TensorFlow笔记-07-神经网络优化-学习率,滑动平均
TensorFlow笔记-07-神经网络优化-学习率,滑动平均
学习率
- 学习率 learning_rate: 表示了每次参数更新的幅度大小。学习率过大,会导致待优化的参数在最小值附近波动,不收敛;学习率过小,会导致待优化的参数收敛缓慢
- 在训练过程中,参数的更新向着损失函数梯度下降的方向
- 参数的更新公式为:
wn+1 = wn - learning_rate▽ - 假设损失函数 loss = (w + 1)2。梯度是损失函数 loss 的导数为 ▽ = 2w + 2 。如参数初值为5,学习率为 0.2,则参数和损失函数更新如下:
1次 ·······参数w: 5 ·················5 - 0.2 * (2 * 5 + 2) = 2.6
2次 ·······参数w: 2.6 ··············2.6 - 0.2 * (2 * 2.6 + 2) = 1.16
3次 ·······参数w: 1.16 ············1.16 - 0.2 * (2 * 1.16 +2) = 0.296
4次 ·······参数w: 0.296
损失函数loss = (w + 1) 2 的图像为:
由图可知,损失函数 loss 的最小值会在(-1,0)处得到,此时损失函数的导数为 0,得到最终参数 w = -1。
代码 tf08learn 文件:https://xpwi.github.io/py/TensorFlow/tf08learn.py
# coding: utf-8
# 设损失函数loss = (w + 1)^2 , 令 w 是常数 5。反向传播就是求最小
# loss 对应的 w 值
import tensorflow as tf
# 定义待优化参数 w 初值赋予5
w = tf.Variable(tf.constant(5, dtype=tf.float32))
# 定义损失函数 loss
loss = tf.square(w + 1)
# 定义反向传播方法
train_step = tf.train.GradientDescentOptimizer(0.20).minimize(loss)
# 生成会话,训练40轮
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
for i in range(40):
sess.run(train_step)
W_val = sess.run(w)
loss_val = sess.run(loss)
print("After %s steps: w: is %f, loss: is %f." %(i, W_val, loss_val))
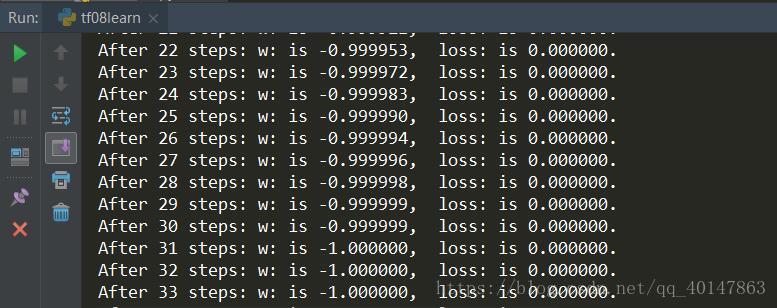
运行结果
运行结果分析: 由结果可知,随着损失函数值得减小,w 无线趋近于 -1
学习率的设置
- 学习率过大,会导致待优化的参数在最小值附近波动,不收敛;学习率过小,会导致待优化的参数收敛缓慢
- 例如:
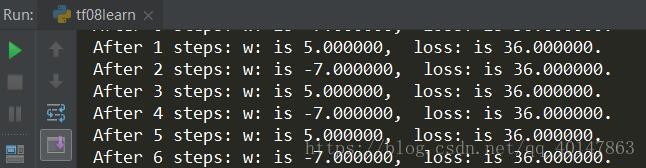
- (1) 对于上例的损失函数loss = (w + 1) 2,则将上述代码中学习率改为1,其余内容不变
实验结果如下:
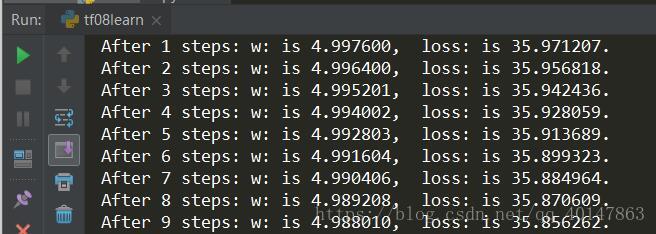
- (2) 对于上例的损失函数loss = (w + 1) 2,则将上述代码中学习率改为0.0001,其余内容不变
实验结果如下:
由运行结果可知,损失函数 loss 值缓慢下降,w 值也在小幅度变化,收敛缓慢
指数衰减学习率
- 指数衰减学习率:学习率随着训练轮数变化而动态更新
其中,LEARNING_RATE_BASE 为学习率初始值,LEARNING_RATE_DECAY 为学习率衰减率,global_step 记录了当前训练轮数,为了不可训练型参数。学习率 learning_rate 更新频率为输入数据集总样本数除以每次喂入样本数。若 staircase 设置为 True 时,表示 global_step / learning rate step 取整数,学习率阶梯型衰减;若 staircase 设置为 False 时,学习率会是一条平滑下降的曲线。 - 例如:
在本例中,模型训练过程不设定固定的学习率,使用指数衰减学习率进行训练。其中,学习率初值设置为0.1,学习率衰减值设置为0.99,BATCH_SIZE 设置为1。 - 代码 tf08learn2 文件:https://xpwi.github.io/py/TensorFlow/tf08learn2.py

# coding: utf-8
'''
设损失函数loss = (w + 1)^2 , 令 w 初值是常数5,
反向传播就是求最优 w,即求最小 loss 对应的w值。
使用指数衰减的学习率,在迭代初期得到较高的下降速度,
可以在较小的训练轮数下取得更有收敛度
'''
import tensorflow as tf
LEARNING_RATE_BASE = 0.1 # 最初学习率
LEARNING_RATE_DECAY = 0.99 # 学习率衰减率
# 喂入多少轮 BATCH_SIZE 后,更新一次学习率,一般设置为:样本数/BATCH_SIZE
LEARNING_RATE_STEP = 1
# 运行了几轮 BATCH_SIZE 的计算器,初始值是0,设为不被训练
global_step = tf.Variable(0, trainable=False)
# 定义指数下降学习率
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, global_step,
LEARNING_RATE_STEP, LEARNING_RATE_DECAY, staircase=True)
# 定义待优化参数 w 初值赋予5
w = tf.Variable(tf.constant(5, dtype=tf.float32))
# 定义损失函数 loss
loss = tf.square(w+1)
# 定义反向传播方法
# 学习率为:0.2
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
# 生成会话,训练40轮
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
for i in range(40):
sess.run(train_step)
learning_rate_val = sess.run(learning_rate)
global_step_val = sess.run(global_step)
w_val = sess.run(w)
loss_val = sess.run(loss)
print("After %s steps: global_step is %f; : w: is %f;learn rate is %f; loss: is %f."
%(i,global_step_val, w_val, learning_rate_val, loss_val))
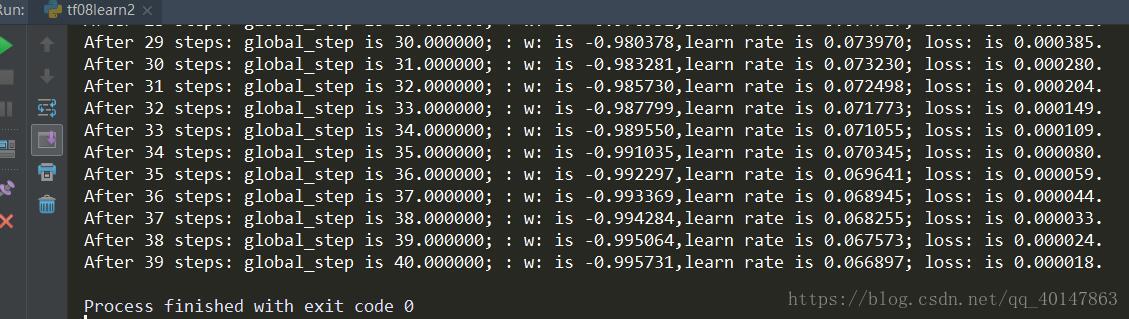
运行结果
由结果可以看出,随着训练轮数增加学习率在不断减小
滑动平均
- **滑动平均:记录了一段时间内模型中所有参数 w 和 b 各自的平均值,利用滑动平均值可以增强模型的泛化能力
- **滑动平均值(影子)计算公式:影子 = 衰减率 * 参数
- 其中衰减率 = min{AVERAGEDECAY(1+轮数/10+轮数)},影子初值 = 参数初值
- 用 Tensorflow 函数表示:
**ema = tf.train.ExpoentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
- 其中 MOVING_AVERAGE_DECAY 表示滑动平均衰减率,一般会赋予接近1的值,global_step 表示当前训练了多少轮
**ema_op = ema.apply(tf.trainable_varables())
- 其中 ema.apply() 函数实现对括号内参数的求滑动平均,tf.trainable_variables() 函数实现把所有待训练参数汇总为列表
with tf.control_dependencies([train_step, ema_op]):
**train_op = tf.no_op(name='train') **
- 其中,该函数实现滑动平均和训练步骤同步运行
- 查看模型中参数的平均值,可以用 ema.average() 函数
- 例如:
在神经网络中将 MOVING_AVERAGE_DECAY 设置为 0.9,参数 w1 设置为 0,w1 滑动平均值设置为 0 - (1)开始时,轮数 global_step 设置为 0,参数 w1 更新为 1,则滑动平均值为:
**w1 滑动平均值 = min(0.99, 1/10)0+(1-min(0.99,1/10))1 = 0.9 **
- (2)当轮数 global_step 设置为 0,参数 w1 更新为 10,以下代码 global_step 保持 100,每次执行滑动平均操作影子更新,则滑动平均值变为:
**w1 滑动平均值 = min(0.99, 101/110)0.9+(1-min(0.99,101/110))10 = 0.826+0.818 = 1.644 **
- (3)再次运行,参数 w1 更新为 1.644,则滑动平均值变为:
**w1
更多文章链接:Tensorflow 笔记
- 本笔记不允许任何个人和组织转载
TensorFlow笔记-07-神经网络优化-学习率,滑动平均的更多相关文章
- TensorFlow笔记-06-神经网络优化-损失函数,自定义损失函数,交叉熵
TensorFlow笔记-06-神经网络优化-损失函数,自定义损失函数,交叉熵 神经元模型:用数学公式比表示为:f(Σi xi*wi + b), f为激活函数 神经网络 是以神经元为基本单位构成的 激 ...
- 吴裕雄 python 神经网络——TensorFlow训练神经网络:不使用滑动平均
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data INPUT_NODE = 784 ...
- 20180929 北京大学 人工智能实践:Tensorflow笔记07
(完)
- Tensorflow 笔记
TensorFlow笔记-08-过拟合,正则化,matplotlib 区分红蓝点 TensorFlow笔记-07-神经网络优化-学习率,滑动平均 TensorFlow笔记-06-神经网络优化-损失函数 ...
- tensorflow笔记之滑动平均模型
tensorflow使用tf.train.ExponentialMovingAverage实现滑动平均模型,在使用随机梯度下降方法训练神经网络时候,使用这个模型可以增强模型的鲁棒性(robust),可 ...
- tensorflow笔记2(北大网课实战)
1.正则化缓解过拟合 正则化在损失函数中引入模型复杂度指标,利用给w加权值,弱化了训练数据的噪声 一般不会正则化b. 2.matplotlib.pyplot 3.搭建模块化的神经网络八股: 前向传播就 ...
- tensorflow:实战Google深度学习框架第四章02神经网络优化(学习率,避免过拟合,滑动平均模型)
1.学习率的设置既不能太小,又不能太大,解决方法:使用指数衰减法 例如: 假设我们要最小化函数 y=x2y=x2, 选择初始点 x0=5x0=5 1. 学习率为1的时候,x在5和-5之间震荡. im ...
- tensorflow入门笔记(二) 滑动平均模型
tensorflow提供的tf.train.ExponentialMovingAverage 类利用指数衰减维持变量的滑动平均. 当训练模型的时候,保持训练参数的滑动平均是非常有益的.评估时使用取平均 ...
- TensorFlow+实战Google深度学习框架学习笔记(11)-----Mnist识别【采用滑动平均,双层神经网络】
模型:双层神经网络 [一层隐藏层.一层输出层]隐藏层输出用relu函数,输出层输出用softmax函数 过程: 设置参数 滑动平均的辅助函数 训练函数 x,y的占位,w1,b1,w2,b2的初始化 前 ...
随机推荐
- CF808D STL
D. Array Division time limit per test 2 seconds memory limit per test 256 megabytes input standard i ...
- 62. 63. Unique Paths 64. Minimum Path Sum
1. A robot is located at the top-left corner of a m x n grid (marked 'Start' in the diagram below). ...
- SQL优化(SQL TUNING)可大幅提升性能的实战技巧之一——让计划沿着索引跑
我们进行SQL优化时,经常会碰到对大量数据集进行排序,然后从排序后的集合取前部分结果的需求,这种情况下,当我们按照常规思路去写SQL时,系统会先读取过滤获得所有集合,然后进行排序,再从排序结果取出极少 ...
- React脚手架create-react-app+elementUI使用
一.介绍 1.create-react-app是FaceBook官方发布了一个无需配置的.用于快速构建开发环境的脚手架工具. 2.优点 a.无需配置:官方的配置堪称完美,几乎不用你再配置任何东西,就可 ...
- Vysor安装图解
Vysor安装图解 11 准备东西 路径 C:\Users\Administrator\AppData\Local\Google\Chrome\User Data\Default ...
- JDBCTemplate使用
业务上,手机App(离线状态下的数据),在在线的时候需要往服务端上传,由于App上的SQLite数据库里的需要 同步数据的表 跟服务端的数据库表结构一致,所以为了同步数据的方便性,我们决定App在进行 ...
- Eclipse中复制项目重命名后重新发布,项目名在地址栏仍然是原来的项目名”的问题
转载自: http://www.cnblogs.com/chenxueling/p/5474717.html 将20170331-JavaEE-SSH项目复制一份,重命名为20170407-JavaE ...
- Linux更改中国时区
执行tzselect命令-->选择Asia-->选择China-->选择east China - Beijing, ->然后输入1 再执行 ln -sf /usr/share/ ...
- AR.Drone 2.0四轴飞机体验:最好的玩具航拍器
http://digi.tech.qq.com/a/20140513/007458.htm?pgv_ref=aio2012&ptlang=2052 AR.Drone 2.0四轴飞机体验:最好的 ...
- ReactNative——UI2.组件生命周期
对于习惯了iOS开发的同学,可能会对React Native中组件的生命周期很困惑.在iOS中有一个ViewDidLoad来初始化,那么在RN中,又是在哪里呢? 一.看图分析 在下图中描述了React ...