Hive入门学习随笔(二)
====使用Load语句执行数据的导入
--将操作系统上的文件student01.txt数据导入到t2表中
load data local inpath '/root/data/student01.txt' into table t2;
--将操作系统上/root/data文件夹下的所有文件导入t3表中,并且覆盖原来的数据
load data local inpath '/root/data/' overwrite into table t3;
--将HDFS中,/input/student01.txt导入到t3表中
load data inpath '/input/student01.txt' overwrite into table t3;
--将操作系统上的data1.txt导入到分区t3表中
load data local inpath 'root/data/data1.txt' into table t3 partition (gender='M')
===使用Sqoop实现数据的导入
Sqoop是一个工具,用来进行Hadoop与关系型数据之间的批量数据的导入和导出。
Sqoop的安装非常简单,只需要从网站上下载Sqoop的安装包,并配置环境变量即可。
环境变量:
由于Sqoop是基于Hadoop的,所以需要通过环境变量HADOOP_COMMON_HOME来指明Hadoop的安装目录。
由于Sqoop是把作业最终转换成MapReduce的作业进行提交执行,所以,需要通过环境变量HADOOP_MAPRED_HOME来指明MapReduce的Jar目录。
--使用Sqoop导入Oracle数据到HDFS中。
./sqoop import --connect jdbc:oracle:thin:@192.168.1.36:1521:orcl --username xxx --password xxx --table emp --columns 'empno,ename,job,sal' -m 1 --target-dir '/sqoop/emp'
--使用Sqoop导入Oracle数据到Hive中。
./sqoop import --hive-import --connect jdbc:oracle:thin:@192.168.1.36:1521:orcl --username xxx --password xxx --table emp --columns 'empno,ename,job,sal' -m 1
--使用Sqoop导入Oracle数据到Hive中,并且指定表名
./sqoop import --hive-import --connect jdbc:oracle:thin:@192.168.1.36:1521:orcl --username xxx --password xxx --table emp --columns 'empno,ename,job,sal' -m 1 --hive-table emp1
--使用Sqoop导入Oracle数据到Hive中,并且制定Where条件
./sqoop import --hive-import --connect jdbc:oracle:thin:@192.168.1.36:1521:orcl --username xxx --password xxx --table emp --columns 'empno,ename,job,sal' -m 1 --hive-table emp1 --where 'DEPTNO=10'
--使用Sqoop导入Oracle数据到Hive中,并且使用查询语句
./sqoop import --hive-import --connect jdbc:oracle:thin:@192.168.1.36:1521:orcl --username xxx --password xxx --table emp --columns 'empno,ename,job,sal' -m 1 --hive-table emp1 --query 'SELECT * FROM EMP WHERE SAL<2000 $CONDITIONS' --target-dir '/sqoop/emp5' --hive-table emp5
--使用Sqoop将Hive中的数据导出到Oracle中。
./sqoop export --connect jdbc:oracle:thin:@192.168.1.36:1521:orcl --username xxx --password xxx -m 1 --table MYEMP --export-dir HDFS路径
Sqoop在业务系统中有着非常重要的作用,一般的应用场景是下面这个样子。
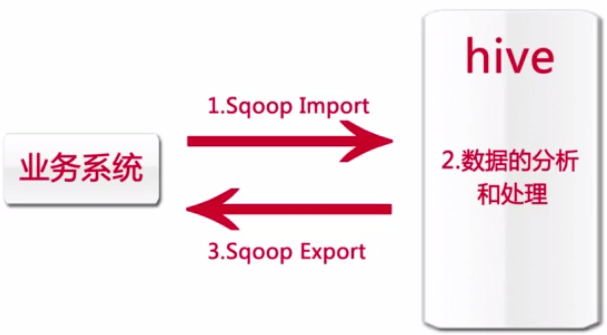
====Hive的数据查询

--查询所有员工的所有信息
select * from emp;
--查询员工信息:员工号 姓名 月薪
select empno, ename, sal from emp;
--查询员工信息:员工号 姓名 月薪 年薪 奖金 年收入
select empno, ename, sal, sal*12 comm, sal*12+nvl(comm, 0) from emp;
--查询奖金为null的员工
select * from emp where comm is null;
--使用distinct来去掉重复记录
select distinct deptno from rmp;
====Hive简单查询的FetchTask功能
从Hive0.10.0版本开始支持。开始了这个功能以后,我们执行一条简单的语句(没有函数、排序等)不会生成一个MapReduce作业。

hive-site.xml配置内容:

====在查询中使用过滤
--查询10号部门的员工
select * from emp where deptno=10;
--查询名称为KING的员工
select * from emp where ename='KING';
--查询部门号是10,薪水小于2000的员工
select * from emp where deptno=10 and sal<2000;
--模糊查询:查询名字以S开头的员工
select empno, ename, sal from emp where ename like 'S%';
--模糊查询:查询名字含有下划线的员工
select empno, ename, sal from emp where ename like '%\\_%';
注意:下划线在模糊查询中有特殊的含义,代表任意字符。所以,语句中需要转义符进行标记
====在查询中使用排序
--查询员工信息:员工号 姓名 月薪 按照月薪排序
select empno, ename, sal from emp order by sal desc;
※order by后面可以使用:列名、表达式、别名、序号。
另外,如果想使用需要进行排序的时候,需要设置下面的环境变量。
set hive.groupby.orderby.position.alias=true;
※null排序:升序时null排最前面,降序时null排最后面,一般用法都是将null转换成0之后进行排序。
====Hive的函数
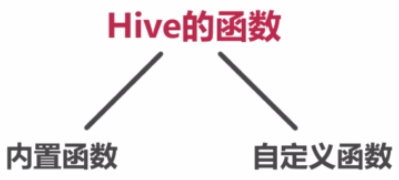
内置函数可以直接调用。也可以通过编写java程序来自定义函数
--内置函数

--自定义函数

①、自定义UDF需要继承org.apache.hadoop.hive.ql.UDF
需要实现evaluate函数,evaluate函数支持重载。
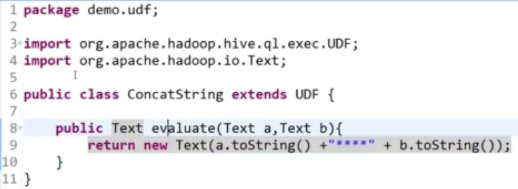
②、将程序打包放到目标机器上去,进入Hive客户端添加jar包
命令例:hive>add jar /root/udfjar/udf_text.jar
③、创建临时函数:CREATE TEMPORARY FUNCTION <函数名> AS 'java类名'
命令例:hive>CREATE TEMPORARY FUNCTION myconcat AS 'demo.udf.ConcatString';
④、自动以函数使用。select <函数名> from table;

⑤、销毁临时函数:DROP TEMPORARY FUNCTION <函数名>
====Hive表连接
Hive的表连接分为:等值连接、不等值连接、外链接、自连接
--等值连接
select e.empno, e.ename, e.sal, d.name from emp e, dept d where e.deptno=d.deptno;
--不等值连接
select e.empno, e.ename, e.sal, s.grade from emp e, salgrade s where e.sal between s.local and s.hisal;
--外链接(包括左连接和右连接)
select d.deptno, d.dname, count(e.empno) from emp e right outer join dept d on (e.deptno=d.deptno) group by d.deptno, d.dname;
--自连接
核心:通过表的别名将同一张表视为多张表
====Hive中的子查询
hive只支持from和where子句中的子查询。
例:select e.ename from emp e where e.deptno in (select d.deptno from dept d where d.dname='SALES' or d.dname='KING');
注意:子查询中的空值:如果子查询返回的结果集中含有空值得话,我们不能使用not in,但是可以使用in。
====Hive的JDBC客户端操作
①、启动Hive远程服务。命令:#hive --service hiveserver
②、JDBC客户端操作
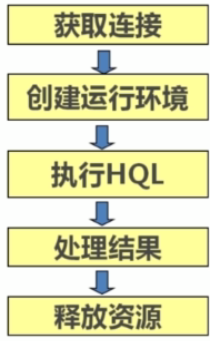
====Hive的Thrift Java客户端操作
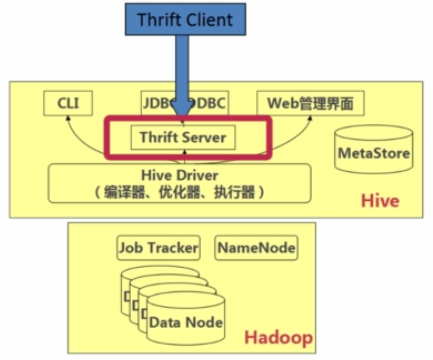
--END--
Hive入门学习随笔(二)的更多相关文章
- Hive入门学习随笔(一)
Hive入门学习随笔(一) ===什么是Hive? 它可以来保存我们的数据,Hive的数据仓库与传统意义上的数据仓库还有区别. Hive跟传统方式是不一样的,Hive是建立在Hadoop HDFS基础 ...
- 【转载】salesforce 零基础开发入门学习(二)变量基础知识,集合,表达式,流程控制语句
salesforce 零基础开发入门学习(二)变量基础知识,集合,表达式,流程控制语句 salesforce如果简单的说可以大概分成两个部分:Apex,VisualForce Page. 其中Apex ...
- Hive入门学习--HIve简介
现在想要应聘大数据分析或者数据挖掘岗位,很多都需要会使用Hive,Mapreduce,Hadoop等这些大数据分析技术.为了充实自己就先从简单的Hive开始吧.接下来的几篇文章是记录我如何入门学习Hi ...
- MyBatis入门学习(二)
在MyBatis入门学习(一)中我们完成了对MyBatis简要的介绍以及简单的入门小项目测试,主要完成对一个用户信息的查询.这一节我们主要来简要的介绍MyBatis框架的增删改查操作,加深对该框架的了 ...
- Java Web入门学习(二) Eclipse的配置
Java Web学习(二) Eclipse的配置 一.下载Eclipse 1.进入Eclipse官网,进行下载 上图,下载Eclipse IDE for JaveEE Developers 版本,然后 ...
- Swoole 入门学习(二)
Swoole 入门学习 swoole 之 定时器 循环触发:swoole_timer_tick (和js的setintval类似) 参数1:int $after_time_ms 指定时间[毫秒] ...
- Reactive UI -- 反应式编程UI框架入门学习(二)
前文Reactive UI -- 反应式编程UI框架入门学习(一) 介绍了反应式编程的概念和跨平台ReactiveUI框架的简单应用. 本文通过一个简单的小应用更进一步学习ReactiveUI框架的 ...
- salesforce 零基础开发入门学习(二)变量基础知识,集合,表达式,流程控制语句
salesforce如果简单的说可以大概分成两个部分:Apex,VisualForce Page. 其中Apex语言和java很多的语法类似,今天总结的是一些简单的Apex的变量等知识. 有如下几种常 ...
- Hibernate入门学习(二)
本文主要讲如何搭建Hibernate开发环境和简单实例. 一.搭建开发测试环境 1.1 下载Hibernate 从Hibernate官方网站上下载最新的Hibernate ORM,从Hibernate ...
随机推荐
- FPGA之外,了解一下中断
中断是什么? 中断的汉语解释是半中间发生阻隔.停顿或故障而断开.那么,在计算机系统中,我们为什么需要“阻隔.停顿和断开”呢? 举个日常生活中的例子,比如说我正在厨房用煤气烧一壶水,这样就只能守在厨房里 ...
- java代码-----String数组进行排序。是英文的字符串
总结:主要是方法不同了.是compareTo()方法比较字符串大小 package com.s.x; import java.util.Arrays; public class Jay { publi ...
- java代码啊==indexOf()方法返回字符第一次出现的位置
package com.s.x; public class Wang { public static void main(String[] args) { if ("woaini" ...
- jQuery给控件赋值....
1.jQuery给span取值:$("#id").html(); 2.jQuery给input取值:$("#id").val(); 3.jQuery给texta ...
- 【UVa】208 Firetruck(dfs)
题目 题目 分析 一开始不信lrj的话,没判联通,果然T了. 没必要全部跑一遍判,只需要判断一下有没有点与n联通,邻接表不太好判,但无向图可以转换成去判n与什么联通. 关于为什么要判,还是因为 ...
- 多个else if语句
public class demo { public static void main(String[] args) { boolean examIsDone = true; int score = ...
- oracle 索引使用小结
1. 普通索引 create index my_index on test (col_1); 可创建合并两列或多列的索引,最多可将32列合并在一个索引中(位图索引最多可合并30列) create in ...
- iframe有哪些缺点?
iframe会阻塞主页面的Onload事件: iframe和主页面共享连接池,而浏览器对相同域的连接有限制,所以会影响页面的并行加载.使用iframe之前需要考虑这两个缺点.如果需要使用ifram ...
- 第八章 分布式配置中心:Spring Cloud Config
Spring Cloud Config 是 Spring Cloud 团队创建的一个全新项目,用来为分布式系统中的基础设施和微服务应用提供集中化的外部配置支持, 它分为服务端与客户端两个部分. 其中服 ...
- 深入浅出 Java Concurrency (15): 锁机制 part 10 锁的一些其它问题
主要谈谈锁的性能以及其它一些理论知识,内容主要的出处是<Java Concurrency in Practice>,结合自己的理解和实际应用对锁机制进行一个小小的总结. 首先需要强调的 ...