hbase-写操作
hbase连接过程
hbase client在写入的数据的过程中,是直接和rs进行通信的,整个的数据写入流程并不涉及到HMaster。那么client是如何找到对应的rs呢?流程如下:
- client从zookeeper中获取存储hbase:root表的RegionServer(设为rs1)的地址信息,hbase考虑到hbase:meta表过大,存储到了不同的region中,需要一个hbase:root的表对hbase:meta表的元数据进行存储。在0.98版本后,hbase:mata表不在split,只有一个region,也去除掉了hbase:root表,client的访问过程也不用进行这一步。
- client访问rs1,从hbase:root表中获取对应hbase:meta表的RegionServer(rs2)的地址信息。这里有些问题?hbase:root中如何知道一条数据应该写入哪个RegionServer?而这个对应的RegionServer应该存储在哪个hbase:meta中?在下面介绍hbase:meta表介绍。
- client访问rs2,从hbase:meta表中获取对应要访问的region的RegionServer(rs3)的地址信息。
- client访问rs3,和rs3进行数据交互。这里是具体的数据插入流程看下面两个具体的步骤(hbase客户端流程和hbase服务器端流程)。
meta表和root表格式:
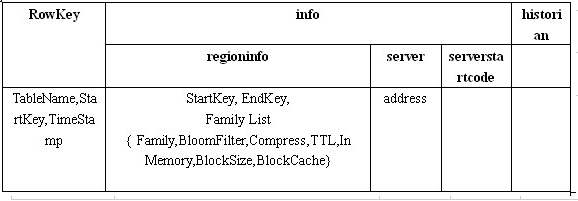
meta表结构例子:
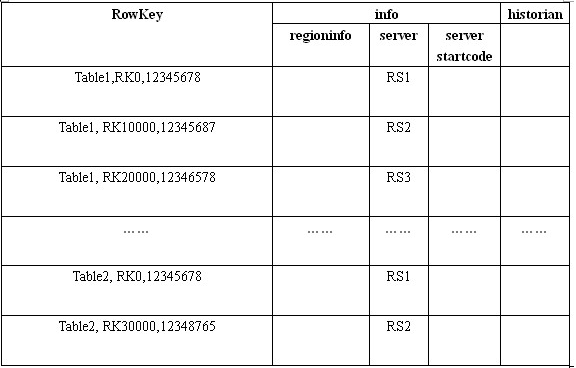
root表结构例子:

- 回答一下上面步骤二问题,从上面的root表中可以知道,RowKey里面包含了具体的表信息,这里就可以排除其他表,在regioninfo里面有具体的startKey和endKey信息,这里可以判断该条数据是否在这个区间。通过这两个信息就可以查找到对应meta表的rs地址。同理可以在meta表中查到到对应的数据交互的rs。
- 还有一个问题,是否每次put数据都需要进行这3次连接?其实不用的,每次client和hbase进行通信后,将访问过的meta表信息存储在本地。数据首先从本地的缓存中获取meta表数据,直接访问rs进行数据交互。
hbase客户端流程
- 用户提交put请求。hbase client提交可以设置autoflush参数,该参数默认autoflush=true,表示put请求会直接提交给服务器进行处理。可以设置为autoflush=false,这样的话put请求数据首先会存放在buffer中,等待本地的buffer数据大小达到阈值之后才会提交。很明显,两种方式的有优缺点在于,方式一数据写入慢,但是不会丢数据,方式二写入快,但是存在丢数据的风险。
- 在提交数据之前,client通过meta表查找到对应rowkey所属的rs,如果的批量提交,会将rowkey对应不同的rs分组,每个分组分别批量提交。
hbase服务器端流程
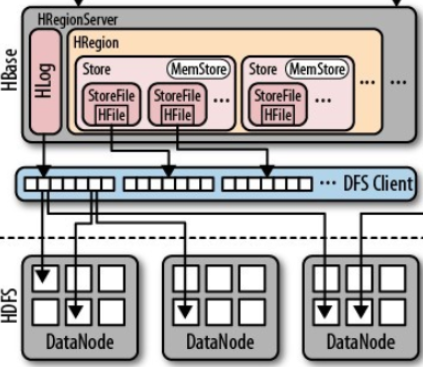
数据的写入流程:
- 数据首先写入到wal中
- 然后数据写入到MemStore中
- 当MemStore中的数据大小超过阈值,flush到HFile中
当机器出现宕机情况,因为wal和HFile中的数据存储在hdfs中,并不会出现数据丢失情况,数据丢失的是在MemStore中尚未flush到HFile的数据,可以从wal将这部分数据从新恢复
hbase-写操作的更多相关文章
- Spark-读写HBase,SparkStreaming操作,Spark的HBase相关操作
Spark-读写HBase,SparkStreaming操作,Spark的HBase相关操作 1.sparkstreaming实时写入Hbase(saveAsNewAPIHadoopDataset方法 ...
- NoSQL生态系统——事务机制,行锁,LSM,缓存多次写操作,RWN
13.2.4 事务机制 NoSQL系统通常注重性能和扩展性,而非事务机制. 传统的SQL数据库的事务通常都是支持ACID的强事务机制.要保证数据的一致性,通常多个事务是不可能交叉执行的,这样就导致了可 ...
- HBase Shell操作
Hbase 是一个分布式的.面向列的开源数据库,其实现是建立在google 的bigTable 理论之上,并基于hadoop HDFS文件系统. Hbase不同于一般的关系型数据库(RDBMS ...
- hbase日常操作及维护
一,基本命令: 建表:create 'testtable','coulmn1','coulmn2' 也可以建表时加coulmn的属性如:create 'testtable',{NAME => ' ...
- Hbase写数据,存数据,读数据的详细过程
Client写入 -> 存入MemStore,一直到MemStore满 -> Flush成一个StoreFile,直至增长到一定阈值 -> 出发Compact合并操作 -> 多 ...
- HBase写数据
1 多HTable并发写 创建多个HTable客户端用于写操作,提高写数据的吞吐量,一个例子: static final Configuration conf = HBaseConfiguration ...
- 大数据技术之_11_HBase学习_01_HBase 简介+HBase 安装+HBase Shell 操作+HBase 数据结构+HBase 原理
第1章 HBase 简介1.1 什么是 HBase1.2 HBase 特点1.3 HBase 架构1.3 HBase 中的角色1.3.1 HMaster1.3.2 RegionServer1.3.3 ...
- HBase写请求分析
HBase作为分布式NoSQL数据库系统,不单支持宽列表.而且对于随机读写来说也具有较高的性能.在高性能的随机读写事务的同一时候.HBase也能保持事务的一致性. 眼下HBase仅仅支持行级别的事务一 ...
- HBase常用操作之namespace
1.介绍 在HBase中,namespace命名空间指对一组表的逻辑分组,类似RDBMS中的database,方便对表在业务上划分.Apache HBase从0.98.0, 0.95.2两个版本开始支 ...
- HBase写过程详解
1首次读写流程图 2 首次写基本流程 (1)客户端发起PUT请求,Zookeeper返回hbase:meta所在的region server (2)去(1)返回的server上,根据rowkey去hb ...
随机推荐
- rest_framework目录
一 REST API规范 二 rest framework框架的基本使用
- Ubuntu离线安装docker
1.先安装依赖libltdl7_2.4.6-0.1_amd64.deb 下载链接http://archive.ubuntu.com/ubuntu/pool/main/libt/libtool/libl ...
- Powerdesigner16 逆向 postgresql9.2
参考配置连接:https://www.cnblogs.com/simpleZone/p/5489781.html 过程中遇到的问题: 1.Powerdesigner需要用32位的jdk进行逆向,所以需 ...
- (11)ssh免密登录配置
***在Linux命令行中登录到另一台虚拟机(需要用到ssh协议) Linux中默认有ssh的服务器端和客户端,客户端的名字就叫ssh 前提是当前使用的用户名在待连接的虚拟机中存在 格式: ssh ...
- Ubuntu安装后上网问题,
首先VMware网络配置详解一:三种网络模式简介 http://www.cnblogs.com/gylei/archive/2012/04/06/2435087.html 很详细. 此处讲述通过桥接来 ...
- [SQL]删除约束
来源:http://www.archonsystems.com/devblog/2012/05/25/how-to-drop-a-column-with-a-default-value-constra ...
- 主成分分析、实例及R语言原理实现
欢迎批评指正! 主成分分析(principal component analysis,PCA) 一.几何的角度理解PCA -- 举例:将原来的三维空间投影到方差最大且线性无关的两个方向(二维空间). ...
- HTTP和HTTPS协议,看一篇就够了
https://blog.csdn.net/xiaoming100001/article/details/81109617 因为http请求是无状态的,所以需要三次握手.四次挥手来确定状态. 大纲 这 ...
- 自学web前端能不能找到一份前端的工作吗
关于自学web前端能不能通过社招找到一份互联网公司web前端开发的工作,有无数的人问出这样的问题,答案没有标准的,只能从概率去考虑.有的人可以,有的人不可以,有的人自学就业的概率就是高,有的概率就是低 ...
- ubuntu搭建svn服务器并htpp访问版本库并svn与web同步
Ubuntu搭建SVN服务器多版本库 1 介绍 Subversion是一个自由,开源的版本控制系统,这个版本库就像一个普通的文件服务器,不同的是,它可以记录每一次文件和目录的修改情况.这样就可 ...