HashMap 你真的了解吗?
一. hashmap简介
HashMap是基于哈希表的Map接口的非同步实现。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。
HashMap 的实例有两个参数影响其性能:“初始容量” 和 “加载因子”。容量 是哈希表中桶的数量,初始容量 只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生 rehash 操作。
二. hashmap数据结构
大概了解hashmap之后,知道了hashmap的键值对映射,知道了hashmap的线程不安全,知道了hashmap的put,get方法。觉得自己足够了解hashmap了吗?并不是,接着,让我们先去了解一下hashmap的底层数据结构。
首先,ArrayList和LinkedList的数据结构我们非常了解
ArrayList :
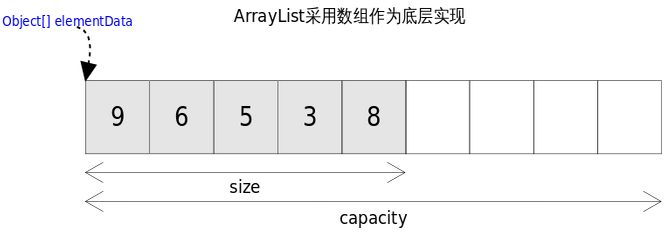 ArrayList 底层数据结构是数组,查询效率比较高,增删效率比较低。
ArrayList 底层数据结构是数组,查询效率比较高,增删效率比较低。
可以参照一下Arraylist的源码,可以看出Arraylist的数据结构为数组
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
LinkedList:
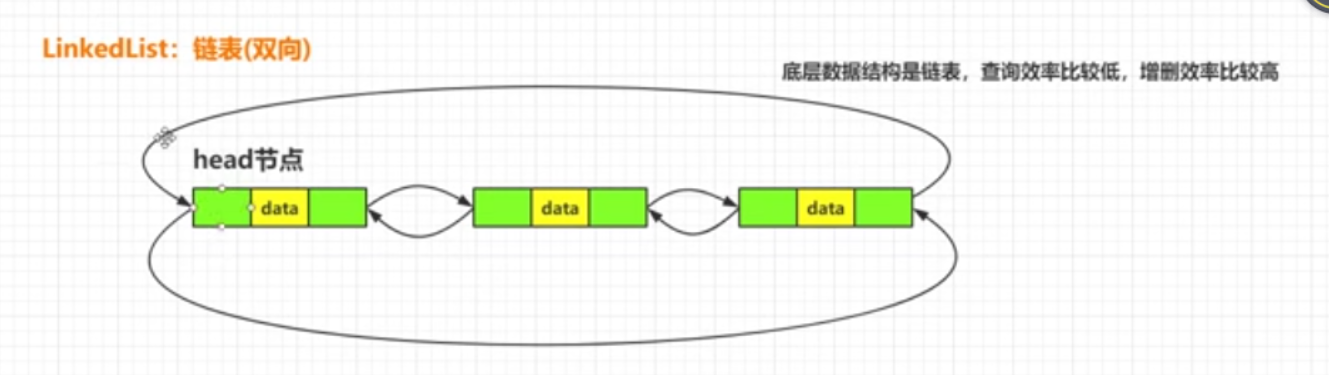
LinkedList 底层数据是链表(双向链表),查询效率比较低,增删效率比较高。
源码验证:可以看出LinkedList为双向链表结构
private static class Node<E> {
//数据
E item;
//后面数据
Node<E> next;
//前面数据
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
由此看来,ArrayList查询速度快,增删慢,LinkedList查询速度慢,增删快,那么,如果我们想查询速度快并且增删慢的话,将两种数据结构相结合,就是我们要讲的HashMap
HashMap : 数组 + 链表
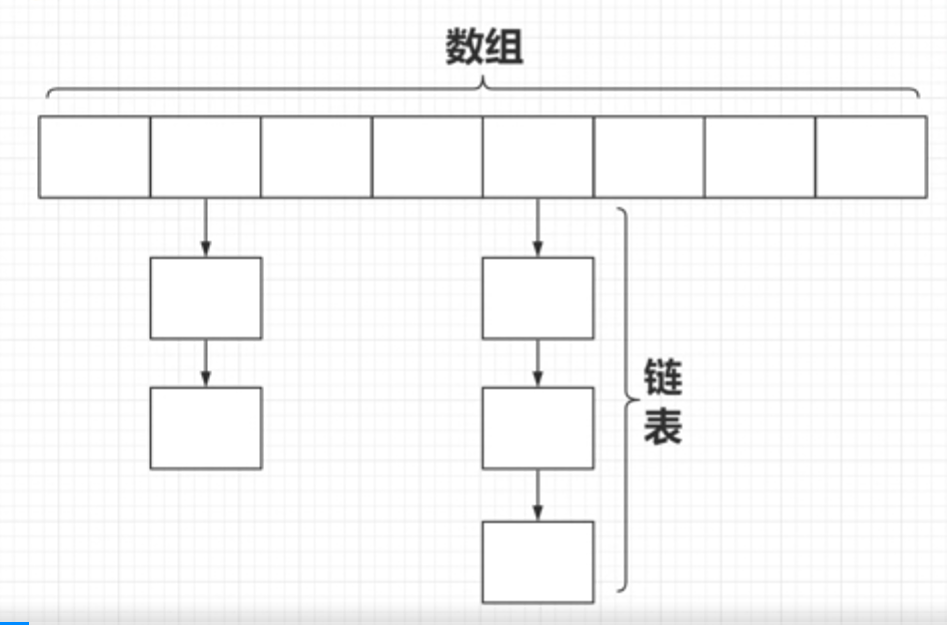
在这样的数据结构中,如果我们想存放数据的话,除了map中一定要有的Key和Value,还要有指向下个单元的next,根据刚才数据结构的分析,可以猜想到Hashmap的存储单元应该是这样的:
Class Node{
Key;
Value;
Node next;
}
让我们带着我们的猜想去看一下HashMap的源码,果然,我们的猜想是正确的,源码如下
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*
* 基本的hash存储单元
/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
} public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; } public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
} public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
} public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
大家看到源码中的变量,正如我们所猜想的一样,有Key、Value还有Node<K,V> next,然后我们发现还有一个变量int hash我们不太清楚,这个等下再提。
那么,在HashMap中,数组和链表究竟是怎样表示的?在源码中是如何体现的呢?我们接着去猜想验证。
1. 数组的表示
平时我们表示数组,如字符串数组,是String[],整型数组是Integer[],那在HashMap中,他的基本单元是node,那假如我们是HashMap的源码编写人员,那么我们可以写成
Node[] table;
table是我们随意取的变量值。接着,我们去源码中去看看在HashMap中数组是如何定义表示的:
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table;
果然和我们猜想的一样,在HashMap中的数组是以Node<K,V>[]表示的。(transient关键字是不进行序列化的意思)
2. 数组的大小是如何定义设置的呢
初始化大小:
/**
* The default initial capacity - MUST be a power of two.必须是2的n次幂
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
这里我们可以看到数组的初始化大小为 1 << 4 ,这里是个位运算,1 << 4 是 1000,转化为十进制是16(位运算更快一些)
最大容量:
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
当数组的大小如果不够用了,就要进行扩容。但是并不是全部都用完了再去扩容,如果全部用完再去扩容的话,性能会下降,存取效率也会受到影响。在HashMap中,如果用了数组大小的0.75倍,也就是四分之三的容量之后,就需要扩容
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
如数组大小定义为16,当超过12的时候,就要求去进行扩容,那么在HashMap中肯定会有一个值去记录目前占用的空间内存:
/**
* The number of key-value mappings contained in this map.
*/
transient int size;
我们用size来记录目前占用的空间内存,大家看一下HashMap中最常用的put方法中有这么一串代码:
if (++size > threshold)
resize();
// (The javadoc description is true upon serialization.
// Additionally, if the table array has not been allocated, this
// field holds the initial array capacity, or zero signifying
// DEFAULT_INITIAL_CAPACITY.)
int threshold;
这串代码的含义是什么呢?
每当我们往HashMap中put一个值后,size就会增加1,这个threshold我们通过英文注释可以了解到,这个变量就是我们之前说的那个要求扩容的临界值,是现有内存的0.75倍。当现在的内容超过这个临界值时,就需要进行扩容了。
3.链表的长度是如何限制的呢?
让我们去源码中看一下在Hashmap中链表的长度是如何限制的呢?
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*/
static final int TREEIFY_THRESHOLD = 8;
在源码中我们可以看到HashMap链表的长度限制为8。但是,通过英文注释我们可以看到,当链表的长度并不是不能超过8,当长度大于8时,数据结构会变形,表现形式就变成了红黑树(JDK1.8之后)。
三. 源码分析
基本的数据结构和Hashmap的设计思想我们已经大概了解了,现在我们要去正式的走近HashMap的源码了
HashMap最核心的代码肯定是我们经常用的put和get方法。
put方法:
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>.
* (A <tt>null</tt> return can also indicate that the map
* previously associated <tt>null</tt> with <tt>key</tt>.)
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
在put方法中,key和value这两个参数我们已经了解了,那么,这个hash(key)是什么含义呢?
首先,我们要先考虑一个问题,每当一个node结点进入HashMap中时,究竟该放入哪里呢?
结论就是:这个key值通过这个hash函数过滤之后的数值就是存放位置的一个标识,让我们去看一下这个hash函数是如何实现的
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
从这里我们可以看出,这个不仅仅是得到key的hashcode值那么简单,还做了一些操作,那么为什么要如此复杂的计算这个数值呢?
这是因为hashcode容易重复,不同的元素存储时容易处在同一个数组的下标位置,还有一个问题,这个hashcode值较大,容易出现数组越界的问题。
这里将hashcode值与他本身向右位移了16位的值做了一个异或。总结一下就是:
hash函数就是将高16位和低16位做一个异或运算,然后得到一个结果来确定node节点的存放位置
作用:尽量让Node落点分布均匀,减少碰撞的一个概率,如果碰撞概率高了,就势必导致数组下标下的链表长度太长。
在这里,我们举个具体的数值去观察一下,一个Key的hashcode如果是3254239,他的高16位不变,与他的低16位做一个异或得到的值为3812。
那我们存放的位置就是table[3812]吗?,显然这个长度太大了,我们还是得去限制一下这个长度,保证这个数组下标的位置在我们定义的数组大小之内。
那么假如我们的数组大小为16的话,我们可以将3812对16取余
3812 % 16 < 16,我们发现,这样去做的话取到的数值一定会小于我们定义的数组大小。那么,在hashmap源码中是这样实现的吗?
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
奇怪的是,我们设想的方式是取模,为什么源码中取了(n-1)和hash值的与运算呢?让我们去看一下他们的值是否是等价的。
按照源码中来说,这个数组下标就是 (16 - 1) & 3812 = 15 & 3812,
那么我们就要去证明 15 & 3812 === 3812 % 16 这个是否成立
15用二进制表示是 001111, 那么不管3812的二进制数是什么,他们的与运算的值也永远不会超过15,就是>=15,我们发现这和我们的取模运算的结果是一样的,这是hashmap源码里一个比较精秒的地方。
那为什么要用这种方式呢?
因为与运算要比我们的取模运算速度快,效率高
我们再回过头看一串代码
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
在这里,为什么要一定强调 数组的大小必须是2的n次幂呢,让我们举个例子来看一下,如果数组的自定义初始化大小为15
那么 15 -1 = 14 ,14用二进制表示就是001110,那么与hash值做了与运算之后,得到的这个数值可能就会大于这个数组大小的规定值,还有就是不论hash值的这位数字是0还是1,得到的这个位数总会是0,那么结点的落点位置就很可能会重叠在一起,所以,这个数组的大小必须是2的n次幂。
那么,2的n次幂减1的二进制数的后几位一定是1吗?我们验证一下
16 15 01111
32 31 011111
64 63 0111111,没有问题
推出: 数组大小不够用了,我希望扩大数组的大小,也要 * 2。
做了这么多的铺垫,接下来让我们完整的去看一下HashMap中的put方法
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
//定义几个局部变量供接下来使用
Node<K,V>[] tab; Node<K,V> p; int n, i;
//这里将全局变量table,也就是我们刚才说的数组形式,赋给了局部变量tab
if ((tab = table) == null || (n = tab.length) == 0)
//如果数组的大小为空,就用resize方法来对数组进行初始化
n = (tab = resize()).length;
//计算节点的落点位置
if ((p = tab[i = (n - 1) & hash]) == null)
//如果为空则可以放置
tab[i] = newNode(hash, key, value, null);
else {
//如果数组该位置有节点,则往下压,为链表结构
Node<K,V> e; K k;
//如果key的值是一样的,则保留老值
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
//如果发现下面的结构已经是一个二叉树的话,就用红黑树的方式去储存
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//遍历链表
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
//如果下一个节点为空,则可以放置
p.next = newNode(hash, key, value, null);
//如果放置之后正好为8的话,要进行链表向红黑树转化的过程
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
//key值重复的话,保留老的值
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//判断数组的大小是否超过了一个阈值,0.75倍的值
if (++size > threshold)
//超过大小后重新初始化
resize();
afterNodeInsertion(evict);
return null;
}
我们发现这个resize()方法调用了两次,他的作用是:
1.数组的初始化
2.数组的扩容
源码分析:resize()
/**
* Initializes or doubles table size. If null, allocates in
* accord with initial capacity target held in field threshold.
* Otherwise, because we are using power-of-two expansion, the
* elements from each bin must either stay at same index, or move
* with a power of two offset in the new table.
*
* @return the table
*/
final Node<K,V>[] resize() {
//定义数组
Node<K,V>[] oldTab = table;
//如果数组存在,oldCap代表数组的长度
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
//如果数组的大小大于0
if (oldCap >= MAXIMUM_CAPACITY) {
//如果数组的大小大于最大值,不需要扩容
threshold = Integer.MAX_VALUE;
return oldTab;
}
//进行扩容,位运算,相当于乘以2
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
//相应的临界值(阈值)也要乘2
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
//扩容之后要把原来的部分数据移到扩容的部分
table = newTab;
if (oldTab != null) {
//遍历之前的节点
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
//如果该节点不为空,则将他置为空
oldTab[j] = null;
//判断下面的节点是否为空
if (e.next == null)
//计算新的落点
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
//如果下面是红黑树
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
//如果是链表
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
//判断链表的下一个是否为空
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
//省去了e.hash和oldcap-1 的与操作,如果为0,则hash的第5位是0,则不需要去移动
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
//如果需要移动的话
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead; //链表的移动就是自己所处的位
置加上原来老的容量
}
}
}
}
}
return newTab;
}
接着,我们去看了看get方法的源码,发现和put方法大同小异,也是通过key去找到对应的节点,然后根据数组或者红黑树这些结构去判断,然后获取节点的key和value。
分享阿里的一个hashmap的面试题:

通过hashmap的初步了解,到hashmap数据结构的分析,到源码的透彻分析,相信你们对hashmap已经有了充分的了解。
HashMap 你真的了解吗?的更多相关文章
- 深入浅出一下Java的HashMap
在平常的开发当中,HashMap是我最常用的Map类(没有之一),它支持null键和null值,是绝大部分利用键值对存取场景的首选.需要切记的一点是——HashMap不是线程安全的数据结构,所以不要在 ...
- (恐怕是)写得最通俗易懂的一篇关于HashMap的文章——xx大佬这样说
先看再点赞,给自己一点思考的时间,微信搜索[沉默王二]关注这个有颜值却假装靠才华苟且的程序员. 本文 GitHub github.com/itwanger 已收录,里面还有一线大厂整理的面试题,以及我 ...
- 面试这么撩准拿offer,HashMap深度学习,扰动函数、负载因子、扩容拆分,原理和实践验证,让懂了就是真的懂!
作者:小傅哥 博客:https://bugstack.cn 沉淀.分享.成长,让自己和他人都能有所收获! 一.前言 得益于Doug Lea老爷子的操刀,让HashMap成为使用和面试最频繁的API,没 ...
- HashMap的循环姿势你真的掌握了吗?
hashMap 应该是java程序员工作中用的比较多的一个键值对处理的数据的类型了.这种数据类型一般都会有增删查的方法,今天我们就来看看它的循环方法以前写过一篇关于ArrayList的循环效率问题&l ...
- 如果你这么去理解HashMap就会发现它真的很简单
Java中的HashMap相信大家都不陌生,也是大家编程时最常用的数据结构之一,各种面试题更是恨不得掘地三尺的去问HashMap.HashTable.ConcurrentHashMap,无论面试题多么 ...
- HashMap源码阅读笔记(基于jdk1.8)
1.HashMap概述: HashMap是基于Map接口的一个非同步实现,此实现提供key-value形式的数据映射,支持null值. HashMap的常量和重要变量如下: DEFAULT_INITI ...
- HashMap的key可以是可变的对象吗???
大家都知道,HashMap的是key-value(键值对)组成的,这个key既可以是基本数据类型对象,如Integer,Float,同时也可以是自己编写的对象,那么问题来了,这个作为key的对象是否能 ...
- Java中HashSet,HashMap和HashTable的区别
HashMap.HashSet.HashTable之间的区别是Java程序员的一个常见面试题目,在此仅以此博客记录,并深入源代码进行分析: 在分析之前,先将其区别列于下面 1:HashSet底层采用的 ...
- 实在没想到系列——HashMap实现底层细节之keySet,values,entrySet的一个底层实现细节
我在看HashMap源码的时候发现了一个没思考过的问题,在这之前可以说是完全没有思考过这个问题,在一开始对这个点有疑问的时候也没有想到居然有这么个语法细节存在,弄得我百思不得其解,直到自己动手做实验改 ...
随机推荐
- selenium2自动化测试学习笔记(四)
今天是学习selenium2第四天.总结下今天的学习成果,自动登录网易邮箱并写信发送邮件. 知识点or坑点: 1.模块化编写测试模块(类似java里的抽象方法,js的函数编写) from 包名 imp ...
- 课堂作业 泛型类-Bag
自定义泛型类Bag 一.具体代码: 代码连接 二.伪代码: 1.思路: 老师讲完后我的想法是要做出一个类似于List的Bag,首先它的本身是又数组构成的并且是可自动增加长度的,然后实现一些基本的操作, ...
- 创建带缩进的XML
from xml.etree import ElementTree as ET from xml.dom import minidom root = ET.Element('}) son=ET.Sub ...
- JavaScript 相关知识
一.数组 var a = [1,2,3,4]; console.log(a.length); a.push(5); console.log(a); // [1, 2, 3, 4, 5] var r ...
- nyoj 仿射密码
仿射密码 时间限制:1000 ms | 内存限制:65535 KB 难度:1 描述 仿射密码是替换密码的另一个特例,可以看做是移位密码和乘数密码的结合.其加密变换如下: E(m)=(k1*m+k2) ...
- Mybatis学习日志
在Mybatis深入学习的一周中,总感觉跟着师傅的视屏讲解什么都能懂,但实际自己操作的时候才发现自己一脸懵逼,不知道从何入手.但还好自己做了点笔记.在此记录一下自己浅度学习Mybatis遇到几个小问题 ...
- Windows Powershell脚本执行
在cmd下执行powershell进入shell模式: 变量定义:$i = 10 $a = ifconfig | findstr "192" Windows下的命令都可以执行如: ...
- KNN算法的代码实现
# -*- coding: utf-8 -*-"""Created on Wed Mar 7 09:17:17 2018 @author: admin"&quo ...
- APP手机端加载不到资源服务器后台解决参考
今天发现app登录时,报could not get resource,日志中打印的是redis相关的错误,于是开始一步步检查错误! 后台架构:redis+mysql+elk+tomcat+zookee ...
- Python扩展模块——自动化(testlinkAPI的使用)
使用TESTLINKAPI首先要安装TestLink_API_Python_client-0.6.4(当前最新版本) 目前只使用到了通过api获取testlink中的自定义字段and值 url = ' ...