Python 爬虫-正则表达式(补)
2017-08-08 18:37:29
一、Python中正则表达式使用原生字符串的几点说明
- 原生字符串和普通字符串的不同
相较于普通字符串,原生字符串中的\就是反斜杠,并不表达转义。不过,字符串转成正则表达式的时候会将其中的\理解为转义字符,这点需要注意。
- 为什么使用原生字符串
使用原生字符串是为了更好的表达正则表达式。若采用普通字符串,将会产生两次字符串的解释。
举两个例子:
(1)在正则表达式中匹配 \
使用普通字符串:"\\\\"->'\',原因是如果使用普通字符串,那么Python会将其中的\理解为转义字符,所以传给正则表达式的其实是“\\”,此时正则表达式也会将\理解为转义字符,所以讲“\\”理解为普通的\。
使用原生字符串:r“\\”->'\',原因是使用了原生字符串,简化了第一步的转义操作,所以给正则表达式的就是“\\”, 所以正则表达式会把其解释为\。
(2)在正则表达式中使用元字符\d
众所周知\d用来匹配一个数字字符,等价于 [0-9]。
使用普通字符串:“\\d”->\d",原因其实和刚才的是一样的,Python字符串解释的时候会将反斜杠理解为转义字符,所以提交给正则表达式的时候其实是‘\d’,这样就符合要求了。
使用原生字符串:r‘\d’->'\d',使用原生字符串的话,就直接是\d就可以了,这就体现出了使用原生字符串的优势。
通过查阅资料,使用原生字符串的时候,发现需要对一些特殊字符进行转义,需要转义的特殊字符有* . ? + $ ^ [ ] ( ) { } | \ /。
二、正则表达式详细的语法说明
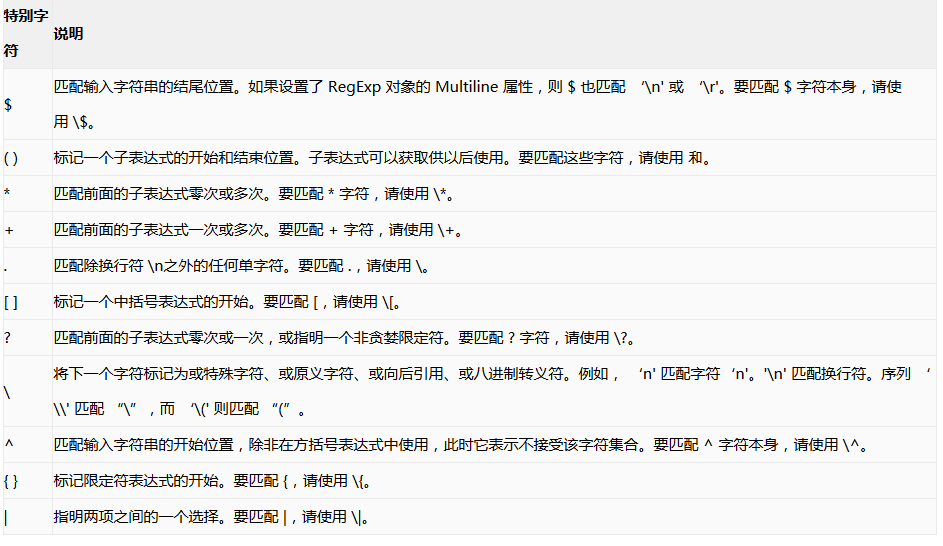






三、最小匹配问题
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。考虑这个表达式:a.*b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配。
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号?。这样.*?就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。现在看看懒惰版的例子吧:
a.*?b匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab(第一到第三个字符)和ab(第四到第五个字符)。
为什么第一个匹配是aab(第一到第三个字符)而不是ab(第二到第三个字符)?简单地说,因为正则表达式有另一条规则,比懒惰/贪婪规则的优先级更高:最先开始的匹配拥有最高的优先权——The match that begins earliest wins。
Python 爬虫-正则表达式(补)的更多相关文章
- Python爬虫 正则表达式
1.正则表达式概述 正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符.及这些特定字符的组合,组成一个"规则字符串",这个"规则字符串"用来 ...
- Python 爬虫-正则表达式
2017-07-27 13:52:08 一.正则表达式的概念 (1)正则表达式是用来简洁表达一组字符串的表达式,最主要应用在字符串匹配中. 正则表达式是用来简洁表达一组字符串的表达式 正则表达式是一 ...
- Python爬虫-正则表达式基础
import re #常规匹配 content = 'Hello 1234567 World_This is a Regex Demo' #result = re.match('^Hello\s\d\ ...
- python爬虫+正则表达式实例爬取豆瓣Top250的图片
直接上全部代码 新手上路代码风格可能不太好 import requests import re from fake_useragent import UserAgent #### 用来伪造爬头部信息 ...
- Python爬虫与数据分析之爬虫技能:urlib库、xpath选择器、正则表达式
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
- python爬虫之re正则表达式库
python爬虫之re正则表达式库 正则表达式是用来简洁表达一组字符串的表达式. 编译:将符合正则表达式语法的字符串转换成正则表达式特征 操作符 说明 实例 . 表示任何单个字符 [ ] 字符集,对单 ...
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
本次python爬虫百步百科,里面详细分析了爬虫的步骤,对每一步代码都有详细的注释说明,可通过本案例掌握python爬虫的特点: 1.爬虫调度入口(crawler_main.py) # coding: ...
- python爬虫数据解析之正则表达式
爬虫的一般分为四步,第二个步骤就是对爬取的数据进行解析. python爬虫一般使用三种解析方式,一正则表达式,二xpath,三BeautifulSoup. 这篇博客主要记录下正则表达式的使用. 正则表 ...
- Python爬虫入门之正则表达式
在前面我们已经搞定了怎样获取页面的内容,不过还差一步,这么多杂乱的代码夹杂文字我们怎样把它提取出来整理呢?下面就开始介绍一个十分强大的工具,正则表达式! 1.了解正则表达式 正则表达式是对字符串操作的 ...
随机推荐
- System.arraycopy方法详解
- 174. Dungeon Game(动态规划)
The demons had captured the princess (P) and imprisoned her in the bottom-right corner of a dungeon. ...
- EditPlus 4.3.2560 中文版已经发布
新的版本修复了选中文本操作的一些问题. 下载连接在左上角!
- 20155239 2016-2017-2 《Java程序设计》第5周学习总结
教材内容学习 第八章 JAVA异常架构 Java异常是Java提供的一种识别及响应错误的一致性机制. Java异常机制可以使程序中异常处理代码和正常业务代码分离,保证程序代码更加优雅,并提高程序健壮性 ...
- 文本按列导入excel
打开excel,选择数据选项卡,自文本选项.
- eclispe 相关设置
1. 关闭js文件校验: 1). windows->preference->Java Script->Validator->Errors/Warnings->Enable ...
- 如何禁用MySql总是定时弹出一个MySQLInstallerConsole.exe的窗口
如何禁用MySql总是定时弹出一个MySQLInstallerConsole.exe的窗口 禁用mysql总是弹出一个安装框的定时任务这一条安装命令,Installing MySQL 5.6.21 u ...
- JS重要的内置对象
Array对象: 属性: .length 获得数组的长度: 方法: .concat() 连接内容或者数组,组成新的数组: .join(n) 用n连接数组的每一项组成字符串,可以是空字符串: ...
- JProfiler8 远程监控tomcat配置过程
1. 阅读人群 1.熟悉liunx服务器,起码知道liunx常见的命令 2.熟悉tomcat容器,起码知道怎么tomcat的启动以及停止 3.熟悉java编程语言,JProfiler8是专门监控jav ...
- spoj1825 Free tour II
题目链接 一道神奇的点分治 貌似有很多做法,我觉得BIT要好些一些(雾 要求经过黑点数<k就用BIT区间查询前缀 对于每个点用 BIT[0,k-经过黑点数]的最大值+路径长度 使用点分治做到O ...