[kafka] 001_kafka起步
一、简介
- Kafka is a distributed, partitioned, replicated commit log service. It provides the functionality of a messaging system, but with a unique design.
- Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。
- 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。
- 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。
- Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。
二、特点
- Kafka maintains feeds of messages in categories called topics.
- We'll call processes that publish messages to a Kafka topic producers.
- We'll call processes that subscribe to topics and process the feed of published messages consumers.
- Kafka is run as a cluster comprised of one or more servers each of which is called a broker.
at a high level, producers send messages over the network to the Kafka cluster which in turn serves them up to consumers like this:

Communication between the clients and the servers is done with a simple, high-performance, language agnostic TCP protocol. We provide a Java client for Kafka, but clients are available in many languages.(客户端和服务器之间的沟通采用了TCP协议,kafka提供了基于Java的客户端,但是理论上客户端可以用任何语言编码实现)
三、相关术语
- Broker
- Kafka集群包含一个或多个服务器,这种服务器被称为broker.
- Topic
- 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic. 物理上不同Topic的消息分开存储,逻辑上一个Topic 的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处.
- Partition
- Partition是物理上的概念,每个Topic包含一个或多个Partition.
- Producer
- 负责发布消息到Kafka broker
- Consumer
- 消息消费者,向Kafka broker读取(pull)消息的客户端.
- Consumer Group
- 每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group).
四、设计原理
- kafka的设计初衷是希望作为一个统一的信息收集平台,能够实时的收集反馈信息,并需要能够支撑较大的数据量,且具备良好的容错能力.
1、持久性
- kafka使用文件存储消息,这就直接决定kafka在性能上严重依赖文件系统的本身特性.且无论任何OS下,对文件系统本身的优化几乎没有可能.
- 文件缓存/直接内存映射等是常用的手段.
- 因为kafka是对日志文件进行append操作,因此磁盘检索的开支是较小的;同时为了减少磁盘写入的次数,broker会将消息暂时buffer起来,当消息的个数(或尺寸)达到一定阀值时,再flush到磁盘,这样减少了磁盘IO调用的次数.
2、性能
- 需要考虑的影响性能点很多,除磁盘IO之外,我们还需要考虑网络IO,这直接关系到kafka的吞吐量问题.kafka并没有提供太多高超的技巧;
- 对于producer端,可以将消息buffer起来,当消息的条数达到一定阀值时,批量发送给broker;
- 对于consumer端也是一样,批量fetch多条消息.不过消息量的大小可以通过配置文件来指定.
- 对于kafka broker端,似乎有个sendfile系统调用可以潜在的提升网络IO的性能:将文件的数据映射到系统内存中,socket直接读取相应的内存区域即可,而无需进程再次copy和交换.
- 其实对于producer/consumer/broker三者而言,CPU的开支应该都不大,因此启用消息压缩机制是一个良好的策略;压缩需要消耗少量的CPU资源,不过对于kafka而言,网络IO更应该需要考虑.可以将任何在网络上传输的消息都经过压缩.kafka支持gzip/snappy等多种压缩方式.
3、生产者
- 负载均衡:
- producer将会和Topic下所有partition leader保持socket连接;消息由producer直接通过socket发送到broker,中间不会经过任何"路由层".事实上,消息被路由到哪个partition上,有producer客户端决定.比如可以采用"random""key-hash""轮询"等,如果一个topic中有多个partitions,那么在producer端实现"消息均衡分发"是必要的.
- 其中partition leader的位置(host:port)注册在zookeeper中,producer作为zookeeper client,已经注册了watch用来监听partition leader的变更事件.
- 异步发送:将多条消息暂且在客户端buffer起来,并将他们批量的发送到broker,小数据IO太多,会拖慢整体的网络延迟,批量延迟发送事实上提升了网络效率。不过这也有一定的隐患,比如说当producer失效时,那些尚未发送的消息将会丢失。
4、消费者
- consumer端向broker发送"fetch"请求,并告知其获取消息的offset;此后consumer将会获得一定条数的消息;consumer端也可以重置offset来重新消费消息.
- 在JMS实现中,Topic模型基于push方式,即broker将消息推送给consumer端.不过在kafka中,采用了pull方式,即consumer在和broker建立连接之后,主动去pull(或者说fetch)消息;这中模式有些优点,首先consumer端可以根据自己的消费能力适时的去fetch消息并处理,且可以控制消息消费的进度(offset);此外,消费者可以良好的控制消息消费的数量,batch fetch.
- 其他JMS实现,消息消费的位置是有prodiver保留,以便避免重复发送消息或者将没有消费成功的消息重发等,同时还要控制消息的状态.这就要求JMS broker需要太多额外的工作.在kafka中,partition中的消息只有一个consumer在消费,且不存在消息状态的控制,也没有复杂的消息确认机制,可见kafka broker端是相当轻量级的.当消息被consumer接收之后,consumer可以在本地保存最后消息的offset,并间歇性的向zookeeper注册offset.由此可见,consumer客户端也很轻量级.

5、消息传送机制
- 对于JMS实现,消息传输担保非常直接:有且只有一次(exactly once).在kafka中稍有不同,有三种方式:
) at most once: 最多一次,这个和JMS中"非持久化"消息类似.发送一次,无论成败,将不会重发.- ) at least once: 消息至少发送一次,如果消息未能接受成功,可能会重发,直到接收成功.
- ) exactly once: 消息只会发送一次.
- at most once: 消费者fetch消息,然后保存offset,然后处理消息;当client保存offset之后,但是在消息处理过程中出现了异常,导致部分消息未能继续处理.那么此后"未处理"的消息将不能被fetch到,这就是"at most once".
at least once: 消费者fetch消息,然后处理消息,然后保存offset.如果消息处理成功之后,但是在保存offset阶段zookeeper异常导致保存操作未能执行成功,这就导致接下来再次fetch时可能获得上次已经处理过的消息,这就是"at least once",原因offset没有及时的提交给zookeeper,zookeeper恢复正常还是之前offset状态.
exactly once: kafka中并没有严格的去实现(基于2阶段提交,事务),我们认为这种策略在kafka中是没有必要的.
通常情况下"at-least-once"是我们首选.(相比at most once而言,重复接收数据总比丢失数据要好).
6、复制备份
- kafka将每个partition数据复制到多个server上,任何一个partition有一个leader和多个follower(可以没有);
- 备份的个数可以通过broker配置文件来设定.
- leader处理所有的read-write请求,follower需要和leader保持同步.Follower和consumer一样,消费消息并保存在本地日志中;leader负责跟踪所有的follower状态,如果follower"落后"太多或者失效,leader将会把它从replicas同步列表中删除.当所有的follower都将一条消息保存成功,此消息才被认为是"committed",那么此时consumer才能消费它.
- 即使只有一个replicas实例存活,仍然可以保证消息的正常发送和接收,只要zookeeper集群存活即可.(不同于其他分布式存储,比如hbase需要"多数派"存活才行)
- 当leader失效时,需在followers中选取出新的leader,可能此时follower落后于leader,因此需要选择一个"up-to-date"的follower.选择follower时需要兼顾一个问题,就是新leader-server上所已经承载的partition leader的个数,如果一个server上有过多的partition leader,意味着此server将承受着更多的IO压力.在选举新leader,需要考虑到"负载均衡".
7.日志
- 如果一个topic的名称为"my_topic",它有2个partitions,那么日志将会保存在my_topic_0和my_topic_1两个目录中;
- 日志文件中保存了一序列"log entries"(日志条目),每个log entry格式为"4个字节的数字N表示消息的长度" + "N个字节的消息内容";
- 每个日志都有一个offset来唯一的标记一条消息,offset的值为8个字节的数字,表示此消息在此partition中所处的起始位置.每个partition在物理存储层面,由多个log file组成(称为segment).
- segmentfile的命名为"最小offset".kafka.例如"00000000000.kafka";其中"最小offset"表示此segment中起始消息的offset.
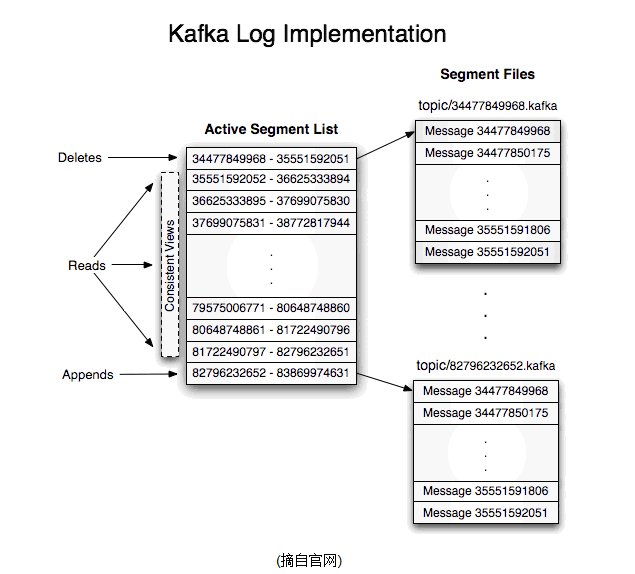
- 其中每个partiton中所持有的segments列表信息会存储在zookeeper中.
- 当segment文件尺寸达到一定阀值时(可以通过配置文件设定,默认1G),将会创建一个新的文件;当buffer中消息的条数达到阀值时将会触发日志信息flush到日志文件中,同时如果"距离最近一次flush的时间差"达到阀值时,也会触发flush到日志文件.如果broker失效,极有可能会丢失那些尚未flush到文件的消息.因为server意外实现,仍然会导致log文件格式的破坏(文件尾部),那么就要求当server启东是需要检测最后一个segment的文件结构是否合法并进行必要的修复.
- 获取消息时,需要指定offset和最大chunk尺寸,offset用来表示消息的起始位置,chunk size用来表示最大获取消息的总长度(间接的表示消息的条数).根据offset,可以找到此消息所在segment文件,然后根据segment的最小offset取差值,得到它在file中的相对位置,直接读取输出即可.
- 日志文件的删除策略非常简单:启动一个后台线程定期扫描log file列表,把保存时间超过阀值的文件直接删除(根据文件的创建时间).为了避免删除文件时仍然有read操作(consumer消费),采取copy-on-write方式.
8、分配
- kafka使用zookeeper来存储一些meta信息,并使用了zookeeper watch机制来发现meta信息的变更并作出相应的动作(比如consumer失效,触发负载均衡等)
- ) Broker node registry: 当一个kafka-broker启动后,首先会向zookeeper注册自己的节点信息(临时znode),同时当broker和zookeeper断开连接时,此znode也会被删除.
- 格式: /broker/ids/[...N] -->host:port;其中[..N]表示broker id,每个broker的配置文件中都需要指定一个数字类型的id(全局不可重复),znode的值为此broker的host:port信息.
- ) Broker Topic Registry: 当一个broker启动时,会向zookeeper注册自己持有的topic和partitions信息,仍然是一个临时znode.
格式: /broker/topics/[topic]/[...N] 其中[..N]表示partition索引号.
) Consumer and Consumer group: 每个consumer客户端被创建时,会向 zookeeper 注册自己的信息;此作用主要是为了"负载均衡".- 一个group中的多个consumer可以交错的消费一个topic的所有partitions;简而言之,保证此topic的所有partitions都能被此group所消费,且消费时为了性能考虑,让partition相对均衡的分散到每个consumer上.
- ) Consumer id Registry: 每个consumer都有一个唯一的ID(host:uuid,可以通过配置文件指定,也可以由系统生成),此id用来标记消费者信息.
- 格式:/consumers/[group_id]/ids/[consumer_id]
- 仍然是一个临时的znode,此节点的值为{"topic_name":#streams...},即表示此consumer目前所消费的topic + partitions列表.
- ) Consumer offset Tracking: 用来跟踪每个consumer目前所消费的partition中最大的offset.
- 格式:/consumers/[group_id]/offsets/[topic]/[broker_id-partition_id]-->offset_value
- 此znode为持久节点,可以看出offset跟group_id有关,以表明当group中一个消费者失效,其他consumer可以继续消费.
- ) Partition Owner registry: 用来标记partition被哪个consumer消费.临时znode
- 格式:/consumers/[group_id]/owners/[topic]/[broker_id-partition_id]-->consumer_node_id当consumer启动时,所触发的操作:
- A) 首先进行"Consumer id Registry";
- B) 然后在"Consumer id Registry"节点下注册一个watch用来监听当前group中其他consumer的"leave"和"join";只要此znode path下节点列表变更,都会触发此group下consumer的负载均衡.(比如一个consumer失效,那么其他consumer接管partitions).
- C) 在"Broker id registry"节点下,注册一个watch用来监听broker的存活情况;如果broker列表变更,将会触发所有的groups下的consumer重新balance.

- ) Producer端使用zookeeper用来"发现"broker列表,以及和Topic下每个partition leader建立socket连接并发送消息.
- ) Broker端使用zookeeper用来注册broker信息,已经监测partition-leader存活性.
- ) Consumer端使用zookeeper用来注册consumer信息,其中包括consumer消费的partition列表等,同时也用来发现broker列表,并和partition leader建立socket连接,并获取消息.
五、参考资料
http://kafka.apache.org/documentation.html#gettingStarted
http://www.cnblogs.com/likehua/p/3999538.html
[kafka] 001_kafka起步的更多相关文章
- Kafka 快速起步(作者:杜亦舒)
Kafka 快速起步 原创 2017-01-05 杜亦舒 性能与架构 主要内容:1. kafka 安装.启动2. 消息的 生产.消费3. 配置启动集群4. 集群下的容错测试5. 从文件中导入数据,并导 ...
- Kafka 快速起步
Kafka 快速起步 原创 2017-01-05 杜亦舒 性能与架构 性能与架构 性能与架构 微信号 yogoup 功能介绍 网站性能提升与架构设计 主要内容:1. kafka 安装.启动2. 消息的 ...
- 001_kafka起步
一.简介 Kafka is a distributed, partitioned, replicated commit log service. It provides the functionali ...
- Apache Kafka系列(一) 起步
Apache Kafka系列(一) 起步 Apache Kafka系列(二) 命令行工具(CLI) Apache Kafka系列(三) Java API使用 Apache Kafka系列(四) 多线程 ...
- Confluent Platform 3.0支持使用Kafka Streams实现实时的数据处理(最新版已经是3.1了,支持kafka0.10了)
来自 Confluent 的 Confluent Platform 3.0 消息系统支持使用 Kafka Streams 实现实时的数据处理,这家公司也是在背后支撑 Apache Kafka 消息框架 ...
- Spark Streaming,Flink,Storm,Kafka Streams,Samza:如何选择流处理框架
根据最新的统计显示,仅在过去的两年中,当今世界上90%的数据都是在新产生的,每天创建2.5万亿字节的数据,并且随着新设备,传感器和技术的出现,数据增长速度可能会进一步加快. 从技术上讲,这意味着我们的 ...
- kafka背着你做了什么?
Kafka中有broker.主题.分区.副本等概念,底层有日志和日志分片. 我们先简单介绍一下这些概念,做个类比. broker可以简单理解为一台物理机,其实一台机器上可以有多个broker进程,但是 ...
- ActiveMQ、RabbitMQ、RocketMQ、Kafka四种消息中间件分析介绍
ActiveMQ.RabbitMQ.RocketMQ.Kafka四种消息中间件分析介绍 我们从四种消息中间件的介绍到基本使用,以及高可用,消息重复性,消息丢失,消息顺序性能方面进行分析介绍! 一.消息 ...
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
随机推荐
- Android 源码解析:单例模式-通过容器实现单例模式-懒加载方式
本文分析了 Android 系统服务通过容器实现单例,确保系统服务的全局唯一. 开发过 Android 的用户肯定都用过这句代码,主要作用是把布局文件 XML 加载到系统中,转换为 Android 的 ...
- Atitit js es5 es6新特性 attilax总结
Atitit js es5 es6新特性 attilax总结 1.1. JavaScript发展时间轴:1 1.2. 以下是ES6排名前十的最佳特性列表(排名不分先后):1 1.3. Es6 支持情况 ...
- [na]数据链路层&网络层协议小结截图版
ip层:分组选路 tcp:端到端的通信 中间系统没必要有应用程序,分组选路即可 应用程序中隐藏所有的物理细节. 语音肯定用udp linux主版本 次版本号 修订号 次版本为偶数说明是稳定版.奇数是开 ...
- android源码上面开发App
使用eclipse 打开源码:http://blog.csdn.net/androidlover1991/article/details/17011991 使用android studio 打开源码h ...
- CCObject
/**************************************************************************** Copyright (c) 2010 coc ...
- linux安全配置检查脚本_v0.5
看到网上有人分享了一些linux系统的基线检查脚本,但有些检查项未必适合自己或者说检查的不够完善, 计划按着自己的需求重新写一份出来,其中脚本的检查范围在不断更新中. 脚本内容: [root@loca ...
- CSAPP 读书笔记 - 2.31练习题
根据等式(2-14) 假如w = 4 数值范围在-8 ~ 7之间 2^w = 16 x = 5, y = 4的情况下面 x + y = 9 >=2 ^(w-1) 属于第一种情况 sum = x ...
- 【Python】京东商品价格监控
import requests,json,re,winsound,time class Stock(object): def __init__(self): self.province_dict={v ...
- java基础篇---文件上传(commons-FileUpload组件)
上一篇讲解了smartupload组件上传,那么这一篇我们讲解commons-FileUpload组件上传 FileUpload是Apache组织(www.apache.org)提供的免费的上传组件, ...
- thinkphp验证码乱码的解决办法
很有可能是入口文件index.php和.htaccess文件要转换成 以UTF-8无BOM格式编码