神经网络、logistic回归等分类算法简单实现
最近在github上看到一个很有趣的项目,通过文本训练可以让计算机写出特定风格的文章,有人就专门写了一个小项目生成汪峰风格的歌词。看完后有一些自己的小想法,也想做一个玩儿一玩儿。用到的原理是深度学习里的循环神经网络,无奈理论太艰深,只能从头开始开始慢慢看,因此产生写一个项目的想法,把机器学习和深度学习里关于分类的算法整理一下,按照原理写一些demo,方便自己也方便其他人。项目地址:https://github.com/LiuRoy/classfication_demo,目前实现了逻辑回归和神经网络两种分类算法。
Logistic回归
这是相对比较简单的一种分类方法,准确率较低,也只适用于线性可分数据,网上有很多关于logistic回归的博客和文章,讲的也都非常通俗易懂,就不赘述。此处采用随机梯度下降的方式实现,讲解可以参考《机器学习实战》第五章logistic回归。代码如下:
def train(self, num_iteration=150):"""随机梯度上升算法Args:data (numpy.ndarray): 训练数据集labels (numpy.ndarray): 训练标签num_iteration (int): 迭代次数"""for j in xrange(num_iteration):data_index = range(self.data_num)for i in xrange(self.data_num):# 学习速率alpha = 0.01rand_index = int(random.uniform(0, len(data_index)))error = self.label[rand_index] - sigmoid(sum(self.data[rand_index] * self.weights + self.b))self.weights += alpha * error * self.data[rand_index]self.b += alpha * errordel(data_index[rand_index])
效果图:
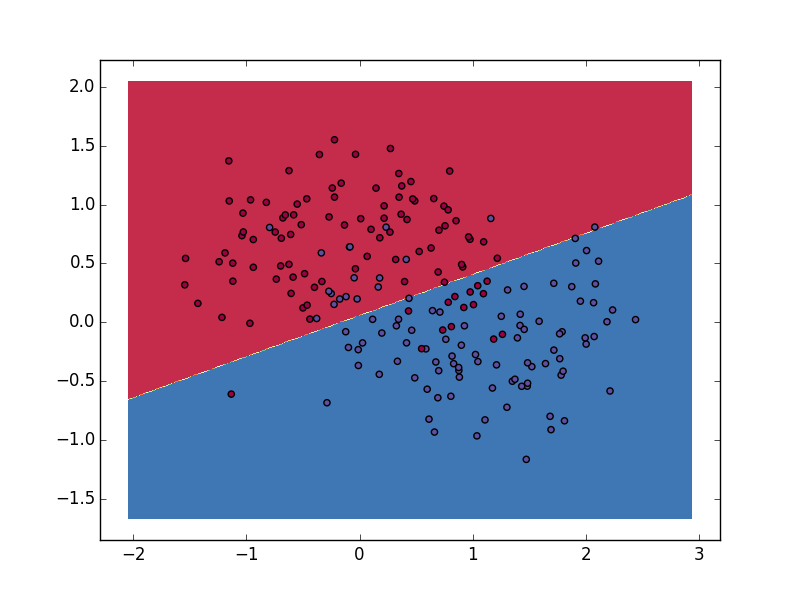
神经网络
参考的是这篇文章,如果自己英语比较好,还可以查看英文文章,里面有简单的实现,唯一的缺点就是没有把原理讲明白。关于神经网络,个人认为确实不是一两句就能解释清楚的,尤其是网上的博客,要么只给公式,要么只给图,看起来都非常的晦涩,建议大家看一下加州理工的一个公开课,有中文字幕,一个小时的课程绝对比自己花一天查文字资料理解的深刻,知道原理之后再来看前面的那篇博客就很轻松啦!
BGD实现
博客里面实现用的是批量梯度下降(batch gradient descent),代码:
def batch_gradient_descent(self, num_passes=20000):"""批量梯度下降训练模型"""for i in xrange(0, num_passes):# Forward propagationz1 = self.data.dot(self.W1) + self.b1a1 = np.tanh(z1)z2 = a1.dot(self.W2) + self.b2exp_scores = np.exp(z2)probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)# Backpropagationdelta3 = probsdelta3[range(self.num_examples), self.label] -= 1dW2 = (a1.T).dot(delta3)db2 = np.sum(delta3, axis=0, keepdims=True)delta2 = delta3.dot(self.W2.T) * (1 - np.power(a1, 2))dW1 = np.dot(self.data.T, delta2)db1 = np.sum(delta2, axis=0)# Add regularization terms (b1 and b2 don't have regularization terms)dW2 += self.reg_lambda * self.W2dW1 += self.reg_lambda * self.W1# Gradient descent parameter updateself.W1 += -self.epsilon * dW1self.b1 += -self.epsilon * db1self.W2 += -self.epsilon * dW2self.b2 += -self.epsilon * db2
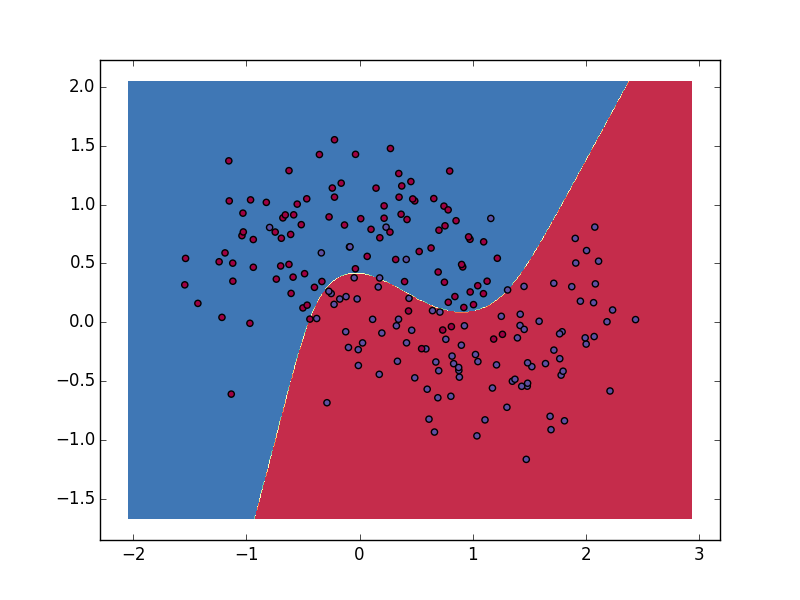
效果图:

注意:强烈怀疑文中的后向传播公式给错了,因为和代码里的delta2 = delta3.dot(self.W2.T) * (1 - np.power(a1, 2))对不上。
SGD实现
考虑到logistic回归可以用随机梯度下降,而且公开课里面也说随机梯度下降效果更好一些,所以在上面的代码上自己改动了一下,代码:
def stochastic_gradient_descent(self, num_passes=200):"""随机梯度下降训练模型"""for i in xrange(0, num_passes):data_index = range(self.num_examples)for j in xrange(self.num_examples):rand_index = int(np.random.uniform(0, len(data_index)))x = np.mat(self.data[rand_index])y = self.label[rand_index]# Forward propagationz1 = x.dot(self.W1) + self.b1a1 = np.tanh(z1)z2 = a1.dot(self.W2) + self.b2exp_scores = np.exp(z2)probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)# Backpropagationdelta3 = probsif y:delta3[0, 0] -= 1else:delta3[0, 1] -= 1dW2 = (a1.T).dot(delta3)db2 = np.sum(delta3, axis=0, keepdims=True)va = delta3.dot(self.W2.T)vb = 1 - np.power(a1, 2)delta2 = np.mat(np.array(va) * np.array(vb))dW1 = x.T.dot(delta2)db1 = np.sum(delta2, axis=0)# Add regularization terms (b1 and b2 don't have regularization terms)dW2 += self.reg_lambda * self.W2dW1 += self.reg_lambda * self.W1# Gradient descent parameter updateself.W1 += -self.epsilon * dW1self.b1 += -self.epsilon * db1self.W2 += -self.epsilon * dW2self.b2 += -self.epsilon * db2del(data_index[rand_index])
可能是我写的方式不好,虽然可以得到正确的结果,但是性能上却比不上BGD,希望大家能指出问题所在,运行效果图:
其他
SVM我还在看,里面的公式推导能把人绕死,稍晚一点写好合入,数学不好就是坑啊
神经网络、logistic回归等分类算法简单实现的更多相关文章
- 02-15 Logistic回归(鸢尾花分类)
目录 Logistic回归(鸢尾花分类) 一.导入模块 二.获取数据 三.构建决策边界 四.训练模型 4.1 C参数与权重系数的关系 五.可视化 更新.更全的<机器学习>的更新网站,更有p ...
- 《转》Logistic回归 多分类问题的推广算法--Softmax回归
转自http://ufldl.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92 简介 在本节中,我们介绍Softmax回归模型,该模型是log ...
- 【2008nmj】Logistic回归二元分类感知器算法.docx
给你一堆样本数据(xi,yi),并标上标签[0,1],让你建立模型(分类感知器二元),对于新给的测试数据进行分类. 要将两种数据分开,这是一个分类问题,建立数学模型,(x,y,z),z指示[0,1], ...
- Logistic回归二分类Winner or Losser----台大李宏毅机器学习作业二(HW2)
一.作业说明 给定训练集spam_train.csv,要求根据每个ID各种属性值来判断该ID对应角色是Winner还是Losser(0.1分类). 训练集介绍: (1)CSV文件,大小为4000行X5 ...
- Sklearn中的回归和分类算法
一.sklearn中自带的回归算法 1. 算法 来自:https://my.oschina.net/kilosnow/blog/1619605 另外,skilearn中自带保存模型的方法,可以把训练完 ...
- logistic regression二分类算法推导
- 《Machine Learning in Action》—— Taoye给你讲讲Logistic回归是咋回事
在手撕机器学习系列文章的上一篇,我们详细讲解了线性回归的问题,并且最后通过梯度下降算法拟合了一条直线,从而使得这条直线尽可能的切合数据样本集,已到达模型损失值最小的目的. 在本篇文章中,我们主要是手撕 ...
- 如何在R语言中使用Logistic回归模型
在日常学习或工作中经常会使用线性回归模型对某一事物进行预测,例如预测房价.身高.GDP.学生成绩等,发现这些被预测的变量都属于连续型变量.然而有些情况下,被预测变量可能是二元变量,即成功或失败.流失或 ...
- 【机器学习实战】第5章 Logistic回归
第5章 Logistic回归 Logistic 回归 概述 Logistic 回归虽然名字叫回归,但是它是用来做分类的.其主要思想是: 根据现有数据对分类边界线建立回归公式,以此进行分类. 须知概念 ...
随机推荐
- nohup程序后台执行
Linux常用命令,用于不挂断的执行程序. nohup命令:如果你正在运行一个进程,而且你觉得在退出帐户时该进程还不会结束,那么可以使用nohup命令.该命令可以在你退出帐户/关闭终端之后继续运行相应 ...
- JS核心系列:浅谈函数的作用域
一.作用域(scope) 所谓作用域就是:变量在声明它们的函数体以及这个函数体嵌套的任意函数体内都是有定义的. function scope(){ var foo = "global&quo ...
- php批量删除
php批量删除可以实现多条或者全部数据一起删除 新建php文件 显示数据库中内容: <table width="100%" border="1" cell ...
- npm 使用小结
本文内容基于 npm 4.0.5 概述 npm (node package manager),即 node 包管理器.这里的 node 包就是指各种 javascript 库. npm 是随同 Nod ...
- LINQ to SQL Select查询
1. 查询所有字段 using (NorthwindEntities context = new NorthwindEntities()) { var order = from n in contex ...
- 【手记】注意BinaryWriter写string的小坑——会在string前加上长度前缀length-prefixed
之前以为BinaryWriter写string会严格按构造时指定的编码(不指定则是无BOM的UTF8)写入string的二进制,如下面的代码: //将字符串"a"写入流,再拿到流的 ...
- [LintCode]——目录
Yet Another Source Code for LintCode Current Status : 232AC / 289ALL in Language C++, Up to date (20 ...
- 真假4K电视验证:一张图足矣
国庆期间笔者逛了一下电视卖场,考虑到国内电视台以及宽带的情况,1080P至少还能用十年,所以只想要个2k电视就够了.然而事与愿违,卖场中八成的都是4k电视,清一色的4k电视让人眼花缭乱.难道4k面板技 ...
- 浅谈Web自适应
前言 随着移动设备的普及,移动web在前端工程师们的工作中占有越来越重要的位置.移动设备更新速度频繁,手机厂商繁多,导致的问题是每一台机器的屏幕宽度和分辨率不一样.这给我们在编写前端界面时增加了困难, ...
- cesium核心类Viewer简介
1.简单描述Viewer Viewer类是cesium的核心类,是地图可视化展示的主窗口,cesium程序应用的切入口,扮演必不可少的核心角色. 官网的英文解析如下: A base widget fo ...