Kafka核心概念(转)
转自:https://blog.csdn.net/liyiming2017/article/details/82805479
1、Kafka集群结构
实际上kafka的结构图是有些区别的,现在我们看下面的图:
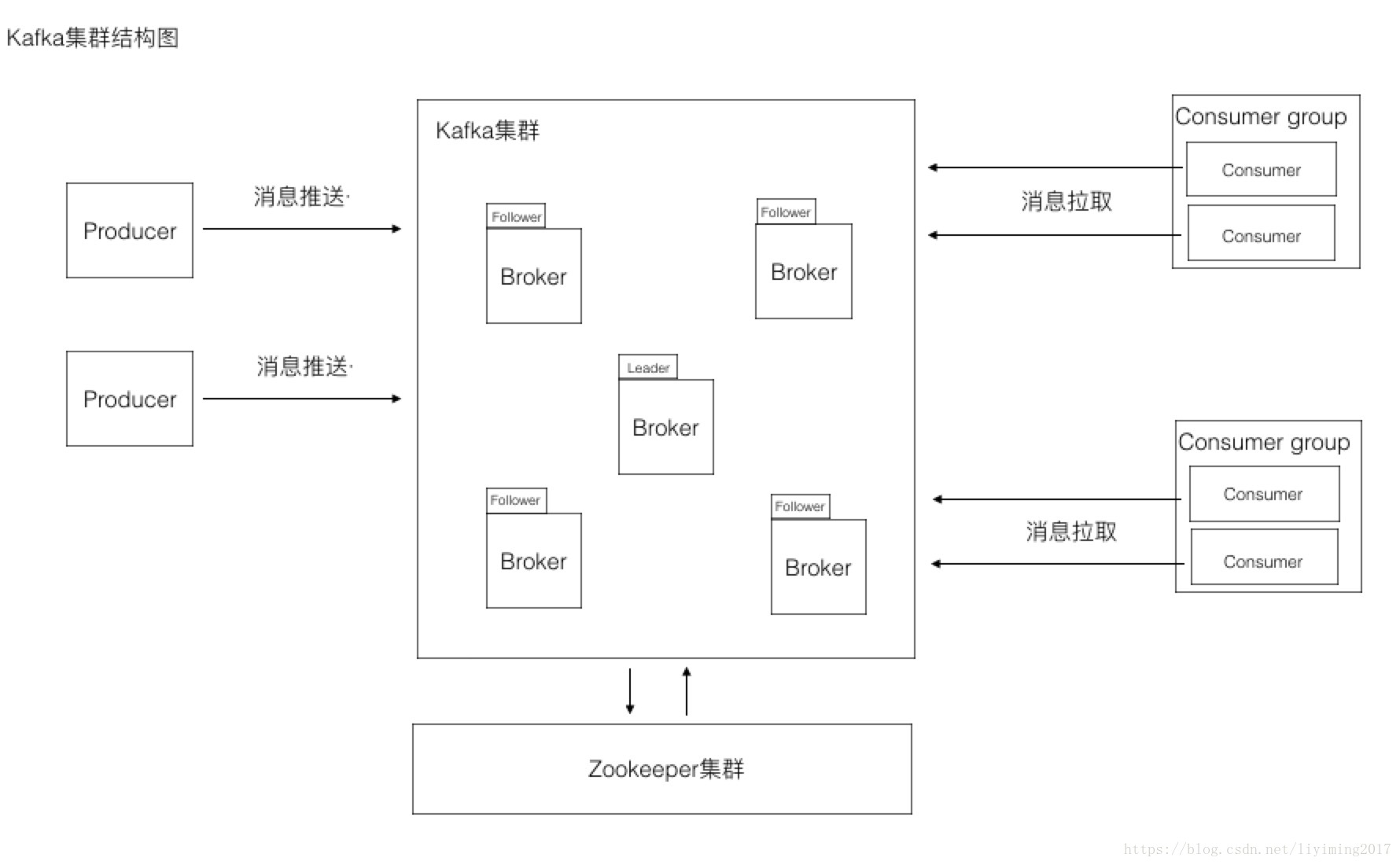
producer和consumer想必大家都很熟悉,一个生产消息,一个消费掉消息。这里就不再做太多解释。
此图和第一张图可以看到有几个区别:
1、多了zookeeper集群,通过前几章的学习我们已经知道kafka是配合zookeeper进行工作的。
2、kafka集群中可以看到有若干个Broker,其中一个broker是leader,其他的broker是follower
3、consumer外面包裹了一层Consumer group。
我们先讲解一下Broker和consumer group的概念,以及Topic。
Broker
一个Borker就是Kafka集群中的一个实例,或者说是一个服务单元。连接到同一个zookeeper的多个broker实例组成kafka的集群。在若干个broker中会有一个broker是leader,其余的broker为follower。leader在集群启动时候选举出来,负责和外部的通讯。当leader死掉的时候,follower们会再次通过选举,选择出新的leader,确保集群的正常工作。
Consumer Group
Kafka和其它消息系统有一个不一样的设计,在consumer之上加了一层group。同一个group的consumer可以并行消费同一个topic的消息,但是同group的consumer,不会重复消费。这就好比多个consumer组成了一个团队,一起干活,当然干活的速度就上来了。group中的consumer是如何配合协调的,其实和topic的分区相关联,后面我们会详细论述。
如果同一个topic需要被多次消费,可以通过设立多个consumer group来实现。每个group分别消费,互不影响。
通过本节学习,我们从全局的层面了解了kafka的结构,接下来我们会深入到kafka内部,来看看它是怎么工作的。
Topic
kafka中消息订阅和发送都是基于某个topic。比如有个topic叫做NBA赛事信息,那么producer会把NBA赛事信息的消息发送到此topic下面。所有订阅此topic的consumer将会拉取到此topic下的消息。Topic就像一个特定主题的收件箱,producer往里丢,consumer取走。
2、Kafka核心概念简介
kafka采用分区(Partition)的方式,使得消费者能够做到并行消费,从而大大提高了自己的吞吐能力。同时为了实现高可用,每个分区又有若干份副本(Replica),这样在某个broker挂掉的情况下,数据不会丢失。
接下来我们详细分析kafka是如何基于Partition和Replica工作的。
分区(Partition)
大多数消息系统,同一个topic下的消息,存储在一个队列。分区的概念就是把这个队列划分为若干个小队列,每一个小队列就是一个分区,如下图:
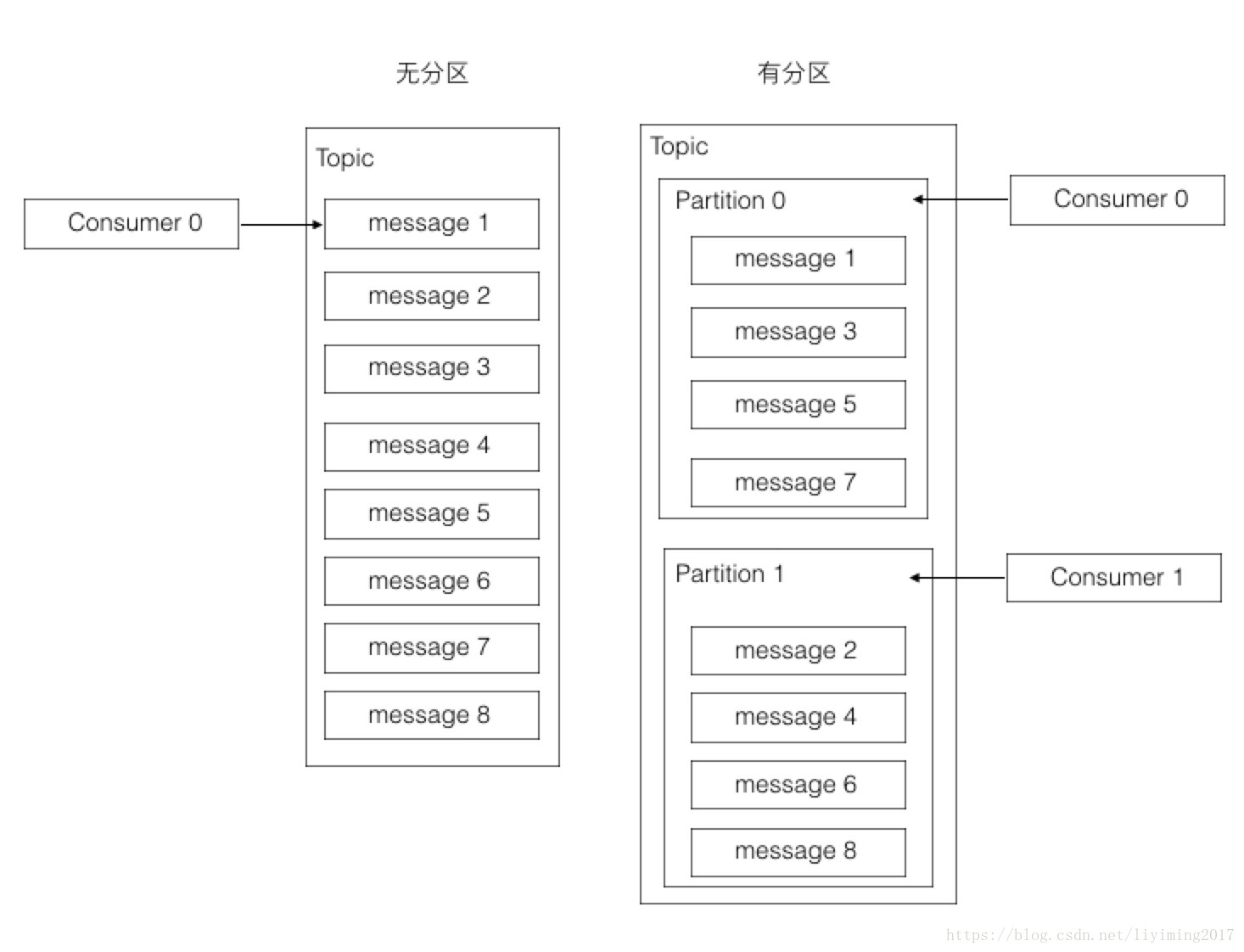
这样做的好处是什么呢?其实从上图已经可以看出来。无分区时,一个topic只有一个消费者在消费这个消息队列。采用分区后,如果有两个分区,最多两个消费者同时消费,消费的速度肯定会更快。如果觉得不够快,可以加到四个分区,让四个消费者并行消费。分区的设计大大的提升了kafka的吞吐量!!
我们再结合下图继续讲解Partition。
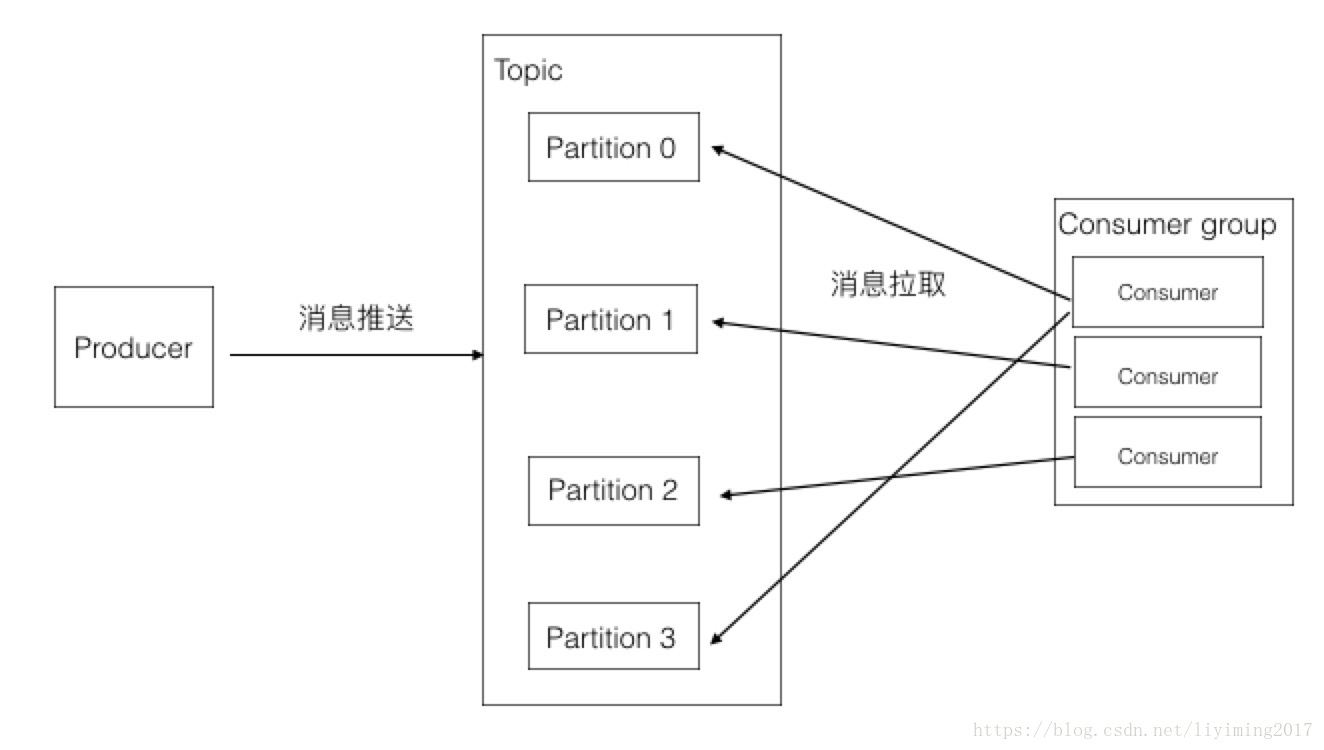
此图包含如下几个知识点:
1、一个partition只能被同组的一个consumer消费(图中只会有一个箭头指向一个partition)
2、同一个组里的一个consumer可以消费多个partition(图中第一个consumer消费Partition 0和3)
3、消费效率最高的情况是partition和consumer数量相同。这样确保每个consumer专职负责一个partition。
4、consumer数量不能大于partition数量。由于第一点的限制,当consumer多余partition时,就会有consumer闲置。
5、consumer group可以认为是一个订阅者的集群,其中的每个consumer负责自己所消费的分区
为了加深理解,我举个吃苹果的例子。
问题:有一篮子苹果,你如何把这一篮子苹果尽可能快的吃完?
办法一:
我一个人,一个一个苹果吃,如下图。这样显然很慢,我吃完一个才能拿下一个。
办法二:
我再找两个人来一块吃,第一个人拿走一个去吃,然后第二个人拿一个去吃,接着第三个人拿一个去吃,如此循环。速度肯定快了,但是三个人还是会排队等待。三个人排队时间可能很短,但是如果叫了100个人帮忙吃呢?会有大量时间消耗在排队上。
办法三:
我还是找两个人来一块吃,但我把苹果提前分到三个盘子里,每人分一个盘子,自己吃自己的,这样不但能三个人同时吃苹果,还无须排队。速度显然是最快的。
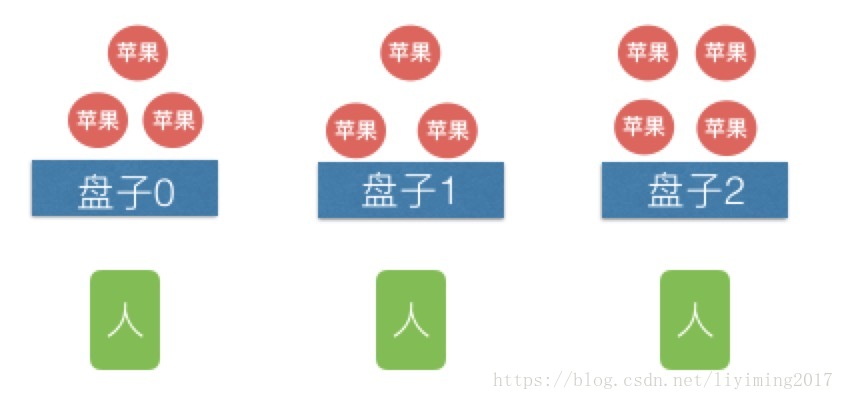
办法三正是kafka所采用的设计方式,盘子就是partition,每个人就是一个consumer,每个苹果就是一条message。办法三每个盘子中苹果的消费是有序的,而办法二的消费是完全无序的。
相信通过这个例子你一定能充分理解partition的概念,以及为什么kafka会如此设计。
关于partition暂时说到这里,接下来介绍副本。
副本(Replica)
提到副本,肯定就会想到正本。副本是正本的拷贝。在kafka中,正本和副本都称之为副本(Repalica),但存在leader和follower之分。活跃的称之为leader,其他的是follower。
每个分区的数据都会有多份副本,以此来保证Kafka的高可用。
Topic、partition、replica的关系如下图:
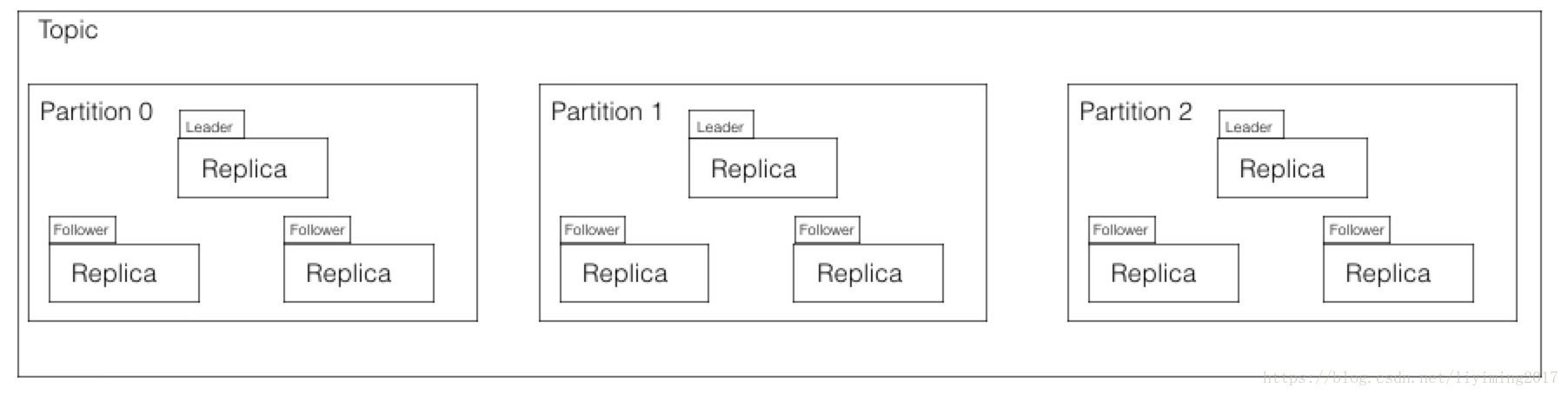
topic下会划分多个partition,每个partition都有自己的replica,其中只有一个是leader replica,其余的是follower replica。
消息进来的时候会先存入leader replica,然后从leader replica复制到follower replica。只有复制全部完成时,consumer才可以消费此条消息。这是为了确保意外发生时,数据可以恢复。consumer的消费也是从leader replica读取的。
由此可见,leader replica做了大量的工作。所以如果不同partition的leader replica在kafka集群的broker上分布不均匀,就会造成负载不均衡。
kafka通过轮询算法保证leader replica是均匀分布在多个broker上。如下图。
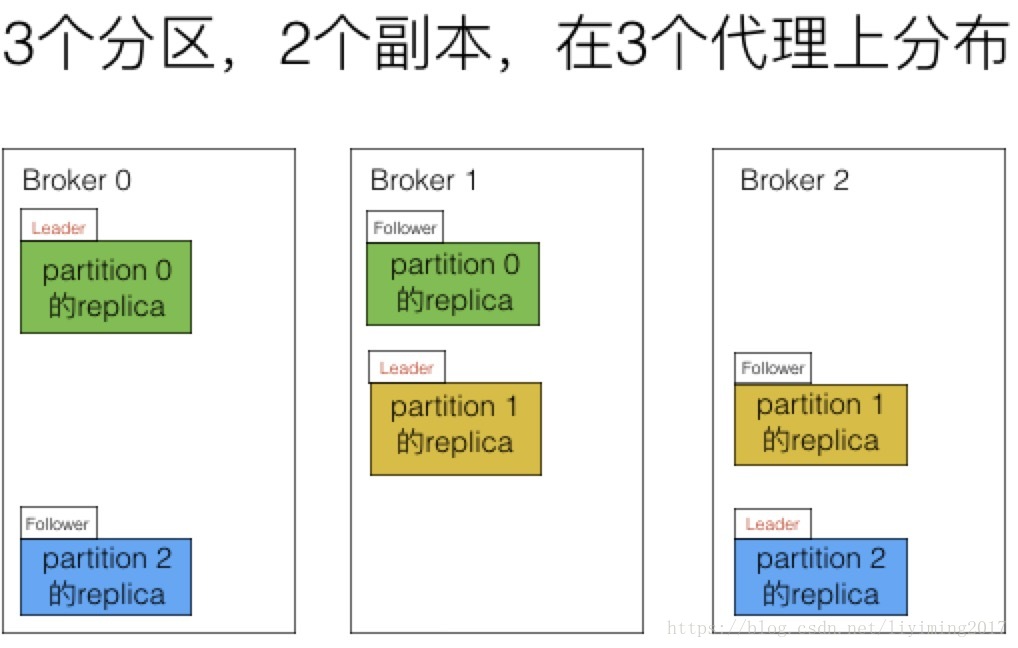
可以看到每个partition的leader replica均匀的分布在三个broker上,follower replica也是均匀分布的。
关于Replica,有如下知识点:
1、Replica均匀分配在Broker上,同一个partition的replica不会在同一个borker上
2、同一个partition的Replica数量不能多于broker数量。多个replica为了数据安全,一台server存多个replica没有意义。server挂掉,上面的副本都要挂掉。
3、分区的leader replica均衡分布在broker上。此时集群的负载是均衡的。这就叫做分区平衡
分区平衡是个很重要的概念,接下来我们就来讲解分区平衡。
分区平衡
在讲分区平衡前,先讲几个概念:
1、AR: assigned replicas,已分配的副本。每个partition都有自己的AR列表,里面存储着这个partition最初分配的所有replica。注意AR列表不会变化,除非增加分区。
2、PR(优先replica):AR列表中的第一个replica就是优先replica,而且永远是优先replica。最初,优先replica和leader replica是同一个replica。
3、ISR:in sync replicas,同步副本。每个partition都有自己的ISR列表。ISR是会根据同步情况动态变化的。
最初ISR列表和AR列表是一致的,但由于某个节点死掉,或者某个节点的follower replica落后leader replica太多,那么该节点就会被从ISR列表中移除。此时,ISR和AR就不再一致
接下来我们通过一个例子来理解分区平衡。
1、根据以上信息,一个拥有3个replica的partition,最初是下图的样子。
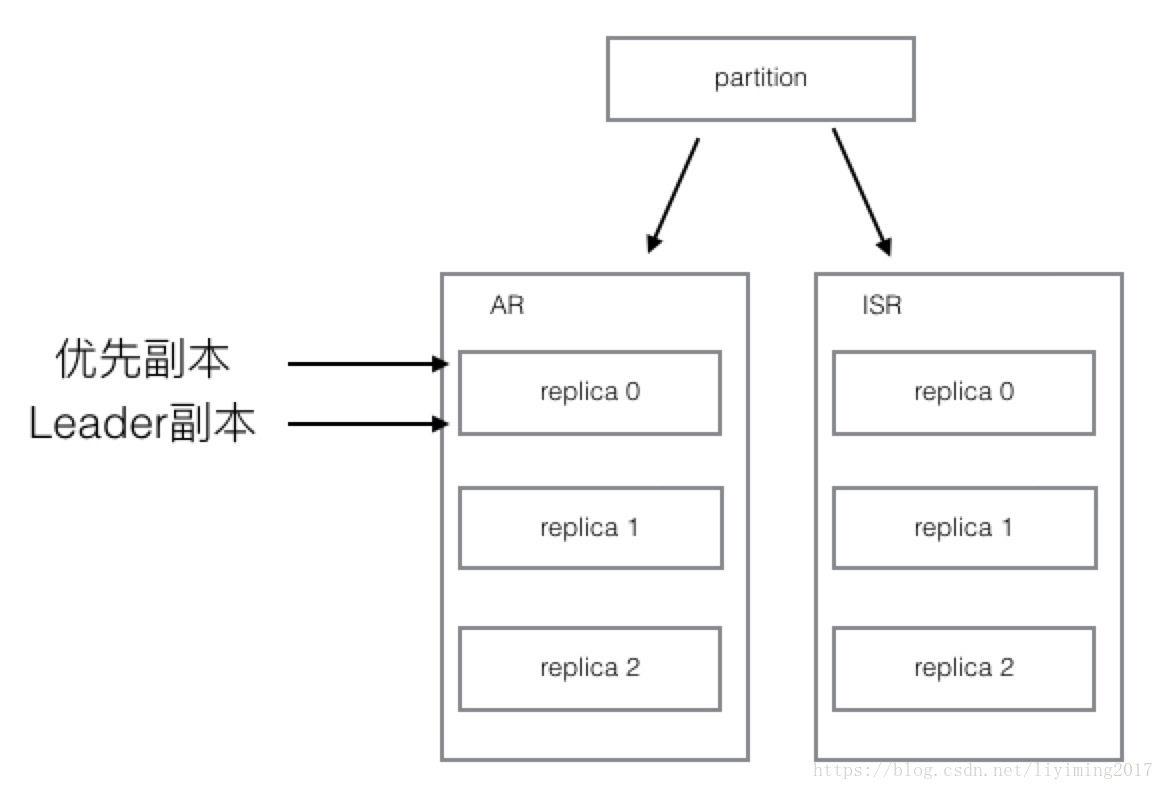
可以看到AR和ISR保持一致,并且初始时刻,优先副本和leader副本都指向replica 0.
2、接下来,replica 0所在的机器下线了,那么情况会变成如下图所示:
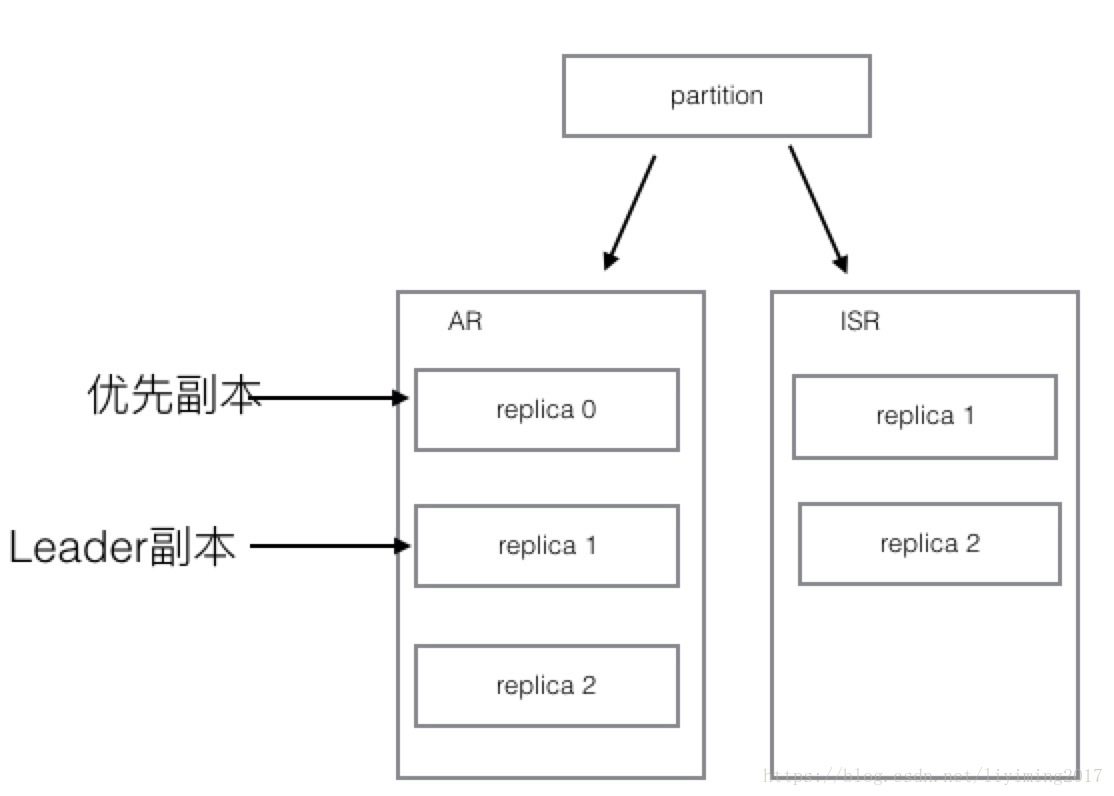
可以看到replica 0已经从ISR中移除掉了。同时,由于重新选举,leader副本变成了replica 1,而优先副本还是replica 0。优先副本是不会改变的。
由于最初时,leader副本在broker均匀分布,分区是平衡的。但此时,由于此partition的leader副本换成了另外一个,所以此时分区平衡已经被破坏。
3、replica 0所在的机器修复了,又重新上线,情况如下图:
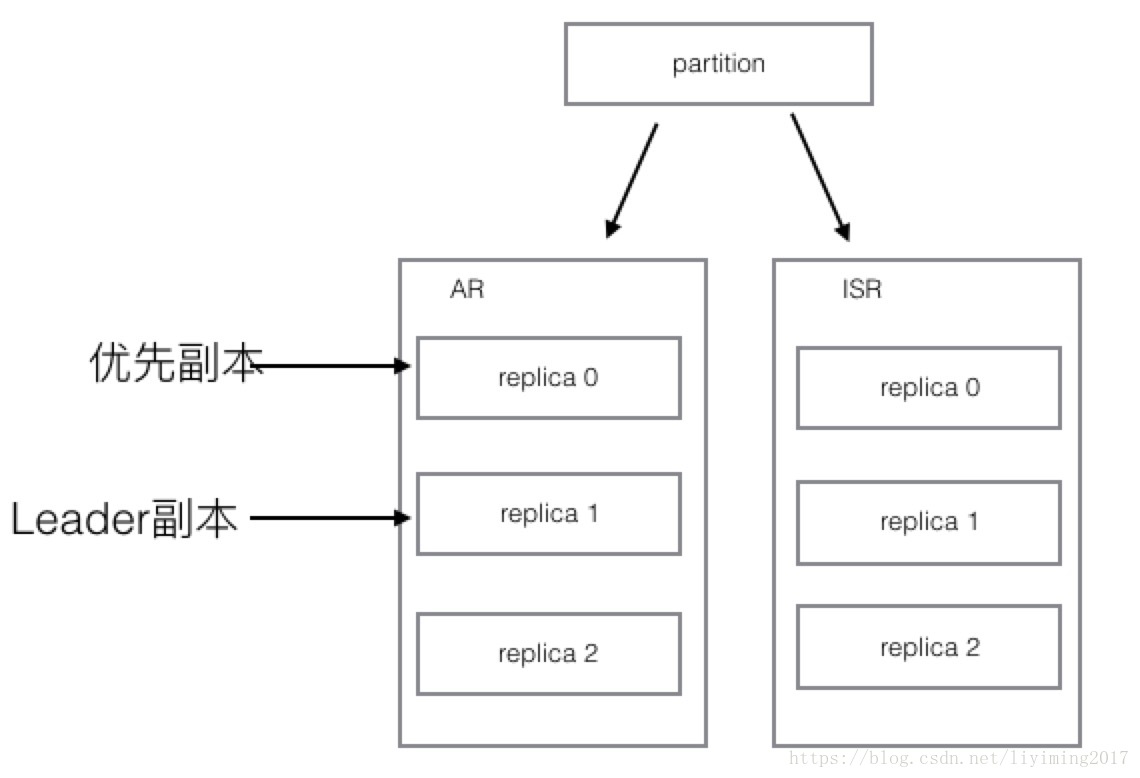
可以看到replica 0重新回到ISR列表中,不过此时他没能恢复leader的身份。只能作为follower当一名小弟。
此时分区依旧是不平衡的。那是否意味着分区永远都会不平衡下去呢?不是的。
4、kafka会定时触发分区平衡操作,也可以主动触发分区平衡。这就是所谓的分区平衡操作,操作完后如下图。
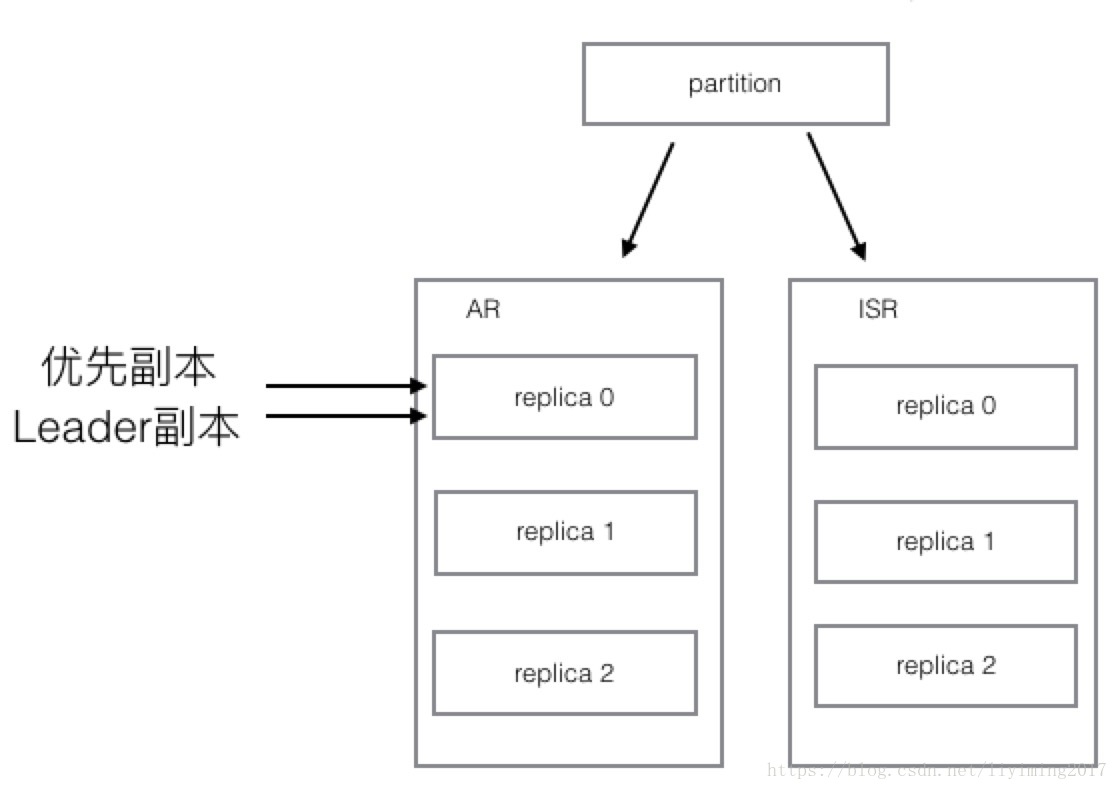
可以看到此时leader副本通过选举,会重新变回来replica 0,因为replica 0是优先副本,其实优先的含义就是选择leader时被优先选择。这样整个分区又回到了初始状态,而初始时,leader副本是均匀分布的。此时已经分区平衡了。
由此可见,分区平衡操作就是使leader副本和优先副本保持一致的操作。可以把优先副本理解为分区的平衡状态位,平衡操作就是让leader副本归位。
Partition的读和写
通过之前的学习,我们知道topic下划分了多个partition,消息的生产和消费最终都是发生在partition之上。下图是一个三个partition的topic的读写示意。
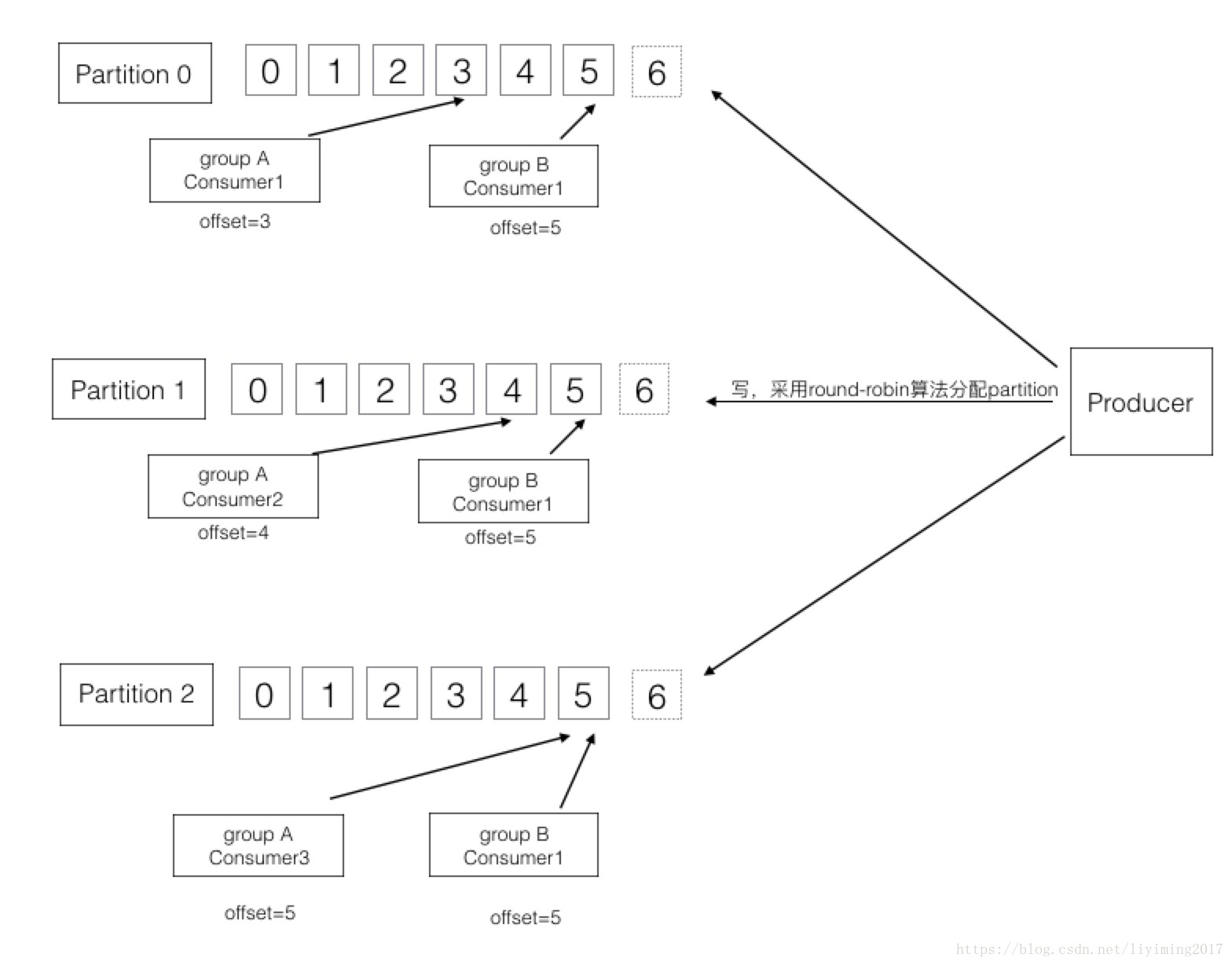
我们先看右边的producer,可以看到写的时候,采用round-robin算法,轮询往每个partition写入。
而在消费者端,每个consumer都维护一个offset值,指向的是它所消费到的消息坐标。
我们先看group A的三个consumer,他们分别独立消费不同的三个partition。每个consumer维护了自己的offset。
再结group B,可以看到两个group是并行消费整个topic,同一条消息会被不同group消费到。
此处有如下知识点:
1、每个partition都是有序的不可变的。
2、Kafka可以保证partition的消费顺序,但不能保证topic消费顺序。
3、无论消费与否,保留周期默认两天(可配置)。
4、每个consumer维护的唯一元数据是offset,代表消费的位置,一般线性向后移动。
5、consumer也可以重置offset到之前的位置,可以以任何顺序消费,不一定线性后移。
Kafka核心概念(转)的更多相关文章
- Kafka 基础概念及架构
一.Kafka 介绍 Kafka是⼀个分布式.分区的.多副本的.多⽣产者.多订阅者,基于zookeeper协调的分布式⽇志系统(也可以当做MQ系统),常⻅可以⽤于web/nginx⽇志.访问⽇志,消息 ...
- ElasticSearch学习笔记-01 简介、安装、配置与核心概念
一.简介 ElasticSearch是一个基于Lucene构建的开源,分布式,RESTful搜索引擎.设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便.支持通过HTTP使用JSON进 ...
- Zookeeper与Kafka基础概念和原理
1.zookeeper概念介绍 在介绍ZooKeeper之前,先来介绍一下分布式协调技术,所谓分布式协调技术主要是用来解决分布式环境当中多个进程之间的同步控制,让他们有序的去访问某种共享资源,防止造成 ...
- Spark Streaming核心概念与编程
Spark Streaming核心概念与编程 1. 核心概念 StreamingContext Create StreamingContext import org.apache.spark._ im ...
- Kafka学习(三)-------- Kafka核心之Cosumer
了解了什么是kafka( https://www.cnblogs.com/tree1123/p/11226880.html)以后 学习核心api之消费者,kafka的消费者经过几次版本变化,特别容易混 ...
- Spring Cloud Stream 核心概念
Spring Cloud Stream简介 Spring cloud stream是一个构建与Spring Boot和Spring Integration之上的框架,方便开发人员快速构建基于Messa ...
- Kafka到底有几个Offset?——Kafka核心之偏移量机制
Kafka是由LinkIn开源的实时数据处理框架,目前已经更新到2.3版本.不同于一般的消息中间件,Kafka通过数据持久化和磁盘读写获得了极高的吞吐量,并可以不依赖Storm,SparkStre ...
- 轻松理解 Kubernetes 的核心概念
Kubernetes 迅速成为云环境中软件部署和管理的新标准. 与强大的功能相对应的是陡峭的学习曲线. 本文将提供 Kubernetes 的简化视图,从高处观察其中的重要组件,以及他们的关联. 硬件 ...
- Nifi简介及核心概念整理
简介 Apache NiFi 是一个易于使用.功能强大而且可靠的数据拉取.数据处理和分发系统,用于自动化管理系统间的数据流. 它支持高度可配置的指示图的数据路由.转换和系统中介逻辑,支持从多种数据源动 ...
随机推荐
- CH1803 City Game
题意 这片土地被分成NM个格子,每个格子里写着'R'或者'F',R代表这块土地被赐予了rainbow,F代表这块土地被赐予了freda. 现在freda要在这里卖萌...它要找一块矩形土地,要求这片土 ...
- 关于python中的循环
参考下面这一篇: http://www.cnblogs.com/vamei/archive/2012/05/30/2526357.html 其中用range的方式最好!
- (转)如何获得当前ListVIew包括下拉的所有数据?
ListView listView = activity.getListView();获取的仅仅是当前屏幕显示的list,但是具有下拉信息,不在当前屏幕,但是下拉显示的数据无法或得到.谁知道如何获得当 ...
- callback&&callback()
如果存在回调函数就执行!这是利用了 JS &&符号的一个小技巧&& 符号在前面为假时就不会执行后面的语句了所以这个就相当于 if(callback){ callback ...
- Unit01: Spring简介 、 Spring容器 、 Spring IOC
Unit01: Spring简介 . Spring容器 . Spring IOC Spring (1)Spring是什么? Spring是一个开源的用来简化应用开发的框架. (2)Spring的特点? ...
- SPUtils
public class SPUtils { /** * 保存在手机里的SP文件名 */ public static final String FILE_NAME = "my_sp" ...
- flv格式详解+实例剖析
简介 FLV(Flash Video)是现在非常流行的流媒体格式,由于其视频文件体积轻巧.封装播放简单等特点,使其很适合在网络上进行应用,目前主流的视频网站无一例外地使用了FLV格式.另外由于当前浏览 ...
- Android UI一些技巧
(1)去掉EditText的背景颜色 android:background="@null" (2)ListView 修改某行的值,因为一些功能逻辑,需要修改ListView某行的 ...
- Eclipse中设置JDK、${user}变量
为eclipse设置jdk方法: 两个方法: 1.设置PATH路径-eclipse自动会查找! 2.在快捷方式中加上参数:-VM java虚拟机路径 Eclipse中设置${user}变量 在Ecli ...
- HDU-3661-Assignments
/* Assignments Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Tota ...