MySQL技术内幕读书笔记(二)——InnoDB存储引擎
InnoDB存储引擎
InnoDB存储架构
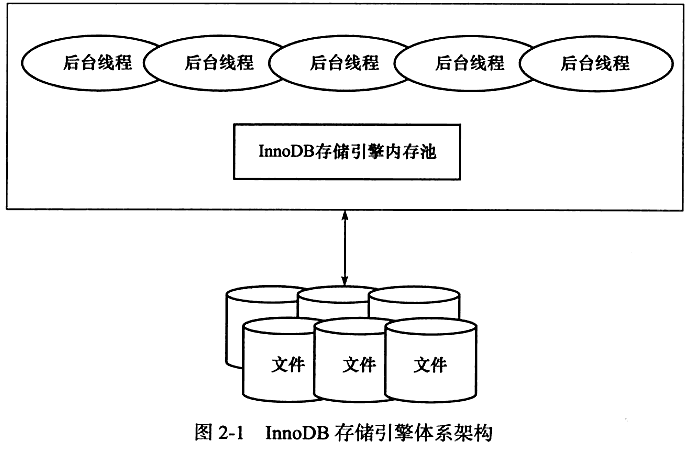
InnoDB存储引擎有多个内存块,可以认为这些内存块组成了一个大的内存池,负责如下工作:
- 维护所有进程/线程需要访问的多个内部数据结构
- 缓存磁盘上的数据,方便快速的读取,同时在对磁盘文件的数据修改之前在这里缓存。
- 重做日志(redo log)缓冲
后台线程的主要作用
- 刷新内存池中的数据,保证缓冲池中的内存缓存是最新的数据
- 将已经修改的数据文件刷新到磁盘文件,同时保障在数据库发生异常的情况下InnoDB能恢复到正常运行状态。
后台线程
Master Thread
核心线程,主要负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性,包括脏页的刷新,合并插入缓冲,UNDO页的回收等。
IO Thread
- 在INNODB存储引擎中大量使用了AIO(Async IO)来处理写IO请求,这样可以极大提高数据库的性能。
- 有四种IO Thread 分别是(1.0.x开始):
- wrtie thread:4个
- read thread:4个
- insert buffer thread:1个
- buffer log IO:1个
- 可以使用innodb_read_io_threads 和 innodb_write_io_threads参数进行设置。
- 读线程一定小于写线程
# INNODB版本查询
SHOW VARIABLES LIKE 'INNODB_VERSION'\G; # INNODB THREAD 数量查询
SHOW VARIABLES LIKE 'innodb_%io_threads'\G; # 查询IO THREAD
SHOW ENGINE INNODB STATUS\G;
Purge Thread
事务被提交后,其所使用的undolog可能不再需要,因此需要PurgeThread来回收已经使用并分配的undo页。从INNODB 1.1版本开始,可以将purge操作从MASTER THREAD中抽离出来,来减轻MASTER THEAD的工作。使用配置开始
[mysqld]
innodb_purge_threads=1
从INNODB 1.2版本开始,可以支持多个purge Thread,这样做的目的是为了进行加快undo页的回收。例如可以设置4个
SELECT VERSION() \G;
SHOW VARIABLES LIKE 'innodb_purge_threads'\G;
Page Cleaner Thread
是在INNODB 1.2.x版本中引入的。起作用是将之前版本中脏页的刷新操作都放入到单独的线程中来完成。其目的是为简称MASTER THREAD的工作以及对用于查询线程的堵塞,进一步提高性能。
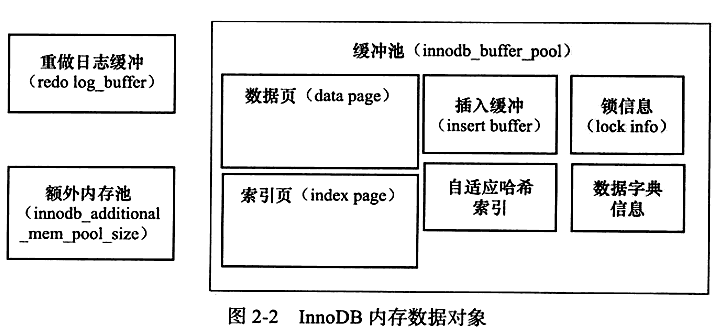
内存
缓冲池
InnoDB存储引擎是在磁盘按照页的方式进行管理,是基于磁盘的数据库系统。需要使用缓冲池技术提高数据库的整体性能。
缓冲池就是一块内存区域,读取先再缓存找,找不到去磁盘加载。写入的是后续通过Checkpoint的机制刷新回磁盘。
SHOW VARIABLES LIKE 'innodb_buffer_pool_size'\G;
从1.0.X版本开始,允许有多个缓冲池实例。每个页根据哈希值平均分配到不同缓冲池实例中。好处是减少数据库内部的资源竞争,增加数据库的并发处理能力。
## 查询缓冲池信息、状态
SHOW VARIABLES LIKE 'innodb_buffer_pool_instances'\G; SHOW ENGINE INNODB STATUS\G; SELECT POOL_ID, POOL_SIZE, FREE_BUFFERS, DATABASES_PAGES
FROM INNODB_BUFFER_POOL_STATUS\G;
INNODB内存管理模式——LRU List、Free List(空闲页列表) 和 Flush List(脏页列表)
InnoDB存储引擎使用LRU算法进行内存管理,不同的是,他最新读取的页不是放在列表的首部,而是放在midpoint的位置。midpoint位置可由参数
innodb_old_blocks_pct控制,例如SHOW VARIABLES LIKE 'innodb_old_blocks_pct'\G;
为什么不是用最基础的LRU算法呢?这是因为某些SQL(例如索引或者数据的扫描操作)可能会将缓冲池中的页被刷新出,影响缓冲池的效率。但是这类SQL的数据使用的页并不是活跃数据。
为了更进一步优化这个问题,引入一个新的参数
innodb_old_blocks_time,表示页读取到mid位置后需要等待多久才会被加入到LRU列表的热端。所以在执行上述类型的SQL时候,可以先设置这个参数保证原来的LRU列表热点数据不被刷出。SET GLOBAL innodb_old_blocks_time = 1000; # 一些操作
..... SET GLOBAL innodb_old_blocks_time = 0;
如果用户预估自己热点数据不止63%,可以在执行SQL前改变
innodb_old_blocks_pct参数SET GLOBAL innodb_old_blocks_pct=20;
InnoDB开始启动时,LRU加载过程:
- 数据库刚启动时,LRU列表是空的,即没有任何的页。所有页都放在Free列表中。
- 当需要从缓冲池分页时,首先从Free列表中查找是否有可用的空闲页,若有则将该页从Free列表中删除,放入到LRU列表中。
- 页从LRU列表的old部分加入到new部分时,称此时发生的操作为page made young
- 因为
innodb_old_blocks_time的设置而导致页没有从old部分移动到new部分的操作称为page not made young。 - 通过命令SHOW ENGINE INNODB STATUS观察LRU列表以及FREE列表的使用情况和运行状态。
SHOW ENGINE INNODB STATUS\G

# INNODB1.2版本开始,还可以通过表INNODB_BUFFER_POOL_STATUS来观察缓冲池的运行状态
SELECT POOL_ID, HIT_RATE, PAGES_MADE_YOUNG, PAGES_NOT_MADE_YOUNG
FROM information_schema.INNODB_BUFFER_POOL_STATUS\G;

# 通过表INNODB_BUFFER_PAGE_LRU来观察每个LRU列表中每个页的具体信息
SELECT TABLE_NAME, SPACE, PAGE_NUMBER, PAGE_TYPE
FROM INNODB_BUFFER_PAGE_LRU WHERE SPACE = 1;

INNODB存储引擎从1.0.X版本开始支持压缩页的功能,即将原来16KB的页压缩为1KB、2KB、4KB和8KB。由于页的大小发生了变化,所以LRU列表也有了些许的变化,对于非16KB的页,是通过unzip_LRU列表进行管理的。通过命令观察得到:
SHOW ENGINE INNODB STATUS\G;

这里需要注意的是LRU列表长度包括unzip_LRU列表长度。
unzip_LRU是怎样从缓冲池中分配内存的呢?
首先,在unzip_LRU列表中对不同压缩页大小的页进行分别管理。其次通过伙伴算法进行内存的分配。来如对需要从缓冲池中申请页为4KB的大小的过程如下:
- 检查4KB的unzip_LRU的列表,检查是否有可用的空闲页;
- 若有,则直接使用
- 否则,检查8KB的unzip_LRU列表
- 若能够得到空闲页,将页分成2个4KB的页,存放到4KB的unzip_LRU列表汇总;
- 若不能得到空闲页,从LRU列表中申请一个16KB的页,分为1个8K的页还有2个4KB的页,分别存放到对应的unzip_LRU列表中。
# 观察unzip_LRU列表中的页
SELECT
TABLE_NAME, SPACE, PAGE_NUMBER, COMPERSSID_SIZE
FROM INNODB_BUFFER_PAGE_LRU
WHERE COMPRESSED_SIZE <> 0;
在LRU列表中的页被修改后,该页成为脏页,即缓冲池中的页和磁盘上的页的数据产生了不一致。这时数据库会通过CHECKPOINT机制将脏页刷新会磁盘。
Flush列表中的页即为脏页列表。
脏页既存在于LRU列表中,也存在与Flush列表中。LRU列表用来管理缓冲池中的页的可用性,Flush列表用来管理将页刷新回磁盘,二者互不影响。
# modified db pages显示脏页的数量
SHOW ENGINE INNODB STATUS # 可以通过源数据库表INNODB_BUFFER_PAGE_LRU来查看
SELECT TABLE_NAME, SPACE, PAGE_NUMBER, PAGE_TYPE
FROM INNODB_BUFFER_PAGE_LRU
WHERE OLDEST_MODIFICATION > 0;
重做日志缓冲
INNODB存储引擎首先将重做日志信息放在这个缓冲区中,然后按照一定的频率刷新到重做日志文件。一般不用设置的很大。因为刷新速度很快。可通过
innodb_log_buffer_size控制,默认8MBSHOW VARIABLES LIKE 'innodb_log_buffer_size'\G;
刷新到磁盘的策略
- MASTER THREAD每一秒将重做日志缓冲刷新到重做日志文件中
- 每个事务提交时会将重做日志缓冲刷新到重做日志文件中
- 当重做日志缓冲池剩余空间小于一半时,重做日志缓冲刷新到重做日志文件中。
额外的内存池
在INNODB存储引擎中,对内存的管理是通过一种称为内存堆(heap)的方式进行的。在对一些数据结构本身的内存进行分配时,需要从额外的内存池中进行申请,当该区域的内存不够时,也会从缓冲池中进行申请。所以在申请了很大的INNODB缓冲池时,也要相应增加这个数值。
Checkpoint技术
一条DML语句会使得产生脏页(内存的数据比磁盘新),那就需要刷新到磁盘中。基本上是采用Write Ahead Log策略。即当事务提交时,先写重做日志,再修改页。当由于发生宕机而导致数据丢失时,通过重做日志来完成数据的恢复。
而Checkpoint技术是为了解决这个过程的痛点:
缩短数据库恢复的时间
由于checkpoint之前的数据都刷回去磁盘了,所以只需要对checkpoint后的重做日志进行恢复。大大缩短了恢复时间。
缓冲池不够用时,将脏页刷新到磁盘
LRU算法会溢出最近最少使用的页,如果是脏页,强制Checkpoint。
重做日志不可用时,刷新脏页。
重做日志的空间是循环使用的,当要被重用的时候,被重用的部分必须进行checkpoint。
在InnoDB存储引擎中,通过LSN(Log Sequence Number)来标记版本的。LSN是8字节的数字。每个页、重做日志、Checkpoint都有LSN。可以通过命令来查看
SHOW ENGINE INNODB STATUS\G;
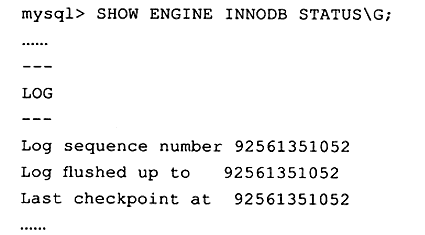
在InnoDB存储引擎内部,有两种Checkpoint,分别为:
Sharp Checkpoint
是在数据库关闭时刷新全部脏页到磁盘。参数是
innodb_fast_shutdown=1Fuzzy Checkpoint
运行时使用,指刷新一部分脏页。
Master Thread Checkpoint 每秒或者每十秒刷新从缓冲池的脏页列表中刷新一定比例的页回磁盘。
FLUSH_LRU_LIST Checkpoint 是因为InnoDB存储引擎需要保障LRU列表中需要有足够多的空闲页可使用。
在InnoDB 1.1.x版本之前,检查LRU列表空间是否足够是在用户查询线程中,会堵塞用户的查询操作。而且如果查询空间不足,会将尾端的页移除,如果有脏页就进行Checkpoint。
在InnoDB1.2.x版本开始,这个操作会放在Page Cleaner 线程中进行。
可以通过参数进行设置预留的空间大小,设置LRU列表需要保留多少个空闲页的空间
SHOW VARIABLES LIKE 'innodb_lru_sacn_depth'\G;
Async/Sync Flush Checkpoint 是指重做日志文件不可用(空间快用完了)的情况,这时需要强制将一些页刷新会磁盘,而此时脏页是从脏页列表中选取的。
在INNODB1.2.x版本后,放入到了单独的page Cleaner Thread中。可以通过命令来观察状态
SHOW ENGINE INNODB STATUS\G;
Dirty Page too much Checkpoint
脏页的数量太多,导致InnoDB强制进行CheckPoint。可以由参数来配置,表示缓冲中脏页的数量占据百分比为多少后,进行脏页的刷新。
SHOW VARIABLES LIKE 'innodb_max_dirty_pages_pct'\G;
Master Thread 工作方式
InnoDB 1.0.x版本之前的Master Thread
Master Thread具有最高的线程优先级别,内部由多个循环(loop)组成,会根据运行状态在不同的循环中切换。
- 主循环
loop - 后台循环
backgroup loop - 刷新循环
flush loop - 暂停循环
suspend loop
主循环
包括每秒操作和每十秒操作。
每秒操作包括:
日志缓冲刷新到磁盘,即使这个事务还没提交(总是)
合并插入缓冲(可能)
判断前一秒发生IO次数是否小于5次,才会执行
至多刷新100个InnoDB的缓冲池中的脏页到磁盘(可能)
// 当前脏页比例
if buf_get_modified_ratio_pct> innodb_max_drity_pages_pct
then
刷新100个脏页到磁盘
如果当前没有用户活动,则切换到background loop(可能)
每十秒操作包括:
- 刷新100个脏页到磁盘(可能的情况下)
- 合并至多5个插入缓冲(总是)
- 将日志缓冲刷新到磁盘(总是)
- 删除无用的Undo页(总是)
- 刷新100个或者10个脏页到磁盘(总是)
background loop
以上的操作,都是基于过去10秒内IO次数小于200才会进行。
当前没有用户活动或者数据库关闭,就会切换到background loop循环
- 删除无用的Undo页(总是)
- 合并20个插入缓冲(总是)
- 跳回到主循环(总是)
- 不断刷新100个页知道符合条件(可能,跳转到flush loop中完成)
suspend_loop
如果flush loop事情完成了,就会切到suspend_loop,将master_thread挂起,等待事件发生
InnoDB 1.2.x版本之前的Master Thread
可以看出之前版本的代码,做了很多的硬编码,很大程度上限制了InnoDB存储引擎对IO的性能(SSD盘使用后)。所以有时候数量上去后,其实是代码中未充分使用资源,导致性能瓶颈。所以抽出参数供用户来设置调节。
- 参数:innodb_io_capacity,用来表示磁盘IO的吞吐量,默认值为200.
- 在合并插入缓冲时,合并插入缓冲的数量为Innodb_io_capacity值的5%;
- 在从缓冲区刷新脏页时,刷新脏页的数量innodb_ip_capacity。
- 参数:innodb_adaptive_flushing ,自适应刷新,影响每秒刷新脏页的数量
原来的规则是:脏页在缓冲池所占的比例小于innodb_max_dirty_pages_pct时,不刷新脏页,大于时,刷新100个脏页。
现在的规则是,引擎会通过一个名为buf_flush_get_desired_flush_rate的函数来获取刷新脏页合适的数量。粗略翻阅源代码后发现buf_flush_get_desired_flush_rate通过重做日志的产生速度来决定最合适的刷新脏页的数量。
- 参数:innodb_purge_batch_size,该参数控制每次full purge回收的undo页的数量。
SHOW VARIABLES LIKE 'innodb_purge_batch_size'\G;
通过命令可以查看当前master thread的状态信息
SHOW ENGINE INNODB STATUS\G;
InnoDB1.2.x版本的Master Thread
对于脏页的刷新操作,分离到一个单独的Page Cleaner Thread,从而减轻了Master Thread的工作。进一步提升了系统的并发性。
InnoDB关键特性(放一下,感觉看后面,再看总结吧)
MySQL技术内幕读书笔记(二)——InnoDB存储引擎的更多相关文章
- MySQL技术内幕读书笔记(八)——事务
事务的实现 事务隔离性由锁来实现.原子性.一致性.持久性通过数据库的redo log和undo log来完成.redo log称为重做日志,用来保证事务的原子性和持久性.undo log用来保证事 ...
- MySQL技术内幕读书笔记(一)——Mysql体系结构和存储引擎
目录 MySQL体系结构和存储引擎 定义数据库和实例 MYSQL体系结构 MYSQL存储引擎 MySQL体系结构和存储引擎 定义数据库和实例 数据库:物理操作系统文件或者其他形式文件类型的结合.在MY ...
- MySQL技术内幕读书笔记(七)——锁
锁 锁是数据库系统区分与文件系统的一个关键特性.为了保证数据一致性,必须有锁的介入.数据库系统使用锁是为了支持对共享资源进行并发访问,提供数据的完整性和一致性. lock与latch 使用命令 ...
- MySQL技术内幕读书笔记(五)——索引与算法
索引与算法 INNODB存储引擎索引概述 INNODB存储引擎支持以下几种常见的索引: B+树索引 全文索引 哈希索引 InnoDB存储引擎支持的哈希索引是自适应的.会根据表的情况自动添加 ...
- MySQL技术内幕读书笔记(四)——表
目录 表 索引组织表 InnoDB逻辑存储结构 INNODB行记录格式 INNODB数据页结构 约束 视图 分区表 表 表就是关于特定实体的数据集合,是关系型数据库模型的核心. 索引组织表 在 ...
- MySQL技术内幕读书笔记(六)——索引与算法之全文索引
全文索引 概述 通过索引字段的前缀进行查找,B+树索引是支持的,利用B+树索引就可以进行快速查询. SELECT * FROM blog WHERE content like 'xxx%'; ...
- MySQL技术内幕读书笔记(三)——文件
目录 文件 参数文件 日志文件 套接字文件 pid文件 表结构定义文件 INNODB存储引擎文件 文件 有以下类型文件 参数文件:告诉MYSQL实例启动时在哪里找到数据库文件,并且制定某些初始化参 ...
- Struts2技术内幕 读书笔记二 web开发的基本模式
最佳实践 在讨论基本模式之前,我们先说说一个词:最佳实践 任何程序的编写都得遵循一个特定的规范.这种规范有约定俗称的例如:包名全小写,类名每个单词第一个字母大写等等等等;另外还有一些需要我们严格遵守的 ...
- 深入理解linux网络技术内幕读书笔记(二)--关键数据结构
Table of Contents 1 套接字缓冲区: sk_buff结构 1.1 网络选项及内核结构 1.2 结构说明及操作函数 2 net_device结构 2.1 MTU 2.2 结构说明及操作 ...
随机推荐
- execution(* com.sample.service.impl..*.*(..))
execution(* com.sample.service.impl..*.*(..)) 解释如下: 符号 含义 execution() 表达式的主体: 第一个”*“符号 表示返回值的类型任意: c ...
- TF之RNN:TensorBoard可视化之基于顺序的RNN回归案例实现蓝色正弦虚线预测红色余弦实线—Jason niu
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt BATCH_START = 0 TIME_STEP ...
- ecplise打不开提示Eclipse中...No java virtual machine was found...
解决办法: 在eclipse.ini文件中最前面添加这两行: -vm C:\Program Files\Java\jdk1.8.0_191\bin\javaw.exe 上面那个路径是你的java jd ...
- Linux发展历史
一.硬件与软件发展历史 计算机由硬件和软件组成结构 硬件 1946年诞生于宾夕法尼亚州,占地170平米,重量达到30吨,名字叫做ENIAC(electronic numerical integrato ...
- Codeforces Round #530 (Div. 2)
RANK :2252 题数 :3 补题: D - Sum in the tree 思路:贪心 把权值放在祖先节点上 ,预处理 每个节点保存 他与他儿子中 权值最小值即可. 最后会有一些叶子节点依旧为 ...
- async函数
async函数的实现原理,就是将Generator函数和自动执行器,包装在一个函数里.async函数返回Promise对象,async函数的return值是then方法的参数,await后跟Promi ...
- 大数据环境完全分布式搭建hbase-0.96.2-hadoop2
1.上传hbase安装包 2.解压 3.配置hbase集群,要修改3个文件 (首先zookeeper集群已经安装好了 并且启动 hadoop启动) 注意:要把hadoop的hdfs-site.xml和 ...
- 发布网站配置IIS(把网上找到的解决方法综合了一下)
1.由于权限不足而无法读取配置文件,无法访问请求的页面(参考网址:http://blog.csdn.net/yinjingjing198808/article/details/7185453) 2.处 ...
- BZOJ.4199.[NOI2015]品酒大会(后缀数组 单调栈)
BZOJ 洛谷 后缀自动机做法. 洛谷上SAM比SA慢...BZOJ SAM却能快近一倍... 显然只需要考虑极长的相同子串的贡献,然后求后缀和/后缀\(\max\)就可以了. 对于相同子串,我们能想 ...
- Shell脚本笔记(五)Shell函数
Shell函数 1.定义语法 标准写法: funciton funName () { order....... return n } 简化写法1: funciton funName { order.. ...