HBase写入性能及改造——multi-thread flush and compaction(续:详细测试数据)[转]
转载:http://blog.csdn.net/kalaamong/article/details/7290192
接上文啊:
| CPU | 16* Intel(R) Xeon(R) CPU E5620 @ 2.40GHz |
|---|---|
| MEMORY | 48GB |
| DISK | 12*SATA 2TB |
| NET | 4*1Gb Ethernet |
测试数据:
| 类型 | 国内某视频网站近半年用户访问日志 |
| 结构 | 一行九列,包括用户访问页,关键词及其它用户信息。对应HBase一个family下9个column,一行120到180字节 |
| 数据量 | 每次测试写入10亿条数据,原始数据约110GB,写到HBase中一张不加压缩的表里HDFS中单副本约480GB (dus结果) |
集群结构
| RegionServer | 1个 hostname: data2 |
| DataNode | 5个hostname: data12~data16 |
这样设设计的集群结构,主要目的就是要压测Region Server。以下所有测试客户端put关HLog,服务端不split。
第一组:(原始情况)
这是最初Hbase的情况,没有对服务端代码做修改,在配置参数上稍稍改动了类似于MemStore up water level,low water level,以及handler数目和HFile的最大Size值。可以看出虽然是压测,hbase所有地方都很闲,内部的情况是就Multi写入数据了之后MemStore大了等flush,flush的store file多了就等compact。各种等也就各种闲。
最后写入10亿行数据用时6小时48分。整个表在HDFS dus出的大小约440GB。


第二组:(配置项修改)
下面的图是继上面情况之后修改了
<property>
<name>hbase.hstore.blockingStoreFiles</name>
<value>2000</value>
</property>
把block flush的storefile数从默认的7改到了2000,已经不让split了,还不许storefile数多一点,太没人性了。此时前段时间写入的性能有些改善,但毕竟还是单线程的flush和compact治标不治本。
最后写入10亿行数据用时5小时54分,比上一组实验缩短了1个小时。整个表在HDFS dus出的大小约480GB,原因应当是flush被阻塞的次数减少,flush得更频繁了,写入流量也稍增,但没来得及compact的store file更多,所以整个表大了40G( 约9%)。


第三组:(代码修改)
最后来治标治本吧。后面的实验中配置参数与上一组相同,同时服务端修改代码,为flush和compact添加了线程池。并新加入两个配置项:
25 <property>
26 <name>hbase.hstore.flush.thread</name>
27 <value>20</value>
28 </property>
29 <property>
30 <name>hbase.hstore.compaction.thread</name>
31 <value>15</value>
32 </property>
再看压测情况CPU基本满载。唉这才是压测啊!!
如此这般下来写入10亿行数据用时2小时58分,不到第一组一半的时间。表大小约410GB
由于compact做得及时,表大小比第一组小30GB,比第二组小70GB。


第四组:(代码修改加压缩)
接着按第三组的情况加上GZ的软压缩(为什么挑GZ请参第五组测试),这组估计CPU都要冒烟了。
写入10亿行数据耗时3小时5分,比上一组多了7分钟。但表的size为71GB !差不多是上一组的六分之一,尽然压缩到了原数据的17%大小。
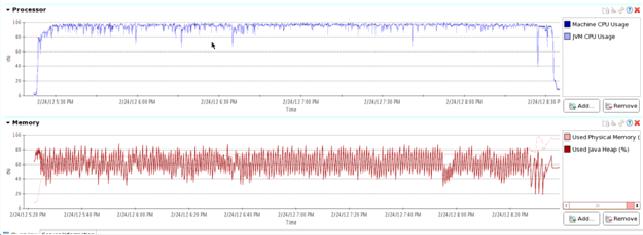
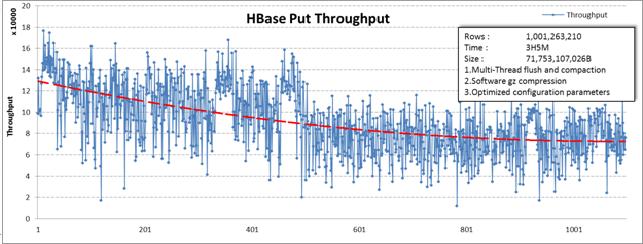
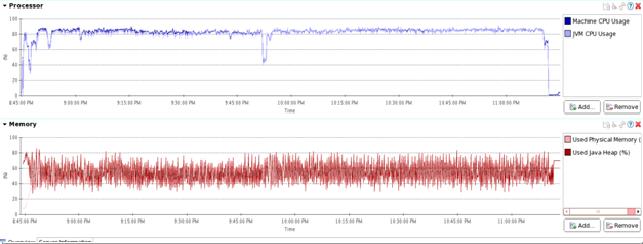
第五组:(第五组大家自己研究吧)
这一组最强悍,采用了一些特殊的硬件改了改HDFS,HBase的修改与上两组相同。
写入10亿行数据耗时2小时24分钟。差不多是第一组时间的1/3。文件size为111GB,压到了第一组的1/4。且CPU也没到冒烟的状态,应当还能加压。关于这个组今后还将有更详细的测试结果放出。现在先不详细介绍了。

HBase写入性能及改造——multi-thread flush and compaction(续:详细测试数据)[转]的更多相关文章
- HBase写入性能改造(续)--MemStore、flush、compact参数调优及压缩卡的使用【转】
首先续上篇测试: 经过上一篇文章中对代码及参数的修改,Hbase的写入性能在不开Hlog的情况下从3~4万提高到了11万左右. 本篇主要介绍参数调整的方法,在HDFS上加上压缩卡,最后能达到的写入 ...
- 多Region下HBase写入问题
最近在集群上发现hbase写入性能受到较大下降,测试环境下没有该问题产生.而生产环境和测试环境的区别之一是生产环境的region数量远远多于测试环境,单台regionserver服务了约3500个re ...
- 提高HBase写性能
以下为使用hbase一段时间的三个思考,由于在内存充足的情况下hbase能提供比较满意的读性能,因此写性能是思考的重点.希望读者提出不同意见讨论 1 autoflush=false的影响 无论是官方还 ...
- 万字长文详解HBase读写性能优化
一.HBase 读优化 1. HBase客户端优化 和大多数系统一样,客户端作为业务读写的入口,姿势使用不正确通常会导致本业务读延迟较高实际上存在一些使用姿势的推荐用法,这里一般需要关注四个问题: 1 ...
- HBase配置性能调优(转)
因官方Book Performance Tuning部分章节没有按配置项进行索引,不能达到快速查阅的效果.所以我以配置项驱动,重新整理了原文,并补充一些自己的理解,如有错误,欢迎指正. 配置优化 zo ...
- HBase配置性能调优
因官方Book Performance Tuning部分章节没有按配置项进行索引,不能达到快速查阅的效果.所以我以配置项驱动,重新整理了原文,并补充一些自己的理解,如有错误,欢迎指正. 配置优化 zo ...
- hbase实践之flush and compaction
本文主要涉及flush流程,探讨flush流程过程中引入的问题并阐述2种解决策略,最后简要说明Flush执行策略. 对于Compaction,本文主要探讨Compaction要解决的本质问题以及由Co ...
- MySQL · 性能优化· InnoDB buffer pool flush策略漫谈
MySQL · 性能优化· InnoDB buffer pool flush策略漫谈 背景 我们知道InnoDB使用buffer pool来缓存从磁盘读取到内存的数据页.buffer pool通常由数 ...
- 公司HBase基准性能测试之结果篇
上一篇文章<公司HBase基准性能测试之准备篇>中详细介绍了本次性能测试的基本准备情况,包括测试集群架构.单台机器软硬件配置.测试工具以及测试方法等,在此基础上本篇文章主要介绍HBase在 ...
随机推荐
- [转]NLP数据集
原文链接 nlp-datasets Alphabetical list of free/public domain datasets with text data for use in Natural ...
- 看过这两张图,就明白 Buffer 和 Cache 之间区别
Buffer常见的是这个: 对,就是铁道端头那个巨大的弹簧一类的东西.作用是万一车没停住,撞弹簧上减速慢,危险小一些.叫缓冲. Cache常见的是这个: 没错,就是一种保管箱.看到右边那个被锈掉的Fo ...
- 自动化安装smokeping-2.6.11脚本
自动化安装Smokeping-2.6.11脚本 一.目的 1.1 监控目的 为方便监测各数据中心网络状况,自定义全国各节点,从而发现网络异常,判断网络故障. 1.2 本文目的 快速部署Smokepin ...
- go interface 的坑
一.概述 [root@node175 demo]# tree . ├── lib │ └── world.go ├── README └── server.go directory, files ...
- openstack neutron 二/三层网络实现
引用声明:https://zhangchenchen.github.io/2017/02/12/neutron-layer2-3-realization-discovry/ 一.概述 Neutron是 ...
- IntelliJ IDEA 最新激活码(截止到2018年10月14日)
IntelliJ IDEA 注册码: EB101IWSWD-eyJsaWNlbnNlSWQiOiJFQjEwMUlXU1dEIiwibGljZW5zZWVOYW1lIjoibGFuIHl1IiwiYX ...
- notepad++ 语法高亮
1. notepad++ 添加新语言语法高亮和加载插件 用notepad++已经很久了,很习惯用这个小东西做事情,简单方便,超实用的一款工具. 先说说在呢么添加对新的编程语言的支持吧, 添加新语言语法 ...
- php截取字符去掉最后一个字符
$str="中国.美国.俄罗斯.德国."$str=substr($str,0,-1); 输出结果为:中国.美国.俄罗斯.德国
- 例说Linux内核链表(一)
介绍 众所周知,Linux内核大部分是使用GNU C语言写的.C不同于其它的语言,它不具备一个好的数据结构对象或者标准对象库的支持. 所以能够借用Linux内核源代码树的循环双链表是一件非常值得让人高 ...
- C#基础第六天-作业答案-利用面向对象的思想去实现名片
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...