
- Mybatis转义字符
Mybatis的sql语句中需要用到'>'或者'<'时,不能直接使用. < < 小于号 > > 大于号 & & 和 ' ' 单引号 ...
- java集合框架详解
java集合框架详解 一.Collection和Collections直接的区别 Collection是在java.util包下面的接口,是集合框架层次的父接口.常用的继承该接口的有list和set. ...