BAT面试上机题从3亿个ip中找出访问次数最多的IP详解
我们面临的问题有以下两点:
1)数据量太大,无法在短时间内解决;
2)内存不够,没办法装下那么多的数据。
而对应的办法其实也就是分成1)针对时间,合适的算法+合适的数据结构来提高处理效率;2)针对空间,就是分而治之,将大数据量拆分成多个比较小的数据片,然后对其各个数据片进行处理,最后再处理各个数据片的结果。
原文中也给出一个问题,"从3亿个ip中访问次数最多的IP",就试着来解决一下吧。
1)首先,生成3亿条数据,为了产生更多的重复ip,前面两节就不变了,只随机生成后面的2节。
private static String generateIp() {
return "192.168." + (int) (Math.random() * 255) + "."
+ (int) (Math.random() * 255) + "\n";
}
private static void generateIpsFile() {
File file = new File(FILE_NAME);
try {
FileWriter fileWriter = new FileWriter(file);
for (int i = 0; i < MAX_NUM; i++) {
fileWriter.write(generateIp());
}
fileWriter.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
1个char是一个Byte,每个ip大概是11Btye,所以生成的ip文件,大概是3,500,000 KB,如下:
2)文件生成了,那么我们现在就要假设内存不是很够,没有办法一次性装入那么多的数据,所以要先把文件给拆分成多个小文件。
在这里采取的是就是Hash取模的方式,将字符串的ip地址给转换成一个长整数,并将这个数对3000取模,将模一样的ip放到同一个文件,这样就能够生成3000个小文件,每个文件就只有1M多,在这里已经是足够小的了。
首先是hash跟取模函数:
private static String hash(String ip) {
long numIp = ipToLong(ip);
return String.valueOf(numIp % HASH_NUM);
}
private static long ipToLong(String strIp) {
long[] ip = new long[4];
int position1 = strIp.indexOf(".");
int position2 = strIp.indexOf(".", position1 + 1);
int position3 = strIp.indexOf(".", position2 + 1);
ip[0] = Long.parseLong(strIp.substring(0, position1));
ip[1] = Long.parseLong(strIp.substring(position1 + 1, position2));
ip[2] = Long.parseLong(strIp.substring(position2 + 1, position3));
ip[3] = Long.parseLong(strIp.substring(position3 + 1));
return (ip[0] << 24) + (ip[1] << 16) + (ip[2] << 8) + ip[3];
}
2.1)将字符串的ip转换成长整数
2.2)对HASH_NUM,这里HASH_NUM = 3000;
下面是拆文件的函数:
private static void divideIpsFile() {
File file = new File(FILE_NAME);
Map<String, StringBuilder> map = new HashMap<String,StringBuilder>();
int count = 0;
try {
FileReader fileReader = new FileReader(file);
BufferedReader br = new BufferedReader(fileReader);
String ip;
while ((ip = br.readLine()) != null) {
String hashIp = hash(ip);
if(map.containsKey(hashIp)){
StringBuilder sb = (StringBuilder)map.get(hashIp);
sb.append(ip).append("\n");
map.put(hashIp, sb);
}else{
StringBuilder sb = new StringBuilder(ip);
sb.append("\n");
map.put(hashIp, sb);
}
count++;
if(count == 4000000){
Iterator<String> it = map.keySet().iterator();
while(it.hasNext()){
String fileName = it.next();
File ipFile = new File(FOLDER + "/" + fileName + ".txt");
FileWriter fileWriter = new FileWriter(ipFile, true);
StringBuilder sb = map.get(fileName);
fileWriter.write(sb.toString());;
fileWriter.close();
}
count = 0;
map.clear();
}
}
br.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
2.3)在这里,我们如果每读取一个ip,经过hash映射之后,就直接打开文件,将其加到对应的文件末尾,那么有3亿条ip,我们就要读写文件3亿次,那IO开销的时候就相当大,所以我们可以先拿一个Map放着,等到一定的规模之后,再统一写进文件,然后把map清空,继续映射,这样的话,就能够提高折分的速度。而这个规模,就是根据能处理的内存来取的值的,如果内存够大,这个值就可以设置大点,如果内存小,就要设置小一点的值,IO开销跟内存大小,总是需要在这两者之间的取个平衡点的。
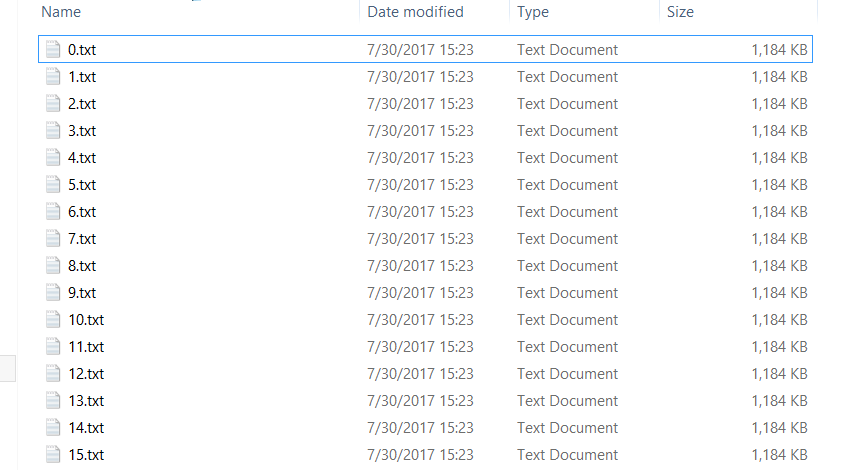
可以看到,这样我们拆分成了3000个小文件,每个文件只有1100KB左右,所耗的时间如下,17分钟到18分钟左右:
Start Divide Ips File: 06:18:11.103
End: 06:25:44.134
而这种映射可以保证同样的IP会映射到相同的文件中,这样后面在统计IP的时候,就可以保证在a文件中不是最多次数的ip(即使是第2多),也不会出现在其它的文件中。
3)文件拆分了之后,接下来我们就要分别读取这3000个小文件,统计其中每个IP出现的次数。
private static void calculate() {
File folder = new File(FOLDER);
File[] files = folder.listFiles();
FileReader fileReader;
BufferedReader br;
for (File file : files) {
try {
fileReader = new FileReader(file);
br = new BufferedReader(fileReader);
String ip;
Map<String, Integer> tmpMap = new HashMap<String, Integer>();
while ((ip = br.readLine()) != null) {
if (tmpMap.containsKey(ip)) {
int count = tmpMap.get(ip);
tmpMap.put(ip, count + 1);
} else {
tmpMap.put(ip, 0);
}
}
fileReader.close();
br.close();
count(tmpMap,map);
tmpMap.clear();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
count(map,finalMap);
Iterator<String> it = finalMap.keySet().iterator();
while(it.hasNext()){
String ip = it.next();
System.out.println("result IP : " + ip + " | count = " + finalMap.get(ip));
}
}
private static void count(Map<String, Integer> pMap, Map<String, Integer> resultMap) {
Iterator<Entry<String, Integer>> it = pMap.entrySet().iterator();
int max = 0;
String resultIp = "";
while (it.hasNext()) {
Entry<String, Integer> entry = (Entry<String, Integer>) it.next();
if (entry.getValue() > max) {
max = entry.getValue();
resultIp = entry.getKey();
}
}
resultMap.put(resultIp,max);
}
3.1)第一步要读取每个文件,将其中的ip放到一个Map中,然后调用count()方法,找出map中最大访问次数的ip,将ip和最多访问次数存到另外一个map中。
3.2)当3000个文件都读取完之后,我们就会产生一个有3000条记录的map,里面存储了每个文件中访问次数最多的ip,我们再调用count()方法,找出这个map中访问次数最大的ip,即这3000个文件中,哪个文件中的最高访问量的IP,才是真正最高的,好像小组赛到决赛一样。。。。
3.3)在这里没有用到什么堆排序和快速排序,因为只需要一个最大值,所以只要拿当前的最大值跟接下来的值判断就好,其实也相当跟只有一个元素的堆的堆顶元素比较。
下面就是我们的结果 。
Start Calculate Ips: 06:37:51.088
result IP : 192.168.67.98 | count = 1707
End: 06:54:30.221
到这里,我们就把这个ip给查找出来了。
其实理解了这个思路,其它的海量数据问题,虽然可能各个问题有各个问题的特殊之处,但总的思路我觉得应该是相似的。
BAT面试上机题从3亿个ip中找出访问次数最多的IP详解的更多相关文章
- 从一亿个ip找出出现次数最多的IP(分治法)
/* 1,hash散列 2,找到每个块出现次数最多的(默认出现均匀)—–>可以用字典树 3,在每个块出现最多的数据中挑选出最大的为结果 */ 问题一: 怎么在海量数据中找出重复次数最多的一个 算 ...
- 【剑指Offer面试编程题】题目1373:整数中1出现的次数--九度OJ
题目描述: 亲们!!我们的外国友人YZ这几天总是睡不好,初中奥数里有一个题目一直困扰着他,特此他向JOBDU发来求助信,希望亲们能帮帮他.问题是:求出1~13的整数中1出现的次数,并算出100~130 ...
- Spark实战--寻找5亿次访问中,访问次数最多的人
问题描述 对于一个大型网站,用户访问量尝尝高达数十亿.对于数十亿是一个什么样的概念,我们这里可以简单的计算一下.对于一个用户,单次访问,我们通常会记录下哪些数据呢? 1.用户的id 2.用户访问的时间 ...
- 海量数据处理 - 10亿个数中找出最大的10000个数(top K问题)
前两天面试3面学长问我的这个问题(想说TEG的3个面试学长都是好和蔼,希望能完成最后一面,各方面原因造成我无比想去鹅场的心已经按捺不住了),这个问题还是建立最小堆比较好一些. 先拿10000个数建堆, ...
- 刷题之给定一个整数数组 nums 和一个目标值 taget,请你在该数组中找出和为目标值的那 两个 整数
今天下午,看了一会github,想刷个题呢,就翻出来了刷点题提高自己的实际中的解决问题的能力,在面试的过程中,我们发现,其实很多时候,面试官 给我们的题,其实也是有一定的随机性的,所以我们要多刷更多的 ...
- ytu 1061: 从三个数中找出最大的数(水题,模板函数练习 + 宏定义练习)
1061: 从三个数中找出最大的数 Time Limit: 1 Sec Memory Limit: 128 MBSubmit: 154 Solved: 124[Submit][Status][We ...
- 如何从 100 亿 URL 中找出相同的 URL?
题目描述 给定 a.b 两个文件,各存放 50 亿个 URL,每个 URL 各占 64B,内存限制是 4G.请找出 a.b 两个文件共同的 URL. 解答思路 每个 URL 占 64B,那么 50 亿 ...
- php面试上机题(2018-3-3)
需求:将第三方api的前3000条数据全部读取出来,存入对应的数据库字段 第三方api:http://pub.cloudmob.mobi/publisherapi/offers/?uid=92& ...
- 【剑指Offer面试编程题】题目1348:数组中的逆序对--九度OJ
题目描述: 在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对.输入一个数组,求出这个数组中的逆序对的总数. 输入: 每个测试案例包括两行: 第一行包含一个整数n,表示数组 ...
随机推荐
- [POJ2287][Tyvj1048]田忌赛马 (贪心+DP)
瞎扯 很经典的一道题 考前才打 我太菜了QAQ 就是先贪心排序了好 然后在DP 这样比直接DP更容易理解 (其实这题做法还有很多) 代码 #include<cstdio> #include ...
- Shooting Contest 射击比赛 [POJ1719] [CEOI1997] [一题多解]
Description(下有中文题意) Welcome to the Annual Byteland Shooting Contest. Each competitor will shoot to a ...
- java内存和linux关系
运行个JAVA 用sleep去hold住 package org.hjb.test; public class TestOnly { public static void main(String[] ...
- C_关于递归算法的几个例子
1.递归算法的定义: 2.递归与迭代的优劣 eg1:斐波那契数列:斐波那契数列(Fibonacci sequence),又称黄金分割数列.因数学家列昂纳多·斐波那契(Leonardoda Fibona ...
- 几个例子弄懂JS 的setTimeout的运行方式
function test() { var a = 1; setTimeout(function() { alert(a); a = 5 ...
- Codefoces909E Coprocessor(拓扑排序)
http://codeforces.com/problemset/problem/909/E 由于分了两个queue,所以push的时候可以统一操作,不会影响彼此.两个queue相当于是平等的,只是q ...
- javacript onclick事件中传递对象参数
var user = {id:1, name:'zs', age:20}; var ele = '<a onclick="edit(' + JSON.stringify(user).r ...
- netty4.0 Server和Client的通信
netty4.0 Server和Client的通信 创建一个maven项目 添加Netty依赖 <dependency> <groupId>io.netty</group ...
- Java RandomAccessFile与MappedByteBuffer
Java RandomAccessFile与MappedByteBuffer https://www.cnblogs.com/guazi/p/6838915.html
- SpringBoot2.0针对请求参数@RequestBody验证统一拦截
title: "SpringBoot2.0针对请求参数@RequestBody验证的统一拦截"categories: SpringBoot2.0 Shirotags: Spring ...