Disruptor 详解
想了解一个项目,最好的办法就是,把它的源码搞到本地自己捣鼓。
在网上看了 N 多人对 Disruptor 速度的吹捧,M 多人对它的机制分析,就连 Disruptor 官方文档中,也 NB 哄哄自诩:
At LMAX we have built an order matching engine, real-time risk management,
and a highly available in-memory transaction processing system all on this pattern to great success.
Each of these systems has set new performance standards that, as far as we can tell, are unsurpassed.
很少见到哪个开源项目,能够对自己的项目如此接近自大的自信。也难怪,不然该项目怎么会获得 2011 Duke's 程序框架创新奖呢。
但是,在学习它之前,我还是怀疑它是不是真的有那么快(快如闪电)?为什么会那么快?
有没有,不能光听别人说,我相信自己的眼睛和脑瓜胜过耳朵,且看且分析。
于是 down 了 3.2 版本的源码开始捣鼓。
以下对 Disruptor 源码的分析,都是基于这个版本的。
1. Disruptor 初印象
Disruptor 的源码非常精简,没有任何配置文件,所有源文件类加起来也就 58 个(不同版本可能不一样),用代码行统计工具算了下,一共 6306 行(好像我挺无聊的)。对于一个能做到如此成功的开源工具来说,能有这么精短的代码量,确实很不错。
Disruptor 代码共分为四个包:
1). com.lmax.disruptor: 大部分文件存放于这个目录下,包括 Disruptor 中重要的类文件,包括:EventProcessor、RingBuffer、Sequence、Sequencer、WaitStrategy 等
2). com.lmax.disruptor.collections: 该目录下只有一个类:Histogram,它不是 Disruptor 运行的必须类,其实我也没用过它,从源码注释来看,该类的作用是,在一个对性能要求很高的、有多个消费者的系统中,Histogram 可以用来记录系统耗各个组件的耗时情况,并以直方图的形式展示出来。初学 Disruptor 可以不用管关心它。
3). com.lmax.disruptor.dsl: 该包中保存了消费者和生产者的一些信息,核心类文件 Disruptor 也存放在该目录下。
4). com.lmax.disruptor.util: 该包中存放了几个辅助操作类,如 Util 类,DaemonThreadFactory 类,PaddedLong 类,该类用来做缓冲行填充的。
2. Disruptor demo
闲话不多说,来个 hello 级别的 demo 应该是最好的入门手段了:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
package com.lmax.test; import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors; import com.lmax.disruptor.EventHandler;import com.lmax.disruptor.RingBuffer;import com.lmax.disruptor.dsl.Disruptor; public class Sample { @SuppressWarnings("unchecked") public static void main(String[] args) { ExecutorService exec = Executors.newCachedThreadPool(); Disruptor<ValueEvent> disruptor = new Disruptor<ValueEvent>(ValueEvent.EVENT_FACTORY, 4 , exec); final EventHandler<ValueEvent> handler1 = new EventHandler<ValueEvent>() { // event will eventually be recycled by the Disruptor after it wraps public void onEvent(final ValueEvent event, final long sequence, final boolean endOfBatch) throws Exception { System.out.println("handler1: Sequence: " + sequence + " ValueEvent: " + event.getValue()); } };// final EventHandler<ValueEvent> handler2 = new EventHandler<ValueEvent>() {// // event will eventually be recycled by the Disruptor after it wraps// public void onEvent(final ValueEvent event, final long sequence, final boolean endOfBatch) throws Exception {// System.out.println("handler2: Sequence: " + sequence + " ValueEvent: " + event.getValue());// }// }; // disruptor.handleEventsWith(handler1, handler2); disruptor.handleEventsWith(handler1); RingBuffer<ValueEvent> ringBuffer = disruptor.start(); int bufferSize = ringBuffer.getBufferSize(); System.out.println("bufferSize = " + bufferSize); for (long i = 0; i < 1000; i++) { long seq = ringBuffer.next(); try { String uuid = String.valueOf(i); ValueEvent valueEvent = ringBuffer.get(seq); valueEvent.setValue(uuid); } finally { ringBuffer.publish(seq); } } disruptor.shutdown(); exec.shutdown(); }} |
定义 ValueEvent 类,该类作为填充 RingBuffer 的消息,生产者向该消息中填充数据(就是修改 value 属性值,后文用生产消息代替),消费者从消息体中获取数据(获取 value 值,后文用消费消息代替):
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
package com.lmax.test; import com.lmax.disruptor.EventFactory; /** * WARNING: This is a mutable object which will be recycled by the RingBuffer. * You must take a copy of data it holds before the framework recycles it. */public final class ValueEvent { private String value; public String getValue() { return value; } public void setValue(String value) { this.value = value; } public final static EventFactory<ValueEvent> EVENT_FACTORY = new EventFactory<ValueEvent>() { public ValueEvent newInstance() { return new ValueEvent(); } };} |
Sample.java 代码分析:
第13行:
创建ExecutorService对象。
所有消费者线程都由该对象启动。
第14行:
创建 Disruptor 对象。
Disruptor 类是 Disruptor 项目的核心类,另一个核心类之一是 RingBuffer。
如果把 Disruptor 比作计算机的 cpu ,作为调度中心的话,那么 RingBuffer ,就是计算机的 Memory 。
第一个参数,是一个 EventFactory 对象,它负责创建 ValueEvent 对象,并填充到 RingBuffer 中;
第二个参数,指定 RingBuffer 的大小。这个参数应该是2的幂,否则程序会抛出异常:
Exception in thread "main" java.lang.IllegalArgumentException: bufferSize must be a power of 2
at com.lmax.disruptor.AbstractSequencer.<init>(AbstractSequencer.java:51)
at com.lmax.disruptor.MultiProducerSequencer.<init>(MultiProducerSequencer.java:60)
at com.lmax.disruptor.RingBuffer.createMultiProducer(RingBuffer.java:79)
at com.lmax.disruptor.RingBuffer.createMultiProducer(RingBuffer.java:94)
at com.lmax.disruptor.dsl.Disruptor.<init>(Disruptor.java:74)
at com.lmax.test.Sample.main(Sample.java:14)
第三个参数,就是之前创建的 ExecutorService 对象。
伴随着Disruptor的创建,RingBuffer 对象也被创建,RingBuffer是一个环形缓冲区,其实它是用一个 Object[] 实现的(这个后面会详说),RingBuffer 创建之后,会创建bufferSize数量的消息(这里说的消息,就是EventValue对象,下同)填充至RingBuffer,也许有人对此有疑问:生产者还没有启动,怎么已经将消息创建了?其实是这样的:Disruptor在启动前预创建所有消息,以后生产者 "生产消息",只是修改 RingBuffer 中某个消息的内容,当然,这里说的 "某个",不是随随便便从 RingBuffer 中取出一个,而是通过某个策略顺序访问,并和消费者保持协调。生产者修改完消息后,在该消息上打个标记,表示该消息已经生产了,消费者可以来消费了,消费者通过这个标记来确定是否可以读消息了。消费者读完消息后,也会在消息上打一个标记,表示生产者可以再次在该消息上继续生产了。如此循环。我个人认为,理解 Disruptor 最大的难点就在于,要搞清楚生产者和消费者间是如何协同工作的,一旦理解了这一点,就掌握了 Disruptor 的灵魂,本文后续主要精力将集中在对该问题的讨论上。
以下是向 RingBuffer 填充消息的代码:
|
1
2
3
4
5
6
7
|
private void fill(EventFactory<E> eventFactory){ for (int i = 0; i < entries.length; i++) { entries[i] = eventFactory.newInstance(); }} |
同时,生产者对象也会被创建,Disruptor中支持两种生产者类型:多生产者和单生产者,分别用:MultiProducerSequencer 和 SingleProducerSequencer 表示,默认使用 MultiProducerSequencer:
|
1
2
3
4
5
6
7
8
|
public static <E> RingBuffer<E> createMultiProducer(EventFactory<E> factory, int bufferSize, WaitStrategy waitStrategy) { MultiProducerSequencer sequencer = new MultiProducerSequencer(bufferSize, waitStrategy); return new RingBuffer<E>(factory, sequencer); } |
第 16 - 21 行,通过实现 EventHandler 接口,创建了一个 EventHandler 对象,用来处理消费者拿到的消息。
第 23 - 27 行,注释起来了,创建另一个 EventHandler 对象,多消费者情况下,需要创建多个 EventHandler。 EventHandler 对象和消费者一一对应。
第 29 和 30 行,将 EventHandler 对象传入 Disruptor ,Disruptor 依据 EventHandler 参数个数,创建相等数量消费者对象。
至此,准备工作完成:
作为管控中心的 Disruptor 对象已创建;
作为消息存储中心的 RingBuffer 对象已创建;
生产者对象已创建;
消费者对象和与它关联的事件处理对象(EventHandler)对象已创建。
接下来就是启动 Disruptor 系统了,让消费者跑起来。
第 31 行,start() 方法启动消费者线程:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public RingBuffer<T> start(){ Sequence[] gatingSequences = consumerRepository.getLastSequenceInChain(true); ringBuffer.addGatingSequences(gatingSequences); checkOnlyStartedOnce(); for (ConsumerInfo consumerInfo : consumerRepository) { consumerInfo.start(executor); } return ringBuffer;} |
每个消费者线程都有一个等待策略:以确定当无消息可消费时,消费者是阻塞还是轮询。
Disruptor 中定义了几种不同等待策略:BlockingWaitStrategy、TimeoutBlockingWaitStrategy、SleepingWaitStrategy等。
第 36 - 45 行,生产10条消息
生产者线程(main线程)通过 next 方法,获取 RingBuffer 可写入的消息索引号 seq;
通过 seq 检索消息;
修改消息的 value 属性;
通过 publish 方法,告知消费者线程,当前索引位置的消息可被消费了。
第 47 - 48 行,停止 Disruptor系统(停止消费者线程)。
运行结果:
bufferSize = 4
handler1: Sequence: 0 ValueEvent: 0
handler1: Sequence: 1 ValueEvent: 1
handler1: Sequence: 2 ValueEvent: 2
handler1: Sequence: 3 ValueEvent: 3
handler1: Sequence: 4 ValueEvent: 4
handler1: Sequence: 5 ValueEvent: 5
handler1: Sequence: 6 ValueEvent: 6
handler1: Sequence: 7 ValueEvent: 7
handler1: Sequence: 8 ValueEvent: 8
handler1: Sequence: 9 ValueEvent: 9
3. 核心问题
3.1 环形缓冲区(RingBuffer)和索引映射
Disruptor 中缓冲区用数组实现:
|
1
|
private final Object[] entries; |
该数组大小由 bufferSize 参数指定,以 bufferSize = 4 为例:
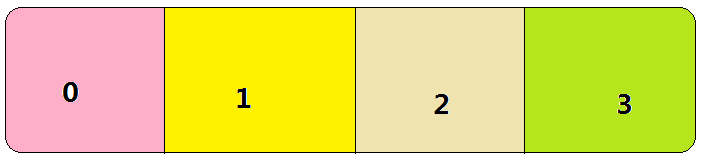
很明显不是个环形。
环形数组应该是这样的:
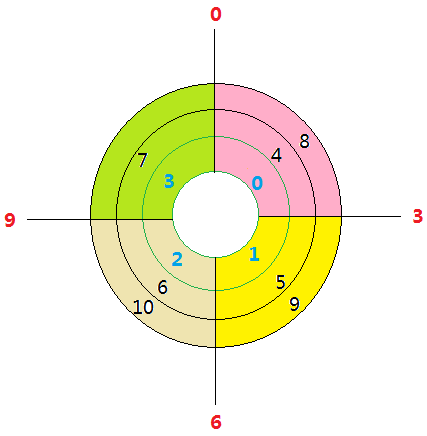
0点-3点区域表示 entries[0];
3点-6点区域表示 entries[1];
6点-9点区域表示 entries[2];
9点-0点区域表示 entries[3];
区域内数字表示数组索引号,
数组容量为 4, 所以索引号必须在[0, 3]区间内。
Disruptor 通过 & 映射索引:
映射后的索引号 = 实际索引号 & (bufferSize - 1)
代码:
|
1
2
3
4
|
public E get(long sequence){ return (E)entries[(int)sequence & indexMask];} |
其中:indexMask = bufferSize - 1。
如:
6 & 3 = 2;实际索引号为 6,映射索引号为 2
8 & 3 = 0;实际索引号为 8,映射索引号为 0
3.2 缓存相关问题(Cache Line padding)
引入三个概念:
(1)伪共享
(2)缓存行
(3)缓存行填充
详细讲解可参考这里,这里简单简说明一下。
3.2.1 CPU 缓存结构
如下图:一个cpu上有一个 L3 Cache,在四个 core 上共享,每个 core 上由独立的 L2 Cache和 L1 Cache,其中 L1 Cache 又分为 D-Cache(数据缓存)和 L-Cache(指令缓存)。
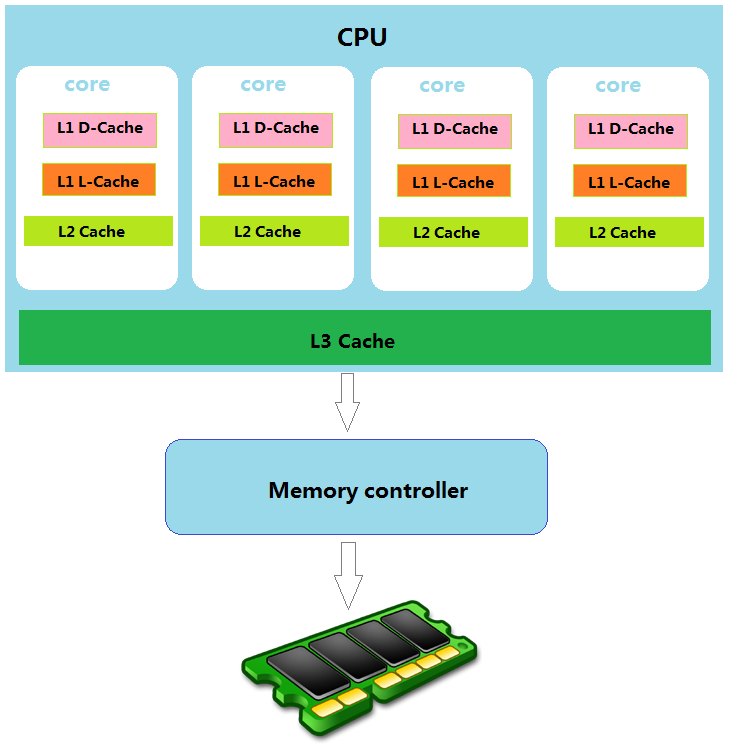
3.2.2 缓存行
缓存是由缓存行构成的,缓存行一般32-256个字节,常见的64字节,如下图,int 型变量 a 和 b 位于同一个缓存行:
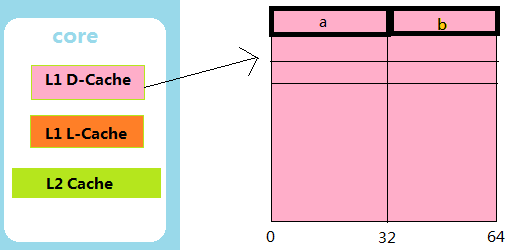
3.2.3 缓存行填充
下图,变量 X、Y 在 L3 Cache 中被存放于同一个缓存行:
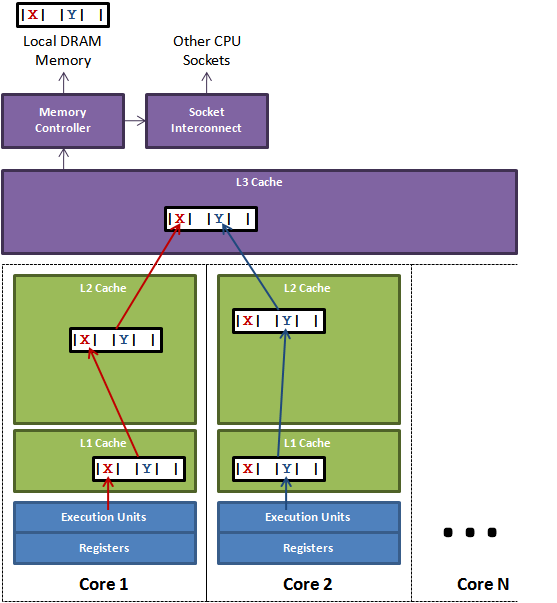
如果存在多核,因为一级和二级缓存不会在核间共享,所以每个核的一级和二级缓存上,又保存和 X 和 Y 的缓存行映像。
一旦cpu core 更改了 X 或 Y,都要经过一级缓存、二级缓存、三级缓存,写回Local Mem。
如:core1 修改了 X,同时core2 修改了 Y,则在缓存更新上必然存在冲突:core1 看到的Y,core2 看到的X,都已被对方修改。
所以,一旦core1 修改了X,就会引起 core2 中的缓存行失效,core2 须等到 core1 将修改同步到 L3 Cache,然后从L3 缓存中读出正确的 X 值,执行Y的修改,再将结果写入L3 Cache。
事情看起来就有点奇怪了:独立的变量 X 和 Y,在两个独立的 cpu core 上由互不相干的线程执行修改,两个 core 上的线程却发生了同步!同步必然影响线程执行效率,所以这也被称作多线程杀手,而且这个杀手藏得很深。
导致以上两个独立线程同步的原因,就是 X 和 Y 被放在了同一个缓存行上,两个线程存现了伪共享:缓存行共享。
很自然的就会想到将 X 和 Y 放到两个不同的缓存行中,没有了缓存行共享,就不存在同步了。
那怎样做到一个缓存行只保存一个变量?
这个问题就像给你两个麻袋,两个苹果,怎样做,可以保证两个苹果被放到不同的麻袋中?
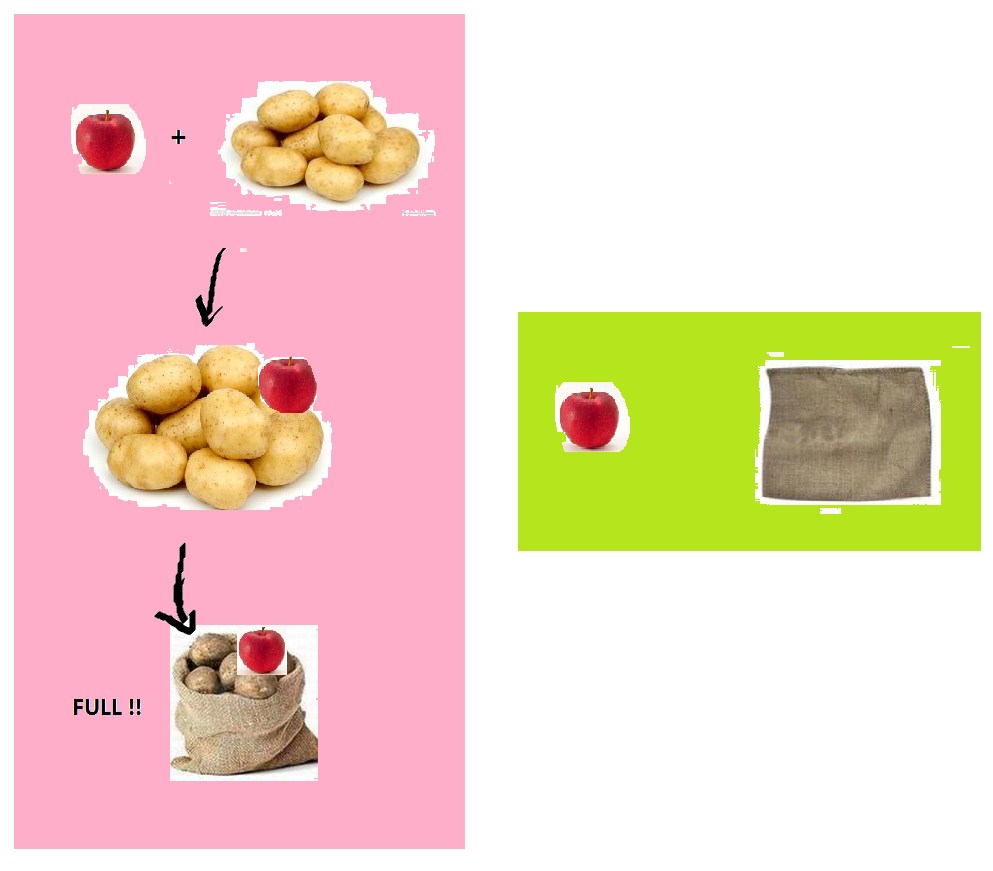
填充是一种解决办法:将一个苹果和一大堆土豆捆绑到一起,只要土豆的数量够多,就能保证这一个苹果和这些土豆能把一个麻袋装的满满的,另一个苹果只能装到另一个麻袋里了。
缓存行填充的思想和这个一样(苹果是变量,麻袋是缓存行):变量 X 和 一些不会被访问到的变量捆绑到一起(通常用数组实现,基于数组元素内存地址的连续性),保证 X 和这些变量能把一个缓存行填充满;Y 也按照同样的方式做。
4. 生产者和消费者协调策略
4.1 相关说明
4.2 生产者
为生产者引入 current 属性,表示当前坐标,current + 1 即表示 下次访问的数组坐标,即 next 属性。
生产者刚启动时:
current = -1; next = -1 + 1 = 0;
生产者开始工作:
第一次生产者向 RingBuffer[0] 生产数据;
第二次生产者向 RingBuffer[1] 生产数据;
第三次生产者向 RingBuffer[2] 生产数据;
第四次生产者向 RingBuffer[3] 生产数据;
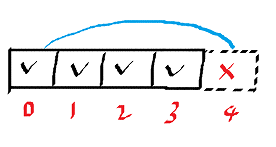
因为RingBuffer[4] 被映射到 RingBuffer[0],所以第五次生产者准备向RingBuffer[0]写数据,问题来了:消费者尚未消费 RingBuffer[0],生产者不能访问RingBuffer[0]:
为方便生产者判断下一个数组元素是否可访问,引入两个变量:wrapPoint,sequence,其中:
1). sequence 记录消费者已消费过的数组元素的索引(未被映射的),初始值为 -1 表示尚未消费任何元素。
2). wrapPoint = next - bufferSize; wrapPoint 在 next 上向后偏移 bufferSize 个单位,如 next = 4 时,wrapPoint = 0。wrapPoint是一个未被映射的索引。那这个 wrapPoint 是用来干嘛的?别急,先看下图:
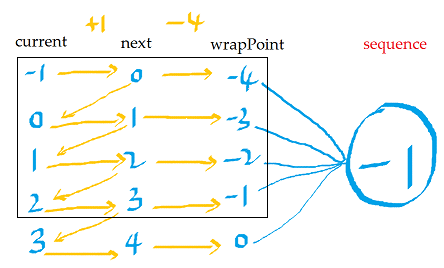
此图是生产者向RingBuffer 中写满数据(next 由 0 变到 3),以及准备继续写入数据这段时间内几个变量的变化情况。因消费者一直未消费,所以sequence值保持为 -1。
生产者写入数据前,判断是否可向 next 位置写入数据的依据是:如果 wrapPoint <= sequence,表示可写,否则,不可写。
所以我觉得可以这样理解wrapPoint的含义:因为RingBuffer的容量是 bufferSize,所以生产者一开始就有bufferSize大小的数组元素可写,但写满之后,就必须看消费者的脸色了,消费者不消费,生产者就不能往里面写(因为这个数组是环形的,生产者再写就要把之前的数据覆盖了)。既然这样,就必须确定一个基准点,用来判断消费者是否超过了消费者。生产者要回退 bufferSize 个单位,才能和消费者站在一个点上进行比较,所以 wrapPoint = next - bufferSize 就是这样来的。next = 4 时,wrapPoint = 0,而 sequence = -1,表示消费者落后于生产者,生产者就必须等待。消费者消费完一个元素,会将自身的 sequence 加1,变为0,表示0索引位置的已经消费,生产者下次比较时发现 wrapPoint == sequence,就可以继续生产了。
多消费者情况下,有些消费者消费的可能比较慢,这样,生产者就必须等待最慢的消费者:
|
1
|
long gatingSequence = Util.getMinimumSequence(gatingSequences, current); |
生产者代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
do{ current = cursor.get(); next = current + n; long wrapPoint = next - bufferSize; long cachedGatingSequence = gatingSequenceCache.get(); if (wrapPoint > cachedGatingSequence || cachedGatingSequence > current) { // eclipseek. 获取最慢的消费者的位置 long gatingSequence = Util.getMinimumSequence(gatingSequences, current); // eclipseek. 表示生产者从后面追过消费者,这个是不允许的。这里等待1纳秒,在重新开始 if (wrapPoint > gatingSequence) { LockSupport.parkNanos(1); // TODO, should we spin based on the wait strategy? continue; } gatingSequenceCache.set(gatingSequence); } // eclipseek. 生成者可以正常去抢位置,compareAndSet不能保证一定成功,所以 // 可以看到 while (true),其实是会不断去尝试,直到成功. else if (cursor.compareAndSet(current, next)) { break; }} while (true); |
4.3 消费者
消费者核心代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
T event = null;long nextSequence = sequence.get() + 1L;try{ while (true) { try { // nextSequence:消费者期望处理的下一个数据的序号 final long availableSequence = sequenceBarrier.waitFor(nextSequence); // 消费者将超过生产者 if (nextSequence > availableSequence) { Thread.yield(); } while (nextSequence <= availableSequence) { event = dataProvider.get(nextSequence); eventHandler.onEvent(event, nextSequence, nextSequence == availableSequence); nextSequence++; } sequence.set(availableSequence); } catch (final TimeoutException e) { notifyTimeout(sequence.get()); } catch (final AlertException ex) { if (!running.get()) { break; } } catch (final Throwable ex) { exceptionHandler.handleEventException(ex, nextSequence, event); sequence.set(nextSequence); nextSequence++; } }} |
上面说过,每个消费者都有 sequence ,初始值为-1,消费者刚进入时,nextSequence = sequence + 1 = 0,nextSequence 表示期望消费的元素索引号。
以后消费者通过 waitFor 方法获取实际可消费的元素索引(期望和实际是两码事),实际可消费的元素索引依赖于生产者,消费者之所以能做出正确的判断,是因为消费者能看到生产者的 current 属性!
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
public long waitFor(long sequence, Sequence cursorSequence, Sequence dependentSequence, SequenceBarrier barrier) throws AlertException, InterruptedException{ long availableSequence; if ((availableSequence = cursorSequence.get()) < sequence) { // eclipseek. 用到了lock.lock();意思就是同时只允许一个个消费者排队去抢, // 下一个消费者要等待上一个消费者处理完一个之后才能抢. lock.lock(); try { while ((availableSequence = cursorSequence.get()) < sequence) { barrier.checkAlert(); processorNotifyCondition.await(); } } finally { lock.unlock(); } } while ((availableSequence = dependentSequence.get()) < sequence) { barrier.checkAlert(); } return availableSequence;} |
if 语句中:cursorSequence 就是生产者的 current,sequence 是消费者期望的消费索引号。这段代码表明,如果实际可消费的索引号小于消费者期望消费的所以号,消费者就进入等待状态。后续生产者通过 publish 方法将消费者唤醒。
上面消费者核心代码中,消费者消费完后,执行了:
sequence.set(availableSequence);
这条语句,就是重设自己的 sequence,是为了让生产者能及时看到,以便生产者确定可写入数组元素的索引。
另外消费者还执行一段重要的代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
public long waitFor(final long sequence) throws AlertException, InterruptedException, TimeoutException { checkAlert(); // eclipseek. waitStrategy 的默认实现是 BlockingWaitStrategy long availableSequence = waitStrategy.waitFor(sequence, cursorSequence, dependentSequence, this); if (availableSequence < sequence) { return availableSequence; } // eclipseek. 检查生产者的位置信息的标志是否正常.这个是和生产者的publish方法联系起来的. return sequencer.getHighestPublishedSequence(sequence, availableSequence); } |
waitFor方法第一个参数是消费者期望消费的索引序列号,cursorSequence是生产者的current,返回值availableSequence是实际可消费的索引号,这个值返回后,生产者还要做检查,就是通过最下面的 getHighestPublishedSequence方法:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
@Overridepublic boolean isAvailable(long sequence){ int index = calculateIndex(sequence); int flag = calculateAvailabilityFlag(sequence); long bufferAddress = (index * SCALE) + BASE; return UNSAFE.getIntVolatile(availableBuffer, bufferAddress) == flag;} @Overridepublic long getHighestPublishedSequence(long lowerBound, long availableSequence){ for (long sequence = lowerBound; sequence <= availableSequence; sequence++) { if (!isAvailable(sequence)) { return sequence - 1; } } return availableSequence;} |
这里要说下 availableBuffer 变量,这是一个 bufferSize 大小的 int 数组,初始值为[-1, -1, -1, -1]。前面说过,索引号映射之后,一定是在[0, 3] 范围内,分别代表RingBuffer底层数组的 RingBuffer[0],RingBuffer[1],RingBuffer[2],RingBuffer[3],每次生产者向该数组中对应位置写入一个值,availableBuffer 数组对应位置的值加1,如:
生产者向 RingBuffer[0] 生产数据,则availableBuffer变为[0, -1, -1, -1];
生产者向 RingBuffer[1] 生产数据,则availableBuffer变为[0, 0, -1, -1];
生产者向 RingBuffer[2] 生产数据,则availableBuffer变为[0, 0, 0, -1];
生产者向 RingBuffer[3] 生产数据,则availableBuffer变为[0, 0, 0, 0];
生产者向 RingBuffer[4] (映射后就是Ringbuffer[0])生产数据,则availableBuffer变为[1, 0, 0, 0];
生产者向 RingBuffer[5] (映射后就是Ringbuffer[1])生产数据,则availableBuffer变为[1, 1, 0, 0];
生产者向 RingBuffer[6] (映射后就是Ringbuffer[2])生产数据,则availableBuffer变为[1, 1, 1, 0];
生产者向 RingBuffer[7] (映射后就是Ringbuffer[3])生产数据,则availableBuffer变为[1, 1, 1, 1];
生产者向 RingBuffer[8] (映射后就是Ringbuffer[0])生产数据,则availableBuffer变为[2, 1, 1, 1];
...
那 available 数组有什么作用呢?其实这是一种验证策略,以防消费者跑到生产者前面去消费那些生产者还没有生产的消息。具体是这样实现的:
生产者:
生产者在索引为 sequence 的位置处生产了元素,则修改 availeable[x] 元素的值:
availeable[x] = flag = (int) (sequence >>> indexShift);;
其中:
x = sequence & (bufferSize -1);
indexShift = log2(bufferSize);
消费者:
|
1
2
3
4
5
6
7
8
|
@Overridepublic boolean isAvailable(long sequence){ int index = calculateIndex(sequence); int flag = calculateAvailabilityFlag(sequence); long bufferAddress = (index * SCALE) + BASE; return UNSAFE.getIntVolatile(availableBuffer, bufferAddress) == flag;} |
消费者以同样的方式,计算 sequence(可用索引坐标)对应的映射坐标index,以及flag,通过比较 available[index] 是否等于 flag,即可判断取到的 sequence 是不是有效的。
简单来说,算法思想是这样的:
生产者和消费者共享 bufferSize 大小的数组 available,生产者生产了元素,就修改available数组 "对应元素" 的值,消费者拿到课消费元素索引时,计算出一个值,然后比较这个值是否和 available 数组“对应元素”的值是否相等,如果相等,就说明该索引确实是可用的。
有点像生产者加密,消费者解密的意思。
参考文献:
1. 写Java也得了解CPU–CPU缓存
2. http://maoyidao.iteye.com/blog/1663193
附件列表
Disruptor 详解的更多相关文章
- Disruptor 详解 二
Disruptor 的大名从很久以前就听说了,但是一直没有时间:看完以后才发现其内部的思想异常清晰,很容易就能前移到其他的项目,所以仔细了解一下还是很有必要的这.篇博客将主要从源码角度分析,Disru ...
- Disruptor 详解 一
这篇博客将主要通过几个示例,简单讲述 Disruptor 的使用方法: 一.disruptor 简介 Disruptor 是英国外汇交易公司 LMAX 开发的一个无锁高性能的线程间消息传递的框架.目前 ...
- Java中日志组件详解
avalon-logkit Java中日志组件详解 lanhy 发布于 2020-9-1 11:35 224浏览 0收藏 作为开发人员,我相信您对日志记录工具并不陌生. Java还具有功能强大且功能强 ...
- Linq之旅:Linq入门详解(Linq to Objects)
示例代码下载:Linq之旅:Linq入门详解(Linq to Objects) 本博文详细介绍 .NET 3.5 中引入的重要功能:Language Integrated Query(LINQ,语言集 ...
- 架构设计:远程调用服务架构设计及zookeeper技术详解(下篇)
一.下篇开头的废话 终于开写下篇了,这也是我写远程调用框架的第三篇文章,前两篇都被博客园作为[编辑推荐]的文章,很兴奋哦,嘿嘿~~~~,本人是个很臭美的人,一定得要截图为证: 今天是2014年的第一天 ...
- EntityFramework Core 1.1 Add、Attach、Update、Remove方法如何高效使用详解
前言 我比较喜欢安静,大概和我喜欢研究和琢磨技术原因相关吧,刚好到了元旦节,这几天可以好好学习下EF Core,同时在项目当中用到EF Core,借此机会给予比较深入的理解,这里我们只讲解和EF 6. ...
- Java 字符串格式化详解
Java 字符串格式化详解 版权声明:本文为博主原创文章,未经博主允许不得转载. 微博:厉圣杰 文中如有纰漏,欢迎大家留言指出. 在 Java 的 String 类中,可以使用 format() 方法 ...
- Android Notification 详解(一)——基本操作
Android Notification 详解(一)--基本操作 版权声明:本文为博主原创文章,未经博主允许不得转载. 微博:厉圣杰 源码:AndroidDemo/Notification 文中如有纰 ...
- Android Notification 详解——基本操作
Android Notification 详解 版权声明:本文为博主原创文章,未经博主允许不得转载. 前几天项目中有用到 Android 通知相关的内容,索性把 Android Notificatio ...
随机推荐
- Quartz.net入门
简介 Quartz.NET是一个开源的作业调度框架,是OpenSymphony的 Quartz API的.NET移植,它用C#写成,可用于winform和asp.net应用中.它提供了巨大的灵活性而不 ...
- alpha冲刺6/10
目录 摘要 团队部分 个人部分 摘要 队名:小白吃 组长博客:hjj 作业博客:感恩节~ 团队部分 后敬甲(组长) 过去两天完成了哪些任务 文字描述 设计了拍照界面和图片上传界面 沟通了前端进度 接下 ...
- python--实践--模拟浏览器(http)登陆
#方法一:直接使用coookies登陆,此方法需要提前在浏览器中使用账号密码登陆后,获取浏览器中的cookies,在构造的请求中携带这个cookies(缺点是有时效性). #方法二:通过账号密码(Fr ...
- P1120 小木棍 [数据加强版] 回溯法 终极剪枝
题目描述 乔治有一些同样长的小木棍,他把这些木棍随意砍成几段,直到每段的长都不超过5050. 现在,他想把小木棍拼接成原来的样子,但是却忘记了自己开始时有多少根木棍和它们的长度. 给出每段小木棍的长度 ...
- 045 RDD与DataFrame互相转换
一:RDD与DataFrame互相转换 1.总纲 二:DataFrame转换为RDD 1.rdd 使用schema可以获取DataFrame的schema 使用rdd可以获取DataFrame的数据 ...
- scrapy 手动编写模板
import scrapy class Tzspider(scrapy.Spider): # spider的名字,唯一 name = 'tz' # 初始url列表 start_urls = ['htt ...
- 初识Linux系统
1. pwd 显示现在所在位置 2. ls 显示目录下的文件 ls -a:显示隐藏文件(带 . 的就是隐藏文件): ls -a -l :每个文件夹的详细信息: ls > bbb (把查到的所有文 ...
- 富文本编辑器上传图片需要配置js,后台代码
富文本编辑器上传图片需要配置js,后台代码
- Codeforces 1131F Asya And Kittens (构造)【并查集】
<题目链接> 题目大意:有$n$只小猫,开始将它们放在指定的n个单元格内,然后随机从n-1个隔板中拆除隔板,最终使得这些小猫在同一单元格.现在依次给出拆除隔板的顺序,比如:1 4 就表示1 ...
- Django之模板基础
Django之模板 目录 变量 过滤器 标签的使用 变量 变量的引用格式 使用双括号,两边空格不能省略. 语法格式: {{var_name}} Template和Context对象 context 字 ...