Keras 中 TimeDistributed 和 TimeDistributedDense 理解
From the offical code:
class TimeDistributed(Wrapper):
"""This wrapper applies a layer to every temporal slice of an input.
The input should be at least 3D, and the dimension of index one
will be considered to be the temporal dimension.
Consider a batch of 32 samples,
where each sample is a sequence of 10 vectors of 16 dimensions.
The batch input shape of the layer is then `(32, 10, 16)`,
and the `input_shape`, not including the samples dimension, is `(10, 16)`.
You can then use `TimeDistributed` to apply a `Dense` layer
to each of the 10 timesteps, independently:
```python
# as the first layer in a model
model = Sequential()
model.add(TimeDistributed(Dense(8), input_shape=(10, 16)))
# now model.output_shape == (None, 10, 8)
```
The output will then have shape `(32, 10, 8)`.
In subsequent layers, there is no need for the `input_shape`:
```python
model.add(TimeDistributed(Dense(32)))
# now model.output_shape == (None, 10, 32)
```
The output will then have shape `(32, 10, 32)`.
`TimeDistributed` can be used with arbitrary layers, not just `Dense`,
for instance with a `Conv2D` layer:
```python
model = Sequential()
model.add(TimeDistributed(Conv2D(64, (3, 3)),
input_shape=(10, 299, 299, 3)))
```
# Arguments
layer: a layer instance.
So - basically the TimeDistributedDense was introduced first in early versions of Keras in order to apply a Dense layer stepwise to sequences. TimeDistributed is a Keras wrapper which makes possible to get any static (non-sequential) layer and apply it in a sequential manner. An example of such usage might be using a e.g. pretrained convolutional layer to a short video clip by applying TimeDistributed(conv_layer) where conv_layer is applied to each frame of a clip. It produces the sequence of outputs which might be then consumed by next recurrent or TimeDistributed layer.
It's good to know that usage of TimeDistributedDense is depreciated and it's better to use TimeDistributed(Dense) .
TimeDistributed
RNNs are capable of a number of different types of input / output combinations, as seen below
The TimeDistributedDense layer allows you to build models that do the one-to-many and many-to-many architectures. This is because the output function for each of the "many" outputs must be the same function applied to each timestep. The TimeDistributedDense layers allows you to apply that Dense function across every output over time. This is important because it needs to be the same dense function applied at every time step.
If you didn't not use this, you would only have one final output - and so you use a normal dense layer. This means you are doing either a one-to-one or a many-to-one network, since there will only be one dense layer for the output.
======================================================
As fchollet said ,
TimeDistributedDense applies a same Dense (fully-connected) operation to every timestep of a 3D tensor.
But I think you still don't catch the point. The most common scenario for using TimeDistributedDense is using a recurrent NN for tagging task.e.g. POS labeling or slot filling task.
In this kind of task:
For each sample, the input is a sequence (a1,a2,a3,a4...aN) and the output is a sequence (b1,b2,b3,b4...bN) with the same length. bi could be viewed as the label of ai.
Push a1 into a recurrent nn to get output b1. Than push a2 and the hidden output of a1 to get b2...
If you want to model this by Keras, you just need to used a TimeDistributedDense after a RNN or LSTM layer(with return_sequence=True) to make the cost function is calculated on all time-step output. If you don't use TimeDistributedDense ans set the return_sequence of RNN=False, then the cost is calculated on the last time-step output and you could only get the last bN.
I am also new to Keras, but I am trying to use it to do sequence labeling and I find this could only be done by using TimeDistributedDense. If I make something wrong, please correct me.
======================================================
It's quite easy to understand . Let's not think in terms of tensors and stuffs for a sec.
It all depends upon the "return_sequences" parameter of the LSTM function.
if return_sequence = false ( by default , it's always false ), then we get LSTM output corresponding only to THE LAST TIME STEP.
Now applying model.add(Dense( )) , what we are doing is connecting only LSTM output at last time step to Dense Layer. (This approach is in encoding the overall sequence into a compact vector .
Now given a sequence of 50 words , my LSTM will only output only one word )
Ques) WHEN NOT TO USE TIMEDISTRIBUTED ?
Ans) In my experience, for encoder decoder model.
if you want to squeeze all your input information into a single vector, we DONT use TIMEDISTRIBUTED.
Only final unrolled layer of LSTM layer will be the output. This final layer will holder the compact information of whole input sequence which is useful for task like classification , summarization etc.
-----------------------------------------------------------However !-----------------------------------------------------------------------
If return_sequence is set True , LSTM outputs at every time step . So , I must use TimeDistributed to ensure that the Dense layer is connected to LSTM output at each TimeStep. Otherwise , error occurs !
Also keep in mind , just like lstm is unrolled , so is the dense layer . i.e dense layer at each time step is the same one . It's not like there are 50 different dense layer for 50 time steps.
There's nothing to get confused.
This time , model will generate a sequence corresponding to length of Timestep. So, given set of 50 input word , LSTM will output 50 output word
Q) WHEN TO USE TIMEDISTRIBUTED ?
A) In case of word generation task (like shakespeare) , where given a sequence of words , we train model predict next set of words .
EXAMPLE : if nth training input to LSTM Network is : 'I want to ' AND output of netwok is "want to eat" . Here , each word ['want','to','eat'] are output of LSTM during each timestep.
======================================================
Let's say you have time-series data with NN rows and 700700 columns which you want to feed to a SimpleRNN(200, return_sequence=True) layer in Keras. Before you feed that to the RNN, you need to reshape the previous data to a 3D tensor. So it becomes a N×700×1N×700×1.
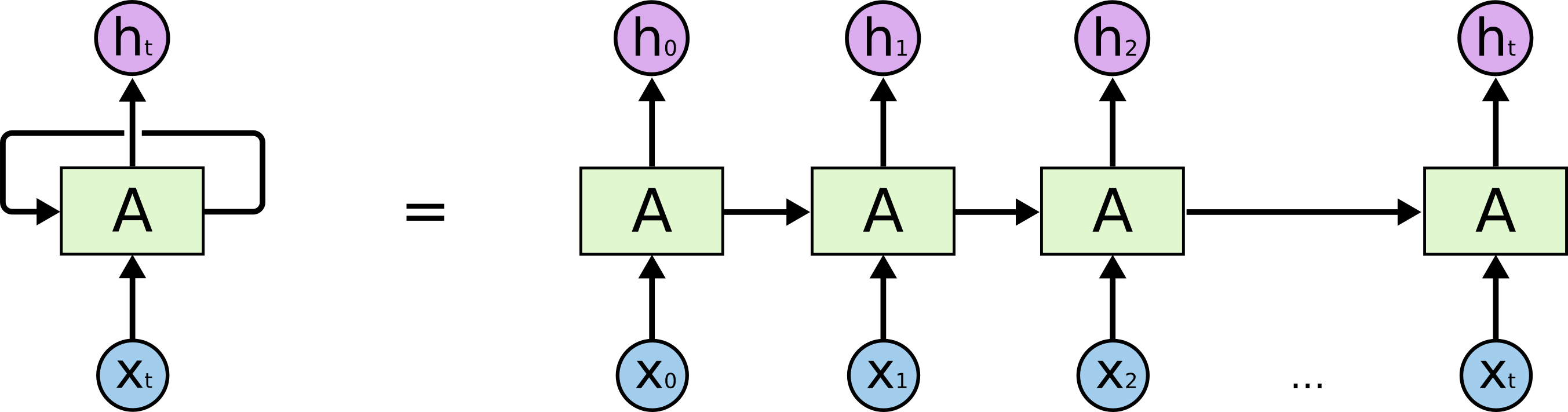
The image is taken from https://colah.github.io/posts/2015-08-Understanding-LSTMs
In RNN, your columns (the "700 columns") is the timesteps of RNN. Your data is processed from t=1 to 700t=1 to 700. After feeding the data to the RNN, now it have 700 outputs which are h1h1 to h700h700, not h1h1to h200h200. Remember that now the shape of your data is N×700×200N×700×200 which is samples (the rows) x timesteps (the columns) x channels.
And then, when you apply a TimeDistributedDense , you're applying a Dense layer on each timestep, which means you're applying a Dense layer on each h1h1, h2h2,...,htht respectively. Which means: actually you're applying the fully-connected operation on each of its channels (the "200" one) respectively, from h1h1 to h700h700. The 1st "1×1×2001×1×200" until the 700th "1×1×2001×1×200".
Why are we doing this? Because you don't want to flatten the RNN output.
Why not flattening the RNN output? Because you want to keep each timestep values separate.
Why keep each timestep values separate? Because:
- you're only want to interacting the values between its own timestep
- you don't want to have a random interaction between different timesteps and channels.
参考:
https://datascience.stackexchange.com/questions/10836/the-difference-between-dense-and-timedistributeddense-of-keras
https://github.com/keras-team/keras/blob/master/keras/layers/wrappers.py#L43
https://github.com/keras-team/keras/issues/1029
https://stackoverflow.com/questions/42398645/timedistributed-vs-timedistributeddense-keras
Keras 中 TimeDistributed 和 TimeDistributedDense 理解的更多相关文章
- keras中TimeDistributed的用法
TimeDistributed这个层还是比较难理解的.事实上通过这个层我们可以实现从二维像三维的过渡,甚至通过这个层的包装,我们可以实现图像分类视频分类的转化. 考虑一批32个样本,其中每个样本是一个 ...
- keras中TimeDistributed
TimeDistributed这个层还是比较难理解的.事实上通过这个层我们可以实现从二维像三维的过渡,甚至通过这个层的包装,我们可以实现图像分类视频分类的转化. 考虑一批32个样本,其中每个样本是一个 ...
- 深度学习基础系列(五)| 深入理解交叉熵函数及其在tensorflow和keras中的实现
在统计学中,损失函数是一种衡量损失和错误(这种损失与“错误地”估计有关,如费用或者设备的损失)程度的函数.假设某样本的实际输出为a,而预计的输出为y,则y与a之间存在偏差,深度学习的目的即是通过不断地 ...
- 在Keras中可视化LSTM
作者|Praneet Bomma 编译|VK 来源|https://towardsdatascience.com/visualising-lstm-activations-in-keras-b5020 ...
- SQL SERVER 2005/2008 中关于架构的理解(二)
本文上接SQL SERVER 2005/2008 中关于架构的理解(一) 架构的作用与示例 用户与架构(schema)分开,让数据库内各对象不再绑在某个用户账号上,可以解决SQL SERVE ...
- SQL SERVER 2005/2008 中关于架构的理解(一)
SQL SERVER 2005/2008 中关于架构的理解(一) 在一次的实际工作中碰到以下情况,在 SQL SERVER 2008中,新建了一个新用户去访问几张由其他用户创建的表,但是无法进行查询, ...
- C++中 类的构造函数理解(一)
C++中 类的构造函数理解(一) 写在前面 这段时间完成三个方面的事情: 1.继续巩固基础知识(主要是C++ 方面的知识) 2.尝试实现一个iOS的app,通过完成app,学习iOS开发中要用到的知识 ...
- ECshop中的session机制理解
ECshop中的session机制理解 在网上找了发现都是来之一人之手,也没有用自己的话去解释,这里我就抛砖引玉,发表一下自己的意见,还希望能得到各界人士的指导批评! 此session机制不需 ...
- [开发技巧]·Numpy中对axis的理解与应用
[开发技巧]·Numpy中对axis的理解与应用 1.问题描述 在使用Numpy时我们经常要对Array进行操作,如果需要针对Array的某一个纬度进行操作时,就会用到axis参数. 一般的教程都是针 ...
随机推荐
- Java学习笔记53(网络编程:TCP协议案例)
简易的案例 客户端: package demo; import java.io.IOException; import java.io.InputStream; import java.io.Outp ...
- [CocoaPods]终端方式加载第三方库
终端方式集成第三方库 1.打开终端,转到当前工程所在的文件夹. 方式一: [访达]->[服务]->[系统偏好设置] ->勾选[新建位于文件夹位置的终端标签 ]和[新建位于文件夹位置的 ...
- 排序算法系列:插入排序算法JAVA版(靠谱、清晰、真实、可用、不罗嗦版)
在网上搜索算法的博客,发现一个比较悲剧的现象非常普遍: 原理讲不清,混乱 啰嗦 图和文对不上 不可用,甚至代码还出错 我总结一个清晰不罗嗦版: 原理: 和选择排序类似的是也分成“已排序”部分,和“未排 ...
- [EXP]Huawei Router HG532e - Command Execution
#!/bin/python ''' Author : Rebellion Github : @rebe11ion Twitter : @rebellion ''' import urllib2,req ...
- c++创建二维动态数组与内存释放
如下: #include <iostream> #include <windows.h> using namespace std; int main() { cout < ...
- 001. Asp.Net Routing与MVC 之(基础知识):URL
URL(Uniform Resoure Locator:统一资源定位器)是WWW页的绝对地址.URL地址格式排列为:scheme://host:port/path. 例如 http://www.zn. ...
- mysql 开发进阶篇系列 40 mysql日志之二进制日志下以及查询日志
一.binlog 二进制其它选项 在二进制日志记录了数据的变化过程,对于数据的完整性和安全性起着非常重要作用.在mysql中还提供了一些其它参数选项,来进行更小粒度的管理. 1.1 binlog-do ...
- Python多进程库multiprocessing中进程池Pool类的使用
问题起因 最近要将一个文本分割成好几个topic,每个topic设计一个regressor,各regressor是相互独立的,最后汇总所有topic的regressor得到总得预测结果.没错!类似ba ...
- jsp页面简单的验证码实现
前段时间赶着结束毕业设计任务,现在完成了.回来补一下设计毕业设计的过程中遇到的问题和解决方案. 为了使小系统更有模有样,这里尝试在登录页面实现验证码功能.现描述一下我的解决方案. 首先看一下实现后的界 ...
- 【PyTorch深度学习60分钟快速入门 】Part1:PyTorch是什么?
0x00 PyTorch是什么? PyTorch是一个基于Python的科学计算工具包,它主要面向两种场景: 用于替代NumPy,可以使用GPU的计算力 一种深度学习研究平台,可以提供最大的灵活性 ...