Mac下hadoop运行word count的坑
Mac下hadoop运行word count的坑
Word count体现了Map Reduce的经典思想,是分布式计算中中的hello world。然而博主很幸运地遇到了Mac下特有的问题Mkdirs failed to create,特此记录
一、代码
- WCMapper.java
package wordcount;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils;
import java.io.IOException;
/**
* 四个泛型中,前两个是指mapper输入的数据类型
* KEYIN是输入的key类型,VALUEIN是输入的value类型
* map和reduce的数据输入输出都是以key-value对的形式分装的
* 默认情况下,框架传递给我们的mapper的输入数据中
* key是要处理的文本中第一行的起始偏移量,value是这一行的内容
*
* Long->LongWritable实现hadoop自己的序列化接口,内容更精简,传输效率高
* String->Text
*/
public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
//mapreduce框架每一行数据就调用一次改方法
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 具体的业务逻辑就写在这个方法中,而且需要的处理的key-value已经传递进来
// 将这一行的内容转换成string
String line = value.toString();
// 切分单词
String[] words = StringUtils.split(line, ' ');
// 通过context把结果输出
for (String word: words){
context.write(new Text(word), new LongWritable(1));
}
}
}
- WCReducer.java
package wordcount;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
// 框架在map处理完成之后,将所有k-v对缓存起来
// 进行分组,然后传递一个组<key, values{}>
// 调用一次reduce方法
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count = 0;
// 遍历values,累加求和
for (LongWritable value: values){
count += value.get();
}
// 输出这一个单词的统计结果
context.write(key, new LongWritable(count));
}
}
- WCRunner.java(启动项)
package wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 用来描述一个特定的作业
* 比如,该作业使用哪个类作为逻辑处理的map,哪个作为reduce
* 还可以指定该作业要需要的数据所在的路径
* 还可以指定该作业输出的结果放到哪个路径
*/
public class WCRunner {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 设置整个job需要的jar包
// 通过WCRuner来找到其他依赖WCMapper和WCReducer
job.setJarByClass(WCRunner.class);
// 本job使用的mapper和reducer类
job.setMapperClass(WCMapper.class);
job.setReducerClass(WCReducer.class);
// 指定reducer的输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 指定mapper的输出kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 指定原始数据存放在哪里
FileInputFormat.setInputPaths(job,new Path("/wc/input/"));
// 指定处理结果的输出数据存放在哪里
FileOutputFormat.setOutputPath(job, new Path("/wc/output/"));
// 将job提交运行
job.waitForCompletion(true);
}
}
二、问题重现
写好代码后打包成jar,博主是用IDEA直接图形化操作的,然后提交到hadoop上运行
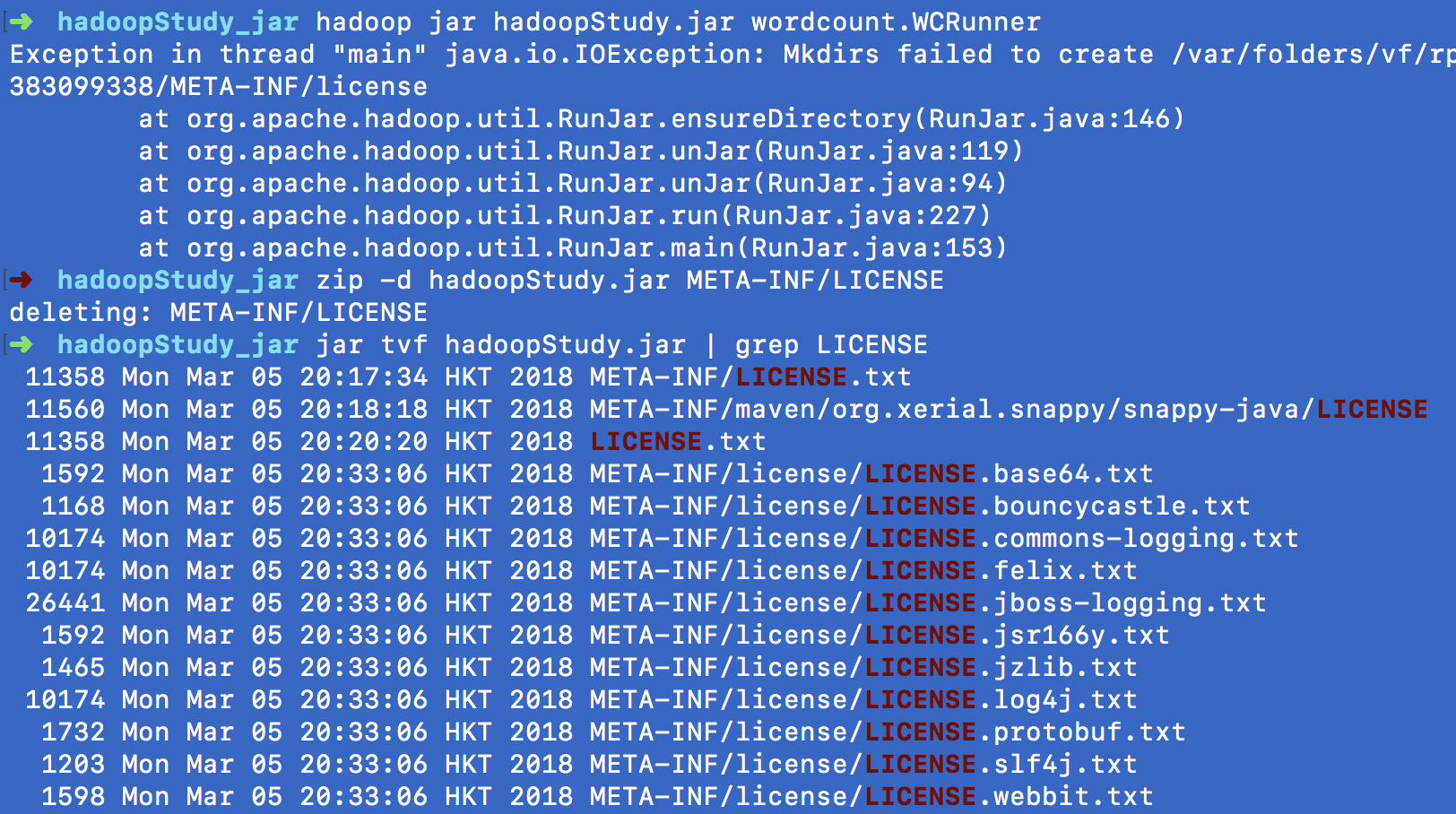
hadoop jar hadoopStudy.jar wordcount.WCRunner
结果未像官网和其他很多教程中说的那样出结果,而是报错
Exception in thread "main" java.io.IOException: Mkdirs failed to create /var/folders/vf/rplr8k812fj018q5lxcb5k940000gn/T/hadoop-unjar1598612687383099338/META-INF/license
at org.apache.hadoop.util.RunJar.ensureDirectory(RunJar.java:146)
at org.apache.hadoop.util.RunJar.unJar(RunJar.java:119)
at org.apache.hadoop.util.RunJar.unJar(RunJar.java:94)
at org.apache.hadoop.util.RunJar.run(RunJar.java:227)
at org.apache.hadoop.util.RunJar.main(RunJar.java:153)
最后折腾了半天,发现是Mac的问题,在stackoverflow中找到解释
The issue is that a /tmp/hadoop-xxx/xxx/LICENSE file and a
/tmp/hadoop-xxx/xxx/license directory are being created on a
case-insensitive file system when unjarring the mahout jobs.
删除原来压缩包的META-INF/LICENS,再重新压缩,解决问题~
zip -d hadoopStudy.jar META-INF/LICENSE
jar tvf hadoopStudy.jar | grep LICENSE
然后把新的jar上传到hadoop上运行
hadoop jar hadoopStudy.jar wordcount.WCRunner
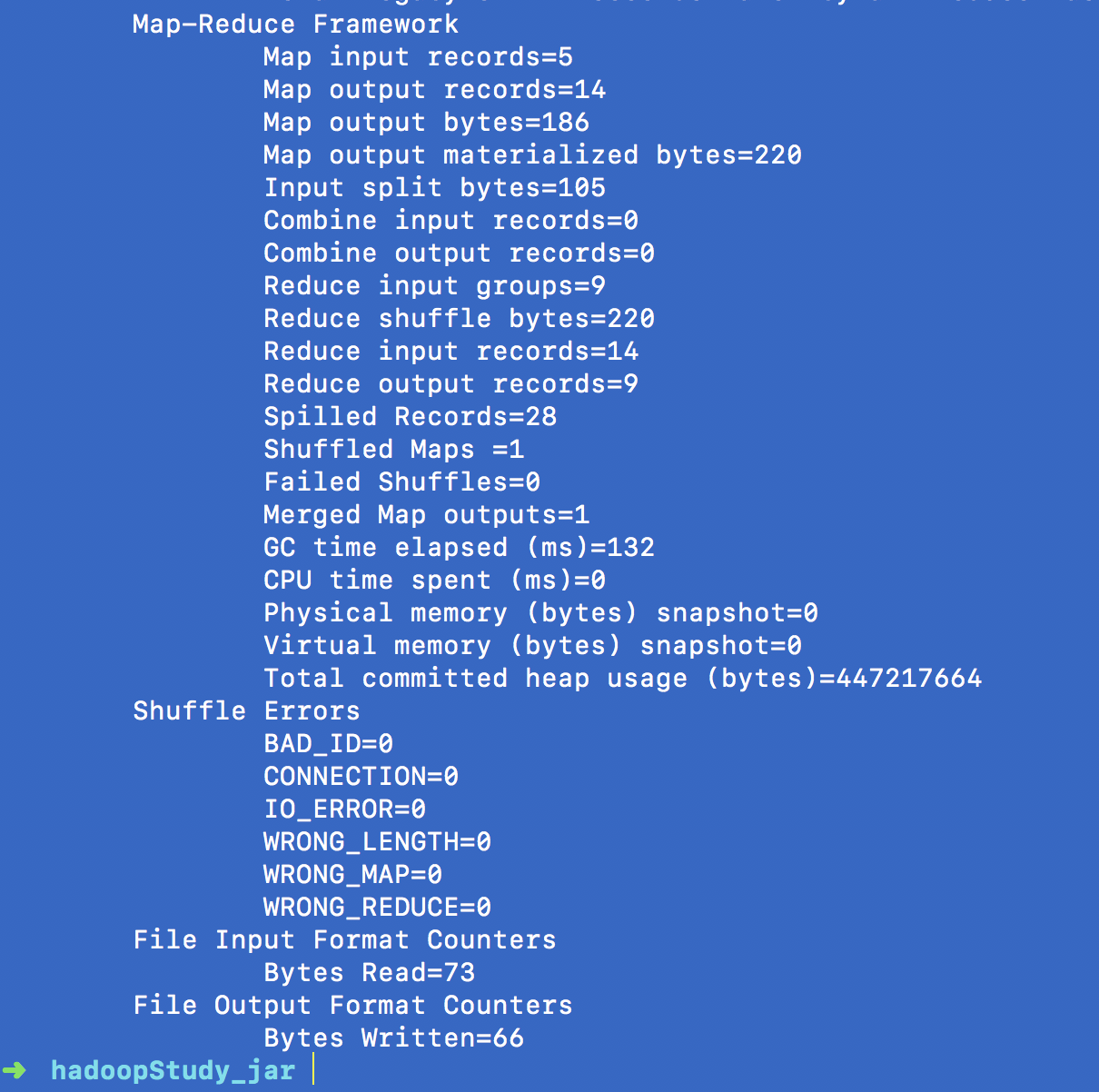
bingo!
三、运行结果
顺便用浏览器看一下运行结果
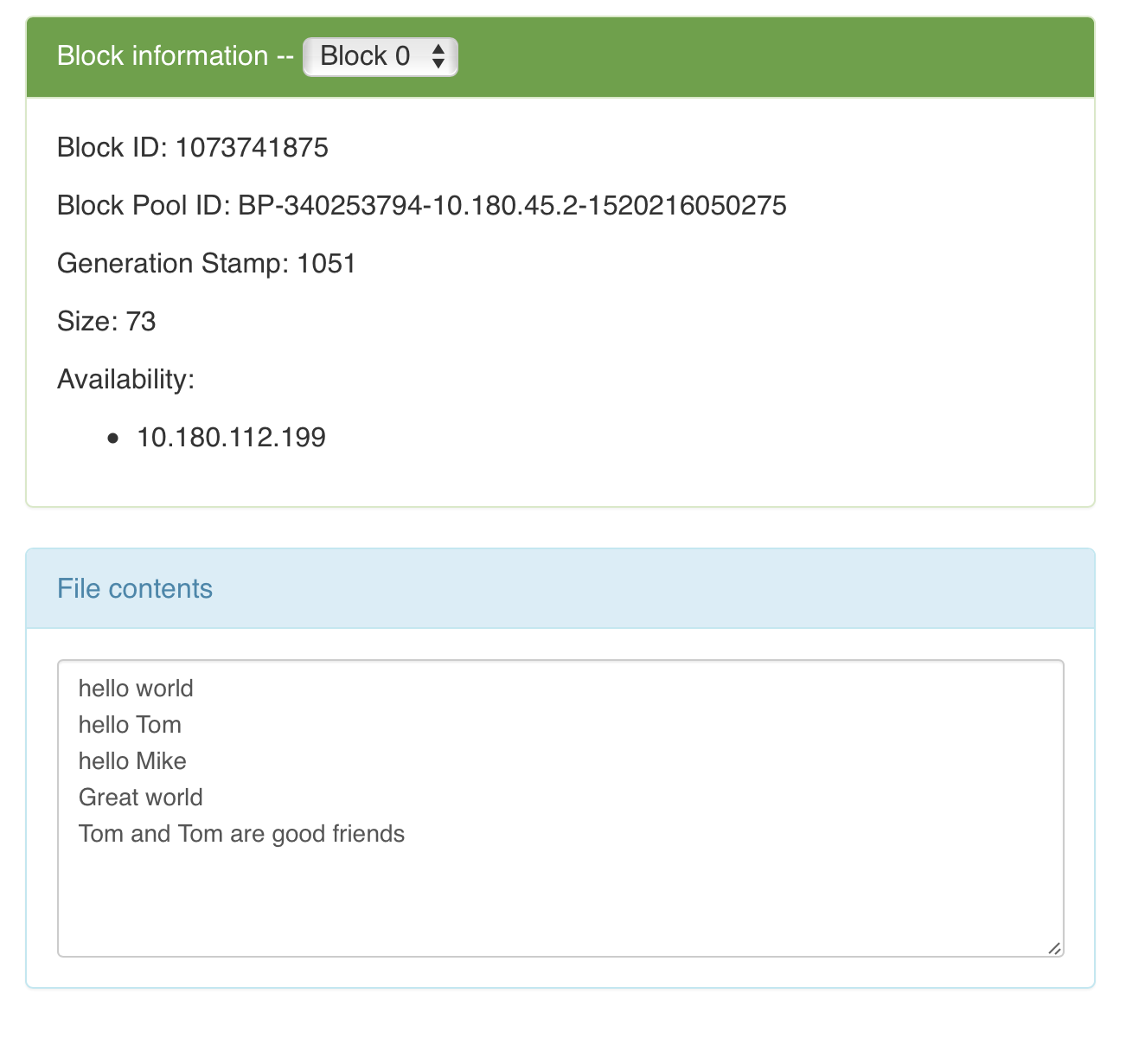
- 输入文件
wc/input/input.txt
- 输出文件
/wc/output/part-r-00000]
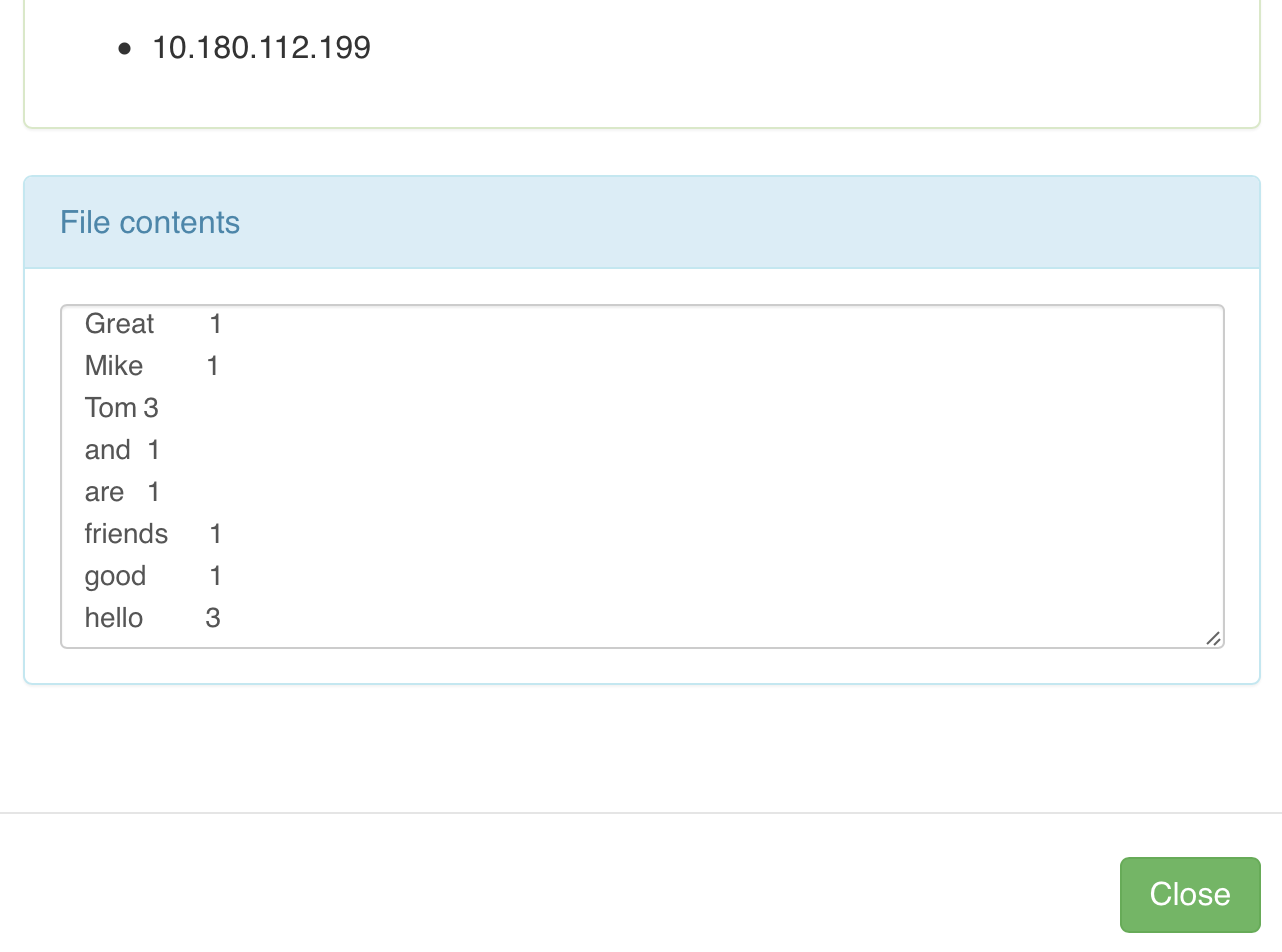
运行结果显然是正确的,再也不敢随便说Mac大法好了……
Mac下hadoop运行word count的坑的更多相关文章
- Mac 下安装运行Rocket.chat
最近花了一周的时间,复习了HTML.CSS.原生JS,并学习了Node.js.CoffeeScript.js.MongoDB,入了下门. 因为准备在Rocket.chat 上做二次开发,所以先下载和安 ...
- mac上eclipse上运行word count
1.打开eclipse之后,建立wordcount项目 package wordcount; import java.io.IOException; import java.util.StringTo ...
- Hadoop AWS Word Count 样例
在AWS里用Elastic Map Reduce 开一个Cluster 然后登陆master node并编译下面程序: import java.io.IOException; import java. ...
- mac 下php运行bug
如下所说bug在window下没有,在mac下存在. mac下的php报如下错误: fopen("data.json") Error: failed to open stream: ...
- [MapReduce_1] 运行 Word Count 示例程序
0. 说明 MapReduce 实现 Word Count 示意图 && Word Count 代码编写 1. MapReduce 实现 Word Count 示意图 1. Map:预 ...
- CentOS下Hadoop运行环境搭建
1.安装ssh免密登录 命令:ssh-keygen overwrite(覆盖写入)输入y 一路回车 将生成的密钥发送到本机地址 ssh-copy-id localhost (若报错命令无法找到则需要安 ...
- openssl1.0在mac下的编译安装(踩坑精华)
之前做了一次brew版本升级,然后用pip3安装的一个python命令就无法执行了(涉及到openssl库),执行就会报一个错误. ImportError: dlopen(/usr/local/Cel ...
- cgywin下 hadoop运行 问题
1 cgywin下安装hadoop需要配置JAVA_home变量 , 此时使用 window下安装的jdk就可以 ,但是安装路径不要带有空格.否则会不识别. 2 在Window下启动Hadoop ...
- Mac下怎么运行python3的py文件
我的Mac现在是10.14.6系统,默认自带的python版本是2.7.(怎么查看版本?打开终端,输入python即可看到版本号) 由于现在需要运行python3写的py文件,需要将自带的python ...
随机推荐
- weixinShare.js / 极简微信分享插件
weixinShare.js / 极简微信分享插件 / 版本:0.1 这是一个很简单.很实用的微信分享插件,无需jQuery,只需要在网页里加入一行JS代码,即可自动识别微信浏览器并启动微信分享的提示 ...
- Go语言之defer关键字
类似于java中的finally, 在函数返回来执行, 它用来保证函数一定会作一些事情. package main import "fmt" func main() { defer ...
- 一脸懵逼学习Hive(数据仓库基础构架)
Hive是什么?其体系结构简介*Hive的安装与管理*HiveQL数据类型,表以及表的操作*HiveQL查询数据***Hive的Java客户端** Hive的自定义函数UDF* 1:什么是Hive(一 ...
- [转]Maven与nexus关系
开始在使用Maven时,总是会听到nexus这个词,一会儿maven,一会儿nexus,当时很是困惑,nexus是什么呢,为什么它总是和maven一起被提到呢? 我们一步一步来了解吧. 一.了解Mav ...
- C# 文件拖放到此程序的操作
问题描述: 怎么写代码可以实现指定类型的文件通过鼠标拖放显示在程序的文本框中,如:选中3个文件(3个文件的格式有MP3和wma)拖到程序,程序的文本框显示这三个文件的路径...解决代码: thi ...
- Ubuntu16.04中nginx除80之外其他端口不能访问
不废话, 大多数都以为是ufw防火墙的问题. 但我的是因iptables防火墙, 坑死我了. 查了好多也没查到怎么在Ubuntu关闭iptables, 索性直接卸载 apt-get remove ip ...
- Codeforces 1071C Triple Flips 构造
原文链接 https://www.cnblogs.com/zhouzhendong/p/CF1071C.html 题目传送门 - CF1071C 题意 给定一个长度为 n 的 01 数列,限定你在 $ ...
- Java中字符串比较的问题
package com.hxl; import java.util.Scanner; public class Test { public static void main(String[] args ...
- mysql解决数据库死锁问题
为了保证数据的正确性,对数据库进行操作的时候都会进行上锁,也就是进行修改数据的时候同一时间只能有一个进程,当这个进程处理完了,释放锁了,其他进程才可以进行操作! 总是会碰见一些意外情况,导致数据库死锁 ...
- jquery开发插件提供的几种方法
http://caibaojian.com/jquery-extend-and-jquery-fn-extend.html