TLB的作用及工作原理
TLB的作用及工作过程
以下内容摘自《步步惊芯——软核处理器内部设计分析》一书
页表一般都很大,并且存放在内存中,所以处理器引入MMU后,读取指令、数据需要访问两次内存:首先通过查询页表得到物理地址,然后访问该物理地址读取指令、数据。为了减少因为MMU导致的处理器性能下降,引入了TLB,TLB是Translation Lookaside Buffer的简称,可翻译为“地址转换后援缓冲器”,也可简称为“快表”。简单地说,TLB就是页表的Cache,其中存储了当前最可能被访问到的页表项,其内容是部分页表项的一个副本。只有在TLB无法完成地址翻译任务时,才会到内存中查询页表,这样就减少了页表查询导致的处理器性能下降。
TLB中的项由两部分组成:标识和数据。标识中存放的是虚地址的一部分,而数据部分中存放物理页号、存储保护信息以及其他一些辅助信息。虚地址与TLB中项的映射方式有三种:全关联方式、直接映射方式、分组关联方式。OR1200处理器中实现的是直接映射方式,所以本书只对直接映射方式作介绍。直接映射方式是指每一个虚拟地址只能映射到TLB中唯一的一个表项。假设内存页大小是8KB,TLB中有64项,采用直接映射方式时的TLB变换原理如图10.4所示。
因为页大小是8KB,所以虚拟地址的0-12bit作为页内地址偏移。TLB表有64项,所以虚拟地址的13-18bit作为TLB表项的索引。假如虚拟地址的13-18bit是1,那么就会查询TLB的第1项,从中取出标识,与虚拟地址的19-31位作比较,如果相等,表示TLB命中,反之,表示TLB失靶。TLB失靶时,可以由硬件将需要的页表项加载入TLB,也可由软件加载,具体取决于处理器设计,OR1200没有提供硬件加载页表项的功能,只能由软件实现。TLB命中时,此时翻译得到的物理地址就是TLB第1项中的标识(即物理地址13-31位)与虚拟地址0-12bit的结合。在地址翻译的过程中还会结合TLB项中的辅助信息判断是否发生违反安全策略的情况,比如:要修改某一页,但该页是禁止修改的,此时就违反了安全策略,会触发异常。
OR1200中的MMU分为指令MMU、数据MMU,分别简称为IMMU、DMMU。采用的是页式内存管理机制,每一页大小是8KB,没有实现页表管理、页表查询、更新、锁定等功能,都需要软件实现。实际上OR1200的MMU模块主要实现的就是TLB,OR1200中TLB的大小可以配置,默认是64项,采用的是直接映射方式。IMMU中有ITLB,DMMU中有DTLB,但是ITLB、DTLB的加载、更新、失效、替换等功能也都需要软件实现。本章从下一节开始将分别对IMMU、DMMU进行分析。
TLB工作原理
TLB - translation lookaside buffer
快表,直译为旁路快表缓冲,也可以理解为页表缓冲,地址变换高速缓存。
由于页表存放在主存中,因此程序每次访存至少需要两次:一次访存获取物理地址,第二次访存才获得数据。提高访存性能的关键在于依靠页表的访问局部性。当一个转换的虚拟页号被使用时,它可能在不久的将来再次被使用到,。
TLB是一种高速缓存,内存管理硬件使用它来改善虚拟地址到物理地址的转换速度。当前所有的个人桌面,笔记本和服务器处理器都使用TLB来进行虚拟地址到物理地址的映射。使用TLB内核可以快速的找到虚拟地址指向物理地址,而不需要请求RAM内存获取虚拟地址到物理地址的映射关系。这与data cache和instruction caches有很大的相似之处。
TLB原理
当cpu要访问一个虚拟地址/线性地址时,CPU会首先根据虚拟地址的高20位(20是x86特定的,不同架构有不同的值)在TLB中查找。如果是表中没有相应的表项,称为TLB miss,需要通过访问慢速RAM中的页表计算出相应的物理地址。同时,物理地址被存放在一个TLB表项中,以后对同一线性地址的访问,直接从TLB表项中获取物理地址即可,称为TLB hit。
想像一下x86_32架构下没有TLB的存在时的情况,对线性地址的访问,首先从PGD中获取PTE(第一次内存访问),在PTE中获取页框地址(第二次内存访问),最后访问物理地址,总共需要3次RAM的访问。如果有TLB存在,并且TLB hit,那么只需要一次RAM访问即可。
TLB表项
TLB内部存放的基本单位是页表条目,对应着RAM中存放的页表条目。页表条目的大小固定不变的,所以TLB容量越大,所能存放的页表条目越多,TLB hit的几率也越大。但是TLB容量毕竟是有限的,因此RAM页表和TLB页表条目无法做到一一对应。因此CPU收到一个线性地址,那么必须快速做两个判断:
1 所需的也表示否已经缓存在TLB内部(TLB miss或者TLB hit)
2 所需的页表在TLB的哪个条目内
为了尽量减少CPU做出这些判断所需的时间,那么就必须在TLB页表条目和内存页表条目之间的对应方式做足功夫
全相连 - full associative
在这种组织方式下,TLB cache中的表项和线性地址之间没有任何关系,也就是说,一个TLB表项可以和任意线性地址的页表项关联。这种关联方式使得TLB表项空间的利用率最大。但是延迟也可能相当的大,因为每次CPU请求,TLB硬件都把线性地址和TLB的表项逐一比较,直到TLB hit或者所有TLB表项比较完成。特别是随着CPU缓存越来越大,需要比较大量的TLB表项,所以这种组织方式只适合小容量TLB
直接匹配
每一个线性地址块都可通过模运算对应到唯一的TLB表项,这样只需进行一次比较,降低了TLB内比较的延迟。但是这个方式产生冲突的几率非常高,导致TLB miss的发生,降低了命中率。
比如,我们假定TLB cache共包含16个表项,CPU顺序访问以下线性地址块:1, 17 , 1, 33。当CPU访问地址块1时,1 mod 16 = 1,TLB查看它的第一个页表项是否包含指定的线性地址块1,包含则命中,否则从RAM装入;然后CPU方位地址块17,17 mod 16 = 1,TLB发现它的第一个页表项对应的不是线性地址块17,TLB miss发生,TLB访问RAM把地址块17的页表项装入TLB;CPU接下来访问地址块1,此时又发生了miss,TLB只好访问RAM重新装入地址块1对应的页表项。因此在某些特定访问模式下,直接匹配的性能差到了极点
组相连 - set-associative
为了解决全相连内部比较效率低和直接匹配的冲突,引入了组相连。这种方式把所有的TLB表项分成多个组,每个线性地址块对应的不再是一个TLB表项,而是一个TLB表项组。CPU做地址转换时,首先计算线性地址块对应哪个TLB表项组,然后在这个TLB表项组顺序比对。按照组长度,我们可以称之为2路,4路,8路。
经过长期的工程实践,发现8路组相连是一个性能分界点。8路组相连的命中率几乎和全相连命中率几乎一样,超过8路,组内对比延迟带来的缺点就超过命中率提高带来的好处了。
这三种方式各有优缺点,组相连是个折衷的选择,适合大部分应用环境。当然针对不同的领域,也可以采用其他的cache组织形式。
TLB表项更新
TLB表项更新可以有TLB硬件自动发起,也可以有软件主动更新
1. TLB miss发生后,CPU从RAM获取页表项,会自动更新TLB表项
2. TLB中的表项在某些情况下是无效的,比如进程切换,更改内核页表等,此时CPU硬件不知道哪些TLB表项是无效的,只能由软件在这些场景下,刷新TLB。
在linux kernel软件层,提供了丰富的TLB表项刷新方法,但是不同的体系结构提供的硬件接口不同。比如x86_32仅提供了两种硬件接口来刷新TLB表项:
1. 向cr3寄存器写入值时,会导致处理器自动刷新非全局页的TLB表项
2. 在Pentium Pro以后,invlpg汇编指令用来无效指定线性地址的单个TLB表项无效。
MMU和cache详解(TLB机制)
1. MMU
MMU:memory management unit,称为内存管理单元,或者是存储器管理单元,MMU是硬件设备,它被保存在主存(main memory)的两级也表控制,并且是由协处理器CP15的寄存器1的M位来决定是enabled还是disabled。MMU的主要作用是负责从CPU内核发出的虚拟地址到物理地址的映射,并提供硬件机制的内存访问权限检查。MMU使得每个用户进程拥有自己的地址空间(对于WINCE5.0,每个进程是32MB;而对于WINCE6.0,每个进程的独占的虚拟空间是2GB),并通过内存访问权限的检查保护每个进程所用的内存不被其他进程破坏。
下面是MMU提供的功能和及其特征

2. VA和PA
VA:virtual address称为虚拟地址,PA:physical address称为物理地址。CPU通过地址来访问内存中的单元,如果CPU没有MMU,或者有MMU但没有启动,那么CPU内核在取指令或者访问内存时发出的地址(此时必须是物理地址,假如是虚拟地址,那么当前的动作无效)将直接传到CPU芯片的外部地址引脚上,直接被内存芯片(物理内存)接收,这时候的地址就是物理地址。如果CPU启用了MMU(一般是在bootloader中的eboot阶段的进入main()函数的时候启用),CPU内核发出的地址将被MMU截获,这时候从CPU到MMU的地址称为虚拟地址,而MMU将这个VA翻译成为PA发到CPU芯片的外部地址引脚上,也就是将VA映射到PA中。MMU将VA映射到PA是以页(page)为单位的,对于32位的CPU,通常一页为4k,物理内存中的一个物理页面称页为一个页框(page frame)。虚拟地址空间划分成称为页(page)的单位,而相应的物理地址空间也被进行划分,单位是页框(frame).页和页框的大小必须相同。
3. VA到PA的映射过程
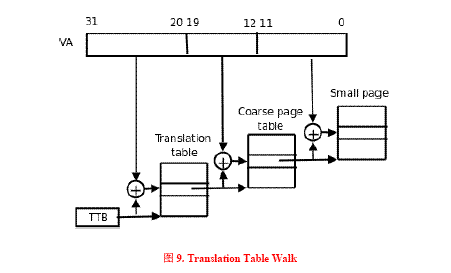
首先将CPU内核发送过来的32位VA[31:0]分成三段,前两段VA[31:20]和VA[19:12]作为两次查表的索引,第三段VA[11:0]作为页内的偏移,查表的步骤如下:
⑴从协处理器CP15的寄存器2(TTB寄存器,translation table base register)中取出保存在其中的第一级页表(translation table)的基地址,这个基地址指的是PA,也就是说页表是直接按照这个地址保存在物理内存中的。
⑵以TTB中的内容为基地址,以VA[31:20]为索引值在一级页表中查找出一项(2^12=4096项),这个页表项(也称为一个描述符,descriptor)保存着第二级页表(coarse page table)的基地址,这同样是物理地址,也就是说第二级页表也是直接按这个地址存储在物理内存中的。
⑶以VA[19:12]为索引值在第二级页表中查出一项(2^8=256),这个表项中就保存着物理页面的基地址,我们知道虚拟内存管理是以页为单位的,一个虚拟内存的页映射到一个物理内存的页框,从这里就可以得到印证,因为查表是以页为单位来查的。
⑷有了物理页面的基地址之后,加上VA[11:0]这个偏移量(2^12=4KB)就可以取出相应地址上的数据了。
这个过程称为Translation Table Walk,Walk这个词用得非常形象。从TTB走到一级页表,又走到二级页表,又走到物理页面,一次寻址其实是三次访问物理内存。注意这个“走”的过程完全是硬件做的,每次CPU寻址时MMU就自动完成以上四步,不需要编写指令指示MMU去做,前提是操作系统要维护页表项的正确性,每次分配内存时填写相应的页表项,每次释放内存时清除相应的页表项,在必要的时候分配或释放整个页表。
4. CPU访问内存时的硬件操作顺序
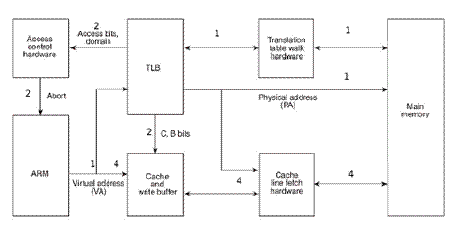
CPU访问内存时的硬件操作顺序,各步骤在图中有对应的标号:
1 CPU内核(图中的ARM)发出VA请求读数据,TLB(translation lookaside buffer)接收到该地址,那为什么是TLB先接收到该地址呢?因为TLB是MMU中的一块高速缓存(也是一种cache,是CPU内核和物理内存之间的cache),它缓存最近查找过的VA对应的页表项,如果TLB里缓存了当前VA的页表项就不必做translation table walk了,否则就去物理内存中读出页表项保存在TLB中,TLB缓存可以减少访问物理内存的次数。
2 页表项中不仅保存着物理页面的基地址,还保存着权限和是否允许cache的标志。MMU首先检查权限位,如果没有访问权限,就引发一个异常给CPU内核。然后检查是否允许cache,如果允许cache就启动cache和CPU内核互操作。
3 如果不允许cache,那直接发出PA从物理内存中读取数据到CPU内核。
4 如果允许cache,则以VA为索引到cache中查找是否缓存了要读取的数据
,如果cache中已经缓存了该数据(称为cache hit)则直接返回给CPU内核,如果cache中没有缓存该数据(称为cache miss),则发出PA从物理内存中读取数据并缓存到cache中,同时返回给CPU内核。但是cache并不是只去CPU内核所需要的数据,而是把相邻的数据都去上来缓存,这称为一个cache line。ARM920T的cache line是32个字节,例如CPU内核要读取地址0x30000134~0x3000137的4个字节数据,cache会把地址0x30000120~0x3000137(对齐到32字节地址边界)的32字节都取上来缓存。
5. ARM920T支持多种尺寸规格的页表
ARM体系结构最多使用两级页表来进行转换,页表由一个个条目组成,每个条目存储一段虚拟地址对应的物理地址及访问权限,或者下一级页表的地址。S3C2443最多会用到两级页表,已段(section,大小为1M)的方式进行转换时只用到一级页表,以页(page)的方式进行转换时用到两级页表。而页的大小有3种:大页(large pages,64KB),小页(small pages,4KB)和极小页(tiny pages,1KB)。条目也成为描述符,有段描述符、大页描述符、小页描述符和极小页描述符,分别保存段、大页、小页和极小页的起始物理地址,见下图

MMU的查表过程,首先从CP15的寄存器TTB找到一级页表的基地址,再把VA[31:20]作为索引值从表中找出一项,这个表项称为一级页描述符(level one descriptor),一个这样的表项占4个字节,那么一级页表需要保存的物理内存的大小是4*4096=16KB,表项可以是一下四种格式之一:
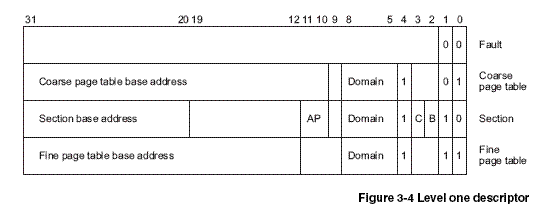
⑴如果描述符的最低位是00,属于fault格式,表示该范围的VA没有映射到PA。
⑵如果描述符的最低位是10,属于section格式,这种格式没有二级页表而是直接映射到物理页面,一个色彩体哦你是1M的大页面,描述符中的VA[31:20]就是这个页面的基地址,基地址的VA[19:0]低位全为0,对齐到1M地址边界,描述符中的domain和AP位控制访问权限,C、B两位控制缓存。
⑶如果描述符的最低两位是01或11,则分别对应两种不同规格的二级页表。根据地址对齐的规律想一下,这两种页表分别是多大?从一级描述符中取出二级页表的基地址,再把VA的一部分作为索引去查二级描述符(level two descriptor),如果是coarse page,则VA[19:12](2^8=256)作为查找二级页表表项的索引;如果是fine page,则VA[19:10](2^10=024)。二级描述符可以是下面四种格式之一:

二级描述符最低两位是00是属于fault格式,其它三种情况分别对应三种不同规格的物理页面,分别是large page(64KB)、small page(4KB)和tiny page(1KB),其中large page和small page有4组AP权限位,每组两个bit,这样可以为每1/4个物理页面分别设置不同的权限,也就是说large page可以为每16KB设置不同的权限,small page可以为每1KB设置不同的权限。
ARM920T提供了多种页表和页面规格,但操作系统只采用其中一种,WINCE采用的就是一级描述符是coarse page table格式(也即由VA[19:12]来作为查找二级页表项的索引),二级描述符是small page格式(也即是VA[11:0]来作为查找物理页面偏移量的索引),每个物理页面大小是4KB。

根据上图我们来分析translation table walk的过程
⑴VA被划分为三段用于地址映射过程,各段的长度取决于页描述符的格式。
⑵TTB寄存器中只有[31:14]位有效,低14位全为0,因此一级页表的基地址对齐到16K地址边界,而一级页表的大小也是16K。
⑶一级页表的基地址加上VA[31:20]左移两位组成一个物理地址。想一想为什么VA[31:20]要左移两位占据[13:2]的位置,而空出[1:0]两位呢?应该是需要空出最低两位用于表示当前要寻找的一级描述符是coarse page格式,目前不清楚,有待了解。
⑷用这个组装的物理地址从物理内存中读取一级页表描述符,这是一个coarse page table格式的描述符。
⑸通过domain权限检查后,coarse page table的基地址再加上VA[19:12]左移两位组装成一个物理地址。
⑹用这个组装的物理地址从物理内存中读取二级页表描述符,这是一个small page格式的描述符。
⑺通过AP权限检查后,small page的基地址再加上VA[11:0]就是最终的物理地址了。
Linux内核-内存-硬件高速缓存和TLB原理
硬件高速缓存和TLB原理
基本概念
硬件高速缓存的引入是为了缩小CPU和RAM之间的速度不匹配,高速缓存单元插在分页单元和主内存之间,它包含一个硬件高速缓存内存和一个高速缓存控制器。高速缓存内存存放内存中真正的行。高速缓存控制器存放一个表项数组,每个表项对应高速缓存内存中的一个行,如下图:
除了通用硬件高速缓存,80x86处理器还包含了另一个称为转换后援缓冲器或TLB(Translation Lookaside Buffer)的高速缓存用于加快线性地址的转换。TLB是一个小的、虚拟寻址的缓存,其中的每一行都保存着一个由单个页表条目组成的块。
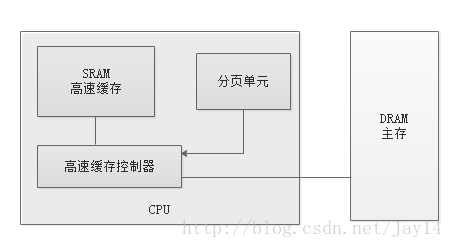
原理
下面通过一个具体的地址翻译示例来说明缓存和TLB的原理(注意:这是简化版的示例,实际过程可能复杂些,不过原理相同),地址翻译基于以下设定:
- 存储器是按字节寻址的
- 存储器访问是针对1字节的字的
- 虚拟地址(线性地址)是14位长的
- 物理地址是12位长的
- 页面大小是64字节
- TLB是四路组相连的,总共有16个条目
- L1 Cache是物理寻址、直接映射的,行大小为4字节,总共有16个组
下面给出小存储系统的一个快照,包括TLB、页表的一部分和L1高速缓存
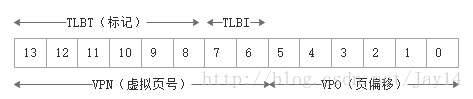
虚拟地址(TLBI为索引):
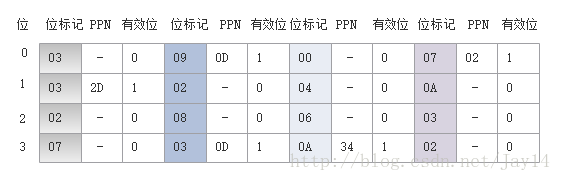
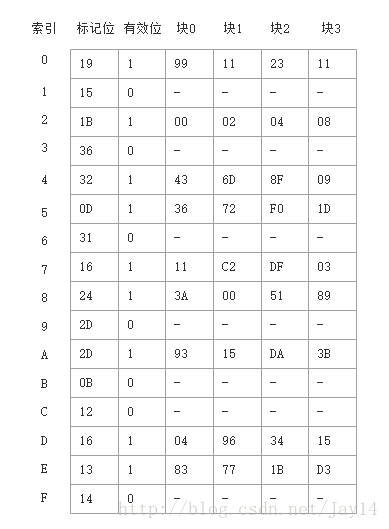
TLB:四组,16个条目,四路组相连(PPN为物理页号):
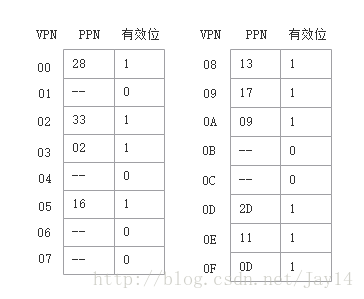
页表:只展示前16个页表条目(PTE)
物理地址(CO为块偏移):
高速缓存:16个组,4字节的块,直接映射
基于以上的设定,我们来看下当CPU执行一条读地址0x3d4(虚拟地址)处字节的加载指令时发生了什么:
- 从0x3d4中取出如下几个字段:
- TLBT: 0x03
- TLBI: 0x03
- VPN: 0x0F
- VPO: 0x14
- 首先,MMU从虚拟地址中取出以上字段,然后检查TLB,看它是否因为前面的某个存储器的引用而缓存了PTE0x0F的一个拷贝。TLB从VPN中抽取出TLB索引(TLBI:0x03)和TLB标记(TLBT:0x03),由上面的TLB表格可知,组0x3的第二个条目中有效匹配,所以命中,将缓存的PPN(0x0D)返回给MMU。
- 将上述的PPN(0x0D)和来自虚拟地址的VPO(0x14)连接起来,得到物理地址(0x354)。
- 接下来,MMU发送物理地址给缓存,缓存从物理地址中取出缓存偏移CO(0x0)、缓存组索引CI(0x5)以及缓存标记CT(0x0D)。
- 从上面高速缓存表格中可得,组0x5中的标记与CT相匹配,所以缓存检测到一个命中,读出在偏移量CO处的数据字节(0x36),并将它返回给MMU,随后MMU将它传递回CPU。
以上只分析命中的情况。
TLB的作用及工作原理的更多相关文章
- Cookie和Session的作用和工作原理
一.Cookie详解 (1)简介 因为HTTP协议是无状态的,即服务器不知道用户上一次做了什么,这严重阻碍了交互式Web应用程序的实现.在典型的网上购物场景中,用户浏览了几个页面,买了一盒饼干和两饮料 ...
- php面试题五之nginx如何调用php和php-fpm的作用和工作原理
nginx如何调用php 采用nginx+php作为webserver的架构模式,在现如今运用相当广泛.然而第一步需要实现的是如何让nginx正确的调用php.由于nginx调用php并不是如同调用一 ...
- TLB的作用及工作过程
下面内容摘自<步步惊芯--软核处理器内部设计分析>一书 页表一般都非常大,而且存放在内存中,所以处理器引入MMU后,读取指令.数据须要訪问两次内存:首先通过查询页表得到物 ...
- 3.httphandler和httpmodule各种的作用以及工作原理?
首先应该知道的是ASP.NET 请求处理过程是基于管道模型的,这个管道模型是由多个HttpModule和HttpHandler组成,ASP.NET 把http请求依次传递给管道中各个HttpModul ...
- 5.cookie每个参数的意义和作用以及工作原理?
cookie主要参数有: (1)expires 过期时间 (2)path cookie存放路径 (3)domain 域名 同域名下可访问 (4)Set-Cookie: name cookie名称
- 4.cache每个参数的意义和作用以及工作原理?
在程序开发过程中,适当使用 Cache 缓存能有效提高程序执行效率.比如一些常常调用的系统公共变量,把它们缓存到 Cache 中,当需要使用它们时,直接从 Cache 中读取,不必每次都从数据库或文件 ...
- hibernate工作原理及作用
转载自 http://www.cnblogs.com/dashi/p/3597969.html#commentform JAVA Hibernate工作原理及为什么要用 hibernate 简介:hi ...
- C++中虚函数的作用和虚函数的工作原理
1 C++中虚函数的作用和多态 虚函数: 实现类的多态性 关键字:虚函数:虚函数的作用:多态性:多态公有继承:动态联编 C++中的虚函数的作用主要是实现了多态的机制.基类定义虚函数,子类可以重写该函数 ...
- Spring工作原理及其作用
1.springmvc请所有的请求都提交给DispatcherServlet,它会委托应用系统的其他模块负责负责对请求进行真正的处理工作. 2.DispatcherServlet查询一个或多个Hand ...
随机推荐
- am335x uboot2016.05 (MLO u-boot.img)执行流程(转)
am335x的cpu上电后,执行流程:ROM->MLO(SPL)->u-boot.img 第一级bootloader:引导加载程序,板子上电后会自动执行这些代码,如启动方式(SDcard. ...
- Linux学习笔记8
其他常用命令 cd+回车=回车~ 进入当前用户主目录 查看指定进程信息 #ps -ef |grep 进程名 #ps ---查看属于自己的进程 #ps -aux 查看所有用户的执行进程 换成 p ...
- Linux学习笔记6
less 命令 空格或者 ctrl+f 前进一屏 ctrl+b 回退一屏 回车 前进一行 /String 查找含有string 字符串的页 ?String 同上 <反方向查找> ...
- SpringBoot使用Swagger2实现Restful API
很多时候,我们需要创建一个接口项目用来数据调转,其中不包含任何业务逻辑,比如我们公司.这时我们就需要实现一个具有Restful API的接口项目. 本文介绍springboot使用swagger2实现 ...
- Xamarin Essentials教程检查网络连通性Connectivity
Xamarin Essentials教程检查网络连通性Connectivity 网络连通性其实就是检测当前设备有没有连接网络.网络连通性在很多与网络相关的应用程序中会使用到.在Xamarin中如果 ...
- web前端知识大纲:系列一 js篇
web前端庞大而复杂的知识体系的组成:html.css和 javascript 一.js 1.基础语法 Javascript 基础语法包括:变量声明.数据类型. ...
- VUE学习第一天,安装
vue生命周期好文章: http://www.zhimengzhe.com/Javascriptjiaocheng/236707.html
- LINUX文件及目录管理命令基础
Linux命令行组成结构 Linux命令结构 在Linux中一切皆文件,一切皆命令! 命令提示符: [root@tt ~]# [xiaohui@tt ~]$ Linux命令行常用快捷键 ctrl + ...
- vim技巧5 常用操作
vim:set number:set nonumbern 移动命令键8l 向右移动八个字符3j 向下移动三行3G:移动到第三行行首10$:下移到10行,并定位到行尾:n1,n2s/word1/word ...
- meta中minimal-ui属性
<meta id="viewport" name="viewport" content="width=device-width, user-sc ...