语义分割之Dual Attention Network for Scene Segmentation
Dual Attention Network for Scene Segmentation

在本文中,我们通过 基于自我约束机制捕获丰富的上下文依赖关系来解决场景分割任务。
与之前通过多尺度特征融合捕获上下文的工作不同,我们提出了一种双重注意网络(DANet)来自适应地集成局部特征及其全局依赖性。
具体来说,我们在传统的扩张FCN之上附加两种类型的注意力模块,它们分别对空间和通道维度中的语义相互依赖性进行建模。
- 位置力关注模块通过所有位置处的特征的加权和来选择性地聚合每个位置处的特征。无论距离如何,相似的特征都将彼此相关。
- 同时,通道注意力模块通过整合所有通道映射中的相关特征来选择性地强调相互依赖的信道映射。
我们将两个注意模块的输出相加以进一步改进特征表示,这有助于更精确的分割结果。
相关工作
场景分割是一个基本且具有挑战性的问题,其目标是将场景图像分割和解析到与语义类别相关联的不同图像区域,包括填充物(例如天空,道路,草地)和离散物体(例如人,汽车,自行车)。 该任务的研究可应用于潜在的应用,例如自动驾驶,机器人传感和图像编辑。 为了有效地完成场景分割任务,我们需要区分一些令人困惑的类别,并将不同外观的对象分解。 例如,“田地”和“草地”的区域通常是难以区分的,并且通常难以区分的“汽车”可能具有不同的尺度,遮挡和照明。 因此,有必要提高像素级识别特征表示的辨别能力。
- 一种方法是利用多标签文本融合。 例如,一些作品通过组合由不同的扩张卷积和池化操作生成的特征图来聚合多尺度上下文。
- 有些作品通过使用分解结构扩大核大小或在网络顶部引入有效编码层来捕获更丰富的全局通信信息。
- 此外,提出编码器 - 解码器结构来融合中级和高级语义特征。
虽然上下文融合有助于捕获不同比例的对象,但它无法利用全局视图中对象或东西之间的关系,这对于场景分割也是必不可少的。
另一种类型的方法使用递归神经网络来利用长程依赖性,从而提高分割精度。提出了基于2DLSTM网络的方法来捕获标签上复杂的空间依赖性。
工作[DAGRNN]使用有向无环图构建一个递归神经网络,以捕获局部特征上丰富的上下文依赖性。然而,这些方法使用递归神经网络隐含地捕捉全局关系,其有效性在很大程度上依赖于长期记忆的学习结果。
本文工作
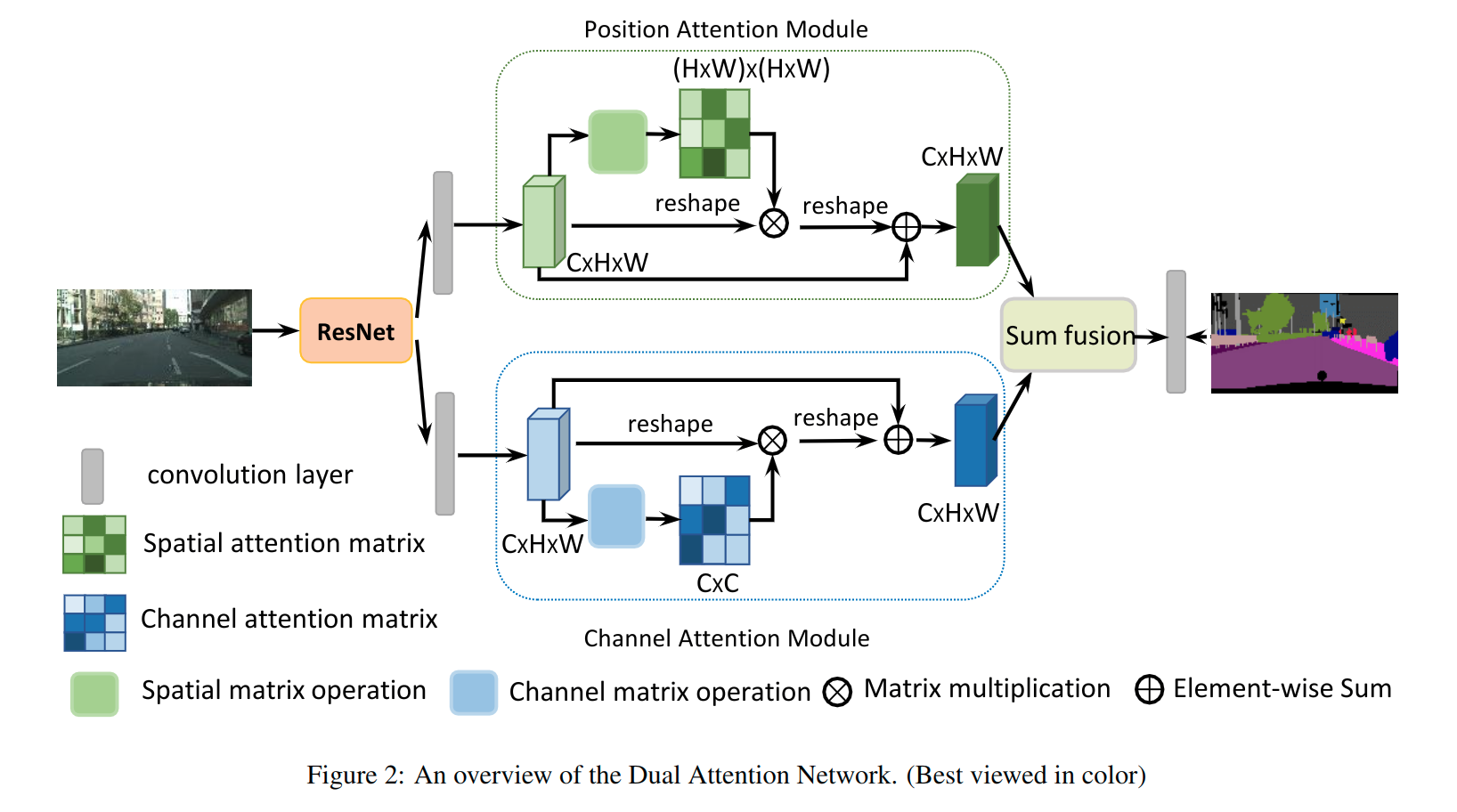
为了解决上述问题,在本文中,我们提出了一种新的框架,称为双注意网络(DANet),用于自然场景图像分割,如图所示。它引入了一种自注意力机制来分别捕捉空间和通道尺寸中的视觉特征依赖性。
具体来说,我们在传统的_扩张FCN_之上添加了两个并行的注意模块。一个是位置注意力模块(position attention module),另一个是通道注意模块(channel attention module)。
1、对于位置注意模块,我们引入自注意力制来捕获特征图的任意两个位置之间的空间依赖性。对于特定位置的特征,通过**加权累积的所有位置的特征来聚合更新特征 权重由相应两个位置之间的特征相似性决定。也就是说,任何具有相似特征的两个位置都可以贡献出改进,无论它们在空间维度上的距离如何。
2、对于通道注意力模块,我们使用相似的自注意力机制来捕获任意两个通道映射之间的通道依赖关系,并 使用所有通道映射的加权和来更新每个通道映射。
最后,这两个注意模块的输出被融合以进一步增强特征表示。

值得注意的是,在处理复杂多样的场景时,我们的方法比以前的方法[Rethinking atrous convolution for semantic image segmentation, PSPNet]更有效,更灵活。走图中的街景。以图1为例。
1、首先,第一行中的一些“人”和“交通信号灯”因为光照和视角, 是不显眼或不完整的物体。
2、如果探索简单的上下文嵌入,来自主导的显着对象(例如汽车,建筑物)的上下文将损害那些不显眼的对象标记。
3、相比之下,我们的注意模型选择性地聚合不显眼对象的相似特征,以突出其特征表示,并避免显着对象的影响。
4、其次,“汽车”和“人”的尺度是多样的,并且识别这种不同的对象需要不同尺度的背景信息。也就是说,应该平等对待不同尺度的特征以表示相同的语义。
5、我们的注意机制模型只是旨在从全局视角自适应地集成任何尺度的相似特征,这可以解决上述问题的程度。
6、第三,我们明确地考虑空间关系和通道关系,以便场景理解可以受益于远程依赖。
我们的主要贡献可归纳如下:
- 我们提出了一种具有自注意力机制的新型双重注意网络(DANet),以增强场景分割的特征表示的判别能力。
- 提出了一种位置注意力模块来学习特征的空间相互依赖性,并设计了一个通道注意力模块来模拟通道相互依赖性。 它通过在本地特征上建模丰富的上下文依赖性来显着改善分割结果。
- 我们在三个流行基准测试中获得了新的最新结果,包括Cityscapes数据集,PASCAL Context数据集和COCO Stuff数据集。
双注意力网络
- We employ a pretrained residual network with the dilated strategy as the backbone.
- Note that we** remove the downsampling operations and employ dilation convolutions in the last two ResNet blocks**, thus enlarging the size of the final feature map size to 1/8 of the input image. This retains more details without adding extra parameters.
- Then the features from the dilated residual network would be fed into two parallel attention modules.
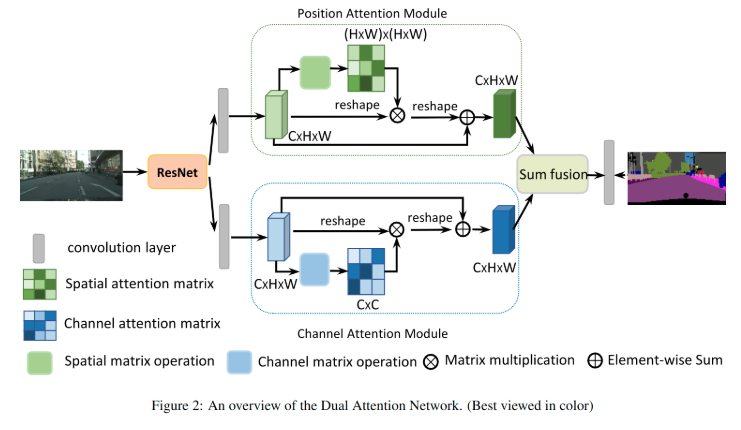 1、Dilated ResNet
1、Dilated ResNet
2、A convolution layer: obtain the feature of dimension reduction => CxHxW
3、Position attention module: generate new features of spatial long-range contextual information:
4、The first step is to generate a spatial attention matrix which models the spatial relationship between any two pixels of the features.
5、Next, we perform a matrix multiplication between the attention matrix and the original features.
6、Third, we perform an element-wise sum operation on the above multiplied resulting matrix and original features to obtain the final representations reflecting long-range contexts.
7、Channel attention module: Meanwhile, channel long-range contextual information are captured by a channel attention module.
除了第一步之外,捕获通道关系的过程类似于位置注意力模块,其中在通道维度中计算通道注意力矩阵。最后,我们汇总了两个注意模块的输出特征,以获得更好的像素级预测特征表示。
Position Attention Module
对于场景理解, 判别特征表示是必不可少的,可以通过捕获远程上下文信息来获得。然而,许多作品表明传统FCN产生的局部特征表示可能导致objects和stuff的错误分类。
为了在局部特征表示之上建模丰富的上下文关系,我们引入了一个位置注意力模块。位置注意力模块将更广泛的上下文信息编码到局部特征中,从而增强其表示能力。
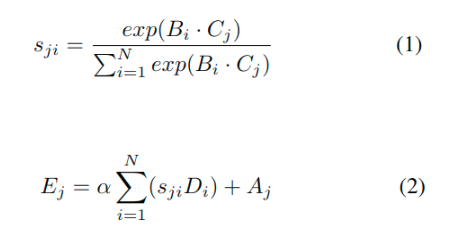
如图:
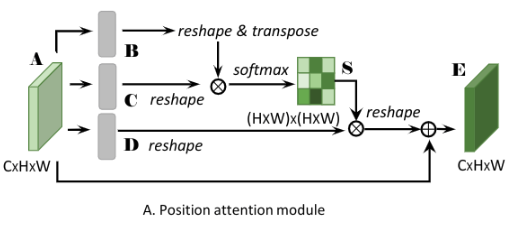
Important:
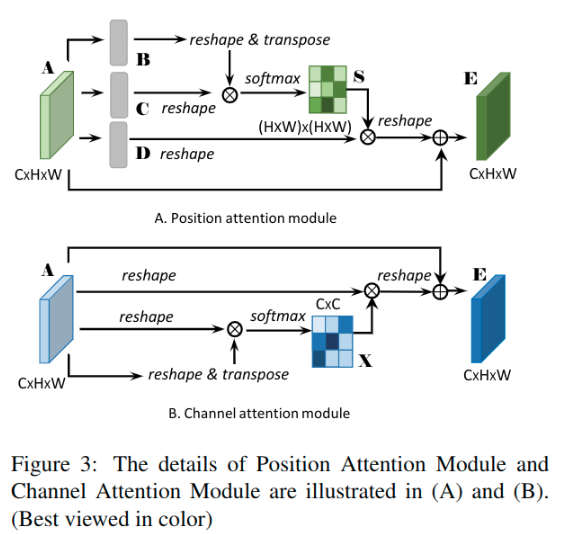
1、A为CxHxW => Conv+BN+ReLU => B, C 都为CxHxW
2、Reshape B, C to CxN (N=HxW)
3、Transpose B to B’
4、Softmax(Matmul(B’, C)) => spatial attention map S为NxN(HWxHW)
5、如上式1, 其中sji测量了第i个位置在第j位置上的影响
6、也就是第i个位置和第j个位置之间的关联程度/相关性, 越大越相似.
7、A => Covn+BN+ReLU => D 为CxHxW => reshape to CxN
8、Matmul(D, S’) => CxHxW, 这里设置为DS
9、Element-wise sum(scale parameter alpha * DS, A) => the final output E 为 CxHxW (式2)
10、alpha is initialized as 0 and gradually learn to assign more weight.
这样一来, 每个算出来的特征E的每个位置都是来自所有位置的特征和原始特征的加权和. 因此可以获得一个全局的上下文信息, 并且可以根据空间注意力图来有选择的集成上下文信息. 相似的特征会互相获得增益, 因此可以提升类间对比度和语义一致性.
利用矩阵乘法来实现对于全局上下文信息的利用与融合, 实际上和全连接是一样的. 全连接确实可以更为全面的利用所有位置的信息, 但是会破坏空间结构, 这也是相互矛盾的, 所以, 不能完全的利用全连接. 还得想办法保留更多的空间结构信息. 这里使用这个全连接的结果用在原始数据信息上, 互相利用, 互相促进.
Channel Attention Module
高级特征的每个通道映射可以被重新看作特定于类的响应,并且不同的语义响应彼此相关联。通过利用通道映射之间的相互依赖关系,我们可以强调相互依赖的特征映射,并改进特定语义的特征表示。因此,我们建立了一个通道注意力模块, 以显式的建模通道之间的相互依赖性。
结构如下:
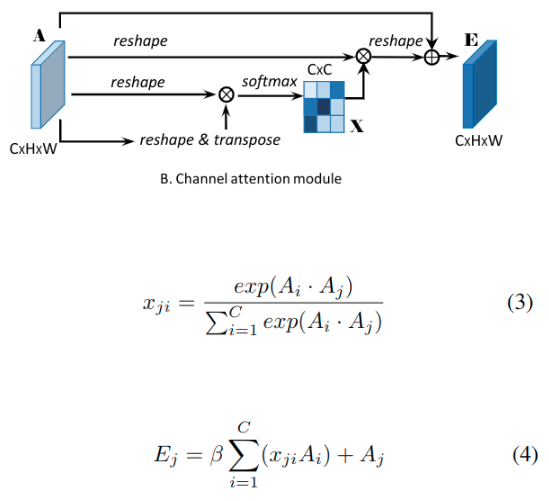
1、A(CxHxW) => 直接计算得到通道注意力图X(CxC)
2、Reshape(A) to CxN(N=HxW)
3、Softmax(Matmul(A, A’)(大小为CxC)) => channel attention map X(CxC), 这里使用公式3
4、xji测量在第j个通道上, 第i个通道的影响.(因为对于xji实际上就是使用A的j行和A’的i列(或者说是A的i行)的矢量乘积(坐标对应乘积之和))
5、Matmul(X’, A) => reshape to CxHxW
6、Element-wise sum(scale parameter beta * X, A)
7、beta从0开始逐渐学习.
公式4显示 每个通道的最终特征是所有通道和原始特征的特征的加权数据,其建模特征映射之间的远程语义依赖性。它 强调依赖于类的特征映射并有助于提高特征可辨性。
我们在计算两个通道的关系之前,我们不使用卷积层来嵌入特征,因为可以维持不同通道映射之间的关系。此外,与最近通过全局池化或者编码层探索通道关系的工作[26]不同,我们利用所有相应位置的空间信息来建通道相关性。
Attention Module Embedding with Networks
为了充分利用远程上下文信息的优势, 我们集成来自两个注意力模块的特征. 特别地, 我们通过一个卷积层和元素级加法来聚合两个注意力模块的输出, 以实现特征融合.
在最后紧跟着一个用来生成最终预测图的卷积层. 我们不采用级联操作, 因为它需要更多的 GPU 内存.
注意到我们的注意力模块很简单, 可以直接插入现有的 FCN流程中。 它们不会增加太多的参数, 却又能有效地增强特征表示。
双注意力模块参考代码
# https://github.com/junfu1115/DANet/blob/master/encoding/nn/attention.py ###########################################################################
# Created by: CASIA IVA
# Email: jliu@nlpr.ia.ac.cn
# Copyright (c) 2018
########################################################################### import numpy as np
import torch
import math
from torch.nn import (Module, Sequential, Conv2d, ReLU, AdaptiveMaxPool2d,
AdaptiveAvgPool2d, NLLLoss, BCELoss, CrossEntropyLoss,
AvgPool2d, MaxPool2d, Parameter, Linear, Sigmoid, Softmax,
Dropout, Embedding)
from torch.nn import functional as F
from torch.autograd import Variable class PAM_Module(Module):
""" Position attention module""" # Ref from SAGAN
def __init__(self, in_dim):
super(PAM_Module, self).__init__()
self.query_conv = Conv2d(in_channels=in_dim,
out_channels=in_dim // 8,
kernel_size=1)
self.key_conv = Conv2d(in_channels=in_dim,
out_channels=in_dim // 8,
kernel_size=1)
self.value_conv = Conv2d(in_channels=in_dim,
out_channels=in_dim,
kernel_size=1)
self.gamma = Parameter(torch.zeros(1)) self.softmax = Softmax(dim=-1) def forward(self, x):
"""
inputs :
x : input feature maps( N X C X H X W)
returns :
out : attention value + input feature
attention: N X (HxW) X (HxW)
"""
m_batchsize, C, height, width = x.size() # B => N, C, HW
proj_query = self.query_conv(x).view(m_batchsize, -1, width * height)
# B' => N, HW, C
proj_query = proj_query.permute(0, 2, 1) # C => N, C, HW
proj_key = self.key_conv(x).view(m_batchsize, -1, width * height) # B'xC => N, HW, HW
energy = torch.bmm(proj_query, proj_key)
# S = softmax(B'xC) => N, HW, HW
attention = self.softmax(energy) # D => N, C, HW
proj_value = self.value_conv(x).view(m_batchsize, -1, width * height) # DxS' => N, C, HW
out = torch.bmm(proj_value, attention.permute(0, 2, 1))
# N, C, H, W
out = out.view(m_batchsize, C, height, width) out = self.gamma * out + x
return out class CAM_Module(Module):
""" Channel attention module""" def __init__(self):
super(CAM_Module, self).__init__() self.gamma = Parameter(torch.zeros(1))
self.softmax = Softmax(dim=-1) def forward(self, x):
"""
inputs :
x : input feature maps( N X C X H X W)
returns :
out : attention value + input feature
attention: N X C X C
"""
m_batchsize, C, height, width = x.size()
proj_query = x.view(m_batchsize, C, -1)
proj_key = x.view(m_batchsize, C, -1).permute(0, 2, 1)
# N, C, C, bmm 批次矩阵乘法
energy = torch.bmm(proj_query, proj_key) # 这里实现了softmax用最后一维的最大值减去了原始数据, 获得了一个不是太大的值
# 沿着最后一维的C选择最大值, keepdim保证输出和输入形状一致, 除了指定的dim维度大小为1
energy_new = torch.max(energy, -1, keepdim=True)
energy_new = energy_new[0].expand_as(energy) # 复制的形式扩展到energy的尺寸
energy_new = energy_new - energy
attention = self.softmax(energy_new) proj_value = x.view(m_batchsize, C, -1) out = torch.bmm(attention, proj_value)
out = out.view(m_batchsize, C, height, width) out = self.gamma * out + x
return out if __name__ == '__main__':
module = CAM_Module()
in_data = torch.randint(0, 255, (2, 3, 7, 7), dtype=torch.float32)
print(module(in_data).size())
实验细节
- employ a poly learning rate policy (lr(1-iter/total_iter)^0,9)*
- momentum 0.9
- weight decay 0.0001
- Synchronized BN
- batchsize 8(cityscapes) or 16(other datasets)
- When adopting multi-scale augmentation, we set training time to 180 epochs for COCO Stuff and 240 epochs for other datasets
- Following [Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs], we also adopt auxiliary supervision on the top of two attention modules.
For data augmentation, we apply random cropping (crop-size 768) and random left-right flipping during training in the ablation study for Cityscapes datasets.
Ablation Study for Attention Modules
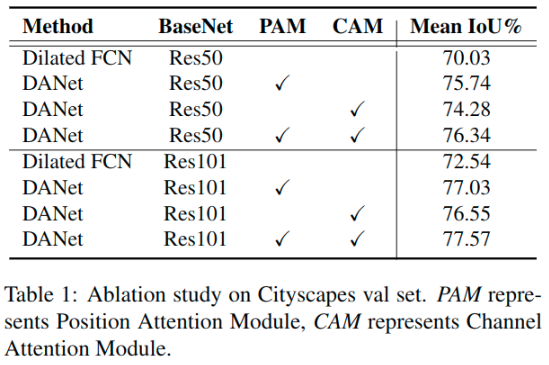

位置注意力模块的效果在图4中可视化, 一些细节和对象边界在使用位置注意力模块时更加清晰, 例如第一行中的 “杆子” 和第三行的 “人行道”。对局部特征的选择性融合增强了对细节的区分。
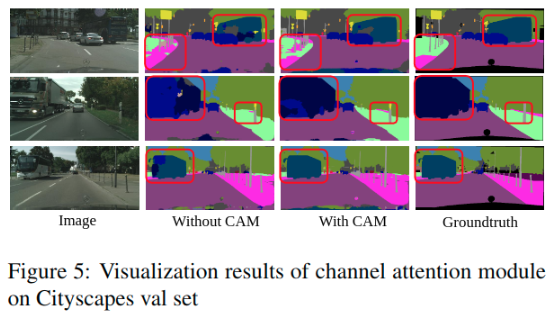
同时, 图5证明, 利用我们的信道注意模块, 一些错误分类的类别现在被正确地分类, 如第一行和第三行中的 “公交车”。 通道映射之间的选择性集成有助于捕获上下文信息。 语义一致性得到了明显的改善。
Ablation Study for Improvement Strategies
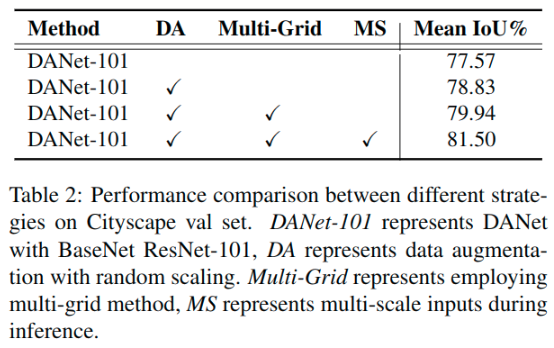
Following [Rethinking atrous convolution for semantic image segmentation], we adopt the same strategies to improve peformance further.
1、DA: Data augmentation with random scaling.
2、Multi-Grid: we apply employ a hierarchy of grids of different sizes (4,8,16) in the last ResNet block.
3、MS: We average the segmentation probability maps from 8 image scales {0.5 0.75 1 1.25 1.5 1.75 2 2.2} for inference.
Visualization of Attention Module

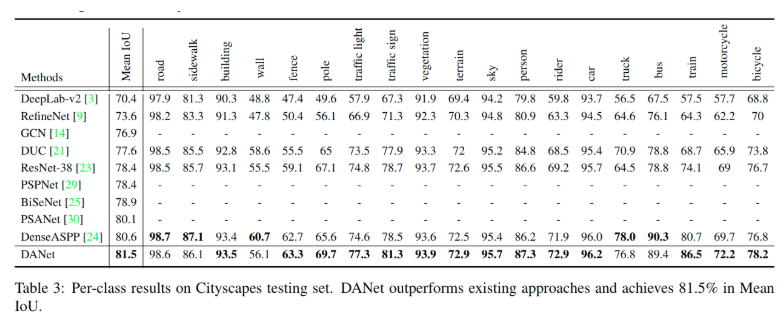
Comparing with State-of-the-art
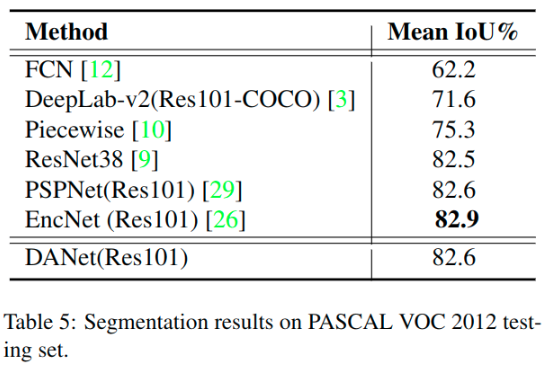
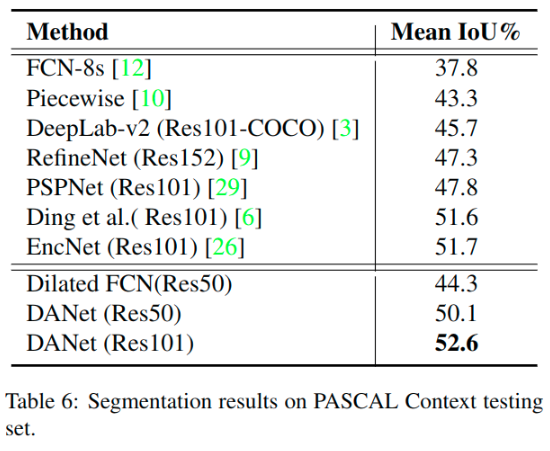
其他数据集的测试
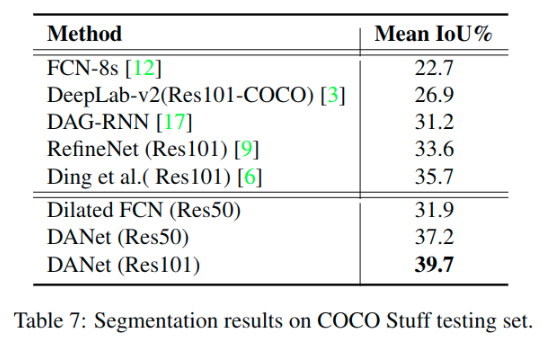
另外的一些想法
- 这里的双注意力模块如何更好的集成到现有的FCN结构上, 一定要放在最后预测之前么?
- 这里的实验中, 没有和现在最强的DeepLabV3+进行比较, 这一点有点可惜. 感觉还是超不过DeepLabV3+.
补充内容
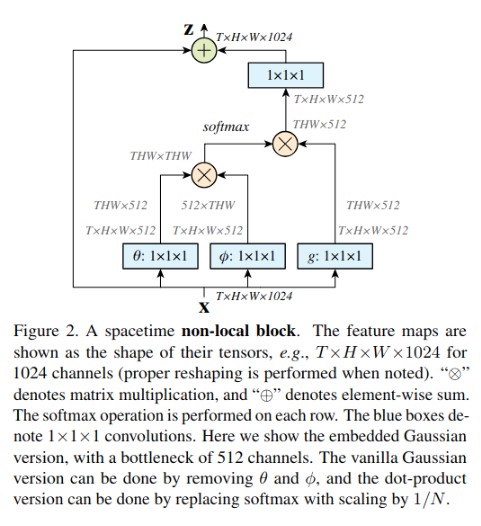
文中的注意力模块中的位置注意力模块, 基本上与何凯明的<X. Wang, R. Girshick, A. Gupta, and K. He. Non-Local
Neural Networks. In CVPR , 2018>提出的Non-Local结构是一致的.
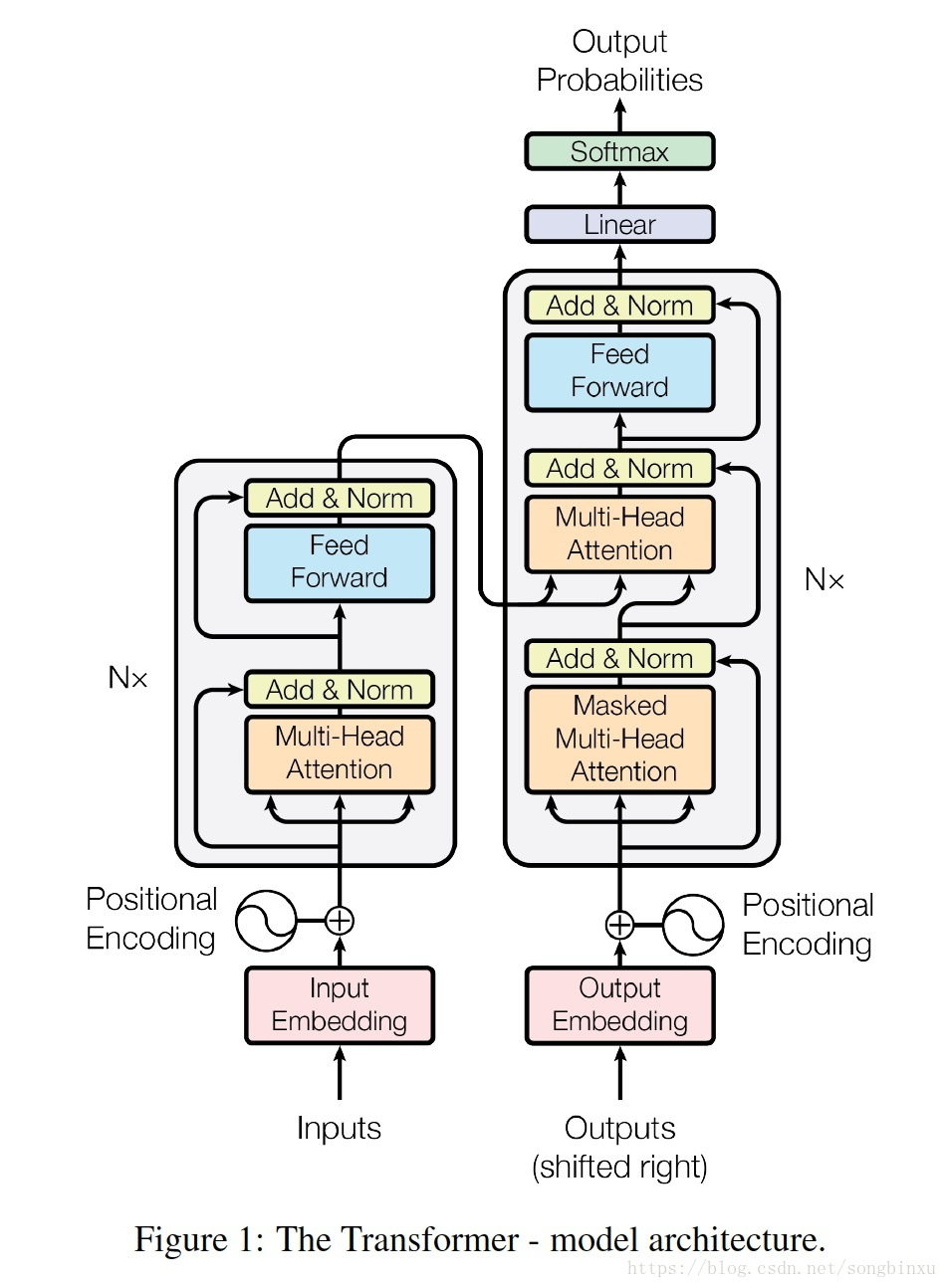
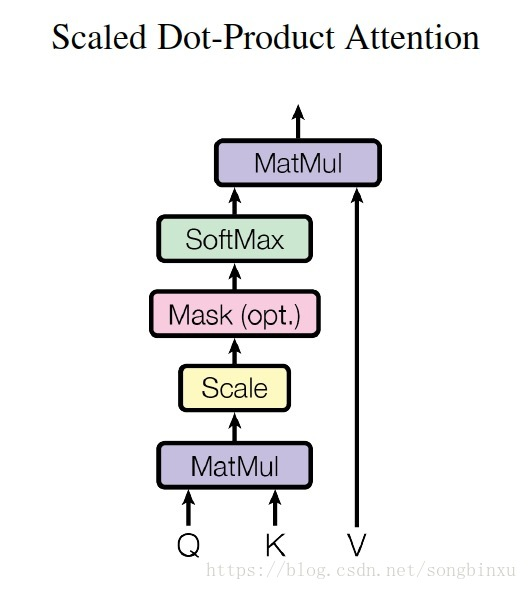
而该自注意力的思路主要来源于google的一份工作(Attention Is All You Need): https://arxiv.org/abs/1706.03762
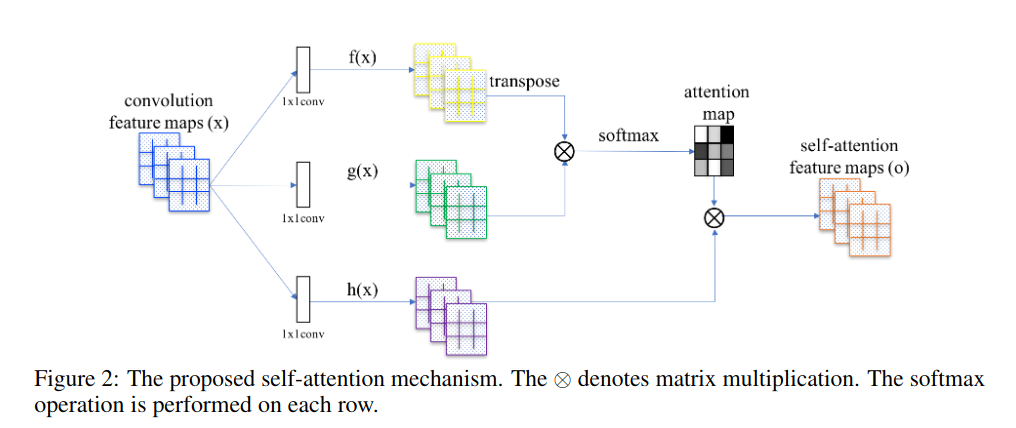
在Goodfellow的这篇文章中使用了 <H. Zhang, I. J. Goodfellow, D. N. Metaxas, and A. Odena. Self-attention generative adversarial networks. CoRR, abs/1805.08318, 2018> 类似的结构.https://arxiv.org/abs/1805.08318
语义分割之Dual Attention Network for Scene Segmentation的更多相关文章
- Dual Attention Network for Scene Segmentation
Dual Attention Network for Scene Segmentation 原始文档 https://www.yuque.com/lart/papers/onk4sn 在本文中,我们通 ...
- CVPR2020:4D点云语义分割网络(SpSequenceNet)
CVPR2020:4D点云语义分割网络(SpSequenceNet) SpSequenceNet: Semantic Segmentation Network on 4D Point Clouds 论 ...
- [论文][半监督语义分割]Semi-Supervised Semantic Segmentation with High- and Low-level Consistency
Semi-Supervised Semantic Segmentation with High- and Low-level Consistency TPAMI 2019 论文原文 code 创新点: ...
- Learning a Discriminative Feature Network for Semantic Segmentation(语义分割DFN,区别特征网络)
1.介绍 语义分割通常有两个问题:类内不一致性(同一物体分成两类)和类间不确定性(不同物体分成同一类).本文从宏观角度,认为语义分割不是标记像素而是标记一个整体,提出了两个结构解决这两个问题,平滑网络 ...
- 比较语义分割的几种结构:FCN,UNET,SegNet,PSPNet和Deeplab
简介 语义分割:给图像的每个像素点标注类别.通常认为这个类别与邻近像素类别有关,同时也和这个像素点归属的整体类别有关.利用图像分类的网络结构,可以利用不同层次的特征向量来满足判定需求.现有算法的主要区 ...
- 语义分割丨PSPNet源码解析「训练阶段」
引言 之前一段时间在参与语义分割的项目,最近有时间了,正好把这段时间的所学总结一下. 在代码上,语义分割的框架会比目标检测简单很多,但其中也涉及了很多细节.在这篇文章中,我以PSPNet为例,解读一下 ...
- 多篇开源CVPR 2020 语义分割论文
多篇开源CVPR 2020 语义分割论文 前言 1. DynamicRouting:针对语义分割的动态路径选择网络 Learning Dynamic Routing for Semantic Segm ...
- 基于YOLO和PSPNet的目标检测与语义分割系统(python)
基于YOLO和PSPNet的目标检测与语义分割系统 源代码地址 概述 这是我的本科毕业设计 它的主要功能是通过YOLOv5进行目标检测,并使用PSPNet进行语义分割. 本项目YOLOv5部分代码基于 ...
- 论文阅读(Weilin Huang——【TIP2016】Text-Attentional Convolutional Neural Network for Scene Text Detection)
Weilin Huang--[TIP2015]Text-Attentional Convolutional Neural Network for Scene Text Detection) 目录 作者 ...
随机推荐
- 软件工程 week 03
一.效能分析 1.作业地址:https://edu.cnblogs.com/campus/nenu/2016CS/homework/2139 2.git地址:https://git.coding.ne ...
- 2018.4.28 kvm虚拟机管理
创建虚拟机: virt-install --name wj-v1.4.1.0411 --vcpus=2 --memory=2048 --disk path=/home/wj/os/osgwV1.4.1 ...
- WIdo联网代码中文注释
代码如下 /*************************************************** 这是一个例子的dfrobot维多-无线集成物联网建兴传感器和控制节点 *产品页面及更 ...
- 学习笔记TF045:人工智能、深度学习、TensorFlow、比赛、公司
人工智能,用计算机实现人类智能.机器通过大量训练数据训练,程序不断自我学习.修正训练模型.模型本质,一堆参数,描述业务特点.机器学习和深度学习(结合深度神经网络). 传统计算机器下棋,贪婪算法,Alp ...
- Web前端入门教程之浏览器兼容问题及解决方法
JavaScript 被称为JS,是作为浏览器的内置脚本语言,为我们提供操控浏览器的能力,可以让网页呈现出各种特殊效果,为用户提供友好的互动体验.JS是Web前端入门教程中的重点和难点,而浏览器兼容性 ...
- git grep的一些用法
https://www.kernel.org/pub/software/scm/git/docs/git-grep.html 把所有本地分支包含某个字符的行列出来,把含有master的列出来 gi ...
- python 文件读写模式r,r+,w,w+,a,a+的区别(附代码示例)
如下表 模式 可做操作 若文件不存在 是否覆盖 r 只能读 报错 - r+ 可读可写 报错 是 w 只能写 创建 是 w+ 可读可写 创建 是 a 只能写 创建 否,追加写 a+ 可读可写 创建 ...
- linux怎么样显示命令历史后又显示命令的输入时间
linux的bash内部命令history就可以显示命令行的命令历史,默认环境执行 history命令后,通常只会显示已执行命令的序号和命令本身.如果想要查看命令历史的时间戳,那么可以执行: 临时显示 ...
- 在Tomcat7.0中设置默认服务器和不加端口名访问
前言 昨天买了域名,服务器,然后搭建了环境,然后想他通过默认的端口,不用端口就访问. 设置WEB项目的欢迎页 在WEB-INF文件夹下有个web.xml文件(最近新建的项目不包含此文件,可以手动新建) ...
- Vue的路由实现:hash模式 和 history模式
hash模式:在浏览器中符号“#”,#以及#后面的字符称之为hash,用 window.location.hash 读取.特点:hash虽然在URL中,但不被包括在HTTP请求中:用来指导浏览器动作, ...