UDF、UDAF、UDTF函数编写
一、UDF函数编写
1.步骤
- 1.继承UDF类
- 2.重写evalute方法
- 1、继承GenericUDF
- 2、实现initialize、evaluate、getDisplayString方法
2.案例
实现lower函数:
- package com.xxx.udf;
- import org.apache.hadoop.hive.ql.exec.UDF;
- import org.apache.hadoop.io.Text;
- public class LowerUDF extends UDF {
- public Text evaluate(Text input){
- if(null == input){
- return null;
- }
- String inputValue = input.toString().trim() ;
- if(null == inputValue){
- return null ;
- }
- return new Text(inputValue.toLowerCase()) ;
- }
- }
- package com.xxx.udf;
- import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
- import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
- import org.apache.hadoop.hive.ql.metadata.HiveException;
- import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
- import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
- import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
- import org.apache.hadoop.hive.serde2.objectinspector.primitive.StringObjectInspector;
- import org.apache.hadoop.io.Text;
- public class LowerUDF extends GenericUDF {
- StringObjectInspector str ;
- @Override
- public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
- //判断输入参数个数是否合法
- if (arguments.length != 1) {
- throw new UDFArgumentLengthException("输入参数长度不合法,应该为一个参数");
- }
- //判断输入参数类型是否合法
- if (!(arguments[0] instanceof StringObjectInspector)) {
- throw new UDFArgumentException("输入非法参数,应为字符串类型");
- }
- str=(StringObjectInspector)arguments[0];
- //确定返回值类型
- return PrimitiveObjectInspectorFactory.javaStringObjectInspector;
- }
- @Override
- public Object evaluate(DeferredObject[] arguments) throws HiveException {
- String input = str.getPrimitiveJavaObject(arguments[0].get());
- return new Text(input.toLowerCase());
- }
- @Override
- public String getDisplayString(String[] children) {
- return "方法的描述信息";
- }
- }
3.打成jar包上传
mvn clean package
4.在hive中创建临时函数
- add jar /home/xxx/yf/to_lower.jar;
- create temporary function to_lower as 'com.xxx.udf.LowerUDF';
- select to_lower("DSJIFASD") from dual;
- drop temporary function comparestringbysplit;

二、UDAF函数编写
1.步骤
- 1、继承AbstractGenericUDAFResolver
- 2、继承GenericUDAFEvaluator
- 3、Evaluator需要实现 init、iterate、terminatePartial、merge、terminate这几个函数
- init初始化
- iterate函数处理读入的行数据
- terminatePartial返回iterate处理的中间结果
- merge合并上述处理结果
- terminate返回最终值
2.案例
实现avg
- package com.xxx.udf;
- import org.apache.hadoop.hive.ql.exec.UDAF;
- import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
- public class Avg extends UDAF {
- public static class AvgState {
- private long mCount;
- private double mSum;
- }
- public static class AvgEvaluator implements UDAFEvaluator {
- AvgState state;
- public AvgEvaluator() {
- super();
- state = new AvgState();
- init();
- }
- /**
- * init函数类似于构造函数,用于UDAF的初始化
- */
- public void init() {
- state.mSum = 0;
- state.mCount = 0;
- }
- /**
- * iterate接收传入的参数,并进行内部的轮转。其返回类型为boolean * * @param o * @return
- */
- public boolean iterate(Double o) {
- if (o != null) {
- state.mSum += o;
- state.mCount++;
- }
- return true;
- }
- /**
- * terminatePartial无参数,其为iterate函数遍历结束后,返回轮转数据, * terminatePartial类似于hadoop的Combiner * * @return
- */
- public AvgState terminatePartial() {
- // combiner
- return state.mCount == 0 ? null : state;
- }
- /**
- * merge接收terminatePartial的返回结果,进行数据merge操作,其返回类型为boolean * * @param o * @return
- */
- public boolean merge(AvgState avgState) {
- if (avgState != null) {
- state.mCount += avgState.mCount;
- state.mSum += avgState.mSum;
- }
- return true;
- }
- /**
- * terminate返回最终的聚集函数结果 * * @return
- */
- public Double terminate() {
- return state.mCount == 0 ? null : Double.valueOf(state.mSum / state.mCount);
- }
- }
- }
实现sum
- package com.xxx.udf;
- import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
- import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
- import org.apache.hadoop.hive.ql.metadata.HiveException;
- import org.apache.hadoop.hive.ql.parse.SemanticException;
- import org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver;
- import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;
- import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
- import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
- import org.apache.hadoop.hive.serde2.objectinspector.primitive.DoubleObjectInspector;
- import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
- import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorUtils;
- import org.apache.hadoop.hive.serde2.objectinspector.primitive.StringObjectInspector;
- import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;
- import org.apache.hadoop.io.DoubleWritable;
- import org.apache.hadoop.io.LongWritable;
- public class Test extends AbstractGenericUDAFResolver {
- /**
- * 获取处理逻辑类
- * @param info
- * @return
- * @throws SemanticException
- */
- @Override
- public GenericUDAFEvaluator getEvaluator(TypeInfo[] info) throws SemanticException {
- //判断输入参数是否合法,参数个数,参数类型
- if (info.length != 1) {
- throw new UDFArgumentLengthException("输入参数个数非法,一个参数");
- }
- return new GenericEvaluate();
- }
- //处理逻辑类
- public static class GenericEvaluate extends GenericUDAFEvaluator {
- private PrimitiveObjectInspector input;
- private DoubleWritable result ; //保存最终结果
- private MyAggregationBuffer myAggregationBuffer; //自定义聚合列,保存临时结果
- //自定义AggregationBuffer
- public static class MyAggregationBuffer implements AggregationBuffer {
- Double sum;
- }
- @Override //指定返回类型
- public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException {
- super.init(m, parameters);
- result = new DoubleWritable(0);
- input = (PrimitiveObjectInspector) parameters[];
- // 指定返回结果类型
- return PrimitiveObjectInspectorFactory.writableDoubleObjectInspector;
- }
- @Override //获得一个聚合的缓冲对象,每个map执行一次
- public AggregationBuffer getNewAggregationBuffer() throws HiveException {
- MyAggregationBuffer myAggregationBuffer = new MyAggregationBuffer();
- reset(myAggregationBuffer); // 重置聚合值
- return myAggregationBuffer;
- }
- @Override
- public void reset(AggregationBuffer agg) throws HiveException {
- MyAggregationBuffer newAgg = (MyAggregationBuffer) agg;
- newAgg.sum = 0.0;
- }
- @Override // 传入参数值聚合
- public void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException {
- MyAggregationBuffer myAgg = (MyAggregationBuffer) agg;
- double inputNum = PrimitiveObjectInspectorUtils.getDouble(parameters[], input);
- myAgg.sum += inputNum;
- }
- @Override //
- public Object terminatePartial(AggregationBuffer agg) throws HiveException {
- MyAggregationBuffer newAgg = (MyAggregationBuffer) agg;
- result.set(newAgg.sum);
- return result;
- }
- @Override // 合并
- public void merge(AggregationBuffer agg, Object partial) throws HiveException {
- double inputNum = PrimitiveObjectInspectorUtils.getDouble(partial, input);
- MyAggregationBuffer newAgg = (MyAggregationBuffer) agg;
- newAgg.sum += inputNum;
- }
- @Override //输出最终结果
- public Object terminate(AggregationBuffer agg) throws HiveException {
- MyAggregationBuffer aggregationBuffer = (MyAggregationBuffer) agg;
- result.set(aggregationBuffer.sum);
- return result;
- }
- }
- }
3.打包
mvn clean package
4.创建临时函数
- add jar /home/xxx/yf/my_avg.jar;
- create temporary function my_avg as 'com.xxx.udf.UDTFExplode';
- select my_avg() from dual;
- drop temporary function my_avg;
三、UDTF函数编写
1.步骤
- 1.继承GenericUDTF
- 2.重写initialize、process方法
- initialize初始化校验参数是否正确、
- process处理返回结果、
- forward将结果返回
2.案例
将字符串按照元素索引分别输出,如:‘a,c,b’ -- > a,1 c,2 b,3
- package com.suning.udf;
- import java.util.ArrayList;
- import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
- import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
- import org.apache.hadoop.hive.ql.metadata.HiveException;
- import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
- import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
- import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
- import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
- import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
- public class UDTFExplode extends GenericUDTF {
- @Override
- public void close() throws HiveException {
- // TODO Auto-generated method stub
- }
- @Override
- public StructObjectInspector initialize(ObjectInspector[] args) throws UDFArgumentException {
- if (args.length != 1) {
- throw new UDFArgumentLengthException("ExplodeMap takes only one argument");
- }
- if (args[].getCategory() != ObjectInspector.Category.PRIMITIVE) {
- throw new UDFArgumentException("ExplodeMap takes string as a parameter");
- }
- ArrayList<String> fieldNames = new ArrayList<String>();
- ArrayList<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();
- fieldNames.add("col1");
- fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
- fieldNames.add("col2");
- fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
- return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
- }
- @Override
- public void process(Object[] args) throws HiveException {
- // TODO Auto-generated method stub
- String input = args[].toString();
- String[] test = input.split(",");
- for (int i = 0; i < test.length; i++) {
- try {
- String[] result = (test[i]+":"+String.valueOf(i+1)).split(":");
- forward(result);
- } catch (Exception e) {
- continue;
- }
- }
- }
- }
3.打包
mvn clean package
4.创建临时函数
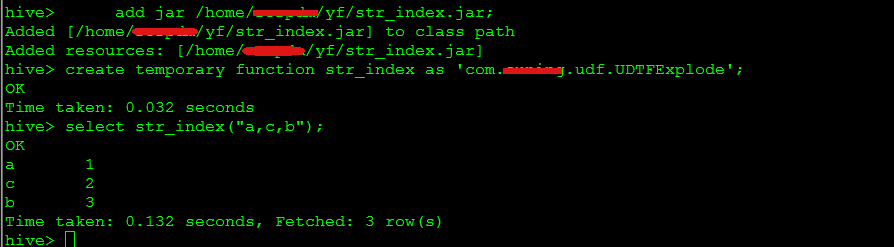
- add jar /home/xxx/yf/str_index.jar;
- create temporary function str_index as 'com.xxx.udf.UDTFExplode';
- select str_index("a,c,b") from dual;
- drop temporary function str_index;
pom.xml
- <?xml version="1.0" encoding="UTF-8"?>
- <project xmlns="http://maven.apache.org/POM/4.0.0"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
- <modelVersion>4.0.0</modelVersion>
- <groupId>spark-hive</groupId>
- <artifactId>spark-hive</artifactId>
- <version>1.0-SNAPSHOT</version>
- <properties>
- <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
- <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
- <scala.version>2.11.8</scala.version>
- <spark.version>2.1.0.9</spark.version>
- <spark.artifactId.version>2.11</spark.artifactId.version>
- </properties>
- <dependencies>
- <dependency>
- <groupId>commons-logging</groupId>
- <artifactId>commons-logging</artifactId>
- <version>1.1.1</version>
- <type>jar</type>
- </dependency>
- <dependency>
- <groupId>org.apache.commons</groupId>
- <artifactId>commons-lang3</artifactId>
- <version>3.1</version>
- </dependency>
- <dependency>
- <groupId>log4j</groupId>
- <artifactId>log4j</artifactId>
- <version>1.2.17</version>
- </dependency>
- <dependency>
- <groupId>org.apache.hadoop</groupId>
- <artifactId>hadoop-common</artifactId>
- <version>2.6.2</version>
- </dependency>
- <dependency>
- <groupId>mysql</groupId>
- <artifactId>mysql-connector-java</artifactId>
- <version>5.1.21</version>
- </dependency>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-core_2.11</artifactId>
- <version>2.1.0</version>
- </dependency>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-streaming_2.11</artifactId>
- <version>2.1.0</version>
- </dependency>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
- <version>2.1.0</version>
- </dependency>
- <dependency>
- <groupId>com.google.code.gson</groupId>
- <artifactId>gson</artifactId>
- <version>2.8.2</version>
- </dependency>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-sql_2.11</artifactId>
- <version>2.1.0</version>
- </dependency>
- <dependency>
- <groupId>com.alibaba</groupId>
- <artifactId>fastjson</artifactId>
- <version>1.2.29</version>
- </dependency>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-hive_${spark.artifactId.version}</artifactId>
- <version>${spark.version}</version>
- <scope>provided</scope>
- </dependency>
- <!--flink dependency-->
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-java</artifactId>
- <version>1.5.0</version>
- </dependency>
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-streaming-java_2.11</artifactId>
- <version>1.5.0</version>
- </dependency>
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-clients_2.11</artifactId>
- <version>1.5.0</version>
- </dependency>
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-connector-wikiedits_2.11</artifactId>
- <version>1.5.0</version>
- </dependency>
- <!--hbase dependency-->
- <dependency>
- <groupId>org.apache.hbase</groupId>
- <artifactId>hbase</artifactId>
- <version>0.98.8-hadoop2</version>
- <type>pom</type>
- </dependency>
- <dependency>
- <groupId>org.apache.hbase</groupId>
- <artifactId>hbase-client</artifactId>
- <version>0.98.8-hadoop2</version>
- </dependency>
- <dependency>
- <groupId>org.apache.hbase</groupId>
- <artifactId>hbase-common</artifactId>
- <version>0.98.8-hadoop2</version>
- </dependency>
- <dependency>
- <groupId>org.apache.hbase</groupId>
- <artifactId>hbase-server</artifactId>
- <version>0.98.8-hadoop2</version>
- </dependency>
- </dependencies>
- <build>
- <plugins>
- <plugin>
- <artifactId>maven-assembly-plugin</artifactId>
- <configuration>
- <descriptorRefs>
- <descriptorRef>jar-with-dependencies</descriptorRef>
- </descriptorRefs>
- </configuration>
- </plugin>
- <plugin>
- <groupId>org.codehaus.mojo</groupId>
- <artifactId>build-helper-maven-plugin</artifactId>
- <version>1.8</version>
- <executions>
- <execution>
- <id>add-source</id>
- <phase>generate-sources</phase>
- <goals>
- <goal>add-source</goal>
- </goals>
- <configuration>
- <sources>
- <source>src/main/scala</source>
- <source>src/test/scala</source>
- </sources>
- </configuration>
- </execution>
- <execution>
- <id>add-test-source</id>
- <phase>generate-sources</phase>
- <goals>
- <goal>add-test-source</goal>
- </goals>
- <configuration>
- <sources>
- <source>src/test/scala</source>
- </sources>
- </configuration>
- </execution>
- </executions>
- </plugin>
- <plugin>
- <groupId>org.apache.maven.plugins</groupId>
- <artifactId>maven-compiler-plugin</artifactId>
- <version>2.3.2</version>
- <configuration>
- <source>1.7</source>
- <target>1.7</target>
- <encoding>${project.build.sourceEncoding}</encoding>
- </configuration>
- </plugin>
- <plugin>
- <groupId>org.scala-tools</groupId>
- <artifactId>maven-scala-plugin</artifactId>
- <executions>
- <execution>
- <goals>
- <goal>compile</goal>
- <goal>add-source</goal>
- <goal>testCompile</goal>
- </goals>
- </execution>
- </executions>
- <configuration>
- <scalaVersion>2.11.8</scalaVersion>
- <sourceDir>src/main/scala</sourceDir>
- <jvmArgs>
- <jvmArg>-Xms64m</jvmArg>
- <jvmArg>-Xmx1024m</jvmArg>
- </jvmArgs>
- </configuration>
- </plugin>
- <plugin>
- <groupId>org.apache.maven.plugins</groupId>
- <artifactId>maven-release-plugin</artifactId>
- <version>2.5.3</version>
- </plugin>
- <plugin>
- <groupId>org.apache.maven.plugins</groupId>
- <artifactId>maven-deploy-plugin</artifactId>
- <configuration>
- <skip>false</skip>
- </configuration>
- </plugin>
- <plugin>
- <groupId>org.apache.maven.plugins</groupId>
- <artifactId>maven-shade-plugin</artifactId>
- <version>2.4.1</version>
- <executions>
- <execution>
- <phase>package</phase>
- <goals>
- <goal>shade</goal>
- </goals>
- <configuration>
- <filters>
- <filter>
- <artifact>*:*</artifact>
- <excludes>
- <exclude>META-INF/*.SF</exclude>
- org.apache.hive <exclude>META-INF/*.DSA</exclude>
- <exclude>META-INF/*.RSA</exclude>
- </excludes>
- </filter>
- </filters>
- <minimizeJar>false</minimizeJar>
- </configuration>
- </execution>
- </executions>
- </plugin>
- </plugins>
- <resources>
- <resource>
- <directory>src/main/resources</directory>
- <filtering>true</filtering>
- </resource>
- <resource>
- <directory>src/main/resources/${profiles.active}</directory>
- </resource>
- </resources>
- <!-- 修复 Plugin execution not covered by lifecycle configuration -->
- <pluginManagement>
- <plugins>
- <plugin>
- <groupId>org.eclipse.m2e</groupId>
- <artifactId>lifecycle-mapping</artifactId>
- <version>1.0.0</version>
- <configuration>
- <lifecycleMappingMetadata>
- <pluginExecutions>
- <pluginExecution>
- <pluginExecutionFilter>
- <groupId>org.codehaus.mojo</groupId>
- <artifactId>build-helper-maven-plugin</artifactId>
- <versionRange>[1.8,)</versionRange>
- <goals>
- <goal>add-source</goal>
- <goal>add-test-source</goal>
- </goals>
- </pluginExecutionFilter>
- <action>
- <ignore></ignore>
- </action>
- </pluginExecution>
- <pluginExecution>
- <pluginExecutionFilter>
- <groupId>org.scala-tools</groupId>
- <artifactId>maven-scala-plugin</artifactId>
- <versionRange>[1.8,)</versionRange>
- <goals>
- <goal>compile</goal>
- <goal>add-source</goal>
- <goal>testCompile</goal>
- </goals>
- </pluginExecutionFilter>
- <action>
- <ignore></ignore>
- </action>
- </pluginExecution>
- </pluginExecutions>
- </lifecycleMappingMetadata>
- </configuration>
- </plugin>
- </plugins>
- </pluginManagement>
- </build>
- </project>
UDF、UDAF、UDTF函数编写的更多相关文章
- 简述UDF/UDAF/UDTF是什么,各自解决问题及应用场景
UDF User-Defined-Function 自定义函数 .一进一出: 背景 系统内置函数无法解决实际的业务问题,需要开发者自己编写函数实现自身的业务实现诉求. 应用场景非常多,面临的业务不同导 ...
- Hive 自定义函数 UDF UDAF UDTF
1.UDF:用户定义(普通)函数,只对单行数值产生作用: 继承UDF类,添加方法 evaluate() /** * @function 自定义UDF统计最小值 * @author John * */ ...
- [转]HIVE UDF/UDAF/UDTF的Map Reduce代码框架模板
FROM : http://hugh-wangp.iteye.com/blog/1472371 自己写代码时候的利用到的模板 UDF步骤: 1.必须继承org.apache.hadoop.hive ...
- hive中 udf,udaf,udtf
1.hive中基本操作: DDL,DML 2.hive中函数 User-Defined Functions : UDF(用户自定义函数,简称JDF函数)UDF: 一进一出 upper lower ...
- 【转】HIVE UDF UDAF UDTF 区别 使用
原博文出自于:http://blog.csdn.net/longzilong216/article/details/23921235(暂时) 感谢! 自己写代码时候的利用到的模板 UDF步骤: 1 ...
- FlinkSQL使用自定义UDTF函数行转列-IK分词器
一.背景说明 本文基于IK分词器,自定义一个UDTF(Table Functions),实现类似Hive的explode行转列的效果,以此来简明开发过程. 如下图Flink三层API接口中,Table ...
- hive UDTF函数
之前说过HIVE,UDF(User-Defined-Function)函数的编写和使用,现在来看看UDTF的编写和使用. 1. UDTF介绍 UDTF(User-Defined Table-Gener ...
- hive自定义UDTF函数叉分函数
hive自定义UDTF函数叉分函数 1.介绍 从聚合体日志中需要拆解出来各子日志数据,然后单独插入到各日志子表中.通过表生成函数完成这一过程. 2.定义ForkLogUDTF 2.1 HiveUtil ...
- PHP代码重用与函数编写
代码重用与函数编写 1.使用require()和include()函数 这两个函数的作用是将一个文件爱你载入到PHP脚本中,这样就可以直接调用这个文件中的方法.require()和include()几 ...
随机推荐
- 微信小程序商业级实战
1.微信开放能力:微信支付.微信登录.二维码生成.分享
- 【进阶3-2期】JavaScript深入之重新认识箭头函数的this(转)
这是我在公众号(高级前端进阶)看到的文章,现在做笔记 https://github.com/yygmind/blog/issues/21 上篇文章详细的分析了各种this的情况,看过之后对this的概 ...
- 信息摘要算法之六:HKDF算法分析与实现
HKDF是一种特定的键衍生函数(KDF),即初始键控材料的功能,KDF从其中派生出一个或多个密码强大的密钥.在此我们想要描述的是基于HMAC的HKDF. 1.HKDF概述 密钥派生函数(KDF)是密码 ...
- STM32L476应用开发之四:触摸屏驱动与数据交互
数据交互可以说是任何一台仪器都需要的功能.我们的便携式气体分析仪,需要人来操作和配置,所以触摸屏就是我们必然的一个选择.本次我们计划采用3.5寸显示屏,串口通讯. 1.硬件设计 前面我们实验了串行通讯 ...
- maven install 报错 No compiler is provided in this environment. Perhaps you are running on a JRE rather than a JDK?
1.控制台打印信息 [INFO] Scanning for projects... [INFO] [INFO] ---------------------< org.cqupt.mauger:R ...
- Confluence 6 后台中的默认空间模板设置
Confluence 6 后台中的默认空间模板设置界面的布局. https://www.cwiki.us/display/CONFLUENCEWIKI/Customizing+Default+Spac ...
- ionic3 点击输入 框弹出白色遮罩 并把 界面顶到上面
这个蛋疼 问题 ,在android 上面遇到这种情况 ,键盘弹出的时候 总有一个白色的遮罩在后面出现,网上查了很久都没发现原因. 偶然发现一个方法 ,试下了下 问题解决了. 代码如下: IonicMo ...
- SpringData使用与整合
SpringData 整合源码:链接: https://pan.baidu.com/s/1_dDEEJoqaBTfXs2ZWsvKvA 提取码: cp6s(jar包自行寻找) author:Simpl ...
- LeetCode(113):路径总和 II
Medium! 题目描述: 给定一个二叉树和一个目标和,找到所有从根节点到叶子节点路径总和等于给定目标和的路径. 说明: 叶子节点是指没有子节点的节点. 示例:给定如下二叉树,以及目标和 sum = ...
- SQLmap超详细文档和实例演示
第一部分,使用文档的说明 Options(选项): -h, -–help 显示此帮助消息并退出 -hh 显示更多帮助信息并退出 –-version 显示程序的版本号并退出 -v VERBOSE 详细级 ...