DAVINCI开发原理
本文中约定:
[host] 表示主机PC机Linux
[target] 表示目标板Linux
DAVINCI开发原理之一----ARM端开发环境的建立(DVEVM)
1. 对DAVINCI平台,TI在硬件上给予双核架构强有力的支撑,在DSP端用DSP/BIOS来支持音视频算法的运行,在ARM端用MontaVista Linux(MV)来支持其对外设的管理.对于ARM与DSP之间的数据交互,则用Code Engine和Codec Server来加以管理
2. 在DAVINCI的开发程序分为codec部分和应用程序部分.开发应用程序前,需要搭建软硬件开发环境.硬件环境包括:DAVINCI开发板DVEVM(含TMS320DM6446的DSP和ARM的双核芯片及丰富的外设)、CCD摄像头、LCD显示器、硬盘(如果不用NFS来映射文件系统,则可通过本地的硬盘上的文件系统)、串口线.其次是与DVEVM配套的ARM端软件开发环境.环境搭建好后,需要对Linux主机进行相关配置才能使用DVEVM开发板.对嵌入式系统开发,开发板上首先需要一个bootloader来初始化硬件,然后会通过bootloader的参数设置来启动系统.如启动bootloader后,通过tftp来下载MV Linux内核镜像文件到内存运行内核,然后通过NFS来启动Linux主机上的目标文件系统,并通过DHCP服务器来为开发板分配IP地址,这样就可以进行基于IP的网络视频应用开发.下面配置ARM端软件开发环境的各个模块
3. TFTP服务器的配置
检查Linux是否安装了TFTP服务
[host]$ rpm -qa|grep tftp
tftp-0.32-
tftp-server-0.32-
否则从Linux安装盘重新用rpm安装tftp相关模块,并打开tftp的服务.
4. 配置NFS服务器
NFS是一种在网络上的机器间共享文件的方法,文件就如同位于客户的本地硬盘驱动器上一样.可以将之看成是一种文件系统的格式,Red Hat Linux既可以是NFS服务器也可以是NFS客户,这意味着它可以把文件系统导出给其他系统,也可以挂载从其他机器上导入的文件系统.DVEVM的NFS主要用来把主机Linux上的MV Linux映射到DVEVM板上去,使得DVEVM在自身无文件系统的情形下,可以正常的执行各种任务.
5. DHCP服务器的配置
配Linux主机和DVEVM的IP.比较简单.
6. bootloader的烧写
是操作系统内核运行前运行的一段程序,通过这段程序来初始化硬件设备、建立内存空间的映射表,从而将系统的软硬件环境初始化,以便为最终调用操作系统内核准备正确的环境,烧写前准备如下软硬件设施.
软件部分:
- U-Boot image(即文件u-boot.bin);
- 文件falshwriter.out;
- CCS 3.2或以上版本
硬件部分:
- 连接到DAVINCI DVEVM的JTAG硬件仿真器;
- 一条连接PC与DACINCI DVEVM的RS323的串口线;
- 跳线J4应该被标识为"CS2 SELECT",并确认"FLASH"被选择;
- 使S3的1和2设置为OFF
准备好上述软硬环境后,即可以开始烧写了,烧写例程见附录(U-boot example.rar),烧写过程很简单,类似emulation.
7. 设置DVEVM的启动参数
[target]#setenv bootargs console=ttyS0,115200n8 noinitrd rw ip=......
详细参数说明见U-BOOT说明文档.
至此,我们ARM端的初步开发环境建立起来了,可以做一些比较简单的开发程序,如例:
[host]$mkdir ~/workdir/filesys/ opt /hello
[host]$cd ~/workdir/filesys/ opt /hello
[host]$vi hello.c
#include<stdio.h>
int main() {
printf("hello world! welcome to DAVINCI test");
return ; }
[host]$arm_v5t_le-gcc hello.c -o hello /*保存后,用交叉编译工具arm_v5t_le-gcc编译程序:*/
这里假设已经将PC机linux中~/workdir/filesys/目录通过nfs挂载为目标板文件系统了.
[target]#cd /opt/hello /*编译生成二进制文件hello后,启动DAVINCI DVEVM板,通过超级终端运行下命令*/
[target]#./hello
DAVINCI开发原理之二----DSP端开发环境的建立(DVSDK)
在一中只是建立了DVEVM的开发环境,只能进行ARM端程序的开发,如果需要开发DSP端的算法就还需要安装使用DVSDK,该软件包包括如下内容:
- Monta Vista Linux Profession Edition v4:相对于DVEVM发布的montavista linux demo版本来说,这个完全专业版包含了DevRocket IDE和相关服务支持,要全面的多;
- DM6446x SoC Analyzer(DSA):这个软件是安装在windows OS上的,用来观测分析DSP端和ARM上运行中程序的负载、资源冲突以及性能瓶颈等,不是一定得要,我没有使用过,好像是要另外付费的;
- DSP/BIOS for linux:DSP/BIOS是一个可升级的实时DSP内核,linux版本相对于window版本来说,不包含相应的图形分析工具;
- TI Codegen Tools for linux:与DSP相关的一些编译、连接工具;
- Framework Components:主要是用来支持DSP端算法开发的一些模块,能够管理符合xDAIS标准的算法模块,分配内存和DMA资源.这些模块是被CE来使用的,但如果有必要在DSP端程序也可以使用它们;
- Digital Video Test Bench(DVTB):这是一个在ARM端运行,基于脚本语言的测试codec的应用程序.用户不需要写任何C代码就可以处理Linux I/O, codec API以及一些与线程有关的问题;
- CCS:运行在windows OS上的集成开发环境,用来开发基于DSP的应用程序和相关算法.
有了以上DVSDK相关套件,就可以构建DSP端的相关开发组建,其中Codec Engine Romote Server运行在DSP/BIOS上,而在RS中封装了相关算法,在算法的封装中要用到一些xDAIS的框架组件.DSP和GPP之间的通讯由DSP/BIOS Link来完成.
1. DVSDK的安装与配置
安装:linux下的操作,比较简单,只是要注意DVSDK的版本必须与DVEVM版本号一致.且最好把相关的DVSDK安装在dvevm_#_#_#下.
配置:在dvevm_#_#_#目录下的Rules.make文件控制了大部分的编译行为,该文件被dvevm_#_#_#目录及其一些子目录下的Makefile文件所包含,对DSP端应用程序的编译需要修改相应的文件,具体根据你实际DVSDK软件包的安装路径.里面要求指定DVEVM、CE、XDAIS、DSP LINK、CMEM、codec server、RTSC、FC、DSP/BIOS、linux kernel等等包的路径.
2. DVTB的安装和使用
数字视频测试平台(DVTB)是不用C代码而直接利用一些脚本语言来测试DSP端算法的工具.在DVSDK安装后,会在dvevm_#_#_#目录下有个dvtb的目录,就在此执行安装,然后到DSP的可执行目录下去运行(DSP的可执行目录下必须要有cmemk.ko, dsplink.ko等文件),如/nfshost/mydemos.
DVTB的命令语法如下:<Command> <class> <options>
通过DVTB命令,可以控制audio/vpbe/bpfe等外设或各音视频编解码器,来完成一些测试工作.具体安装过程和命令使用方法可以参考:\opt\dvevm_#_#_#\dvtb_#_#\目录下文档.暂时还没有用到.
3. XDC(Express DSP Component)的配置
XDC是用来编译和打包的工具,能够创建实时软件组件包RTSC(Real Time Software Component).与其他编译工具一样,它能根据源文件和库文件编译生成可执行文件.不同的是它能够自动的进行性能优化和版本控制.XDC还能够根据所提供的配置脚本语言产生代码,这一特性在编译如编解码器、服务器和引擎等可执行程序时尤为重要.
XDC的调用语法格式:XDC <target files> <XDCPATH> <XDCBUILDCFG>
target files:指编译产生的目标文件.可以通过命令脚本来指定要产生哪些目标文件;
XDCPTH: 编译时所要查找的目录;
XDCBUILDCFG:由"config.bld"文件指定,包含了与平台有关的编译指令.后面细说.
以上命令模式可能在参数过多是很复杂,通常把它写成shell脚本来运行.
与XDC相关的三个配置文件:
package.xdc:主要包含与包package有关的信息:依赖信息、模块信息、版本信息.由自己提供.
package.bld:主要作用是定义一个包应该如何被编译.文件内容用Javascript来描述.其中包含目标平台集的定义[MVArm9,Linux86]、编译版本的定义[release]、确定源文件集、生成的可执行文件信息等等.
这两个文件都是在server目录下,可见每个codec都有自己的package信息描述文件,然后XDC根据再依之生成一个package包.
config.bld:这个文件处在codec_engine_##目录下,为各个codec所共有,它主要定义了与平台有关的特性,包含如下几部分:DSP Target、Arm Target、Linux Host Target、Build Targets、Pkg.attrs.Profile、Pkg.lib等具体信息.通常都是基于TI提供的模板对这三个配置文件做修改.
DAVINCI开发原理之三----达芬奇编解码引擎Codec Engine(CE)
DaVinci是DSP和ARM双核架构的SOC芯片.对芯片与外界的交互通过ARM端的Montavista Linux和相关驱动与应用程序来管理,DSP端只处理编解码相关的算法.DSP和ARM之间的通讯和交互是通过引擎(Engine)和服务器(Server)来完成的.本节只讲述编解码引擎CE.
1. 核心引擎API
从应用来说,CE就是用来调用xDAIS算法的一组API的集合,用户可以通过这些API来实例化和调用xDAIS算法.达芬奇提供了一组VISA接口,用于给应用程序与xDM兼容的xDAIS算法相交互.需要注意,不管算法是运行在本地(ARM端),还是远端(DSP端),也不管硬件体系是只有ARM或是只有DSP或两者都有,也不管OS是Linux、VxWorks、DSP/BIOS,还是WinCE,对算法的接口调用都是一致的.这点通过引擎的配置文件*.cfg可以看出来,而且通过配置文件可以决定自己的codec是运行在ARM端还是DSP端.
CE包括核心引擎API和VISA API,核心引擎API相关接口模块为:初始化模块(CERuntime_)、CE运行时模块(Engine_)、抽象层内存模块(Memory_); VISA API的接口模块我们常用的有:视频编码接口(VIDENCx_)、视频解码接口(VIDDECx_)、音频编码接口(AUDENCx_)、音频解码接口(AUDDECx_),各模块分别包含在对应的头文件中.
应用程序必须使用CE的核心引擎的三个相关模块去打开和关闭编解码引擎的实例. 需要注意的是引擎的句柄是非线程保护的,对单独使用CE的每个线程来说,必须执行Engine_open并管理好自己的引擎句柄,而对多线程应用来说,也可以顺序的访问一个共享的引擎实例,我们目前采用的就是后者,只定义了一个引擎句柄,多个解码器共用.编解码引擎同时还提供相关的API用以访问系统的内存使用状况和CPU的负载信息,接口如下:
- Engine_open: /*打开一个编解码引擎*/
- Engine_close: /*关闭一个编解码引擎,通常是在删除算法实例后调用之来释放相关资源*/
- Engine_getCpuLoad: /*获取CPU的使用百分比*/
- Engine_getLastError: /*获取最后一个失败操作所引发的错误代码*/
- Engine_getUsedMem: /*获取内存使用状况具体定义引擎所需要包含的头文件和如何定义和使用引擎可参考工程实例example_dsp1*/
目前我们都是多个解码器共用一个引擎句柄,比如:
static String engineName = "videodec"; /*定义引擎名字,ceapp.cfg配置文件中会用到*/
Engine_Handle ceHandle_264 = NULL; /*创建一个264解码器引擎句柄*/
Engine_Error errorcode; /*用于返回引擎打开的状况信息,不同返回值代表的意义可参考相应头文件*/
ceHandle_264 = Engine_open(engineName, NULL, &errorcode);
根据上述理解,我觉得如果多个线程需要单独使用自己的引擎时,应该可以定义多个引擎名字,创建多个引擎句柄,此时每个线程必须单独执行Engine_open(),并管理好自己的引擎句柄.
2. VISA API
创建一个算法实例:*_create()
编解码引擎ceHandle_264创建完毕后,可以通过它来创建自己的算法实例,需要调用*_create(),其中*可以是VIDEO或AUDIO的相应编解码模块的名字,例如:
static String decoderName = "h264dec";/*定义解码模块名字,用于标识算法名字,ceapp.cfg会用到*/
VIDDEC_Handle 264Handle; /*创建解码器句柄*/
264Handle = VIDDEC_create(ceHandle_264, decoderName, NULL); /*在引擎上分配和初始化解码器,第三个参数可以用来初始化算法的相关参数,这些参数控制着算法的各种行为,参数结构依VISA中编码或解码器的不同而不同,具体结构内容可参考头文件*/
关闭一个算法实例:*_delete()
VIDDEC_delete(264Handle); /*注意:只有当与算法相关的内存片清除后,才可以调用之删除算法实例*/
控制一个算法实例:*_control()
VIDDEC_control(264Handle, XDM_SETPARAME, dynamicParamsPtr, &encStatus);
第一个参数是已经打开的算法实例句柄; 第二个参数是一整型的command id,它定义在xdm.h中; 第三个参数是需要动态改变算法的参数,比如在create中第三个参数已经为解码器初始化了一些参数,在这里可以对之做修改,但修改有条件,其具体结构内容可以参考头文件; 第四个参数是一个结构体变量,不同模块具有不同的结构,具体参考头文件.
通过算法实例处理数据:*_process()
status = VIDDEC_process(264Handle &inBufDesc,&outBufDesc, &inArgs, &outArgs);
第二和第三个参数是XDM_BufDesc类型的结构体,其中包含了内存片段的数目和开始地址以及长度信息;第四第五个参数分别为算法实例提供输入和输出地址.
上述所有结构体都可以在:\opt\dvevm_#_#\xdais_#_#\packages\xdais\dm下面找到,并可以做修改.只是现在还不知道这些结构体具体怎么使用.
3. 编译"一个"编解码引擎----引擎配置文件(ceapp.cfg)
引擎的配置文件是以*.cfg文件形式存储的,目前我们工程里面含两个*.cfg:app里面含ceapp.cfg,里面包含对引擎的配置,还有一个是video_copy.cfg,在server下,是对服务器的配置文件之一,后面会讲到.ceapp.cfg通过Makefile文件使用package.xdc来产生一个*.c文件和一个链接命令脚本文件.一个引擎配置文件包含如下内容:引擎的名字以及包含在引擎内的编解码器和它们的名字.从这里可以看出,前面定义"h264dec"等名字的作用,用于应用程序中标识算法类别,也可以看出一个引擎是可以由几个编解码器模块共用的.我们以ceapp.cfg文件的内容为例说明配置参数的含义:
/*--------------set up OSAL----------------*/
var osalGlobal = xdc.useModule('ti.sdo.ce.osal.Global');
osalGlobal.runtimeEnv = osalGlobal.DSPLINK_LINUX;
注:这两句是设置全局的模块使配置脚本生效,然后是设置引擎的运行环境,即需要用的DSP/BIOS Link和Linux OS).
/*--------------get codec modules;i.e.implementation of codecs-------*/
var H264DEC = xdc.useModule('codecs.h264dec.H264DEC');
注:设置需要用到的编解码器,即我们将要用到给定目录下的H264DEC.注意我们目前使用的都是codec目录下ti提供的videnc_copy,实际上我们可以修改的,另前面我们定义解码器的名字时用的小写的'h264dec',这里配置改成大写.
/*---------------Engine Cofiguation---------------*/
var Engine = xdc.useModule('ti.sdo.ce.Engine');
var demoEngine = Engine.create("videodec", [
{name:"h264dec", mod:H264DEC, local:false},
/* {name:"h264enc", mod:H264ENC, local:false} ... 如果有的话*/
]);
注:首先使ti.sdo.ce目录下的引擎可用,然后用create()创建一个引擎.每个引擎都有一个名字,这个名字会被开发人员用到(如打开引擎的时候,前面我们定义的引擎名字是"h264dec").create()的参数是一关于算法描述的数组,每个算法描述包含下面几个字段:
name:算法实例的名字,在标识算法时要用到,VIDEC_creat()等VISA API的参数,如前面定义264解码器名字"h264dec";
mod:用来标识实际的算法实现模块,通常就是name的大写,如H264DEC.
local:如果为真,算法实例在ARM端实现,否则通过codec server来创建DSP端的算法实例.
demoEngine.server = "./encodeCombo.x64P";
注:用于指明Codec Server.
DAVINCI开发原理之四----达芬奇编解码服务器(Codec Server)
编解码服务器(CS)就是一个二进制文件,它集成了编解码器,框架组件和一些系统代码,当CS运行在DSP上时,它使用了DSP/BIOS作为其内核.CS同时包括了对客户请求的相关DSP/BIOS线程.CS可以代表实际的DSP硬件、导入到DSP上的镜像文件以及正在运行的任务,其配置需要两个步骤:
通过TCF脚本语言配置DSP/BIOS;
通过XDC配置剩下的组件,比如:FC组件、DSP/BIOS Link、Codec Engine等.配置完成的服务器镜像文件是在引擎配置文件(ceapp.cfg)中使用的,如前所述的demoEngine.server = "./encodeCombo.x64P";
编译一个编解码服务器
CS镜像文件的创建过程是通过前面介绍的XDC工具来完成的,所不同的是,CS在创建时需要一个main.c和相关的BIOS配置脚本.tcf文件.
- tcf:脚本文件主要是对DSP/BIOS内核进行配置,如:定义DSP的内存映射,设置DSP的中断向量表,创建和初始化其他DSP/BIOS数据对象等,具体可参见video_copy.tcf,注意我在里面添了一个关于trace的参数配置是原来没有的;
- main.c:只要你的算法实现了XDM接口,就需要一个main.c的程序去初始化CE,然后用其他配置脚本来创建一个服务器镜像*.x64P. 在main.c里面除了调用CERuntime_init()初始化CE外,就是对于trace相关函数的初始化和处理,这部分暂时没有细究.另有一点值得注意,在这里可以实现对cache的重新配置,因为在tcf文件里面对cache的配置可能会不起作用,这是可以在这里以函数代码的方式来配,这点以前没有注意过.这里有点不明白的是,在ceapp_init()中已经做了一次CERuntime_init(),为何在CS处还要做一次?(我觉得是因为先编译CS,生成*.x64P,然后才编译app端,这样就可以理解成:只要你的算法实现了XDM接口,就需要对CE做初始化CERuntime_init(),而CS的编译是调用了经XDM封装后的codec生成的*.a64P的)
XDC相关文件:
- package.xdc
/*--------------声明包名-----------------*/
package server{}
(我们目前的.xdc是:package server.video.copy, 此即\server\video_copy\..xdc,应该无需改动)
- package.bld
声明所必须包含的包,链接命令脚本,tcf文件和一些源文件,定义编译属性、平台和对象等.
- server.cfg:这是CS配置的重点,说明如下.
/*第一部分:声明运行环境和各种编解码模块, 与CE.cfg类似*/
/*--------------set up OSAL----------------*/
var osalGlobal = xdc.useModule('ti.sdo.ce.osal.Global');
osalGlobal.runtimeEnv = osalGlobal.DSPLINK_BIOS;
注:这两句是设置全局的模块使配置脚本生效,然后是设置引擎的运行环境,即需要用的DSP/BIOS Link,与CE.cfg有点区别). /*---------------server Cofiguation---------------*/
var Server = xdc.useModule('tisdo.ce.Server');
Server.threadAttrs.stackSize = ;
Server.threadAttrs.priority = Server.MINPRI; /*--------------get codec modules;i.e.implementation of codecs-------*/
var H264DEC = xdc.useModule('codecs.h264dec.H264DEC'); //与CE.cfg同,注意H264DEC标识的使用. Server.algs = [
{name:"h264dec", mod:H264DEC,threadAttrs:{stackSize:,stackMemId:,priority:Server.MINPRI+} }, {...if have..},
]; /*第二部分:DSKT2 and DMAN3的配置:XDAIS算法内存和DMA的分配,参考配置文件*/
DAVINCI开发原理之五----定制编解码器的内存映射
主要是DDR的划分和tcf与DSPLINK的内存配置一致性问题,以及dsplink.ko的编译问题,这些我都已经编译过多次,基本没什么差异.需要注意的一点是,DAVINCI的DSP端是没有虚拟地址管理的,所有的程序直接操作平面地址空间.具体操作方式DAVINCI开发原理之四中有详细例子说明.
DAVINCI开发原理之六----引擎(CE)与服务器(CS)的工作原理
编解码引擎CE和服务器CS之间的关系可以比作客户机和应用服务器之间的关系,本质上是远过程调用思想在双核上的实现.
1. 远过程调用(RPC)的工作原理
远过程调用最初是用在C/S架构上进行互操作的一种机制,是OS中进程间通讯在网络环境中的延伸.其目的是使得应用程序在调用另一个远程应用程序(在另外一个节点上,或本节点上的另一个进程中)时,采用与本地调用相同的调用方式,就像本地进行的调用过程一样,如下图所示:
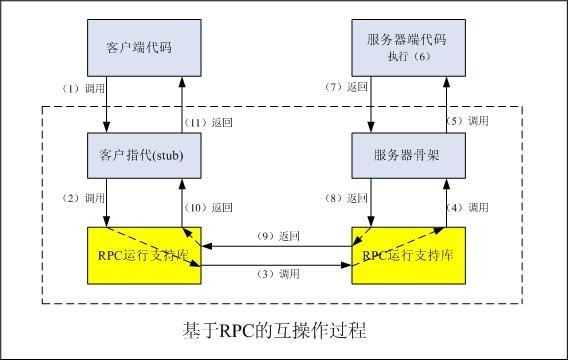
其过程如下:
- 客户按本地调用的方式,直接调用本地的客户指代(stub),客户指代具有与服务器相同的过程接口;
- 客户指代不进行任何逻辑处理,只是一个中介,因此它仅将客户的调用请求进行加工、打包,向低层通讯机制发出请求信息;
- 客户端通过低层通讯机制将消息传送给服务器端的通讯机制;
- 由于一个服务器节点上可能运行多个服务器程序,因此服务器端需要部分的解析消息,找出客户希望调用的服务器程序;
- 服务器骨架(skeleton)对消息进行解析,从中获得调用者的参数,然后调用服务器程序;
- 服务器程序执行相应的过程;
- 服务器程序将结果返回给服务器骨架;
- 服务器骨架将结果打包,向低层通信机制发出应答消息;
- 服务器端通讯机制将消息传送给客户端通信机制;
- 由于一个客户端节点上也可能有多个调用点,因此通信机制需要部分的解析返回的消息,找出消息应该返回给哪个应用程序,并将消息发送给对应的客户指代;
- 客户指代从消息中解析出结果,返回给客户程序.
从上过程分析可见,RPC过程中客户指代的主要工作包括:
- 建立客户与服务器之间的连接;
- 将客户的高层调用用语句打包为一条低层的请求消息(RPC的编排),然后向服务器发出请求信息;
- 等到服务器返回应答消息;
- 接收来自服务器的应答消息,并将来自低层的应答消息解析为可以返回的数据(RPC的还原);
- 将返回值传送给客户指代.
对应服务器骨架也包含上述类似的功能.
2. 引擎与服务器的通讯框架
在ARM端,对视频类程序来说,应用程序首先把采集到的原始图像信号,通过VISA接口调用相关的Codec存根函数,由存根函数调用相关的Engine API函数,也就是SPI(service provider interface)接口,但由于实际的Codec算法在远端(DSP端),所以必须由引擎把信号进行封装,通过OS抽象层与DSP Link通讯把打包后的数据发送出去,如下图所示:

数据进入DSP端后,服务器上的算法实例(codec)接收到相关的数据信息,但这时的信息是被封装过的,必须由服务器骨架对数据进行解析,从中获得调用者的VISA接口参数,然后调用相关的xDM Codec实例,数据的返回方法与之相逆.在这个过程中,ARM端看做客户机,DSP端看做服务器,把server看做服务区骨架,codec看做服务区上的应用程序.
3. 引擎与服务器的通讯细节实例
这里分析一个实际的调用代码的过程. 在视频类程序中,一般是通过像VIDDEC_process(a,b,c)这样的VISA接口函数来调用远端算法的.对内部的工作细节是:首先在应用程序(ARM端app.c)中调用VIDDEC_process(a,b,c)[ceapp_decodeBuf()调用VIDDEC_process(),这个调用只是客户端发送个接口信号],这里首先是调用引擎上的Engine API,也就是服务提供者接口(SPI)VIDDEC_p_process(a,b,c),从这可以看出在app.c中要有一次CERuntime_init()的调用.然后通过引擎CE的操作系统抽象层OSAL把参数a,b,c和调用信息VIDDEC_p_process()打包发送给DSPLink;然后通过DSPLink中转打好包的信息给DSP端的服务器骨架;最后服务器CS解析收到的信息包,由解析后的数据得知我们要调用VIDDEC_process()这一VISA API函数,并解析出所用参数为a,b,c[video_copy.c中调用VIDEC_TI_process(),这里的调用才是真正的远端服务器上执行算法].从这可以看出在server在编译时,main.c需要调用一次CERuntime_init().这一服务器骨架就知道如何调用本地(DSP端)的xDM算法以及其他方法了.这整个过程对用户来说是透明的,也就是说应用程序只需要调用Linux端的VISA API接口函数即可.接下来的内部工作由引擎CE和服务器CS来解决.数据从DSP端返回ARM端的过程与之相逆.如下图:
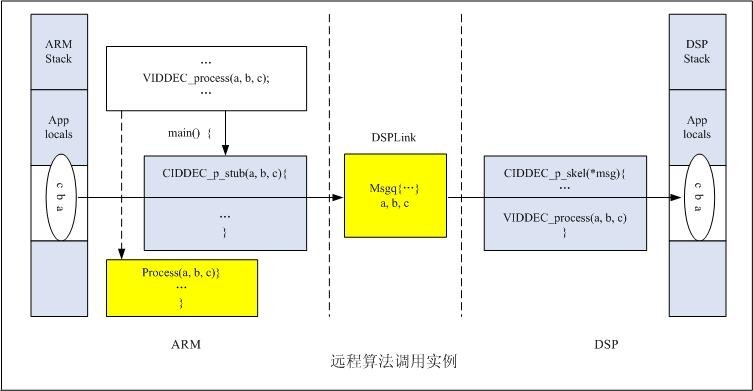
本文转自:http://blog.sina.com.cn/s/blog_5c427ab50100gye4.html
DAVINCI开发原理的更多相关文章
- Excel阅读模式/聚光灯开发技术序列作品之三 高级自定义任务窗格开发原理简述—— 隐鹤
Excel阅读模式/聚光灯开发技术序列作品之三 高级自定义任务窗格开发原理简述—— 隐鹤 1. 引言 Excel任务窗格是一个可以用来存放各种常用命令的侧边窗口(准确的说是一个可以停靠在类名为x ...
- Excel阅读模式/聚光灯开发技术之二 超级逐步录入提示功能开发原理简述—— 隐鹤 / HelloWorld
Excel阅读模式/聚光灯开发技术之二 超级逐步录入提示功能开发原理简述———— 隐鹤 / HelloWorld 1. 引言 自本人第一篇博文“Excel阅读模式/单元格行列指示/聚光灯开发技术要 ...
- Qt项目简易开发原理及常见问题解决
一.资源下载地址 https://www.aliyundrive.com/s/jBU2wBS8poH 本项目路径:项目->免费->QtDev 注释:为了方便qt全功能开发,QtDev中包含 ...
- 【自写信息搜集工具】ThunderSearch开发原理解析
前段时间结合zoomeye的开发文档做了个简易的信息搜集工具ThunderSearch[项目地址 / 博客地址],这次来讲讲具体的实现原理和开发思路 首先要能看懂开发文档,https://www.zo ...
- 安全控件开发原理分析 支付宝安全控件开发 C++
浏览器安全控件是如果支付宝一样结合web程序密码数据安全处理的程序,采用C++语言开发 通常的安全控件分为两种,一种是指支持IE内核的浏览器,一种支持所有内核的浏览器,支付宝采用的是支持所有内核的浏览 ...
- 基于SSM的Java Web应用开发原理初探
SSM开发Web的框架已经很成熟了,成熟得以至于有点落后了.虽然如今是SOA架构大行其道,微服务铺天盖地的时代,不过因为仍有大量的企业开发依赖于SSM,本文简单对基于SSM的Java开发做一快速入门, ...
- wed应用程序开发原理
---恢复内容开始--- 企业应用演变的模式 1.主机/哑终端的集中计算模式 时间二十世纪七十年代,企业应用程序是围绕一个中心大型主机建立的.特点 大,贵,专用.只有输入输出功能,没有处理能力,全部是 ...
- web应用程序开发原理
企业应用计算的演变为1.主机/哑终端的集中计算模式: 2.客户机/服务器计算模式:3.浏览器 /服务器计算模式.其中,1具有部署方面的优势,但在一台计算机中进行全部的处理,应用程序难于维护,难于 ...
- 第一章 web应用程序开发原理
[总结] 1.计算机模式 :主机 哑端计算机模式 优点:速度快 反应快 维护修理方便 数据安全性高 缺点:单台计算机安全操作 应用程序难维护 难以跨出平台 客户端 客户计算机模式 优点:速度快 ...
随机推荐
- WordCount运行详解
1.MapReduce理论简介 1.1 MapReduce编程模型 MapReduce采用"分而治之"的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然 ...
- Sprint第一个冲刺(第七天)
今天休息. 燃尽图:
- oracle数据库存储过程分页
CREATE OR REPLACE PROCEDURE prc_query (p_tableName in varchar2, --表名 p_columnNames in varchar2, --字段 ...
- 40+个对初学者非常有用的PHP技巧
1.不要使用相对路径,要定义一个根路径 这样的代码行很常见: require_once('../../lib/some_class.php'); 这种方法有很多缺点: 它首先搜索php包括路径中的指定 ...
- 怎么安装Docker CE 17( Centos 7)
Docker CE for Centos 7 yum install -y yum-utils device-mapper-persistent-data lvm2 yum-config-manage ...
- google adwords report相关类型
(来自enum的ReportDefinitionReportType) KEYWORDS_PERFORMANCE_REPORT, AD_PERFORMANCE_REPORT, URL_PE ...
- snmp 介绍和Ubuntu安装使用
一.介绍 1. 服务器监控工具可以帮助我们从任何一个地方实时了解服务器的性能和功能.监控宝服务器监控套装,可以实时CPU使用率.内存使用率.平均负载.磁盘I/O.网络流量.磁盘使用率等,能够同时为你带 ...
- (转)Inno Setup入门(十九)——Inno Setup类参考(5)
本文转载自:http://blog.csdn.net/yushanddddfenghailin/article/details/17251019 单选按钮 单选按钮在安装中也很常见,例如同一个程序可以 ...
- git 查看&修改用户名
$ git config user.name 查看用户名 $ git config user.email 查看邮箱 $ git config --global user.name " ...
- mysql字符集和校对规则(Mysql校对集)
字符集的概念大家都清楚,校对规则很多人不了解,一般数据库开发中也用不到这个概念,mysql在这方便貌似很先进,大概介绍一下简要说明 字符集和校对规则 字符集是一套符号和编码.校对规则是在字符集内用于比 ...